







source format is jupyter, converted by nbconvert project.
1.手动回归
基本情况说明
数据集为按照实验要求人工生成,手动实现和利用torch.nn实现的,数据集相同
基本代码思路主要按照课程上讲解思路和实验指导中的代码示例,比较简单,不详细展开
# 生成数据集
import torch.nn
import torch
import torchvision
import numpy as np
def synthetic_data(w, b, num_examples):
X = torch.normal(0, 0.01, (num_examples, len(w)))
y = torch.matmul(X, w) + b
y += torch.normal(0, 0.01, y.shape)
return X, y.reshape((-1, 1))
true_w = torch.ones((500, 1)) * 0.0056
true_b = 0.028
features, labels = synthetic_data(true_w, true_b, 10000)
features.shape
torch.Size([10000, 500])
import random
def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples))
random.shuffle(indices)
for i in range(0, num_examples, batch_size):
batch_indices = torch.tensor(indices[i: min(i+ batch_size, num_examples)])
yield features[batch_indices], labels[batch_indices]
def train_test_split_simple(features, lables, train_size):
num_example = len(features)
indices = list(range(num_example))
random.shuffle(indices)
return features[indices[0:int(num_example*train_size)]], features[indices[int(num_example*(train_size)):]], \
lables[indices[0:int(num_example*train_size)]], lables[indices[int(num_example*train_size):]]
x_train, x_test, y_train, y_test = train_test_split_simple(features, labels, train_size=0.7)
print(x_train.shape)
print(x_test.shape)
print(y_train.shape)
print(y_test.shape)
torch.Size([7000, 500])
torch.Size([3000, 500])
torch.Size([7000, 1])
torch.Size([3000, 1])
w = torch.normal(0, 0.01, size=(500, 1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
def NetLinearRegression(X, w, b):
z = torch.matmul(X, w) + b
# activation func Relu
a = torch.max(input=z, other=torch.tensor(0.0))
return a
# 线性回归使用均方损失
def squared_loss(y_hat, y):
# print(y_hat.shape)
# print(y.shape)
return (y_hat - y.reshape(y_hat.shape)) ** 2 / 2
# mini batch random gradient descent
def sgd(params, lr, batch_size):
with torch.no_grad():
for param in params:
param.data -= lr * param.grad / batch_size
param.grad.zero_()
print(x_train.shape)
print(y_train.shape)
torch.Size([7000, 500])
torch.Size([7000, 1])
class NetNeuralNetwork:
def __init__(self, num_input, num_hidden, num_output):
W1 = torch.tensor(np.random.normal(0, 0.01,(num_hidden, num_input)), dtype=torch.float32, requires_grad=True)
b1 = torch.zeros(num_hidden, dtype=torch.float32, requires_grad=True)
W2 = torch.tensor(np.random.normal(0,0.01, (num_output, num_hidden)), dtype=torch.float32, requires_grad=True)
b2 = torch.zeros(num_output, dtype=torch.float32, requires_grad=True)
self.input_layer = lambda x: x.view(x.shape[0], -1)
self.hidden_layer = lambda x: self.my_Relu(torch.matmul(x, W1.t()) + b1)
self.output_layer = lambda x: torch.matmul(x, W2.t()) + b2
self.params = [W1, b1, W2, b2]
def my_Relu(self, x):
return torch.max(input=x, other=torch.tensor(0.0))
def forward(self,x):
flatten_input = self.input_layer(x)
hidden_output = self.hidden_layer(flatten_input)
final_output = self.output_layer(hidden_output)
return final_output
def my_cross_entropy_loss(y_hat, labels):
def log_softmax(y_hat):
max_v = torch.max(y_hat, dim=1).values.unsqueeze(dim=1)
return y_hat-max_v - torch.log(torch.exp(y_hat-max_v).sum(dim=1)).unsqueeze(dim=1)
return (-log_softmax(y_hat))[range(len(y_hat)), labels].mean()
def evaluate_accuracy_classifier(data_iter, model, loss_func):
acc_sum, test_l_sum, n, c = 0.0, 0.0, 0, 0
for X, y in data_iter:
result = model.forward(X)
acc_sum += (result.argmax(dim=1) == y).float().sum().item()
test_l_sum += loss_func(result, y).item()
n += y.shape[0]
c += 1
return acc_sum/n, test_l_sum/c
print(x_train.shape)
print(w.shape)
print(NetLinearRegression(x_train, w, b))
torch.Size([7000, 500])
torch.Size([500, 1])
tensor([[0.0007],
[0.0009],
[0.0000],
...,
[0.0000],
[0.0000],
[0.0011]], grad_fn=<MaximumBackward0>)
import time
import matplotlib.pyplot as plt
w = torch.normal(0, 0.01, size=(500, 1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
def train_regress(net, loss, x_train, x_test, y_train, y_test, epochs, lr, batch_size, name_net):
train_loss_ls = []
test_loss_ls = []
for epoch in range(epochs):
for X, y in data_iter(batch_size, x_train, y_train):
# print(y_train.shape)
y_hat = net.forward(X)
l = loss(y_hat, y)
# print(y_hat)
l.sum().backward()
# todo
sgd(net.params, lr, batch_size)
with torch.no_grad():
# need to be summed
train_loss = loss(net.forward(x_train), y_train).mean()
test_loss = loss(net.forward(x_test), y_test).mean()
train_loss_ls.append(train_loss)
test_loss_ls.append(test_loss)
print('epochs', "%d" %(epoch+1), "train_loss", "%.4f" %train_loss, "test_loss", "%.4f"%test_loss)
plt.title(name_net)
plt.plot(train_loss_ls, label='train_loss')
plt.plot(test_loss_ls, label='test_loss')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend()
plt.show()
lr = 0.01
epochs = 10
net = NetNeuralNetwork(500, 256, 1)
loss = squared_loss
batch_size = 100
start = time.time()
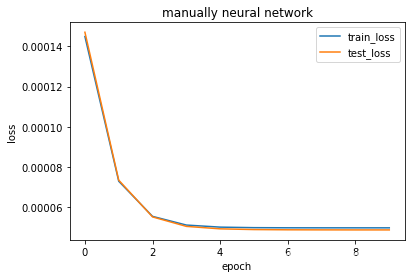
train_regress(net, loss, x_train, x_test, y_train, y_test, epochs, lr, batch_size, "manually neural network")
end = time.time()
print("running time", (end-start))
epochs 1 train_loss 0.0001 test_loss 0.0001
epochs 2 train_loss 0.0001 test_loss 0.0001
epochs 3 train_loss 0.0001 test_loss 0.0001
epochs 4 train_loss 0.0001 test_loss 0.0001
epochs 5 train_loss 0.0001 test_loss 0.0000
