






文章目录
week41 JTFT
摘要
本周阅读了题为A Joint Time-Frequency Domain Transformer for multivariate time series forecasting的论文。该文提出了一种联合时频域变换器(JTFT)。 JTFT 使用少量可学习频率来利用频域 (FD) 中时间序列数据的稀疏性。此外,JTFT 还包含固定数量的最新数据点,以增强对时域局部关系的学习。这些设计降低了理论复杂性和实际计算量。此外,采用低秩注意力层来有效提取关键的跨渠道依赖关系,这使得 JTFT 超越了仅通过 CI 建模所实现的性能。
Abstract
This week’s weekly newspaper decodes the paper entitled A Joint Time-Frequency Domain Transformer for multivariate time series forecasting. This study propose a Joint Time-Frequency Domain Transformer (JTFT). JTFT leverages the sparsity of time series data in the frequency domain (FD) using a small number of learnable frequencies. Additionally, JTFT incorporates a fixed number of the latest data points to enhance the learning of local relationships in the time domain. These designs reduce both theoretical complexity and
real computation. Furthermore, a low-rank attention layer is employed to efficiently extract crucial cross-channel dependencies, which allows JTFT to go beyond the performance achieved by CI modeling alone.
1. 题目
标题:A Joint Time-Frequency Domain Transformer for multivariate time series forecasting
