






注:本文是在南木长博主的博客基础上增加内容,原文链接在末尾。
一、引言
现实生活中的多目标优化问题需要决策者从众多Pareto最优解中选取最终适用的解。但是大部分的多目标问题存在许多甚至无限量的Pareto最优解,获取完整的解集十分消耗时间,甚至可能也无法获取完整的解集。另一方面,决策者也不愿意从大量的Pareto最优解中进行选择。因此,学者们致力于研究能够寻找可控数量的Pareto解且解在PF上均匀分布的多目标优化算法。
众所周知,多目标优化问题的Pareto最优解在某条件下可以转化成一个聚合所有目标函数的单目标优化问题的最优解。因此,求解PF的近似解就可以分解成一些单目标优化子问题。
二、MOEA/D算法
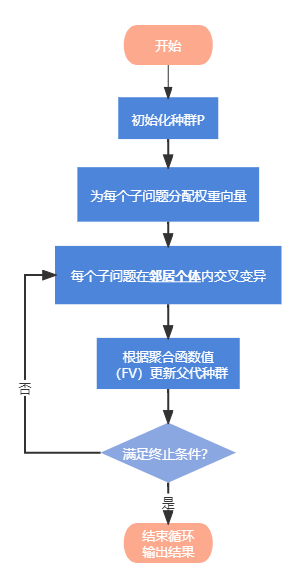
基于分解的多目标进化算法(Multi-objective Evolutionary Algorithm Based on Decomposition, MOEA/D)将一个多目标优化问题分解成许多单目标优化子问题,然后采用进化算法同时对这些子问题进行优化。
- 由于对每一个子问题进行优化时仅使用该子问题邻近的几个子问题的相关信息,因此MOEA/D算法有较低的计算复杂度。
- 由于Pareto前沿面上的一个解对应于每一个单目标优化子问题的最优解,所以最终可以求得一组Pareto最优解。
- 由于分解操作的存在,所以该方法在保持解的分布性方面有着很大优势,而通过分析相邻问题的信息来优化,能避免陷入局部最优。
三、分解方法
该方法第一次系统地被提出是在2007年,由Qingfu Zhang等人提出(MOEA/D: A Multiobjective Evolutionary Algorithm Based on Decomposition)。该方法将MOP分解为多个子问题,这样就可以优化每个子问题来求解一个MOP。一般而言,基于分解的方法首先需要得到一组均匀分布的参照向量来指导选择操作。在此,有必要说说产生参照向量的方法。目前对于低维多目标优化问题,常用方法为Das and Dennis于1998年提出的systematic approach(Normal-boundary intersection: A new method for generating the pareto surface in nonlinear multicriteria optimization problems)。
对于每个参照向量,其指导选择的过程需要比较解的优劣,这就需要用到一些标量函数来定量衡量一个解对于这个参照向量的适应度值。常用的标量函数包括:
- Weighted Sum Approach(WS)
