







Few-Shot Object Detection with Attention-RPN and Multi-Relation Detector
一篇来自腾讯优图和香港大学的2020联合之作
解决问题
本文解决了在Few-shot目标检测中:给定一个包含新目标的few-shot支持图像,能够检测出测试集中所有包含目标物体的前景目标。
本文主要贡献:
- 提出一个Few-Shot目标检测模型(Contrastive tanning strategy、attention module on RPN and detector)
- 构建一个含有1000类的少样本数据集[FSOD]( https://github.com/fanq15/Few-Shot-Object-
Detection-Dataset.[)
网络架构图
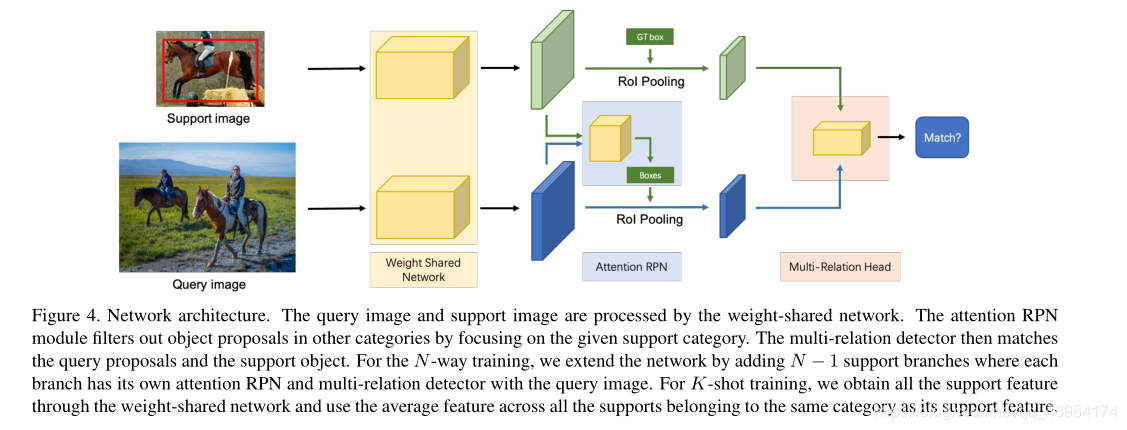
网络包含三个部分:
1. 多分支共享权重网络(K-1个Support Image和1个Query Image)
2. 注意力RPN模块
3. 多关系检测头
基于注意力的RPN网络
文章指出在Two-stage框架中RPN模块不仅要区分出前景和背景,还要过滤掉不属于Support类别的父负面对象。在没有任何Support对象信息的情况下,即使不属于Support类别,RPN模块也会漫无目的得激活每个可能时潜在目标的对象,从而给检测器的后续分类任务带来大量无关对象的负担。为此作者提出了注意力RPN,利用Support信息过滤掉大多数背景框和不匹配类别的框,更小更精确的生成Region Proposal。
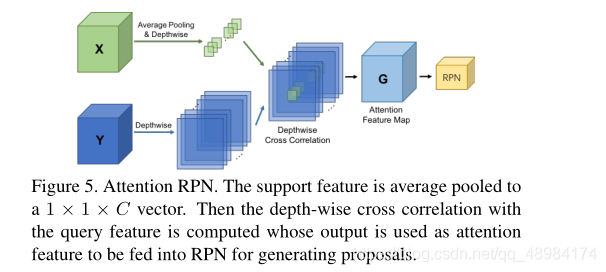
其中X为 Support Feature,Y为Query Feature
具体操作为:1. X进行平均池化操作后再深度卷积,将通道信息分隔开 2. Y进行深度卷积将通道信息分割开 3. 使用深度卷积后的X对深度卷积后的Y进行卷积操作,生成深度互相关特征图。之后进行RPN操作。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FAqSJ56i-1617435449951)(C:\Users\lab519\AppData\Roaming\Typora\typora-user-images\image-20210403145918496.png)]
本文工作中,使用ResNet50中的res4_6特征,并且发现kernel size =1时效果较好,解释为全局特征的一致性能够提供一个好的目标先验知识,因此采用了Average Pooling的方式。
多关系检测头
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ejK2W6Lq-1617435449953)(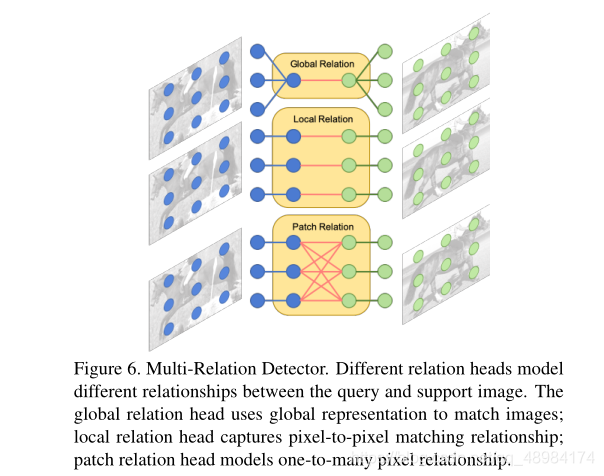
)]
检测器包含三个注意力模块:
- global-relation head:用于学习一个全局匹配的深度特征
- local-correlation head:用于学习Support和Query之间的pixel-wise和depth-wise互相关性
- patch-relation head:学习patch匹配的深度非线性度量
双向对比训练策略
常见的训练策略是构建一个训练对(qc,sc)来匹配相同类别对象,其中查询图像qc和支持图像sc属于相同的类别。本文提出一个好的模型不仅要匹配相同的类别对象,还要区分不同的类别,为此,提出了一种新颖的双向对比训练策略。
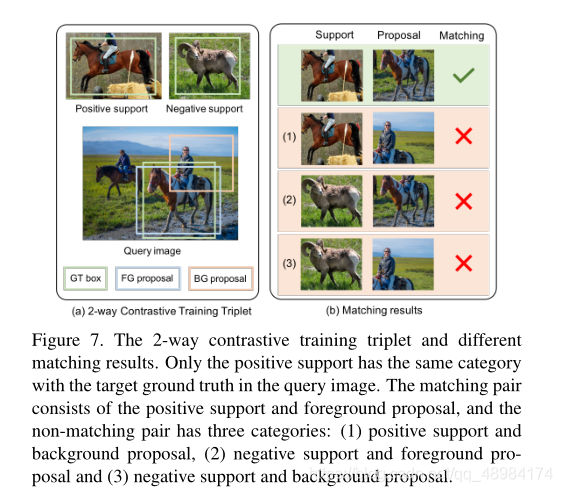
本文送入训练三元组(qc,sc,sn),其中c!=n。在这个三元组中,只有第c类目标被标记为前景,其他的均为背景。