作者:Yushu Chen a 1, Shengzhuo Liu b, Jinzhe Yang c, Hao Jing d, Wenlai Zhao a 1, Guangwen Yang
发布:Neural Networks Volume 176, August 2024, 106334
链接:https://doi.org/10.1016/j.neunet.2024.106334
源代码链接:https://github.com/rationalspark/JTFT.git
2. Abstract
为了增强 Transformer 模型的长期多元预测性能,同时最大限度地减少计算需求,本文引入了联合时频域Transformer(JTFT)。 JTFT 结合时域和频域表示来进行预测。频域表示有效地提取多尺度依赖性,同时通过利用少量可学习频率来保持稀疏性。同时,时域(TD)表示源自固定数量的最新数据点,加强了局部关系的建模并减轻了非平稳性的影响。重要的是,表示的长度独立于输入序列长度,使 JTFT 能够实现线性计算复杂度。此外,提出了低秩注意力层来有效捕获跨维度依赖性,从而防止因时间和通道建模的纠缠而导致的性能下降。八个真实世界数据集的实验结果表明,JTFT 在预测性能方面优于最先进的基线。
3. 网络架构
3.1 JTFT
初步:多元时间序列预测根据历史数据预测时间序列的未来值。用 x 1 : L = { x 1 , … , x L } x_1:L = \{x_1,\dots, x_L\} x1:L={x1,…,xL} 表示输入序列,其中 L 表示回溯窗口(输入长度)。该系列有 D 个通道,第 i 个通道表示为 x i = { x 1 i , … , x L i } x^i = \{x_1^i,\dots, x_L^i\} xi={x1i,…,xLi}。待预测的未来值表示为 x L + 1 : L + T = { x L + 1 , … , x L + T } x_{L+1:L+T}=\{x_{L+1},\dots,x_{L+T}\} xL+1:L+T={xL+1,…,xL+T},其中𝐱𝐿+𝑇},其中 T是目标窗口(预测长度)。该模型的任务是将 x 1 : L x_{1:L} x1:L 映射到 y ∈ R D × T y\in \mathbb R^{D\times T} y∈RD×T ,这是 x L + 1 : L + T x_{L+1:L+T} xL+1:L+T 的近似值。
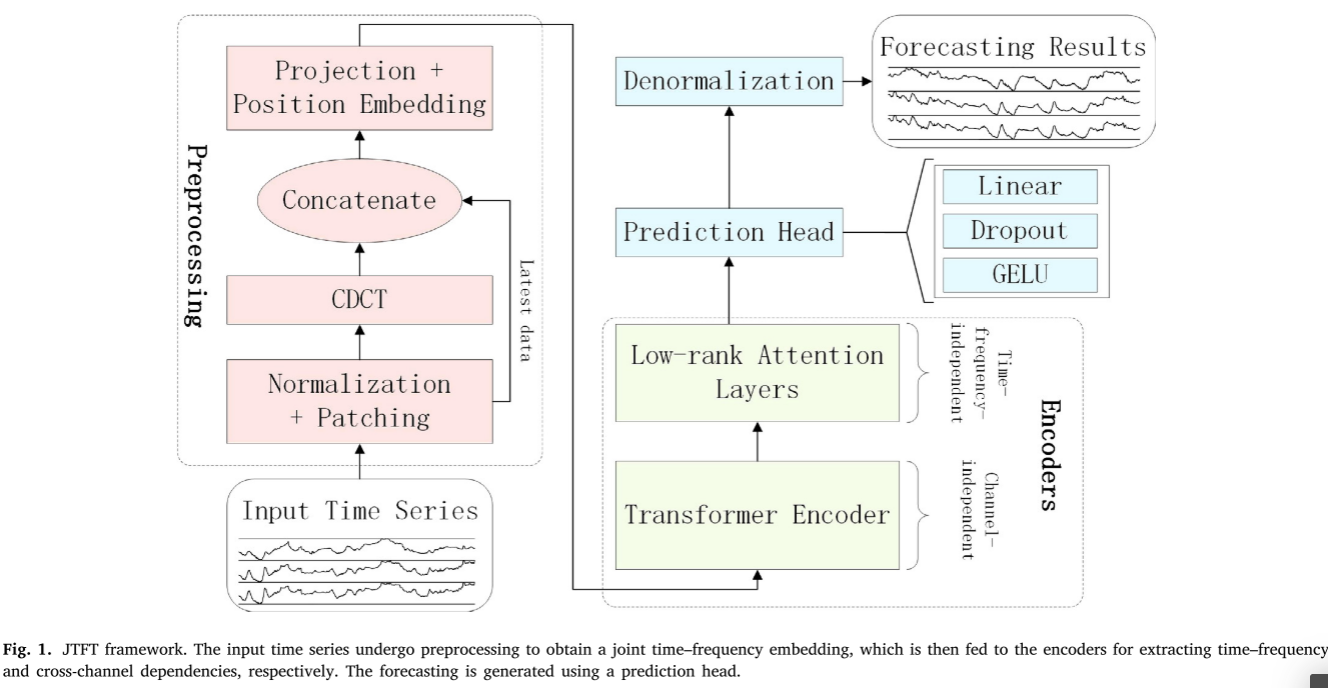