epochs 6 train_loss 0.0000 test_loss 0.0000
epochs 7 train_loss 0.0000 test_loss 0.0000
epochs 8 train_loss 0.0000 test_loss 0.0000
epochs 9 train_loss 0.0000 test_loss 0.0000
epochs 10 train_loss 0.0000 test_loss 0.0000
running time 1.7815287113189697
实验结果说明:
回归任务直接用均方误差的结果表现精度。具体结果见上图。
2.torch.nn实现回归
import torch.nn as nn
import torch
class NetNeuralNetworkWithNN:
def __init__(self, num_input, num_hidden, num_output):
self.layer = nn.Sequential(
nn.Flatten(),
nn.Linear(num_input, num_hidden),
nn.ReLU(),
nn.Linear(num_hidden, num_output)
)
for m in self.layer:
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
def forward(self, x):
return self.layer(x)
def train_regress_withNN(net, loss, x_train, x_test, y_train, y_test, epochs, batch_size, optimizer,name_net):
train_loss_ls = []
test_loss_ls = []
for epoch in range(epochs):
for X, y in data_iter(batch_size, x_train, y_train):
# print(y_train.shape)
optimizer.zero_grad()
y_hat = net.forward(X)
l = loss(y_hat, y)
# print(l)
# print(y_hat)
l.backward()
# todo
optimizer.step()
with torch.no_grad():
# need to be summed
train_loss = loss(net.forward(x_train), y_train).mean()
test_loss = loss(net.forward(x_test), y_test).mean()
train_loss_ls.append(train_loss)
test_loss_ls.append(test_loss)
print('epochs', "%d" %(epoch+1), "train_loss", "%.4f" %train_loss, "test_loss", "%.4f"%test_loss)
plt.title(name_net)
plt.plot(train_loss_ls, label='train_loss')
plt.plot(test_loss_ls, label='test_loss')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend()
plt.show()
import time
lr = 0.01
epochs = 10
net = NetNeuralNetworkWithNN(500, 256, 1)
loss = nn.MSELoss()
start = time.time()
optimizer = torch.optim.SGD(params=net.layer.parameters(), lr=lr)
batch_size = 100
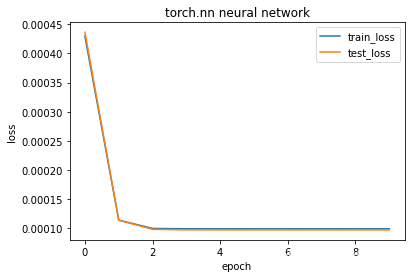
train_regress_withNN(net, loss, x_train, x_test, y_train, y_test, epochs, batch_size, optimizer, "torch.nn neural network")
end = time.time()
print("running time", (end-start))
epochs 1 train_loss 0.0004 test_loss 0.0004
epochs 2 train_loss 0.0001 test_loss 0.0001
epochs 3 train_loss 0.0001 test_loss 0.0001
epochs 4 train_loss 0.0001 test_loss 0.0001
epochs 5 train_loss 0.0001 test_loss 0.0001
epochs 6 train_loss 0.0001 test_loss 0.0001
epochs 7 train_loss 0.0001 test_loss 0.0001
epochs 8 train_loss 0.0001 test_loss 0.0001
epochs 9 train_loss 0.0001 test_loss 0.0001
epochs 10 train_loss 0.0001 test_loss 0.0001
running time 1.26399564743042
3.手动二分类
3.1 基本函数编写
import torch
import torch.nn as nn
x_positive = torch.normal(mean=1.0, std=0.01, size=(10000, 200), dtype=torch.float32)
x_negative = torch.normal(mean=-1.0, std=0.01, size=(10000, 200), dtype=torch.float32)
y_positive = torch.ones(size=(10000, 1), dtype=torch.int32)
y_negative = torch.zeros(size=(10000, 1), dtype=torch.int32)
X = torch.cat([x_positive, x_negative], dim=0)
Y = torch.cat([y_positive, y_negative], dim=0)
def train_test_split_simple(features, lables, train_size):
num_example = len(features)
indices = list(range(num_example))
random.shuffle(indices)
return features[indices[0:int(num_example*train_size)]], features[indices[int(num_example*(train_size)):]], \
lables[indices[0:int(num_example*train_size)]], lables[indices[int(num_example*train_size):]]
x_train, x_test, y_train, y_test = train_test_split_simple(X, Y, train_size=0.7)
class NetBinaryClassifier:
def __init__(self, num_input, num_hidden, num_output, last_act="Relu"):
W1 = torch.tensor(np.random.normal(0, 0.01,(num_hidden, num_input)), dtype=torch.float32, requires_grad=True)
b1 = torch.zeros(num_hidden, dtype=torch.float32, requires_grad=True)
W2 = torch.tensor(np.random.normal(0,0.01, (num_output, num_hidden)), dtype=torch.float32, requires_grad=True)
b2 = torch.zeros(num_output, dtype=torch.float32, requires_grad=True)
self.input_layer = lambda x: x.view(x.shape[0], -1)
self.hidden_layer = lambda x: self.my_Relu(torch.matmul(x, W1.t()) + b1)
self.output_layer = lambda x: torch.matmul(x, W2.t()) + b2
self.params = [W1, b1, W2, b2]
self.last_act = last_act
def my_Relu(self, x):
return torch.max(input=x, other=torch.tensor(0.0))
def forward(self,x):
flatten_input = self.input_layer(x)
hidden_output = self.hidden_layer(flatten_input)
final_output = self.output_layer(hidden_output)
if self.last_act == "Sigmoid":
final_output = torch.sigmoid(final_output)
else:
final_output = self.my_Relu(final_output)
return final_output
def evaluate_acc_binary_classifier(y_hat:torch.tensor, y):
def change(x):
if x>=0.5:
return 1
else:
return 0
result = y_hat.apply_(change)
# print(result)
# print(y==result)
acc = (result==y).float().sum().item()/ y.shape[0]
# print(acc)
return acc
def CrossEntropy_my(y_hat, y):
# print(y_hat)
# y_hat = torch.clamp(y_hat, 1e-20, 1-(1e-20))
result = -y*torch.log(y_hat) - (1-y)*torch.log(1-y_hat)
return result
def train_binary_classifier(net, loss, x_train, x_test, y_train, y_test, epochs, lr, batch_size,eval, name_net, ):
def forward(x):
y_hat = x
for i in net:
y_hat = i.forward(y_hat)
return y_hat
def get_params(net):
param_ls = []
for i in net:
param_ls += i.params
return param_ls
train_loss_ls = []
test_loss_ls = []
acc_test_ls = []
acc_train_ls = []
for epoch in range(epochs):
for X, y in data_iter(batch_size, x_train, y_train):
y_hat = forward(X)
l = loss(y_hat, y).sum()
l.backward()
sgd(get_params(net), lr, batch_size)
