






初入AI安全,暑假回家持续看论文中......
目的:生成一种肉眼不可见且不会被各种防御手段检测出来的后门
方法:主要是通过生成网络和特征层限制的方法来生成隐蔽的触发器,主体方法如下图。
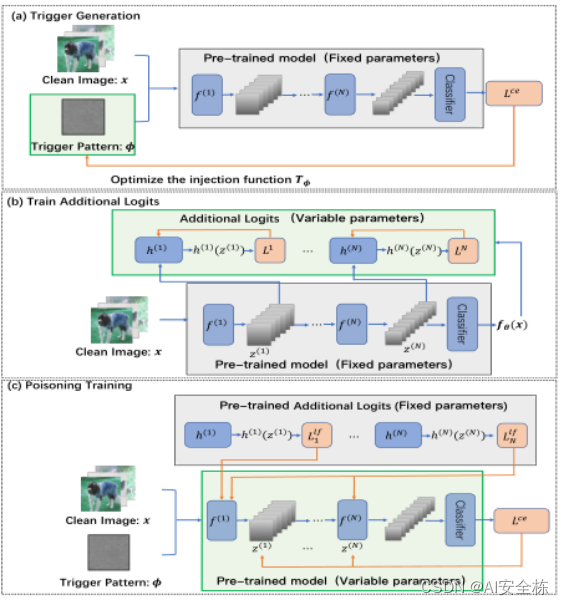
图abc是同一个网络的三个阶段,这篇文章主要是修改了损失函数,修改后的损失函数如下:
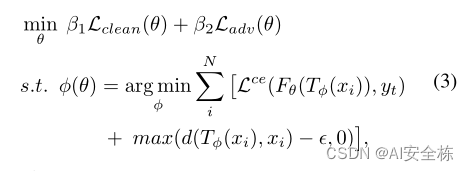
其中:Lce是交叉熵损失函数,F是分类模型,yt是目标标签,xi是干净样本,T是生成有毒样本的函数,d是欧氏距离函数。
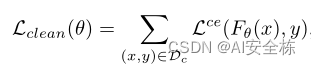
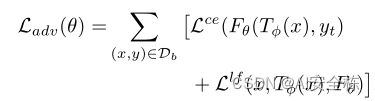
Ladv的Llf为:
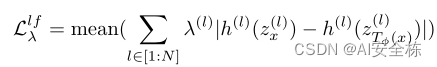
l是网络输出的层数,一共有N层。h是池化操作加一个偏差,Z是模型的每一层输出。
这个损失函数就是对有毒样本与干净样本在模型每一层输出后都加以限制,使得有毒样本与干净样本经过模型每一层输出后的特征图片相差较小,无法被防御手段感知到。
结果:攻击效果显著,可以抵御多种防御
想法:这篇文章也是白盒攻击且对模型中间层的输出加以约束。不同的是文章1仅仅使用了最后第二层,而这篇文章使用了所有层,并且约束的方法不一样,这篇文章除了欧式距离,还增加了池化操作的约束与一开始加了扰动后的图片与原图片区别的约束。从结果看,这篇文章比文章1好的地方是生成了一个不可见的扰动,但是这个不可见的扰动是得益与生成扰动的方式,文章1使用了加一个patch的方式,如果换一种方式生成不可见扰动的方式生成,也许这两篇文章的结果就差不多了。那么这篇文章使用的方法也许就有冗余,可能不需要每一层都加以约束就可以得到相同的结果。















 8698
8698











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