整体结构:JTFT的整体结构如图1所示。该模型首先将输入序列变换为联合时频域嵌入,然后通过Transformer Encoder和低秩跨通道注意力机制将其映射到潜在表示,最后使用预测头生成输出,然后进行反规范化。
在预处理阶段,输入的每个通道都经过均值减法和标准差缩放。
然后,应用修补技术将时间序列分为重叠或非重叠-重叠的连续段。在此过程中,输入多元时间序列的每个通道都被视为单独的单变量时间序列,然后将其划分为补丁。将补丁长度表示为
l
p
l_p
lp,将步幅表示为
l
s
l_s
ls,其中L和
l
p
l_p
lp都必须能被
l
s
l_s
ls整除。通过修补操作重新排列输入:
Patching
x
1
:
L
=
Z
p
c
h
(1)
\text{Patching}_{x_{1:L}}=Z_{pch} \tag{1}
Patchingx1:L=Zpch(1)
其中输入序列
x
1
:
L
∈
R
D
×
L
x_{1:L}\in\mathbb R^{D\times L}
x1:L∈RD×L,补充序列
Z
p
c
h
∈
R
D
×
L
~
×
l
p
Z_{pch}\in \mathbb R^{D\times \tilde L\times l_p}
Zpch∈RD×L~×lp,且
(
Z
p
c
h
)
j
i
=
x
(
j
−
1
)
l
s
+
1
:
(
j
−
1
)
l
s
+
l
p
i
(2)
(Z_{pch})^i_j=x^i_{(j-1)l_s+1:(j-1)l_s+l_p} \tag{2}
(Zpch)ji=x(j−1)ls+1:(j−1)ls+lpi(2)
对于通道索引
i
∈
{
1
,
…
,
D
}
i\in \{1,\dots,D\}
i∈{1,…,D} 和补丁索引
j
∈
{
1
,
…
,
L
^
}
j\in \{1,\dots, \hat L\}
j∈{1,…,L^}。通过重复最后一个元素
l
s
l_s
ls 次来填充输入序列,从而总共生成
L
~
=
(
L
−
l
p
)
/
l
s
+
2
\tilde L=(L-l_p)/l_s+2
L~=(L−lp)/ls+2 个补丁。这些补丁充当后续建模阶段的基本输入单元。
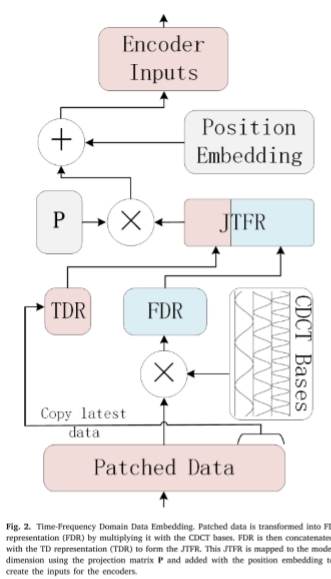
然后,预处理后的数据通过自定义离散余弦变换 (CDCT) 模块来提取频域 (FD) 分量。图 2 进一步说明了这一进展。
TD 和 FD 数据的融合在减轻时间序列数据非平稳性的不利影响方面发挥着至关重要的作用。此外,CDCT 基础的周期性性质可能无法准确代表这些时间变化。因此,纳入最新的 TD 数据对于捕获最新的本地关系至关重要。
