







CSP结构
Applying CSPNet to ResNe(X)t
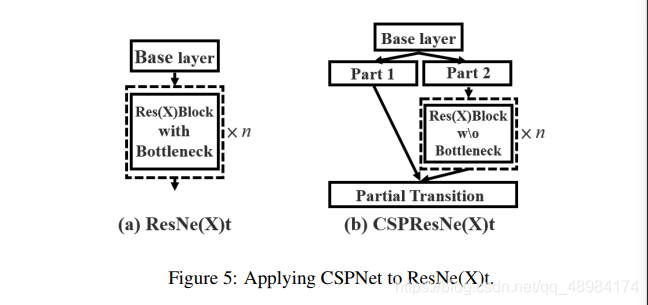
原文如此介绍:设计出Partial transition layers的目的是最大化梯度联合的差异。其使用梯度流截断的手段避免不同的层学习到重复的梯度信息。得出的结论是,如果能够有效的减少重复的梯度学习,那么网络的学习能力能够大大提升.
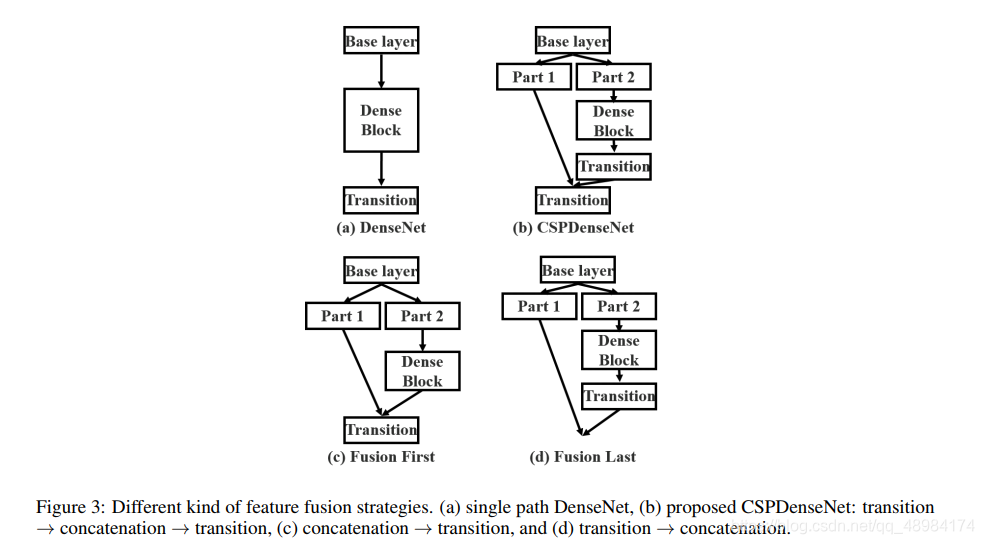
Applying CSPNet to DenseNet
DarkNet53介绍
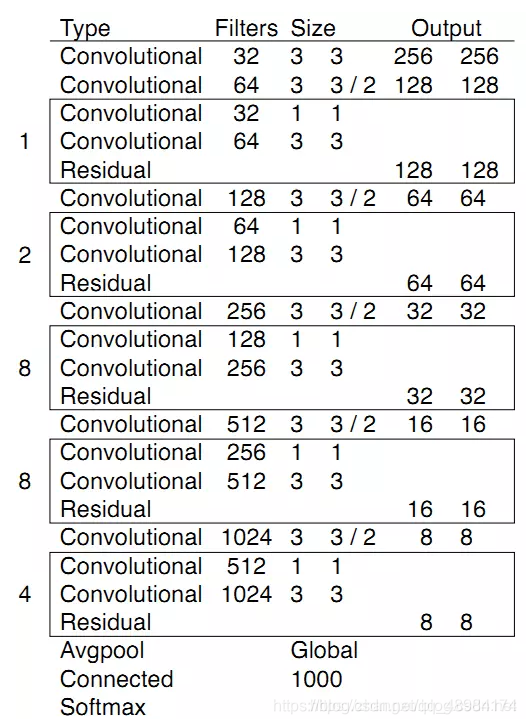
由上我们可以对比ResNet50得出其使用了kernel_size=3,stride=1的卷积代替了kernel_size=7,stride=1的卷积,减少了计算量。使用了kernel_size=3,stride=1的卷积代替了maxpool,因此作者认为Max-Pooling降采样会使得输出变得“高频高幅”,因此在后面会导致网格效应。此外DarkNet含有5个Residual相比于Resnet的4个stage,其中Residual Block中分支路使用的为kernel_size=1,kernel_size=3,stride=1的Conv,注意此处并没有进行降采样,而是在concat操作后stride=2的卷积进行下采样。
CSPDarknet53架构
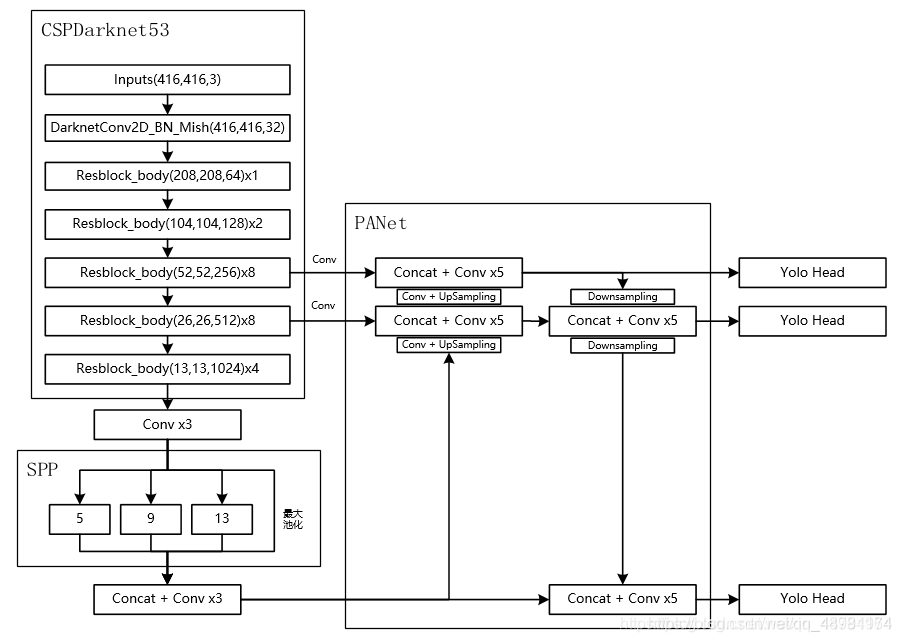
采用博主@Bubbliiiing的YOLOV4实现讲解
import torch
import torch.nn.functional as F
import 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7638
7638

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









