







TextCNN 模型是用来对文本进行分类。
TextCNN 模型结构图
TextCNN模型结构比较简单,其论文中整个模型的结构如下图所示: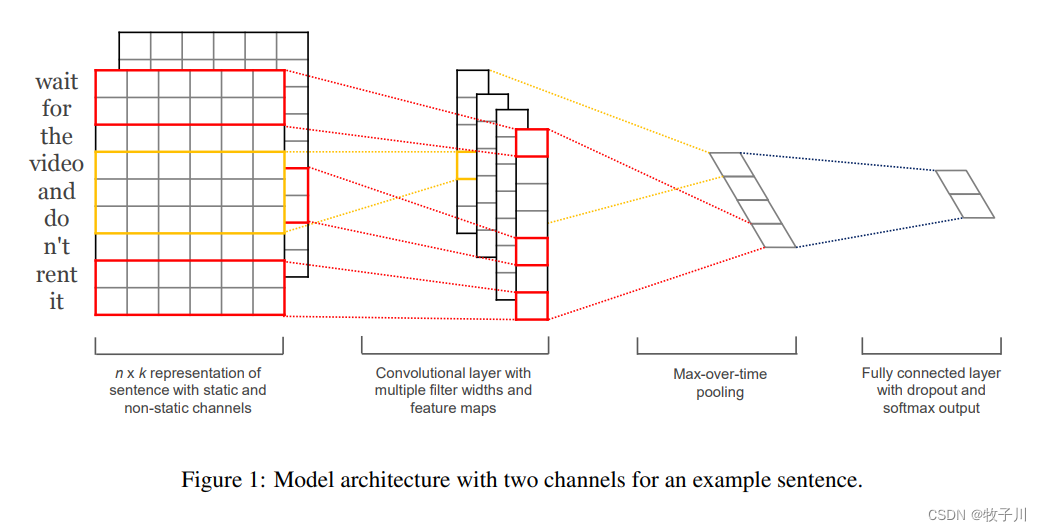
图1 Text CNN 模型结构图1
对于论文中的模型图可能会看不懂,我们会对下面这张原理图进行讲解:
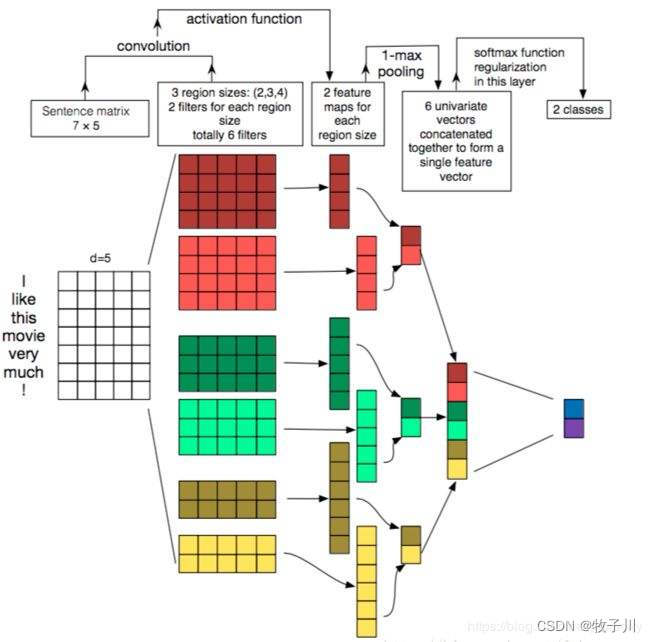
图2 Text CNN 模型结构图2
输入一句话:I like this movie very much!,将其向量化,得到维度为5的矩阵,其 shape 为[1,7,5]。
将其送入模型,先经过3个卷积,卷积核大小分别为(2,5),(3,5),(4,5)。得到的 feature_map 的 shape 为 [1, 6],[1, 5],[1,4]。
将得到的 feature_map 经过最大池化,得到 feature_map 的 shape 为 [1, 2],[1, 2],[1,2]。
将池化后的 feature_map 进行拼接,得到的 shape 为 [1,6],最后将其分为 2 分类。
注:每个 shape 中的第一维度均为 batch_size。这里是以论文为主,所有为 1 ,实际不为 1。
数据集处理
数据集使用THUCNews中的train.txt、test.txt、dev.txt,为十分类问题。其中训练集一共有 180000 条,验证集一共有 10000 条,测试集一共有 10000 条。其类别为 finance、realty、stocks、education、science、society、politics、sports、game、entertainment 这 十个类别。
对于输入数据,我们需要将文本转换成 embedding,即向量化。并且所有数据的长度是需要一致的。
读取所有数据
将数据处理成模型输入的格式
text = self.all_text[index][:self.max_len]
label = int(self.all_label[index])
text_idx = [self.word_2_index.get(i, 1) for i in text]
text_idx = text_idx + [0] * (self.max_len - len(text_idx))
text_idx = torch.tensor(text_idx).unsqueeze(dim=0)
return text_idx, label模型准备
class Block(nn.Module):
def __init__(self, kernel_s, embeddin_num, max_len, hidden_num):
super().__init__()
# shape [batch * in_channel * max_len * emb_num]
self.cnn = nn.Conv2d(in_channels=1, out_channels=hidden_num, kernel_size=(kernel_s, embeddin_num))
self.act = nn.ReLU()
self.mxp = nn.MaxPool1d(kernel_size=(max_len - kernel_s + 1))
def forward(self, batch_emb): # shape [batch * in_channel * max_len * emb_num]
c = self.cnn(batch_emb)
a = self.act(c)
a = a.squeeze(dim=-1)
m = self.mxp(a)
m = m.squeeze(dim=-1)
return m
class TextCNNModel(nn.Module):
