







前言:上传功能现在在各大平台都是显而易见的,我们可以思考一下在网站上传一些小的文件是迅速的,但是为什么上传一下大文件甚至超大文件也是非常迅速的这是怎么实现的呢?这篇文章会告诉你。
在此之前我们需要先了解平常的上传文件流程。
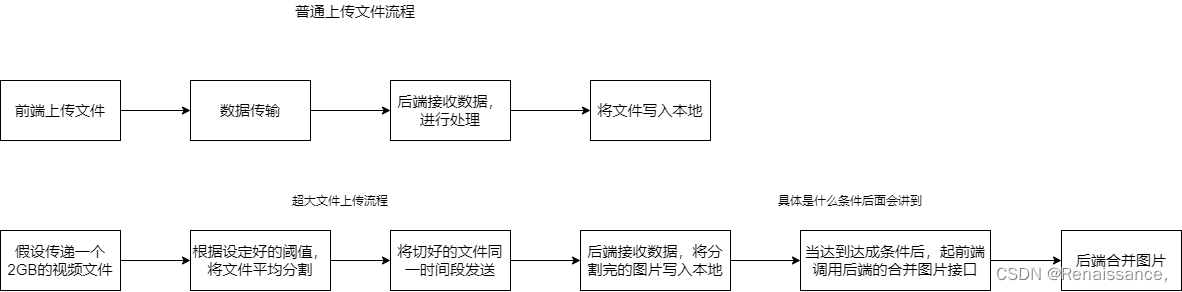
假设我们将阈值设定为500MB(可以把阈值理解为是最小的分割大小),那现在传递一个2GB的文件就会分割为4份文件,但是4份文件我们传递给后端之后顺序是被打乱的,这样的话合并出来的视频就是一张被打乱的视频。所以我们还需要给每个分割开个文件加上一个标识位,可以标示出分割文件的顺序。还有一点重要的就是在什么时机去合并文件(因为有一种情况就是上传图片的途中你的进程结束了,那样你的文件也没有传递完全在这样的情况下我们肯定是不可以去合并文件的)。具体操作请看代码。
话不多说,我们直接上代码
js代码:
<template>
<div >
<p><b>请选择你想要上传的文件:</b></p>
<a-upload
class="upload-list-inline"
:before-upload="beforeUpload"
@change="slice_filess"
>
<a-button>上传文件</a-button>
</a-upload>
</div>
</template>
<script>
import qs from "qs"
export default {
name: '',
data() {
return {
};
},
props: {},
components: {},
created() {
},
mounted() {
},
methods: {