with torch.no_grad():
# need to be summed
y_hat = forward(x_train)
acc_train = eval(y_hat, y_train)
train_loss = loss(y_hat, y_train).mean()
y_hat = forward(x_test)
test_loss = loss(y_hat, y_test).mean()
acc_test = eval(y_hat, y_test)
# train_loss = torch.clamp(train_loss, 1e-10, 1)
train_loss_ls.append(train_loss)
test_loss_ls.append(test_loss)
acc_train_ls.append(acc_train)
acc_test_ls.append(acc_test)
print('epochs', "%d" % (epoch + 1), "train_loss", "%.4f" % train_loss, "test_loss", "%.4f" % test_loss, "train_acc","%.4f"%acc_train, "test_acc", "%.4f"%acc_test)
# print("try acc", accuracy_score(y_test, y_hat))
plt.title(name_net)
plt.plot(train_loss_ls, label='train_loss')
plt.plot(test_loss_ls, label='test_loss')
plt.plot(acc_train_ls, label='acc_train')
plt.plot(acc_test_ls, label='acc_test')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend()
plt.show()
# print(train_loss_ls)
3.2 采用交叉熵损失
3.2.1 调用模块
import time
start = time.time()
lr = 0.1
epochs = 20
net1 = NetBinaryClassifier(200, 150, 100)
net2 = NetBinaryClassifier(100, 50, 1, "Sigmoid")
loss = CrossEntropy_my
net = [net1, net2]
batch_size = 100
eval = evaluate_acc_binary_classifier
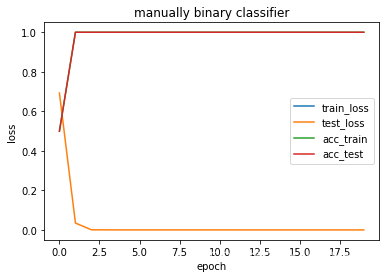
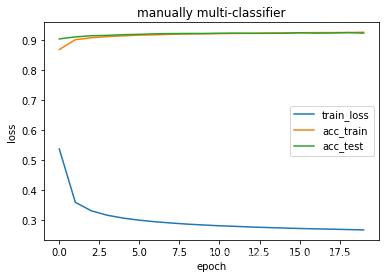
train_binary_classifier(net, loss, x_train, x_test, y_train, y_test, epochs, lr, batch_size, eval, "manually binary classifier")
end = time.time()
print("running time", (end-start))
epochs 1 train_loss nan test_loss 0.6925 train_acc 0.5004 test_acc 0.4990
epochs 2 train_loss nan test_loss 0.0347 train_acc 1.0000 test_acc 1.0000
epochs 3 train_loss nan test_loss 0.0006 train_acc 1.0000 test_acc 1.0000
epochs 4 train_loss nan test_loss 0.0003 train_acc 1.0000 test_acc 1.0000
epochs 5 train_loss nan test_loss 0.0002 train_acc 1.0000 test_acc 1.0000
epochs 6 train_loss nan test_loss 0.0001 train_acc 1.0000 test_acc 1.0000
epochs 7 train_loss nan test_loss 0.0001 train_acc 1.0000 test_acc 1.0000
epochs 8 train_loss nan test_loss 0.0001 train_acc 1.0000 test_acc 1.0000
epochs 9 train_loss nan test_loss 0.0001 train_acc 1.0000 test_acc 1.0000
epochs 10 train_loss nan test_loss 0.0000 train_acc 1.0000 test_acc 1.0000
epochs 11 train_loss nan test_loss 0.0000 train_acc 1.0000 test_acc 1.0000
epochs 12 train_loss nan test_loss 0.0000 train_acc 1.0000 test_acc 1.0000
epochs 13 train_loss nan test_loss 0.0000 train_acc 1.0000 test_acc 1.0000
epochs 14 train_loss nan test_loss 0.0000 train_acc 1.0000 test_acc 1.0000
epochs 15 train_loss nan test_loss 0.0000 train_acc 1.0000 test_acc 1.0000
epochs 16 train_loss nan test_loss 0.0000 train_acc 1.0000 test_acc 1.0000
epochs 17 train_loss nan test_loss 0.0000 train_acc 1.0000 test_acc 1.0000
epochs 18 train_loss nan test_loss 0.0000 train_acc 1.0000 test_acc 1.0000
epochs 19 train_loss nan test_loss 0.0000 train_acc 1.0000 test_acc 1.0000
epochs 20 train_loss nan test_loss 0.0000 train_acc 1.0000 test_acc 1.0000
running time 6.170657396316528
3.2.2交叉熵损失结果分析
交叉熵损失中中调用torch.log 函数 可以出现超出定义域的情况,所以train loss 为nan> 结果说明:
结果回顾时,才发现分类任务中加入了 所谓和回归任务中一样的test loss,实际是不需要的,特此说明。
3.3 采用均方误差损失
3.3.1 调用模块
import time
start = time.time()
lr = 0.1
epochs = 20
net1 = NetBinaryClassifier(200, 150, 100)
net2 = NetBinaryClassifier(100, 50, 1, "Sigmoid")
loss = squared_loss
net = [net1, net2]
batch_size = 100
eval = evaluate_acc_binary_classifier
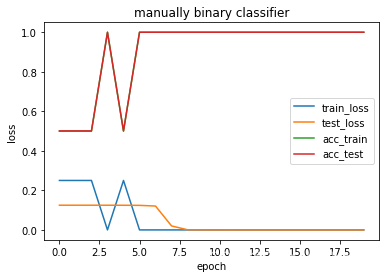
train_binary_classifier(net, loss, x_train, x_test, y_train, y_test, epochs, lr, batch_size, eval, "manually binary classifier")
end = time.time()
print("running time", (end- start))
epochs 1 train_loss 0.2502 test_loss 0.1250 train_acc 0.4996 test_acc 0.5010
epochs 2 train_loss 0.2502 test_loss 0.1250 train_acc 0.4996 test_acc 0.5010
epochs 3 train_loss 0.2502 test_loss 0.1249 train_acc 0.4996 test_acc 0.5010
epochs 4 train_loss 0.0000 test_loss 0.1249 train_acc 1.0000 test_acc 1.0000
epochs 5 train_loss 0.2502 test_loss 0.1247 train_acc 0.4996 test_acc 0.5010
epochs 6 train_loss 0.0000 test_loss 0.1242 train_acc 1.0000 test_acc 1.0000
epochs 7 train_loss 0.0000 test_loss 0.1208 train_acc 1.0000 test_acc 1.0000
epochs 8 train_loss 0.0000 test_loss 0.0202 train_acc 1.0000 test_acc 1.0000
epochs 9 train_loss 0.0000 test_loss 0.0006 train_acc 1.0000 test_acc 1.0000
epochs 10 train_loss 0.0000 test_loss 0.0002 train_acc 1.0000 test_acc 1.0000
epochs 11 train_loss 0.0000 test_loss 0.0001 train_acc 1.0000 test_acc 1.0000
epochs 12 train_loss 0.0000 test_loss 0.0001 train_acc 1.0000 test_acc 1.0000
epochs 13 train_loss 0.0000 test_loss 0.0001 train_acc 1.0000 test_acc 1.0000
epochs 14 train_loss 0.0000 test_loss 0.0001 train_acc 1.0000 test_acc 1.0000
epochs 15 train_loss 0.0000 test_loss 0.0000 train_acc 1.0000 test_acc 1.0000
epochs 16 train_loss 0.0000 test_loss 0.0000 train_acc 1.0000 test_acc 1.0000
epochs 17 train_loss 0.0000 test_loss 0.0000 train_acc 1.0000 test_acc 1.0000
epochs 18 train_loss 0.0000 test_loss 0.0000 train_acc 1.0000 test_acc 1.0000
epochs 19 train_loss 0.0000 test_loss 0.0000 train_acc 1.0000 test_acc 1.0000
epochs 20 train_loss 0.0000 test_loss 0.0000 train_acc 1.0000 test_acc 1.0000
running time 6.602993726730347
3.3.2 均方误差结果分析
均方误差不会出现nan的情况,但是相对于交叉熵损失,收敛比较慢,均方是6.6s,交叉熵为6.2s。而且,均方损失不够稳定,图像上下跳跃。
4. torch.nn实现二分类
4.1 基本代码编写
import torch
import torch.nn as nn
import random