- Tchebycheff Approach(TCH)
- penalty-based boundary intersection (PBI)
1、加权和法(WS)
(向量投影角度理解)该方法通过一个非负权重向量将MOP转化为单目标子向量。设是权重向量且满足
(每个目标函数都有自己的权重),那么下面这个单目标优化问题的最优解(唯一)就是一个Pareto最优解。
(1)
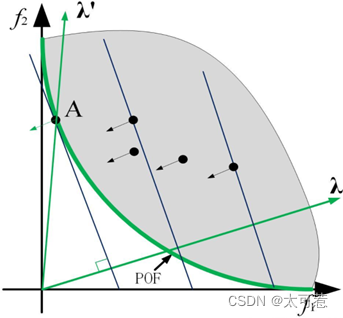
对式(1),(即权重向量和目标函数值向量相乘)可以看做点
(目标函数向量即为一个Pareto最优解)在λ 方向上的投影。从各个最优解向λ方向作垂线,从原点到垂点的距离即是投影值。上图中,A即为最短投影点。通过设置不同的权重向量λ,就可以得到所有的最短投影点,共同组成Pareto最优解集。
加权和分解法将所有的目标函数做了累加处理,然后作为一个整体的子问题来进行求解。文献中表明这种分解方法对凸优化问题的效果较好,但是对于PF 为非凸的情况往往不能求得很好的解。(非凸解向参照向量的垂线不能与PF相切)。对于这个问题,Rui Wang等人与2016年提出相对应的改进(Localized weighted sum method for many-objective optimization),主要是约束替换范围。
2、切比雪夫聚合法 (TCH)
(最大距离最小化角度理解)切比雪夫法中单目标优化函数的表达形式为:
其中,是参考点,
,即
是由所有目标函数最小值组成的参考向量。
从式(2)物理意义角度理解:值越大,就说明在这个目标函数上离理想点(最小值点)越远。假设
是所有
中的最大值,逐渐改变x使得该值减小(靠近理想点)直到到达PF上的对应点,即完成了最小化
的任务。(最大值已经最小化了,那么其它
也会最小化)。
从图像角度理解:令,并将坐标系进行平移变换。在该坐标系中,公式变为
。给定一个权重向量
。对于
上方的个体满足
,因此
上方的优化任务就变成了
。同理,对于
下方的个体满足
,
下方的优化任务就变成了
。
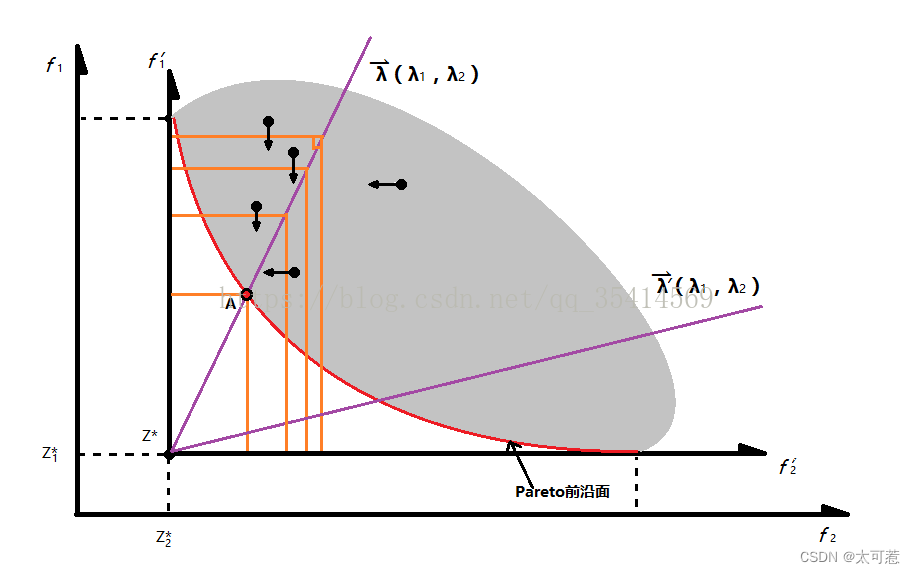
易判断,的等高线垂直于纵轴平行于横轴,
的等高线垂直于横轴平行于纵轴,因此每一个解的等高线就由两条垂线构成。收敛过程如下:对于
上方的个体,若存在新解的
小于当前等高线值,那么等高线向下移动;对于
下方的个体,若存在新解的
小于当前等高线值,那么等高线向左移动(两部分收敛时都是两条等高线同时移动)。由此,直到搜索到Pareto前沿。同理,通过设置不同的权重向量