beforeUpload: function (file) {
return false;
},
// 切片上传
slice_filess(file){
// 文件名称
var filename = file.file.name
// 文件大小
var filesize = file.file.size
// 切片阈值
var shardSize = 1024 * 1024 *2
// 总切片数 向上取整
var shardCount = Math.ceil(filesize/shardSize)
// 切片开始位置
var shardstart = 0
// 切片的结束位置
var shardend = 0
// 设置计数器,用来判断什么时候发送合并图片请求
// (只有在返回200响应的次数与切片次数相同的时候才会发送合并请求,如果次数不相同则代表期中有切片上传失败那我们就不发送合并请求)
var success_count = 0
for (var i=0;i<shardCount;i++){
// 切片的开始位置等于 当前下标*切片阈值
shardstart = i*shardSize
// 结束位置取最小值 因为如果直接开始位置加阈值的话会出错(因为每次切片不可能都正好满足阈值,有可能会小于阈值 所以我们去这里面的最小值)
shardend = Math.min(filesize,shardstart+shardSize)
// 开始切片
var slicess = file.file.slice(shardstart,shardend)
// 创建一个表单来存放文件数据
let data = new FormData()
data.append("file",slicess)
data.append("index",i) // 切片的标识符 (在合并的时候可以有效的防止合并顺序错乱)
data.append("filename",filename)
data.append("uid",1)
console.log(">>>>>>>>>>>>>>>>>>>",data)
// 发送请求,将切好的文件发送到后端
this.axios.post("/test_shard_upload/",data)
.then(resp=>{
if (resp.data.code == 200){
success_count += 1 // 计数器 保存上传切片后的文件成功的次数
if (success_count==shardCount){ // 只有成功次数与切片总数量成功的时候,才调用合并接口
this.merge_file(filename,shardCount)
}
}
}).catch(error=>{
console.log(error)
})
}
},
// 合并图片接口调用
merge_file(filename,shardCount){
this.axios.put("/test_shard_upload/",qs.stringify({'filename':filename,'count':shardCount,"uid":1}))
.then(resp=>{
if (resp.data.code==200){
alert("图片上传成功")
}
}).catch(error=>{
console.log(error)
})
}
},
computed: {},
watch: {},
directives: {},
filters: {}