x_positive = torch.normal(mean=100.0, std=0.01, size=(10000, 200), dtype=torch.float32)
x_negative = torch.normal(mean=-100.0, std=0.01, size=(10000, 200), dtype=torch.float32)
y_positive = torch.ones(size=(10000, 1), dtype=torch.float32)
y_negative = torch.zeros(size=(10000, 1), dtype=torch.float32)
X = torch.cat([x_positive, x_negative], dim=0)
Y = torch.cat([y_positive, y_negative], dim=0)
def train_test_split_simple(features, lables, train_size):
num_example = len(features)
indices = list(range(num_example))
random.shuffle(indices)
return features[indices[0:int(num_example*train_size)]], features[indices[int(num_example*(train_size)):]], \
lables[indices[0:int(num_example*train_size)]], lables[indices[int(num_example*train_size):]]
x_train, x_test, y_train, y_test = train_test_split_simple(X, Y, train_size=0.7)
def evaluate_acc_binary_classifier(y_hat:torch.tensor, y):
def change(x):
with torch.no_grad():
if x>=0.5:
return 1
else:
return 0
with torch.no_grad():
result = y_hat.detach().apply_(change)
# print(result)
# print(y==result)
acc = (result==y).float().sum()/ y.shape[0]
# print(acc)
return acc.item()
import random
def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples))
random.shuffle(indices)
for i in range(0, num_examples, batch_size):
batch_indices = torch.tensor(indices[i: min(i+ batch_size, num_examples)])
yield features[batch_indices], labels[batch_indices]
def train_binary_classifier_withNN(net, loss, x_train, x_test, y_train, y_test, epochs, batch_size,optimizer,eval, name_net):
train_loss_ls = []
# test_loss_ls = []
acc_test_ls = []
acc_train_ls = []
for epoch in range(epochs):
for X, y in data_iter(batch_size, x_train, y_train):
y_hat = net(X)
# print(y_hat[:, 0])
l = loss(y_hat, y).mean()
optimizer.zero_grad()
l.backward()
optimizer.step()
with torch.no_grad():
# need to be summed
y_hat = net(x_train)
train_loss = loss(y_hat, y_train).mean()
acc_train = eval(y_hat, y_train)
y_hat = net(x_test)
# test_loss = loss(y_hat, y_test).mean()
acc_test = eval(y_hat, y_test)
train_loss_ls.append(train_loss)
# test_loss_ls.append(test_loss)
acc_train_ls.append(acc_train)
acc_test_ls.append(acc_test)
# print('epochs', "%d" % (epoch + 1), "train_loss", "%.4f" % train_loss, "test_loss", "%.4f" % test_loss, "train_acc","%.4f"%acc_train, "test_acc", "%.4f"%acc_test)
print('epochs', epoch+1, "train_loss", train_loss.item(), "train_acc", acc_train, "test_loss", acc_test)
plt.title(name_net)
plt.plot(train_loss_ls, label='train_loss')
# plt.plot(test_loss_ls, label='test_loss')
plt.plot(acc_train_ls, label='acc_train')
plt.plot(acc_test_ls, label='acc_test')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend()
plt.show()
4.2 函数调用
4.2.1 调用模块
import time
import matplotlib.pyplot as plt
NetBinaryClassifierWithNN = nn.Sequential(
nn.Flatten(),
nn.Linear(200, 1),
nn.Sigmoid()
)
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
NetBinaryClassifierWithNN.apply(init_weights)
start = time.time()
lr = 0.1
epochs = 10
net = NetBinaryClassifierWithNN
loss = nn.BCELoss(reduction='none')
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
batch_size = 100
eval = evaluate_acc_binary_classifier
train_binary_classifier_withNN(net, loss, x_train, x_test, y_train, y_test, epochs, batch_size, optimizer, eval,'torch.nn binary classifier')
end= time.time()
print("running time", (end-start))
epochs 1 train_loss 2.971291479525462e-08 train_acc 1.0 test_loss 1.0
epochs 2 train_loss 0.0 train_acc 1.0 test_loss 1.0
epochs 3 train_loss 0.0 train_acc 1.0 test_loss 1.0
epochs 4 train_loss 0.0 train_acc 1.0 test_loss 1.0
epochs 5 train_loss 0.0 train_acc 1.0 test_loss 1.0
epochs 6 train_loss 0.0 train_acc 1.0 test_loss 1.0
epochs 7 train_loss 0.0 train_acc 1.0 test_loss 1.0
epochs 8 train_loss 0.0 train_acc 1.0 test_loss 1.0
epochs 9 train_loss 0.0 train_acc 1.0 test_loss 1.0
epochs 10 train_loss 0.0 train_acc 1.0 test_loss 1.0
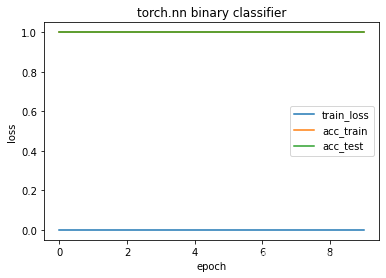
running time 1.3989982604980469
4.2.2 结果分析
在第一个epoch中即可做到完全拟合,人工数据集还是比较好拟合。这里的情况比较特殊,本人采用了下边的模块进行辨析。
def train_binary_classifier_withNN_try(net, loss, x_train, x_test, y_train, y_test, epochs, batch_size,optimizer,eval, name_net):
train_loss_ls = []
# test_loss_ls = []
acc_test_ls = []
acc_train_ls = []
for epoch in range(epochs):
for X, y in data_iter(batch_size, x_train, y_train):
y_hat = net(X)
print(y_hat) # 输出
l = loss(y_hat, y).mean()
optimizer.zero_grad()
l.backward()
optimizer.step()
with torch.no_grad():
# need to be summed
y_hat = net(x_train)
train_loss = loss(y_hat, y_train).mean()
acc_train = eval(y_hat, y_train)
y_hat = net(x_test)
# test_loss = loss(y_hat, y_test).mean()
acc_test = eval(y_hat, y_test)
train_loss_ls.append(train_loss)
# test_loss_ls.append(test_loss)
acc_train_ls.append(acc_train)
acc_test_ls.append(acc_test)
# print('epochs', "%d" % (epoch + 1), "train_loss", "%.4f" % train_loss, "test_loss", "%.4f" % test_loss, "train_acc","%.4f"%acc_train, "test_acc", "%.4f"%acc_test)
print('epochs', epoch+1, "train_loss", train_loss.item(), "train_acc", acc_train, "test_loss", acc_test)
plt.title(name_net)
plt.plot(train_loss_ls, label='train_loss')
# plt.plot(test_loss_ls, label='test_loss')
plt.plot(acc_train_ls, label='acc_train')
plt.plot(acc_test_ls, label='acc_test')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend()