JTFT 中的 Transformer 编码器和低秩注意力层分别提取时频和跨通道依赖性。混合跨渠道相关性可能不如单独建模效果更好(PatchTST效果优于通道混合模型),故JTFT 利用两阶段方法分别捕获时间频率和通道依赖性。虽然在此阶段尚未对跨通道交互进行建模,但编码器在所有通道之间共享,并使用所有可用数据进行训练,这有助于减轻过度拟合。
预测头由 GELU 激活函数、dropout 层和线性投影层组成
该模型使用 Huber 损失函数进行训练,与均方误差 (MSE) 损失相比,该函数对数据中的异常值具有更大的恢复能力。
3.2 具有可学习频率的稀疏FD表示
利用 FD 稀疏性来降低计算和内存复杂性也至关重要。根据FEDTransformer 的研究结果,为了用更少的分量更精确地表示时间序列,引入了具有可学习频率的FD表示。
CDCT 是离散余弦变换 (DCT) 的推广,它以不同频率振荡的实值余弦函数之和来表示序列。DCT大致将长度减半来表示实数序列,并且具有很强的能量压缩特性。因此,它在压缩方面更优选,因此适合用少量 FD 分量来表示系列。 DCT 的一种常用形式是
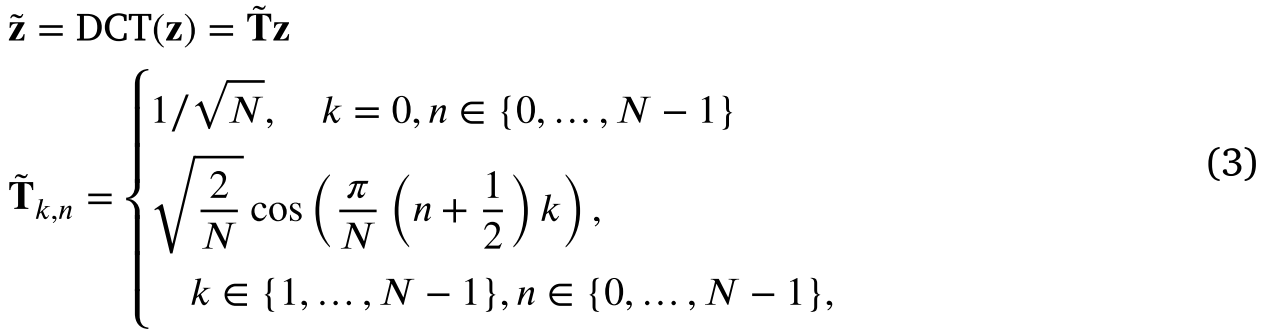
矩阵 T ~ \mathbf {\tilde T} T~ 是正交的,因此逆变换为

为了进一步提高少量固定数量的 FD 分量的表示能力,通过将具有特定频率的 DCT 推广为 CDCT 来提出
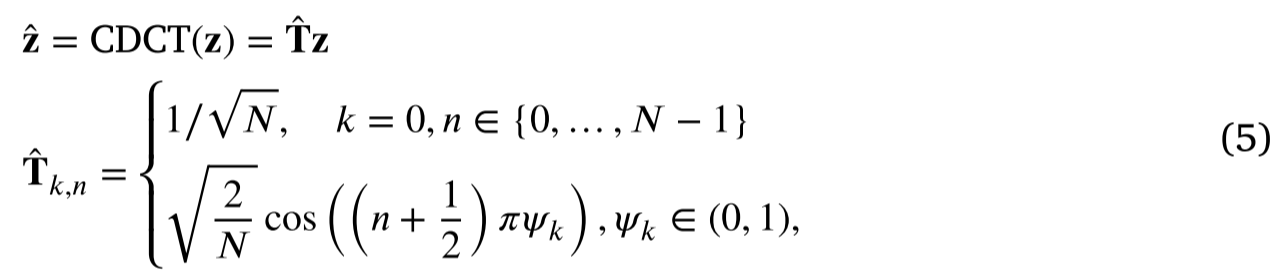
如果将 n f < < N nf<<N nf<<N视为常数,则 CDCT 的复杂度为 O ( N ) O(N) O(N)。
除首个频率外,其余频率均为可学习参数。这种灵活性使得 CDCT 内的频率调整能够更好地近似数据中最重要的频率,这些频率可能与 DCT 的统一网格点不对齐。
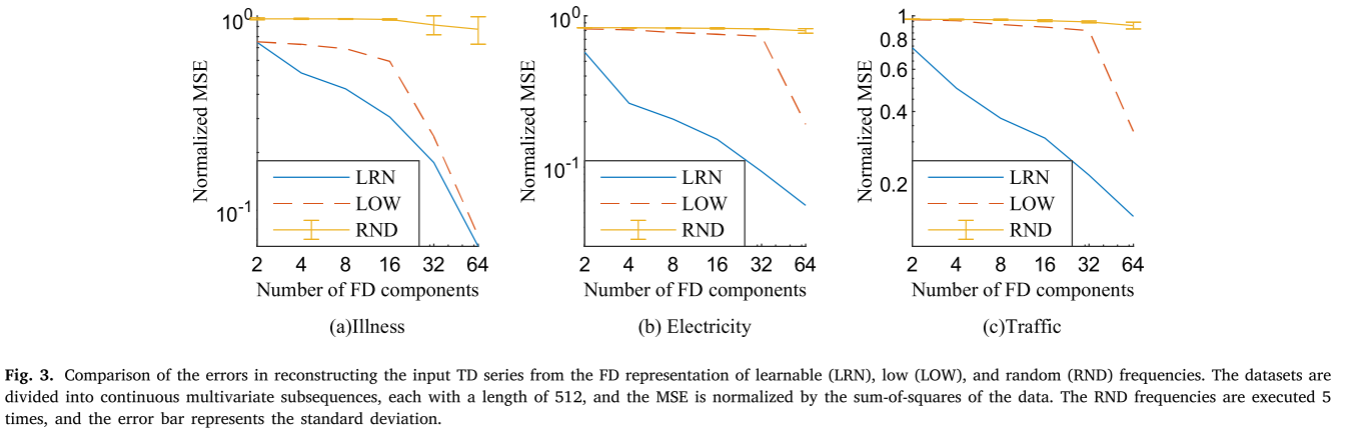
通过检查重建输入 TD 序列的误差来比较可学习 (LRN)、低 (LOW) 和随机 (RND) 频率的表示能力。从图 3 所示的结果来看,当分量数量相同时,与随机和低频相比,可学习频率表示从输入中保留了更多信息。
3.3 用于提取跨渠道依赖关系的低阶注意力层
为了满足以更少的冗余捕获跨通道依赖关系的需求,引入了低秩注意力(LRA)层。 LRA 是一种将跨渠道信息集成到 CI 建模中的计算高效方法。它在通道维度上进行轻量级关注,对 CI Transformer 编码器的输出生成低秩校正。
