





学习时间:2023.4.15-2023.4.21
学习内容:
1.将之前的实验跑了一遍,结果如下:
epoch 29, time: 14880.11
train_loss: 2.67, score: 74.37 ,upper_bound: 92.13
eval score: 59.32 (upper_bound: 91.72)
epoch 30, time: 10764.87
train_loss: 2.65, score: 74.67 ,upper_bound: 92.13
eval score: 59.42 (upper_bound: 91.72)
epoch 31, time: 10765.54
train_loss: 2.63, score: 75.03 ,upper_bound: 92.13
eval score: 59.34 (upper_bound: 91.72)
epoch 32, time: 11274.48
train_loss: 2.61, score: 75.16 ,upper_bound: 92.13
eval score: 59.36 (upper_bound: 91.72)
epoch 33, time: 15305.16
train_loss: 2.60, score: 75.41 ,upper_bound: 92.13
eval score: 59.39 (upper_bound: 91.72)
epoch 34, time: 18538.69
train_loss: 2.59, score: 75.64 ,upper_bound: 92.13
eval score: 59.44 (upper_bound: 91.72)
epoch 35, time: 16682.09
train_loss: 2.57, score: 75.87 ,upper_bound: 92.13
eval score: 59.33 (upper_bound: 91.72)
epoch 36, time: 15214.82
train_loss: 2.56, score: 76.11 ,upper_bound: 92.13
eval score: 59.34 (upper_bound: 91.72)
epoch 37, time: 16723.82
train_loss: 2.55, score: 76.22 ,upper_bound: 92.13
eval score: 59.34 (upper_bound: 91.72)
最后eval_score不在增长,原论文中的eval_score达到了65。相差5分。
还是容易出现过拟合,是不是数据集不够大?
3。查找阅读论文《MixGen: A New Multi-Modal Data Augmentation》
本文介绍了一种用于视觉语言表示学习的联合数据增强技术,通过插入图像和连接文本来生成具有语义关系的新图像-文本对。

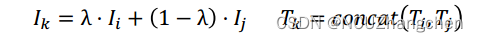
将两个图像文本对,图像进行插值,文本进行拼接。
这个步骤可以分为图像文本编码前和编码后进行。文中实验结果显示编码前进行效果最佳。
但是研究发现该种方法虽然能够增大数据集数量,但是不适合本实验。
本实验中每一个问题答案以及图像不是通过文本图像对:{文本,图像}的编码形式,而是通过image_id,question_id匹配,一个图像对对应多个问题,一个问题对应多个图像。且每张图像会包含一个question_type,以及对应回答的score,这个score是有数据集创建团队调研得出。如果进行拼接,每张图像会包含2个question_type,当然,文章中也尝试过两个文本的融合,这样只有一个question_type。
最为重要的是拼接得到的答案的score不好确定。导致无法用在本数据集上。
2023.04.21 第41周周报
最新推荐文章于 2024-06-01 23:53:57 发布















 384
384











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