plt.show()
NetBinaryClassifierWithNN = nn.Sequential(
nn.Flatten(),
nn.Linear(200, 1),
nn.Sigmoid()
)
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
NetBinaryClassifierWithNN.apply(init_weights)
start = time.time()
lr = 0.1
epochs = 1 # 只遍历一次
net = NetBinaryClassifierWithNN
loss = nn.BCELoss(reduction='none')
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
batch_size = 100
eval = evaluate_acc_binary_classifier
train_binary_classifier_withNN(net, loss, x_train, x_test, y_train, y_test, epochs, batch_size, optimizer, eval,'torch.nn binary classifier')
end= time.time()
print("running time", (end-start))
epochs 1 train_loss 0.0 train_acc 1.0 test_loss 1.0
running time 0.8002612590789795
4.2.3 具体情况分析
这里我们把 epoch 改成1,在y_hat后边输出,这样就可以知道计算出的y_hat,发现几个小batch_size之后就可以发现数据完成变成了0或1,这就解释了为什么acc 是1.0
5.手动实现多分类
5.1 基本函数编写
!nvidia-smi
Tue Oct 25 00:40:14 2022
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |
| N/A 54C P8 10W / 70W | 0MiB / 15109MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
train_datasets = torchvision.datasets.MNIST(root=f"../Datasets/MNIST/", train=True, transform= transforms.ToTensor(), download=True)
test_datasets = torchvision.datasets.MNIST(root=f"../Datasets/MNIST", train=False, transform= transforms.ToTensor(), download=True)
train_loader = torch.utils.data.DataLoader(train_datasets, batch_size=32, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_datasets, batch_size=32, shuffle=False)
num_inputs = 784 #image of fashion minst is 28*28
num_outputs = 10 # and the num of class is 10
W = torch.normal(0, 0.01, size=(num_inputs, num_outputs), requires_grad=True)
b = torch.zeros(num_outputs, requires_grad=True)
def softmax(X):
X_exp = torch.exp(X)
return X_exp / X_exp.sum(1, keepdim=True)
def net(X):
return softmax(torch.matmul(X.reshape((-1, W.shape[0])), W) + b)
def cross_entropy(y_hat, y):
return (- torch.log(y_hat[range(len(y_hat)), y]))
# to gain a scalar
# for-loop is slow. we use a slice of y_hat to gain the all right class' prob, then log them.
def accuracy(y_hat, y):
if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:
y_hat = y_hat.argmax(axis=1)
result = y_hat.type(y.dtype) == y
# op== is very sensitive with data type, so call tensor.type() to stay the same with y
return float(result.type(y.dtype).sum())/len(y)
def mysgd(params, lr, batch_size):
with torch.no_grad():
for param in params:
param -= lr * param.grad / batch_size
param.grad.zero_()
def eval_acc(net, data_iter):
result = []
with torch.no_grad():
for X, y in data_iter:
result.append(accuracy(net(X), y))
return np.array(result).mean()
import numpy as np
import matplotlib.pyplot as plt
import time
def train_muticlassifier(net, loss, train_loader, test_loader, epochs, batch_size, optimizer,name_net):
train_loss_ls = []
# test_loss_ls = []
acc_test_ls = []
acc_train_ls = []
for epoch in range(epochs):
l_sum = 0.0
num = 0
acc =0.0
for X, y in train_loader:
y_hat = net(X)
l = loss(y_hat, y)
acc += accuracy(y_hat, y)
if type(optimizer) == torch.optim.Optimizer:
optimizer.zero_grad()
l.mean().backward()
optimizer.step()
else:
l.sum().backward()
optimizer([W, b], lr, batch_size)
l_sum += l.sum()/ y.shape[0]
num+=1
# need to be summed
with torch.no_grad():
train_loss = l_sum/num
test_acc = eval_acc(net, test_loader)
train_loss_ls.append(train_loss)
acc_train_ls.append(acc/num)
acc_test_ls.append(test_acc) # have gain mean
print('epochs', "%d" % (epoch + 1), "train_loss", "%.4f" %(l_sum/ num), "train_acc","%.4f"%(acc/num), "test_acc", "%.4f"%test_acc)
plt.title(name_net)
plt.plot(train_loss_ls, label='train_loss')
# plt.plot(test_loss_ls, label='test_loss')
plt.plot(acc_train_ls, label='acc_train')
plt.plot(acc_test_ls, label='acc_test')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend()
plt.show()
5.2 函数调用
start = time.time()
lr = 1
epochs = 20
loss = cross_entropy
batch_size = 1024
train_muticlassifier(net, loss, train_loader, test_loader, epochs, batch_size, mysgd, "manually multi-classifier")
end = time.time()
print("running time", (end- start))
epochs 1 train_loss 0.5377 train_acc 0.8684 test_acc 0.9037
epochs 2 train_loss 0.3604 train_acc 0.9011 test_acc 0.9104
epochs 3 train_loss 0.3320 train_acc 0.9076 test_acc 0.9142
epochs 4 train_loss 0.3172 train_acc 0.9114 test_acc 0.9155
epochs 5 train_loss 0.3077 train_acc 0.9137 test_acc 0.9178
epochs 6 train_loss 0.3009 train_acc 0.9165 test_acc 0.9189
epochs 7 train_loss 0.2955 train_acc 0.9171 test_acc 0.9207
epochs 8 train_loss 0.2914 train_acc 0.9192 test_acc 0.9214
epochs 9 train_loss 0.2877 train_acc 0.9199 test_acc 0.9218
epochs 10 train_loss 0.2848 train_acc 0.9207 test_acc 0.9218
epochs 11 train_loss 0.2822 train_acc 0.9214 test_acc 0.9225
epochs 12 train_loss 0.2803 train_acc 0.9219 test_acc 0.9229
epochs 13 train_loss 0.2780 train_acc 0.9224 test_acc 0.9222
epochs 14 train_loss 0.2764 train_acc 0.9234 test_acc 0.9223
epochs 15 train_loss 0.2748 train_acc 0.9234 test_acc 0.9226
epochs 16 train_loss 0.2732 train_acc 0.9244 test_acc 0.9241
epochs 17 train_loss 0.2720 train_acc 0.9247 test_acc 0.9231
epochs 18 train_loss 0.2709 train_acc 0.9248 test_acc 0.9234
epochs 19 train_loss 0.2697 train_acc 0.9250 test_acc 0.9247
epochs 20 train_loss 0.2685 train_acc 0.9259 test_acc 0.9229
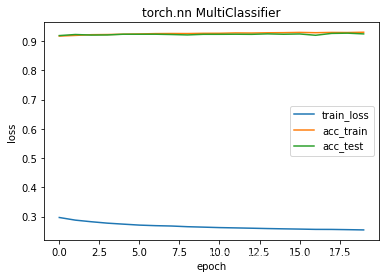
running time 139.71011066436768