};
</script>
<style>
</style>
import aiofiles # 异步文件操作模块
import shutil # 高级文件操作模块,与os模块形成互补的关系
from app.base import BaseHandler # Torando框架跨域
import os # 是python系统和操作系统进行交互的一个接口
# 物料切片上传
class AdGoodsShard(BaseHandler):
# 保存切片物料
async def post(self):
# 获取用户id
uid = self.get_argument("uid")
uid = int(uid)
# 获取用户上传的文件
files = self.request.files.get("file")[0]['body']
# 文件名称
filename= self.get_argument("filename")
# 文件标识位
index = self.get_argument("index")
# 为每一个用户都创建一个uid_upload目录 用来存放文件合并后的位置
path = f"./static/{uid}_upload/"
# 判断目录是否存在 如果不存在则创建
if not os.path.exists(path):
os.makedirs(path)
print("图片文件夹》》》》》》》",path)
paths = path+"shard/"
print("切片文件的临时文件夹》》》》》",paths)
# 为每一个用户创建一个shard文件夹,存放切片文件在合并成功图片后可以直接把shard文件夹删除,便于管理。
if not os.path.exists(paths):
os.makedirs(paths)
# 将切片后的添加到本地文件夹 以二进制的形式写入临时文件夹
async with aiofiles.open(f'{path+"shard/"}{filename}_{index}' , 'wb') as f:
await f.write(files)
return self.finish({'code': 200 , 'msg': "切片上传文件成功"})
# 合并图片接口
async def put (self):
# 获取用户id
uid = self.get_argument("uid")
# 获取总切片数
ShardCount = self.get_argument("count")
# 获取文件名
filename = self.get_argument("filename")
# 生成存放切片文件的临时文件夹,以及存放个人文件的地址。
path = f"./static/{uid}_upload/shard/"
paths = f"./static/{uid}_upload/"
# range返回一个可迭代对象 默认从0开始 到总切片数
for i in range(int(ShardCount)):
# 打开存放切片的临时文件夹 以二进制的形式循环读取文件
# 这里有一个重点,读取文件是按照文件的表示为进行读取!否则会合并出来的图片是错误的。
async with aiofiles.open(f"{path}{filename}_{i}",'rb') as f:
# 以追加的形式将切片写入到用户的文件夹
async with aiofiles.open(f"{paths}{filename}",'ab') as f1:
