







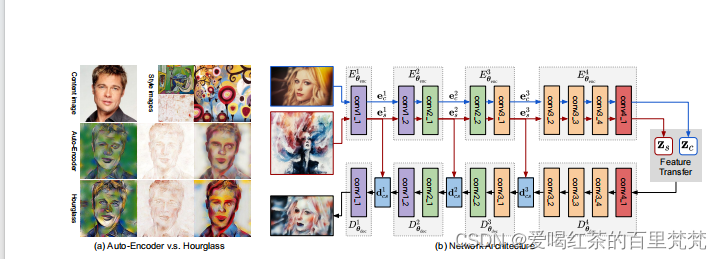
论文中的模型的结构图
一、编码器
看论文中的结构图,编码器应该是有很多个编码块组成的,这些块都是vgg19的一部分,所以编码器可以理解为是vgg19的前21层。
class Encoder(nn.Module):
def __init__(self, layers=[1, 6, 11, 20]):
super(Encoder, self).__init__()
vgg = torchvision.models.vgg19(pretrained=True).features
self.encoder = nn.ModuleList()
temp_seq = nn.Sequential()
for i in range(max(layers) + 1):
temp_seq.add_module(str(i), vgg[i])
if i in layers:
self.encoder.append(temp_seq)
temp_seq = nn.Sequential()
def forward(self, x):
features = []
for layer in self.encoder:
x = layer(x)
features.append(x)
return features
编码器的结构如下:

二、风格装饰器
论文的一大创新点,论文中他的作用就是为内容补丁匹配语义最相近的风格补丁快,论文中分为三部分来解释。
1、补丁
将图片分成一个一个的补丁
def extract_patches(feature, patch_size, stride):
ph, pw = patch_size # 获取图像块的大小 (高度, 宽度)
sh, sw = stride # 获取滑动窗口的步长 (垂直方向, 水平方向)
# 填充特征
padh = (ph - 1) // 2 # 计算垂直方向上的填充大小
padw = (pw - 1) // 2 # 计算水平方向上的填充大小
padding_size = (padw, padw, padh, padh) # 定义填充大小为 (左, 右, 上, 下)
feature = F.pad(feature, padding_size, 'constant', 0) # 使用指定的填充大小和常数0对特征进行填充
# 提取图像块
patches = feature.unfold(2, ph, sh).unfold(3, pw, sw) # 使用给定的图像块大小和步长在特征上进行滑动窗口提取
patches = patches.contiguous().view(*patches.size()[:-2], -1) # 重塑图像块张量,将最后两个维度展平为一个维度
return patches # 返回提取的图像块张量
1、投影
import torch
def covsqrt_mean(feature, inverse=False, tolerance=1e-14):
# I referenced the default svd tolerance value in matlab.
b, c, h, w = feature.size()
mean = torch.mean(feature.view(b, c, -1), dim=2, keepdim=True)
zeromean = feature.view(b, c, -1) - mean
cov = torch.bmm(zeromean, zeromean.transpose(1, 2))
evals, evects = torch.symeig(cov, eigenvectors=True)
p = 0.5
if inverse:
p *= -1
covsqrt = []
for 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 809
809











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