6. torch.nn 实现多分类
6.1 基本函数编写
import torch
import torch.nn as nn
import torchvision
import matplotlib.pylab as plt
import torchvision.transforms as transforms
import time
train_datasets = torchvision.datasets.MNIST(root=f"../Datasets/MNIST/", train=True, transform= transforms.ToTensor(), download=True)
test_datasets = torchvision.datasets.MNIST(root=f"../Datasets/MNIST", train=False, transform= transforms.ToTensor(), download=True)
train_loader = torch.utils.data.DataLoader(train_datasets, batch_size=32, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_datasets, batch_size=32, shuffle=False)
def train_muticlassifier(net, loss, train_loader, test_loader, epochs, batch_size, optimizer,name_net):
train_loss_ls = []
# test_loss_ls = []
acc_test_ls = []
acc_train_ls = []
for epoch in range(epochs):
l_sum = 0.0
num = 0
acc =0.0
for X, y in train_loader:
y_hat = net(X)
l = loss(y_hat, y)
acc += accuracy(y_hat, y)
if isinstance(optimizer, torch.optim.Optimizer):
optimizer.zero_grad()
l.mean().backward()
optimizer.step()
else:
l.sum().backward()
optimizer([W, b], lr, batch_size)
l_sum += l.sum()/ y.shape[0]
num+=1
# need to be summed
with torch.no_grad():
train_loss = l_sum/num
test_acc = eval_acc(net, test_loader)
train_loss_ls.append(train_loss)
acc_train_ls.append(acc/num)
acc_test_ls.append(test_acc) # have gain mean
print('epochs', "%d" % (epoch + 1), "train_loss", "%.4f" %(l_sum/ num), "train_acc","%.4f"%(acc/num), "test_acc", "%.4f"%test_acc)
plt.title(name_net)
plt.plot(train_loss_ls, label='train_loss')
# plt.plot(test_loss_ls, label='test_loss')
plt.plot(acc_train_ls, label='acc_train')
plt.plot(acc_test_ls, label='acc_test')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend()
plt.show()
6.2 函数调用及网络比较
没有隐藏层
net2 = nn.Sequential(
nn.Flatten(),
nn.Linear(784, 10)
)
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net2.apply(init_weights)
loss = nn.CrossEntropyLoss(reduction="none")
optimizer2 = torch.optim.SGD(net2.parameters(), lr=0.1)
epochs = 20
batch_size = 256
start = time.time()
train_muticlassifier(net2, loss, train_loader, test_loader, epochs, batch_size, optimizer2, "torch.nn MultiClassifier")
end = time.time()
print("running time", (end-start))
epochs 1 train_loss 0.2966 train_acc 0.9170 test_acc 0.9187
epochs 2 train_loss 0.2876 train_acc 0.9193 test_acc 0.9224
epochs 3 train_loss 0.2821 train_acc 0.9218 test_acc 0.9205
epochs 4 train_loss 0.2773 train_acc 0.9224 test_acc 0.9209
epochs 5 train_loss 0.2739 train_acc 0.9235 test_acc 0.9234
epochs 6 train_loss 0.2706 train_acc 0.9244 test_acc 0.9233
epochs 7 train_loss 0.2687 train_acc 0.9255 test_acc 0.9234
epochs 8 train_loss 0.2675 train_acc 0.9259 test_acc 0.9224
epochs 9 train_loss 0.2651 train_acc 0.9257 test_acc 0.9210
epochs 10 train_loss 0.2637 train_acc 0.9265 test_acc 0.9231
epochs 11 train_loss 0.2621 train_acc 0.9266 test_acc 0.9231
epochs 12 train_loss 0.2611 train_acc 0.9278 test_acc 0.9234
epochs 13 train_loss 0.2600 train_acc 0.9275 test_acc 0.9230
epochs 14 train_loss 0.2588 train_acc 0.9284 test_acc 0.9246
epochs 15 train_loss 0.2578 train_acc 0.9287 test_acc 0.9233
epochs 16 train_loss 0.2570 train_acc 0.9296 test_acc 0.9243
epochs 17 train_loss 0.2560 train_acc 0.9286 test_acc 0.9198
epochs 18 train_loss 0.2558 train_acc 0.9295 test_acc 0.9262
epochs 19 train_loss 0.2551 train_acc 0.9292 test_acc 0.9270
epochs 20 train_loss 0.2542 train_acc 0.9302 test_acc 0.9245
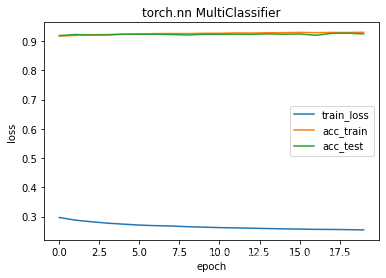
running time 135.89680194854736
一个隐藏层
net3 = nn.Sequential(
nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 10),
)
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net3.apply(init_weights)
loss = nn.CrossEntropyLoss(reduction="none")
optimizer3 = torch.optim.SGD(net3.parameters(), lr=0.1)
epochs = 20
batch_size = 256
start = time.time()
train_muticlassifier(net3, loss, train_loader, test_loader, epochs, batch_size, optimizer3, "torch.nn MultiClassifier")
end = time.time()
print("running time", (end-start))
epochs 1 train_loss 0.3893 train_acc 0.8887 test_acc 0.9374
epochs 2 train_loss 0.1640 train_acc 0.9526 test_acc 0.9605
epochs 3 train_loss 0.1123 train_acc 0.9676 test_acc 0.9691
epochs 4 train_loss 0.0864 train_acc 0.9752 test_acc 0.9712
epochs 5 train_loss 0.0694 train_acc 0.9797 test_acc 0.9774
epochs 6 train_loss 0.0571 train_acc 0.9837 test_acc 0.9774
epochs 7 train_loss 0.0478 train_acc 0.9864 test_acc 0.9788
epochs 8 train_loss 0.0406 train_acc 0.9884 test_acc 0.9778
epochs 9 train_loss 0.0351 train_acc 0.9903 test_acc 0.9803
epochs 10 train_loss 0.0296 train_acc 0.9920 test_acc 0.9789
epochs 11 train_loss 0.0258 train_acc 0.9934 test_acc 0.9798
epochs 12 train_loss 0.0221 train_acc 0.9950 test_acc 0.9794
epochs 13 train_loss 0.0189 train_acc 0.9960 test_acc 0.9811
epochs 14 train_loss 0.0163 train_acc 0.9969 test_acc 0.9807
epochs 15 train_loss 0.0143 train_acc 0.9972 test_acc 0.9803
epochs 16 train_loss 0.0124 train_acc 0.9978 test_acc 0.9812
epochs 17 train_loss 0.0108 train_acc 0.9983 test_acc 0.9812
epochs 18 train_loss 0.0093 train_acc 0.9988 test_acc 0.9807
epochs 19 train_loss 0.0083 train_acc 0.9990 test_acc 0.9809
epochs 20 train_loss 0.0073 train_acc 0.9994 test_acc 0.9809

running time 183.42246270179749
net3 结果分析
第10个eopch有轻微过拟合现象,但是加了一个隐藏层后,相比没有隐藏层,loss更低,acc更高,时间多了近1/2.