# 异步追加写入读取出来的文件
await f1.write(await f.read())
# 关闭文件句柄
f.close()
# 删除存放切片的临时文件
shutil.rmtree(paths+"shard/")
return self.finish({'code':200,'msg':'上传图片成功'})
ad_view_urlpatternss = [
(r'/test_shard_upload/',AdGoodsShard)
]
这里我选择一个8.46兆的视频上传测试一下,可以看到视频被切成了3份(因为我们的上传阈值是4兆的,最后不满4兆按4兆传递),只有在前3个请求返回切片上传成功后才调用了第四个合并视频的请求。
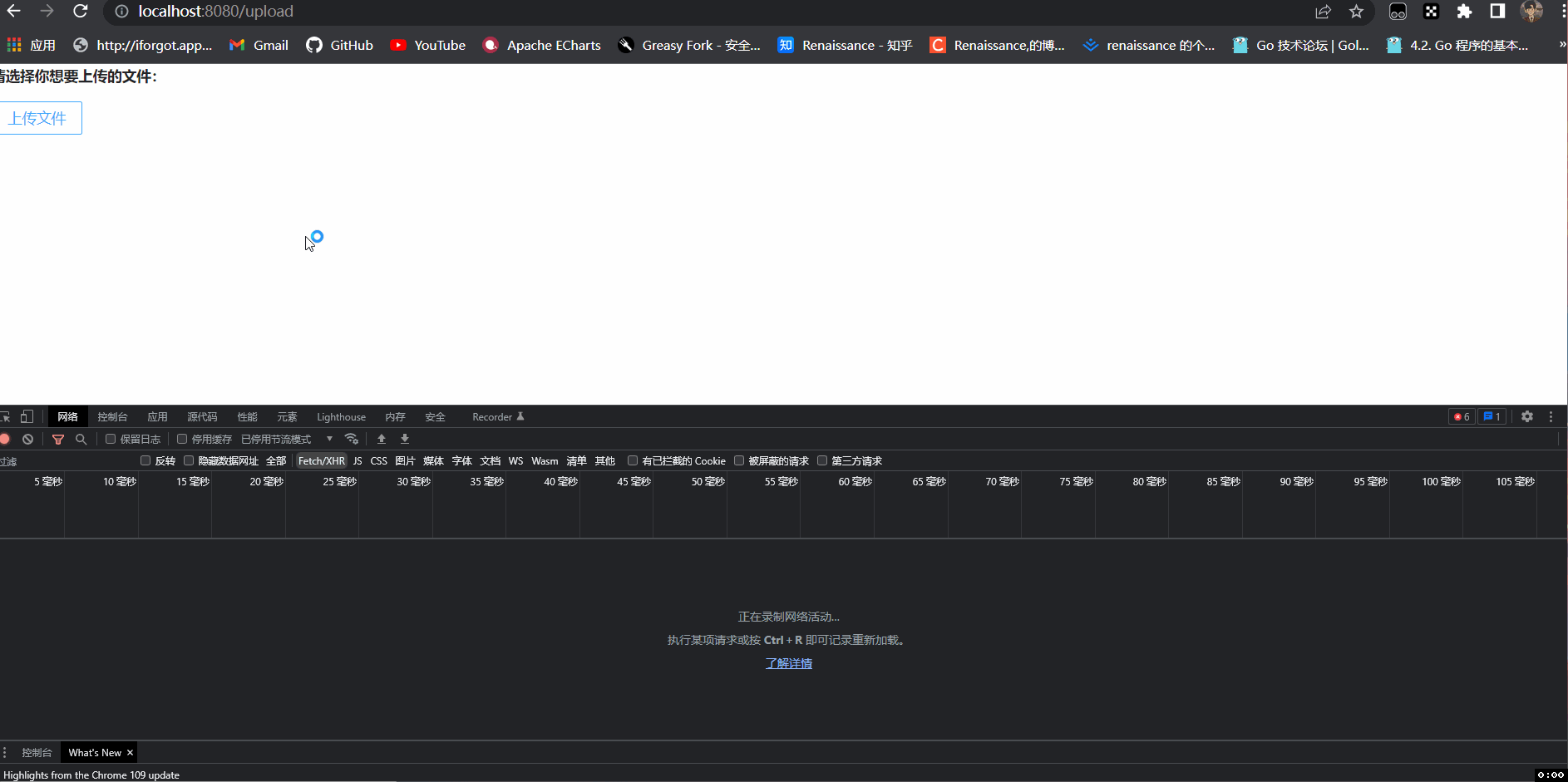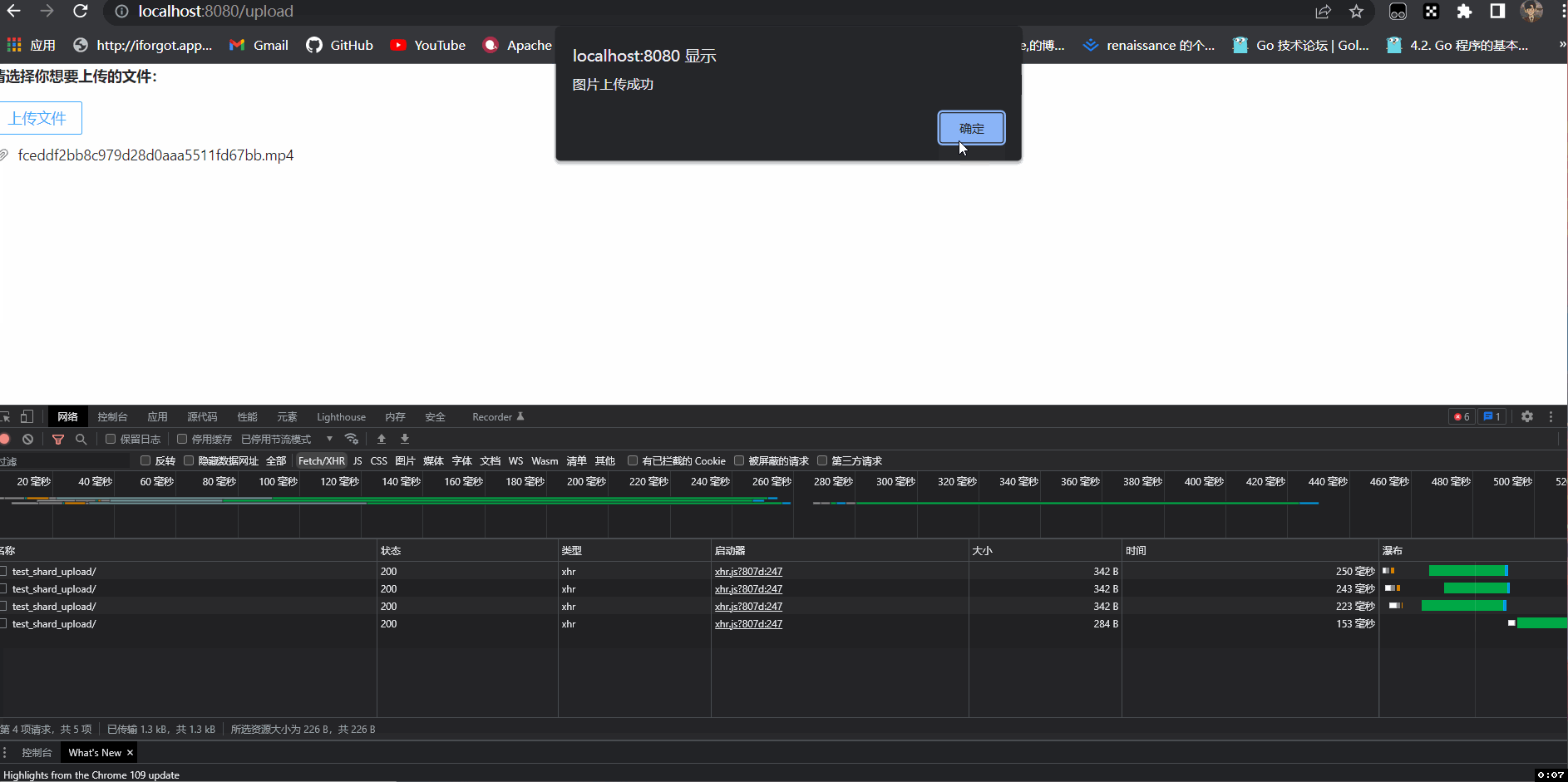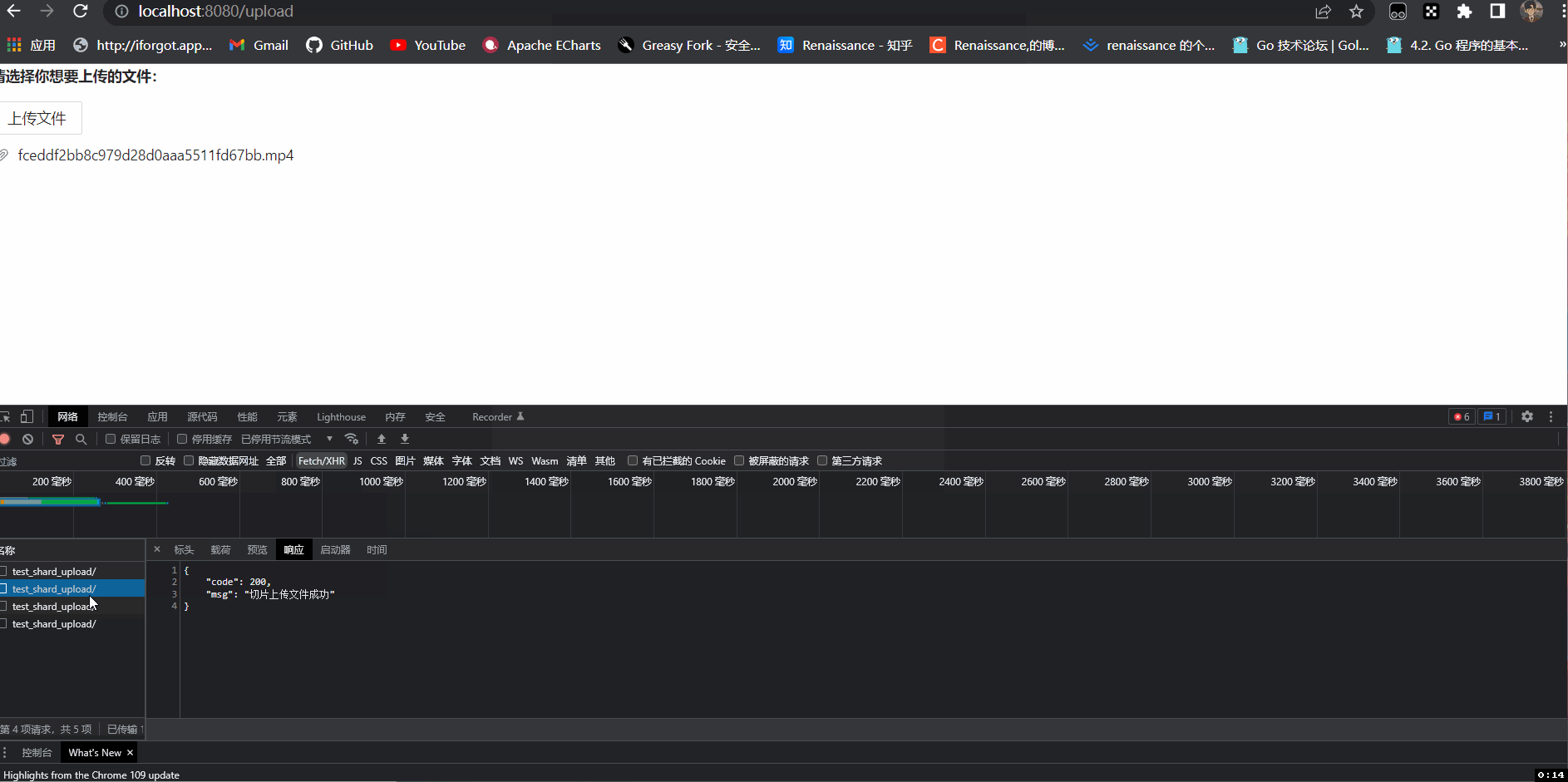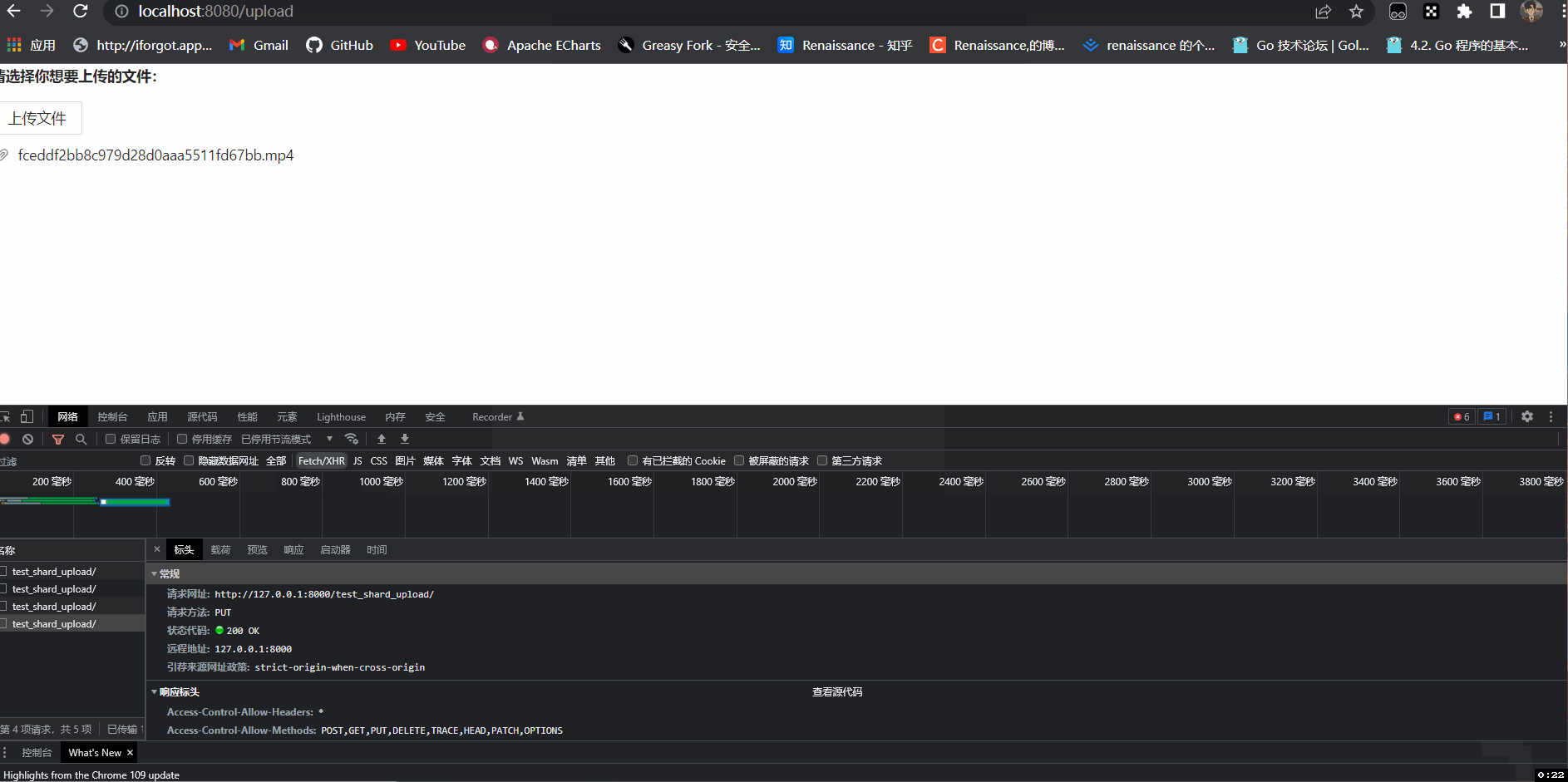
结语:以上就是上传文件的大致流程,其实可以看到哪怕七牛云的上传大型文件的底层原理也是切片处理,而切片其中的重点就是切应该怎么切,怎么切可以在合并的时候不导致文件错误,我上面的代码是在Tornado框架+Vue框架里实现的,如果你想要在别的框架使用也是可以的,换汤不换药嘛,只要你理解切片上传的运行原理都可以适用。

















 1315
1315











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