LRA 通过两种方法将更新限制在低秩空间,从而缓解过度拟合。首先,它将跨通道序列映射到低维表示,然后线性投影回原始空间以生成更新。其次,它采用时频独立(TFI)设置,在时频维度上共享校正。此外,它通过简化注意力机制并将位置嵌入从输入空间移动到低维表示空间来减少参数数量。
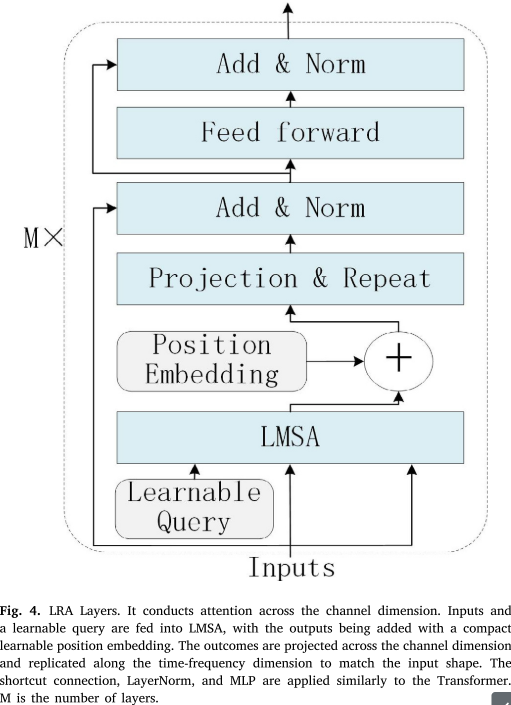
图4说明了LRA的结构。它用轻量级多头自注意力(LMSA)取代了通道式 Transformer 编码器中的资源密集型多头自注意力(MSA)。
LMSA 利用简短的可学习查询将来自所有通道的消息聚合到低秩空间中。此外,LMSA 输出中添加了紧凑的可学习位置嵌入,以说明低秩空间内的位置。
LMSA 是 MSA 的简化版本,减少了计算要求和参数。在 LMSA 中,键和值共享相同的线性投影。因为它与可学习查询一起使用,所以查询的线性投影也被省略。标准 MSA 表示为
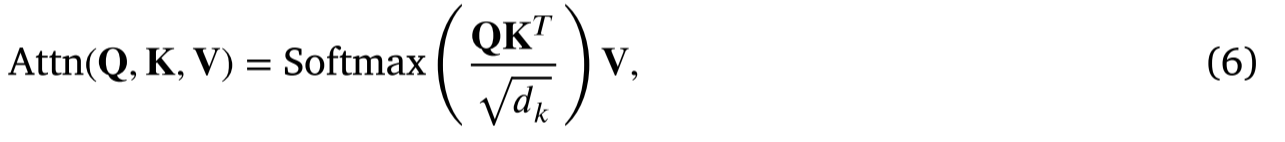
LMSA 表示为
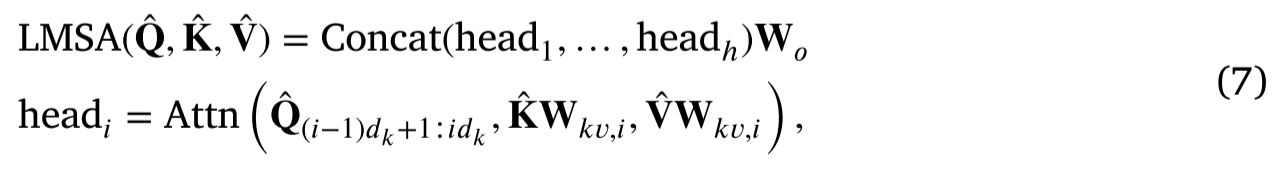
LRA的输入是Transformer编码器得到的CI表示。LRA描述为

R \mathbf R R为可学习参数
LRA 的计算效率很高,这得益于其低秩性质。 LRA 将复杂度降低到 O ( D d r ) O(Dd_r) O(Ddr)。当 d r < < D d_r<<D dr<<D 被视为常数时,该复杂度可以近似为 O ( D ) O(D) O(D)。
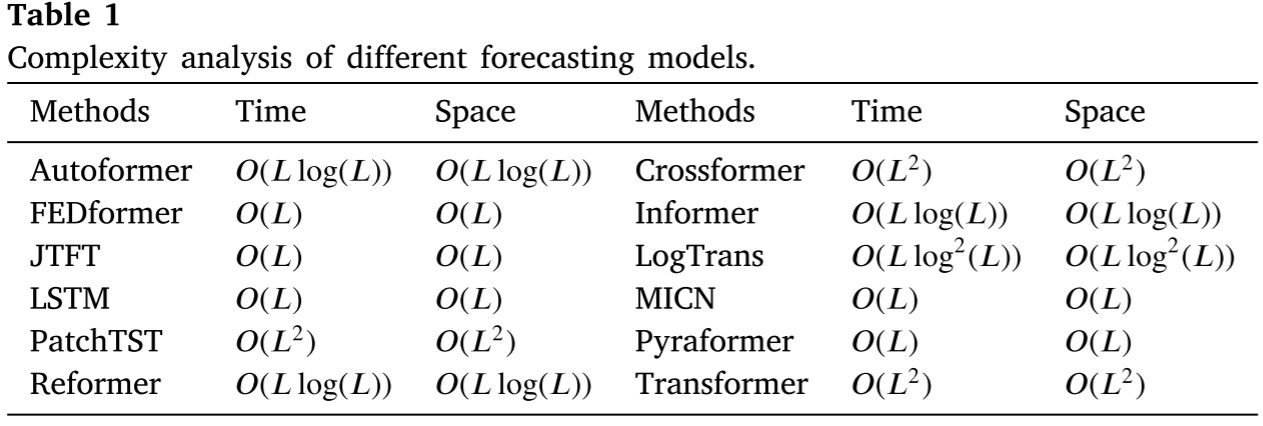
表1比较了各种时间序列预测模型的时间和空间复杂度。 JTFT 是复杂度最低的预测模型之一 。值得注意的是,Crossformer 和 PatchTST 具有很高的理论复杂度,但它们通过使用分段投影而不是单个时间点作为 Transformer 编码器的输入,有效降低了实际计算成本。
4. 文献解读
4.1 Introduction
PatchTST(Nie、Nguyen、Sinthong 和 Kalagnanam,2023)通过应用修补和通道独立 (CI) 设置,使 Transformers 的性能优于 DLinear。
简单的线性模型 DLinear(Zeng、Chen、Zhang 和 Xu,2022)优于许多基于 Transformer 的方法,这表明 Transformer 对于时间序列预测可能不够有效。
增强稀疏频域表示以捕获多尺度特征对于开发低复杂度的高精度预测方法至关重要。