,就可以得到所有的收敛点,共同组成Pareto最优解集。该种方法的聚合函数对于连续MOP问题来说不够平滑。但是仍适用于文中的算法框架。(文中算法不需要对聚合函数求导)。标准的TCH得到的解不均匀,为此Yutao Qi等人于2014年提出一种解决方法(MOEA/D with Adaptive Weight Adjustment),通过下面这个参照向量的转换即可得到分布均匀的解。
3、基于惩罚的边界交集法 (PBI)
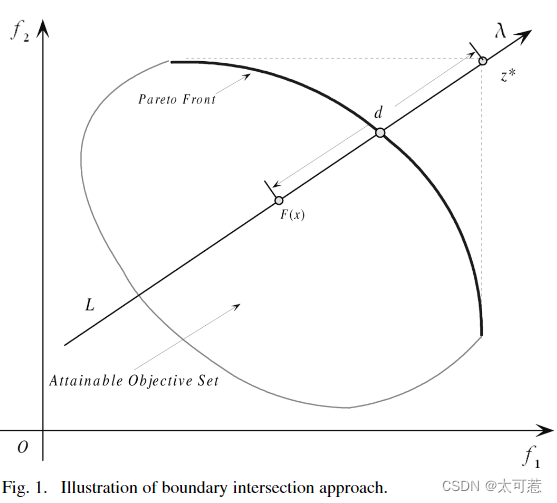
边界交叉方法适用于连续MOP问题。通常情况下,最大化连续MOP问题的PF前沿会是目标函数集的右上部分(最小化MOP的PF前沿是左下部分)。从几何学角度上理解,PBI是为了寻找边界处与一组线的交点。如果这组线在某种意义上均匀分布,那么所得到的交点就可以很好的代表PF 的近似前沿。这种方法可以用于求解非凸集。论文中采用由参考点发散出的一组线求解交点。单目标优化函数形式可以表示为
其中和
的定义与前文相同,
目标空间的一个解。如下图所示,是为了确保
与
共线于直线L(直线L朝
方向且经过参考点)。该问题的求解目标就是尽可能地使
高(d尽可能小)直到到达PF。
但上述问题不易满足等式约束条件。论文中引入惩罚方法处理约束条件,作者称这种方法为PBI approach。单目标约束问题就变为了式(4),其中,是惩罚参数。
从式(4)物理意义来理解,算法通过引入惩罚参数以此放宽了对所求解的要求。也就是说,所求解可以不在权重向量方向上,但若不在权重向量方向上就必须要接收惩罚。所求解距离权重向量越远,受的惩罚越厉害,以此来约束算法向权重向量的方向生成解。
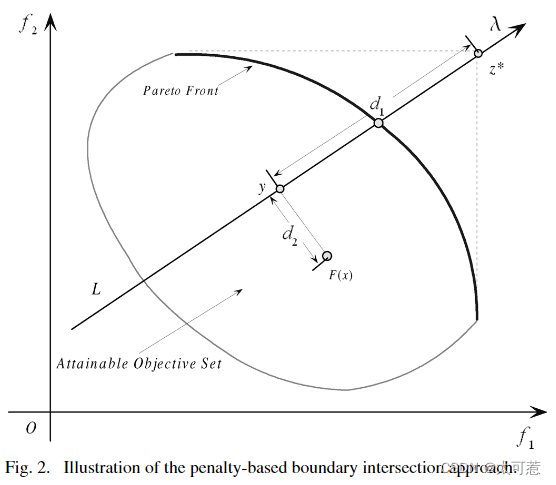
从几何角度理解和
两个公式:
:由点
指向参考点
的向量在
方向上的投影。
:由点
指向点
的向量模长。(反映所求解
与权重向量方向的偏离程度)
PBI与TCH的对比:
- 在目标函数个数大于2的情况下,使用相同均匀分布权重向量的两种方法结果显示PBI方法求出的Pareto最优解分布更均匀,尤其是在权重向量值特别大的时候;
- 如果x支配y,仍存在
的情况。但是对于
和其他BI聚合函数几乎不会出现这种情况;
- PBI也存在一定缺陷:需要自己设定惩罚参数值。参数值过大或者过小都会破坏算法性能。
四、Das and Dennis参考点
Das 和 Dennis 的“边界交叉构造权重法”。该方法将点放在规范化超平面上,该超平面与所有目标轴的斜率相同,且每个轴上的截距为一。 假如有 M 个目标,每个目标被均匀地划分为 H 份,那么规范化超平面上的参考总数 P 可由下式获得:
“边界交叉构造权重法”过程步骤如下:

- 设
是所有
的(
-1)组合
- 设
,例如图4.1中
- 设
为参考点集合,则对于每一个参考点