net4 两个隐藏层
net4 = nn.Sequential(
nn.Flatten(),
nn.Linear(784, 392),
nn.ReLU(),
nn.Linear(392, 196),
nn.ReLU(),
nn.Linear(196, 10)
)
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net4.apply(init_weights)
loss = nn.CrossEntropyLoss(reduction="none")
optimizer4 = torch.optim.SGD(net4.parameters(), lr=0.1)
epochs = 20
batch_size = 256
start = time.time()
train_muticlassifier(net4, loss, train_loader, test_loader, epochs, batch_size, optimizer4, "torch.nn MultiClassifier")
end = time.time()
print("running time", (end-start))
epochs 1 train_loss 0.6128 train_acc 0.7952 test_acc 0.9434
epochs 2 train_loss 0.1448 train_acc 0.9569 test_acc 0.9658
epochs 3 train_loss 0.0918 train_acc 0.9722 test_acc 0.9713
epochs 4 train_loss 0.0675 train_acc 0.9797 test_acc 0.9742
epochs 5 train_loss 0.0505 train_acc 0.9846 test_acc 0.9782
epochs 6 train_loss 0.0396 train_acc 0.9882 test_acc 0.9786
epochs 7 train_loss 0.0308 train_acc 0.9907 test_acc 0.9804
epochs 8 train_loss 0.0234 train_acc 0.9929 test_acc 0.9807
epochs 9 train_loss 0.0181 train_acc 0.9947 test_acc 0.9800
epochs 10 train_loss 0.0141 train_acc 0.9959 test_acc 0.9799
epochs 11 train_loss 0.0099 train_acc 0.9976 test_acc 0.9800
epochs 12 train_loss 0.0068 train_acc 0.9986 test_acc 0.9833
epochs 13 train_loss 0.0050 train_acc 0.9990 test_acc 0.9838
epochs 14 train_loss 0.0041 train_acc 0.9993 test_acc 0.9827
epochs 15 train_loss 0.0023 train_acc 0.9997 test_acc 0.9834
epochs 16 train_loss 0.0014 train_acc 0.9999 test_acc 0.9832
epochs 17 train_loss 0.0010 train_acc 1.0000 test_acc 0.9833
epochs 18 train_loss 0.0008 train_acc 1.0000 test_acc 0.9835
epochs 19 train_loss 0.0007 train_acc 1.0000 test_acc 0.9835
epochs 20 train_loss 0.0006 train_acc 1.0000 test_acc 0.9837
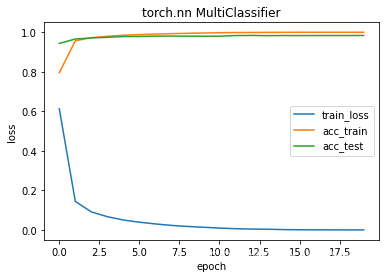
running time 226.2888867855072
net4 结果分析
在第三轮结束,loss已经为降到1%以下,收敛速度相比net3速度更快,train acc可以达到100%,说明模型已经可以完全拟合这个数据集。同样是20个epoch,时间上比net3只增加了5秒。
Sigmoid激活层 对比net3
net5 = nn.Sequential(
nn.Flatten(),
nn.Linear(784, 256),
nn.Sigmoid(),
nn.Linear(256, 10),
)
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net5.apply(init_weights)
loss = nn.CrossEntropyLoss(reduction="none")
optimizer5 = torch.optim.SGD(net5.parameters(), lr=0.1)
epochs = 20
batch_size = 256
start = time.time()
train_muticlassifier(net5, loss, train_loader, test_loader, epochs, batch_size, optimizer5, "torch.nn MultiClassifier")
end = time.time()
print("running time", (end-start))
epochs 1 train_loss 0.7653 train_acc 0.7628 test_acc 0.8976
epochs 2 train_loss 0.3265 train_acc 0.9060 test_acc 0.9147
epochs 3 train_loss 0.2847 train_acc 0.9168 test_acc 0.9217
epochs 4 train_loss 0.2545 train_acc 0.9262 test_acc 0.9280
epochs 5 train_loss 0.2287 train_acc 0.9341 test_acc 0.9365
epochs 6 train_loss 0.2062 train_acc 0.9406 test_acc 0.9442
epochs 7 train_loss 0.1868 train_acc 0.9462 test_acc 0.9477
epochs 8 train_loss 0.1705 train_acc 0.9510 test_acc 0.9524
epochs 9 train_loss 0.1563 train_acc 0.9551 test_acc 0.9552
epochs 10 train_loss 0.1441 train_acc 0.9579 test_acc 0.9577
epochs 11 train_loss 0.1337 train_acc 0.9615 test_acc 0.9587
epochs 12 train_loss 0.1242 train_acc 0.9641 test_acc 0.9613
epochs 13 train_loss 0.1163 train_acc 0.9668 test_acc 0.9629
epochs 14 train_loss 0.1091 train_acc 0.9689 test_acc 0.9660
epochs 15 train_loss 0.1027 train_acc 0.9707 test_acc 0.9673
epochs 16 train_loss 0.0972 train_acc 0.9722 test_acc 0.9681
epochs 17 train_loss 0.0917 train_acc 0.9740 test_acc 0.9685
epochs 18 train_loss 0.0870 train_acc 0.9756 test_acc 0.9697
epochs 19 train_loss 0.0825 train_acc 0.9767 test_acc 0.9711
epochs 20 train_loss 0.0786 train_acc 0.9780 test_acc 0.9714
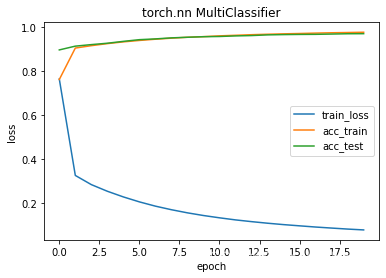
running time 186.14296102523804
net6 tanh激活函数 对比net3
net6 = nn.Sequential(
nn.Flatten(),
nn.Linear(784, 256),
nn.Tanh(),
nn.Linear(256, 10),
)
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net6.apply(init_weights)
loss = nn.CrossEntropyLoss(reduction="none")
optimizer6 = torch.optim.SGD(net6.parameters(), lr=0.1)
epochs = 20
batch_size = 256
start = time.time()
train_muticlassifier(net6, loss, train_loader, test_loader, epochs, batch_size, optimizer6, "torch.nn MultiClassifier")
end = time.time()
print("running time", (end-start))
epochs 1 train_loss 0.4044 train_acc 0.8867 test_acc 0.9255
epochs 2 train_loss 0.2251 train_acc 0.9343 test_acc 0.9482
epochs 3 train_loss 0.1627 train_acc 0.9526 test_acc 0.9544
epochs 4 train_loss 0.1257 train_acc 0.9631 test_acc 0.9648
epochs 5 train_loss 0.1020 train_acc 0.9700 test_acc 0.9701
epochs 6 train_loss 0.0850 train_acc 0.9751 test_acc 0.9708
epochs 7 train_loss 0.0723 train_acc 0.9789 test_acc 0.9725