Crossformer采用两阶段注意力层来学习跨通道依赖性,但在大多数实验中其性能不如带有 CI 的 PatchTST。此外,Li、Rao、Pan 和 Xu(2023 Crossformer)强调了在捕获时间和通道交互时纠缠和冗余的有害影响。
由于现有方法在实现高精度和低复杂性方面的局限性,特别是在合并跨通道依赖性时,该文提出了一种联合时频域变换器(JTFT)。 JTFT 使用少量可学习频率来利用频域 (FD) 中时间序列数据的稀疏性。此外,JTFT 还包含固定数量的最新数据点,以增强对时域局部关系的学习。这些设计降低了理论复杂性和实际计算量。此外,采用低秩注意力层来有效提取关键的跨渠道依赖关系,这使得 JTFT 超越了仅通过 CI 建模所实现的性能。
4.2 创新点
本文的创新点在于提出了JTFT模型,该模型结合了时域和频域表示来进行时间序列预测。通过利用可学习的频率和低秩注意力层,JTFT能够高效地提取多尺度依赖关系和跨通道依赖关系,同时保持较低的计算复杂度。主要贡献有四个方面:
- 提出了定制离散余弦变换 (CDCT),用于计算定制 FD 分量并实现频率学习。基于CDCT,开发了具有一些可学习频率的FD表示,可有效捕获时间序列的多尺度结构。
- 时间序列基于稀疏 FD 和最新 TD 表示进行编码,这使得 Transformer 能够以线性复杂度有效地提取长期和局部依赖关系。
- 引入低秩注意力层来学习跨通道交互,通过减轻捕获时间和通道依赖性的纠缠和冗余来进一步提高预测性能。
- 在涵盖多个领域(医疗、能源、贸易、交通和天气)的 8 个真实世界基准数据集上进行的广泛实验结果表明,我们的模型提高了 SOTA 方法的预测性能。具体来说,JTFT 在 80 个具有不同预测长度和指标的设置中的 68 个中排名最佳,并且在实验中剩余 12 个设置中的 10 个中排名第二。
4.3 实验过程
数据集:评估了 JTFT 在八个真实数据集上的性能,包括交换、天气、交通、电力(电力消耗负载)、ILI(流感样疾病)、ETTm2(每分钟电力变压器温度)、PEMS04 和 PEMS08。按照 Nie 等人的研究,数据集分为训练集、验证集和测试集。 (2023),ETTm2 的分流比为 0.6:0.2:0.2,其他数据集的分流比为 0.7:0.1:0.2。
基线:
- 使用多个 SOTA 模型作为时间序列预测的基线,包括 PatchTST (Nie et al., 2023)、Crossformer (Zhang & Yan, 2023)、FEDformer (Zhou, Ma, Wen, Wang, et al., 2022) 、FiLM(Zhou、Ma、Wen、Sun 等人,2022)、DLinear(Zeng 等人,2022)、DeepTime(Woo 等人,2023)、TSMixer(Chen、Li、Arik、Yoder 和 Pfister) ,2023)。