def __init__(self, emb_matrix, max_len, class_num, hidden_num):
super().__init__()
self.emb_num = emb_matrix.weight.shape[1]
self.block1 = Block(2, self.emb_num, max_len, hidden_num)
self.block2 = Block(3, self.emb_num, max_len, hidden_num)
self.block3 = Block(4, self.emb_num, max_len, hidden_num)
self.emb_matrix = emb_matrix
self.classifier = nn.Linear(hidden_num * 3, class_num) # 2 * 3
self.loss_fun = nn.CrossEntropyLoss()
def forward(self, batch_idx): # shape torch.Size([batch_size, 1, max_len])
batch_emb = self.emb_matrix(batch_idx) # shape torch.Size([batch_size, 1, max_len, embedding])
b1_result = self.block1(batch_emb) # shape torch.Size([batch_size, 2])
b2_result = self.block2(batch_emb) # shape torch.Size([batch_size, 2])
b3_result = self.block3(batch_emb) # shape torch.Size([batch_size, 2])
# 拼接
feature = torch.cat([b1_result, b2_result, b3_result], dim=1) # shape torch.Size([batch_size, 6])
pre = self.classifier(feature) # shape torch.Size([batch_size, class_num])
return pre模型训练
for epoch in range(args.epochs):
model.train()
loss_sum, count = 0, 0
for batch_index, (batch_text, batch_label) in enumerate(train_loader):
batch_text, batch_label = batch_text.to(device), batch_label.to(device)
pred = model(batch_text)
loss = loss_fn(pred, batch_label)
opt.zero_grad()
loss.backward()
opt.step()训练结果
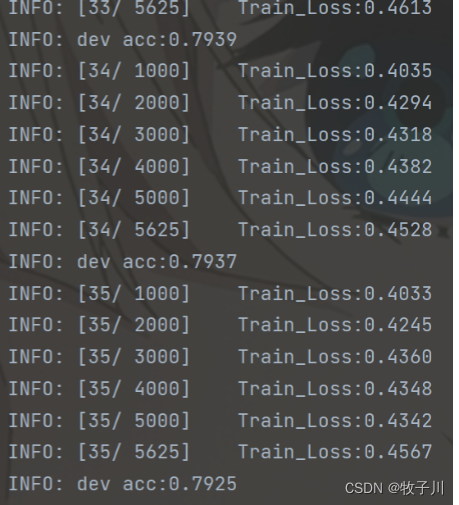
图3 模型训练过程
模型预测

图4 模型推理结果
源码获取
 https://github.com/mzc421/pytorch-nlp/tree/master/01-TextCNN%20%E6%96%87%E6%9C%AC%E5%88%86%E7%B1%BB
https://github.com/mzc421/pytorch-nlp/tree/master/01-TextCNN%20%E6%96%87%E6%9C%AC%E5%88%86%E7%B1%BB硬性的标准其实限制不了无限可能的我们,所以啊!少年们加油吧!


















 3953
3953

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