epochs 8 train_loss 0.0624 train_acc 0.9815 test_acc 0.9743
epochs 9 train_loss 0.0539 train_acc 0.9845 test_acc 0.9758
epochs 10 train_loss 0.0473 train_acc 0.9864 test_acc 0.9770
epochs 11 train_loss 0.0416 train_acc 0.9884 test_acc 0.9784
epochs 12 train_loss 0.0366 train_acc 0.9898 test_acc 0.9778
epochs 13 train_loss 0.0321 train_acc 0.9915 test_acc 0.9799
epochs 14 train_loss 0.0286 train_acc 0.9930 test_acc 0.9790
epochs 15 train_loss 0.0256 train_acc 0.9939 test_acc 0.9802
epochs 16 train_loss 0.0224 train_acc 0.9951 test_acc 0.9786
epochs 17 train_loss 0.0201 train_acc 0.9958 test_acc 0.9799
epochs 18 train_loss 0.0179 train_acc 0.9966 test_acc 0.9798
epochs 19 train_loss 0.0159 train_acc 0.9973 test_acc 0.9798
epochs 20 train_loss 0.0144 train_acc 0.9977 test_acc 0.9802
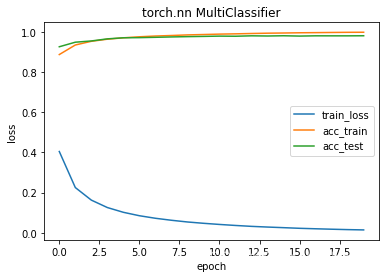
running time 190.70445561408997
net7 隐藏层修改为128 对比net3
net7 = nn.Sequential(
nn.Flatten(),
nn.Linear(784, 128),
nn.ReLU(),
nn.Linear(128, 10),
)
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net7.apply(init_weights)
loss = nn.CrossEntropyLoss(reduction="none")
optimizer7 = torch.optim.SGD(net7.parameters(), lr=0.1)
epochs = 20
batch_size = 256
start = time.time()
train_muticlassifier(net7, loss, train_loader, test_loader, epochs, batch_size, optimizer7, "torch.nn MultiClassifier")
end = time.time()
print("running time", (end-start))
epochs 1 train_loss 0.4095 train_acc 0.8813 test_acc 0.9344
epochs 2 train_loss 0.1692 train_acc 0.9507 test_acc 0.9576
epochs 3 train_loss 0.1178 train_acc 0.9663 test_acc 0.9636
epochs 4 train_loss 0.0927 train_acc 0.9726 test_acc 0.9716
epochs 5 train_loss 0.0762 train_acc 0.9779 test_acc 0.9726
epochs 6 train_loss 0.0637 train_acc 0.9812 test_acc 0.9738
epochs 7 train_loss 0.0557 train_acc 0.9834 test_acc 0.9760
epochs 8 train_loss 0.0482 train_acc 0.9858 test_acc 0.9749
epochs 9 train_loss 0.0418 train_acc 0.9882 test_acc 0.9777
epochs 10 train_loss 0.0369 train_acc 0.9894 test_acc 0.9775
epochs 11 train_loss 0.0319 train_acc 0.9913 test_acc 0.9758
epochs 12 train_loss 0.0284 train_acc 0.9925 test_acc 0.9774
epochs 13 train_loss 0.0249 train_acc 0.9935 test_acc 0.9782
epochs 14 train_loss 0.0219 train_acc 0.9946 test_acc 0.9771
epochs 15 train_loss 0.0191 train_acc 0.9956 test_acc 0.9758
epochs 16 train_loss 0.0169 train_acc 0.9964 test_acc 0.9782
epochs 17 train_loss 0.0149 train_acc 0.9971 test_acc 0.9795
epochs 18 train_loss 0.0134 train_acc 0.9974 test_acc 0.9787
epochs 19 train_loss 0.0116 train_acc 0.9982 test_acc 0.9784
epochs 20 train_loss 0.0104 train_acc 0.9985 test_acc 0.9784
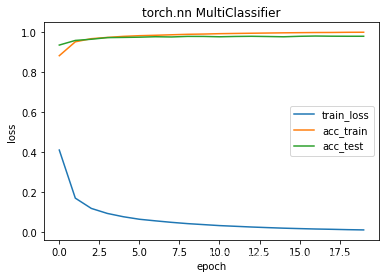
running time 167.7554521560669
net8 隐藏层神经元个数修改为512 对比net3
net8 = nn.Sequential(
nn.Flatten(),
nn.Linear(784, 512),
nn.ReLU(),
nn.Linear(512, 10),
)
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net8.apply(init_weights)
loss = nn.CrossEntropyLoss(reduction="none")
optimizer8 = torch.optim.SGD(net8.parameters(), lr=0.1)
epochs = 20
batch_size = 256
start = time.time()
train_muticlassifier(net8, loss, train_loader, test_loader, epochs, batch_size, optimizer8, "torch.nn MultiClassifier")
end = time.time()
print("running time", (end-start))
epochs 1 train_loss 0.3721 train_acc 0.8948 test_acc 0.9462
epochs 2 train_loss 0.1585 train_acc 0.9544 test_acc 0.9632
epochs 3 train_loss 0.1098 train_acc 0.9687 test_acc 0.9720
epochs 4 train_loss 0.0834 train_acc 0.9757 test_acc 0.9720
epochs 5 train_loss 0.0665 train_acc 0.9804 test_acc 0.9739
epochs 6 train_loss 0.0547 train_acc 0.9845 test_acc 0.9772
epochs 7 train_loss 0.0457 train_acc 0.9870 test_acc 0.9796
epochs 8 train_loss 0.0384 train_acc 0.9898 test_acc 0.9795
epochs 9 train_loss 0.0324 train_acc 0.9913 test_acc 0.9802
epochs 10 train_loss 0.0275 train_acc 0.9930 test_acc 0.9808
epochs 11 train_loss 0.0231 train_acc 0.9949 test_acc 0.9806
epochs 12 train_loss 0.0198 train_acc 0.9957 test_acc 0.9814
epochs 13 train_loss 0.0171 train_acc 0.9967 test_acc 0.9819
epochs 14 train_loss 0.0145 train_acc 0.9977 test_acc 0.9816
epochs 15 train_loss 0.0122 train_acc 0.9984 test_acc 0.9828
epochs 16 train_loss 0.0109 train_acc 0.9987 test_acc 0.9823
epochs 17 train_loss 0.0094 train_acc 0.9988 test_acc 0.9824
epochs 18 train_loss 0.0083 train_acc 0.9992 test_acc 0.9816
epochs 19 train_loss 0.0073 train_acc 0.9992 test_acc 0.9823
epochs 20 train_loss 0.0064 train_acc 0.9995 test_acc 0.9823
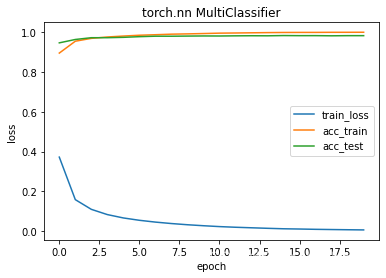
running time 204.5472650527954
实验结果对比分析
更改隐藏层和激活函数的对比

可以很明显的看出,随着隐藏层的增加,train loss 在下降,acc、计算时间上升。
更改隐藏层个数的对比

随着神经元数的增多,train loss下降,acc、计算时间上升。














 953
953











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