- 经典模型如 ARIMA、基本的 RNN/LSTM/CNN 模型
实验设置:ILI 的预测长度为 T ∈ { 24 , 36 , 48 , 60 } T\in\{24, 36, 48, 60\} T∈{24,36,48,60},而其他数据集的预测长度为 T ∈ { 96 , 192 , 336 , 720 } T\in \{96, 192, 336, 720\} T∈{96,192,336,720}。 PatchTST、DLinear、FiLM、DeepTime 和 TSMixer 的基线结果是从其原始论文中获得的,回顾窗口𝐿可以搜索或设置为建议值。具体到 PatchTST,展示了 PatchTST/64 的结果,其整体性能通常比 PatchTST/42 更好。对于文献中没有的其他方法或设置,𝐿是通过网格搜索来确定的,以建立强大的基线。对于两个较小的数据集(ILI 和 Exchange),搜索范围为 {24, 48, 84, 96, 128},对于其他数据集,搜索范围为 {48, 96, 192, 336, 512, 720}。相比之下,JTFT 配置与 PatchTST/64 一致,其中对于较小的数据集,𝐿 设置为 128,对于较大的数据集,设置为 512。
报告的评估指标包括用于多元时间序列预测的均方误差(MSE)和平均绝对误差(MAE)。
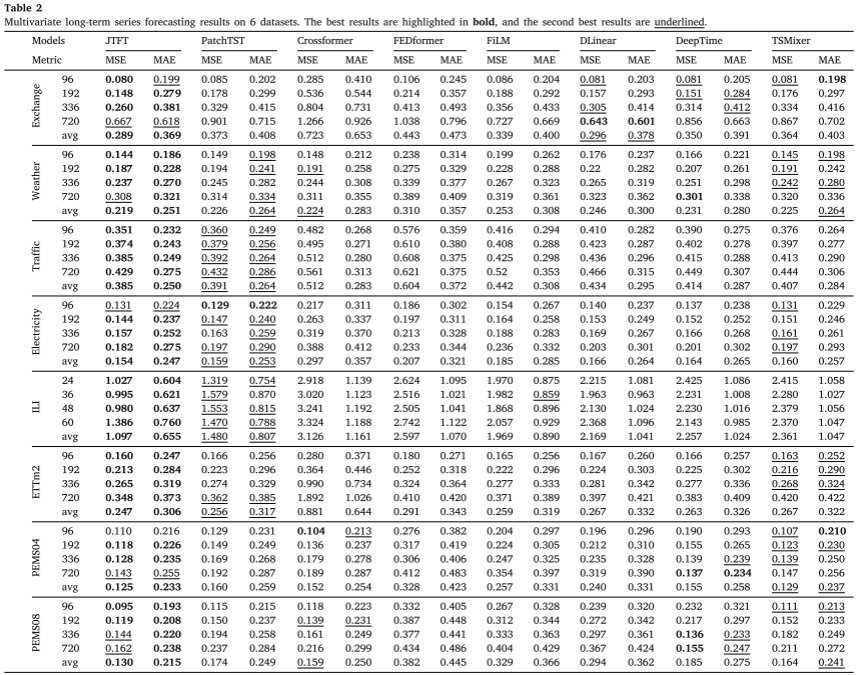
表 2 列出了多变量预测结果,其中 JTFT 优于所有基线方法。结果凸显了通过将跨通道信息纳入多变量时间序列预测来提高 SOTA 通道无关方法性能的挑战,这主要是由于与计算机视觉 (CV) 和自然语言处理等应用相比,可用数据集的规模相对较小(NLP),过度拟合的风险较高。除了基于 Transformer 的方法之外,DLinear、FiLM、DeepTime 和 TSMixer 也被证明具有竞争力。
消融研究:研究联合时频域表示(JTFR)和低秩注意力(LRA)层的影响。将仅具有 TD 表示且无 LRA 的 JTFT 称为 TDR,将仅具有 FD 表示且无 LRA 的 JTFT 称为 FDR,将具有 TD 和 FD 表示但无 LRA 的 JTFT 称为 JTFR。 TDR、FDR 和 JTFR 的性能在三个数据集上进行评估:ILI、天气和电力,分别代表小型、中型和大型数据集。结果与表 3 中的 PatchTST 进行了比较。FEDformer 和 FiLM 也作为之前的 SOTA FD 方法包含在基线中,分别利用随机和低频。