由于在训练中,模型需要去将每一个 query Image生成的proposal和support的目标匹配,因此模型不仅能学习到相同类别目标,也能区别不同类别目标。然而训练中会产生大量的背景框,因此设置了query proposal和supports的比例。其中前景和正例(pf😒p):背景和正例(pb,sp):推荐框和反例(p,sn)=1 : 2 : 1。在训练过程中采用多任务巡视L=Lmatching+Lbox
Appendix
Appendix A: Implementation Details of Multi-Relation Detector
Given the support feature fs and query proposal feature fq with the size of 7 × 7 × C, our multi-relation detector is implemented as follows. We use the sum of all matching scores from the three heads as the final matching scores.
Global-Relation Head We concatenatefs and fq to the concatenated feature fc with the size of 7 × 7 × 2C. Then we average pool fc to a 1 × 1 × 2C vector. We then use an MLP with two fully connected (fc) layers with ReLU and a final fc layer to process fc and generate matching scores.
Local-Relation Head We first use a weight-shared 1 × 1 × C convolution to process fsand fq separately. Then we calculate the depth-wise similarity using the equation in
Section 4.2.1 of the main paper with S = H = W = 7. Then we use a fc layer to generate matching scores.
Patch-Relation Head We first concatenate fs and fq to the concatenated feature fc with the size of 7×7×2C. Then fc is fed into the patch-relation module, whose structure is shown in Table 8. All the convolution layers followed by ReLU and pooling layers in this module have zero padding to reduce the feature map size from 7×7 to 1×1. Then we use a fc layer to generate matching scores and a separate fc layer to generate bounding box predictions.














 1003
1003











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