且
有下式
需要注意的是当的时候将仅会产生“边界参考点”,即使在H=M的时候,会产生一个“中间参考点”,如图4.2 所示。为了解决这个问题 Deb 和 Jain 给出了边界与中间参考点(boundary and intermediate reference points)共同构建参考点的方法。其具体操作如下:
- 按照“边界交叉构造权重法”产生边界层的参考点
- 按照下式产生内层参考点
在实践中,当 M≤5 时,采用 Das 和 Dennis 的方法,其它情况采用 Deb 和 Jain 的方法。
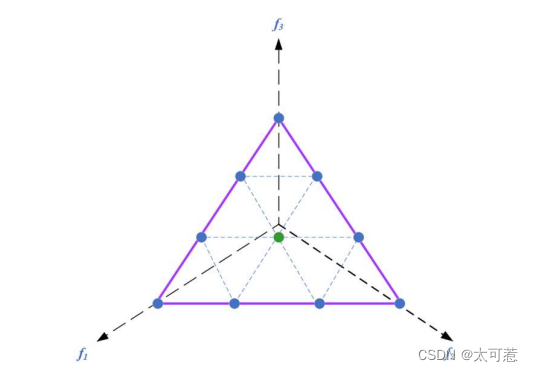
五、伪代码

六、算法框架(TCH为例)
1、基本定义
和
的定义与前文相同。求解PF近似解的MOP问题可以分解成N个单目标优化子问题,这也就意味着需要N个不同的权重向量。MOEA/D算法在一次运行过程中同时优化N个目标函数。对于第
个子问题,其数学表达式为
由于是
的连续函数,所以如果
和
很接近的话,
与
就会很接近。因此,拥有
很接近的权重向量的
对于优化
就会很有帮助。这是MOEA/D算法很重要的机制之一。
2、“邻居”定义
在MOEA/D算法中,权重向量 的邻居定义为
中的一组最接近的权重向量。同理,第
个子问题的邻居就由
的邻居所确定的子问题组成。种群由迄今为止每个子问题找到的最优解组成,仅利用当前子问题的邻近子问题的解来优化当前子问题。
3、符号定义

4、算法步骤

5、流程图
七、讨论
1、交配限制和T(邻居个数)的选择
交配限制:MOEA/D算法中,只使用当前子问题的T邻居子问题来优化当前解。也就是说,只有两个解属于两个邻居子问题,它们才有可能交配。
T的选择:T太小,子代解和父代解会十分接近,从而使得算法缺乏探索其他搜索区域的能力;T 太大,生成算子的两个输入解性能会很差,从而导致子代解性能也很差,影响算法的搜索能力。此外,T太大也会在更新邻居解步骤时产生较大的计算复杂度。
2、MOEA/D采用什么方法保留种群多样性
针对非分解优化算法是在选择机制中使用拥挤距离等算法保留种群多样性,但是这种算法不易生成均匀分布的Pareto最优解。在MOEA/D算法中,当前种群的不同解与不同子问题相关,显而易见的,子问题的多样性会影响种群多样性。因此,只要正确选择分解方法和权重向量生成合适的子问题,MOEA/D算法就会在【各个子问题都能被较好优化的情况下】生成一组在PF上均匀分布的最优解。
版权声明
本文章在【1】的基础上重新排版,并参考了其它博客文章进行丰富,原文链接如下,侵删。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