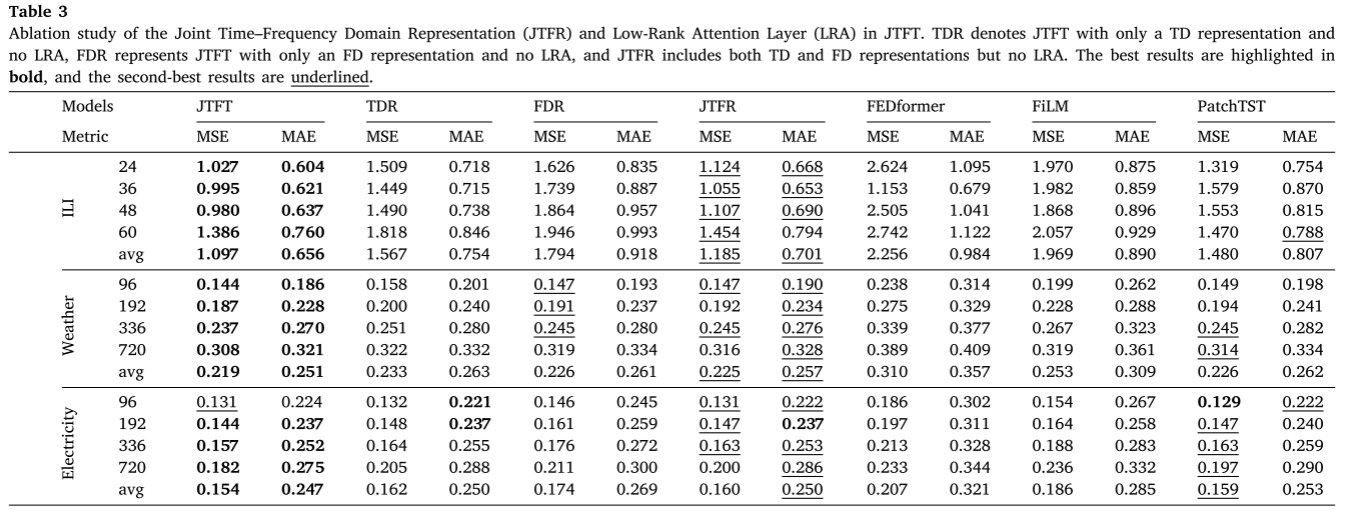
在大多数设置中,与 TDR 和 FDR 相比,JTFR 提高了性能。此外,FDR 在大多数设置中显着优于 FEDformer,甚至超过 FiLM,凸显了可学习频率的有效性。 JTFT 优于 JTFR,表明 LRA 包含通过利用跨通道相关性增强了预测性能。
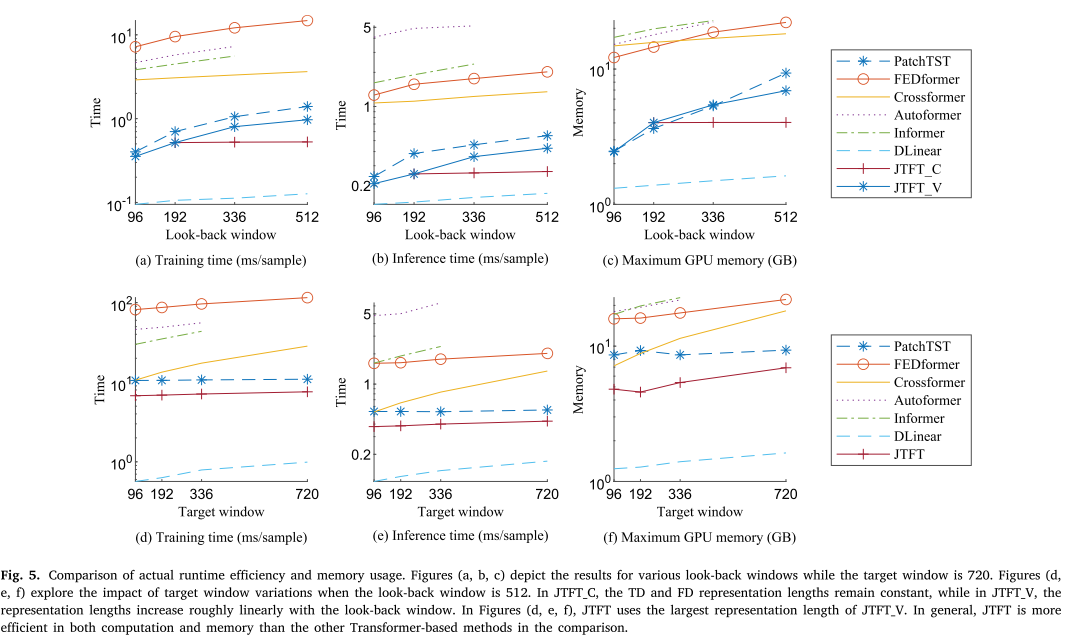
实际时间效率和内存使用情况:结果如图 5 所示。在基于 Transformer 的方法中,JTFT 速度最快且需要最少的内存。虽然 DLinear 比 JTFT 更快,但精度较差。这些结果凸显 JTFT 是一种有效的方法,特别是在考虑速度和准确性时。
5. 结论
该文介绍了 JTFT,一种用于多元时间序列预测的联合时频域 Transformer。 JTFT 使用少量可学习频率有效捕获多尺度结构,同时还利用最新的时域数据来增强局部关系学习并减轻非平稳性的不利影响。此外,它利用低秩注意力层来提取跨通道相关性,同时减轻与时间依赖性建模的纠缠。 JTFT在时间和空间上都具有线性复杂度。对 8 个真实世界数据集的大量实验表明,方法在长期预测方面实现了最先进的性能
小结
由于现有方法在实现高精度和低复杂性方面的局限性,特别是在合并跨通道依赖性时,该文提出了一种联合时频域变换器(JTFT)。 JTFT 使用少量可学习频率来利用频域 (FD) 中时间序列数据的稀疏性。此外,JTFT 还包含固定数量的最新数据点,以增强对时域局部关系的学习。这些设计降低了理论复杂性和实际计算量。此外,采用低秩注意力层来有效提取关键的跨渠道依赖关系,这使得 JTFT 超越了仅通过 CI 建模所实现的性能。
参考文献
[1] Yushu Chen, Shengzhuo Liu, Jinzhe Yang, Hao Jing, Wenlai Zhao, Guangwen Yang, “A Joint Time-Frequency Domain Transformer for multivariate time series forecasting” [J], Neural Networks Volume 176, August 2024, 106334
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









