







“Why Should I Trust You?” Explaining the Predictions of Any Classifier阅读笔记
1. 论文贡献
- LIME,一种算法,可以忠实地解释任何分类器或回归器的预测,通过局部逼近它与一个可解释的模型。
- SP-LIME,一种通过子模块优化,选择一组具有解释的代表性实例来解决“信任模型”问题的方法。
2. 背景 [ 1 ] ^{[1]} [1]
- 在模型被用户使用前,用户都会十分关心模型是否真的值得信赖。
- 现实中,我们的通过目前标准的训练方式得到的模型,往往不能保证模型的可靠性。因为模型开发过程中使用的验证、测试集,可能跟实际场景差别很大。另外,我们使用的评价准则(evaluation metrics)也很局限,不能体现出很多我们关心的但难以量化的标准,例如用户的参与度、留存度。
- 由于模型开发过程中可能存在的非故意的数据泄露(unintentional data leakage,数据泄漏被
认为是信号无意地泄漏到训练(和验证)数据中,而在部署时不会出现,这可能会提高准确性。)和数据集漂移(dataset shift,指训练集和测试集分布不同),得到的模型也可能并不可靠。
3. LIME解释单个样本
3.1 总体思想
- 原始模型复杂的决策边界,在任意一个样本点的局部范围内,可以视为是线性的。那只要找到这些线性的边界,就可以对模型在该样本点处进行解释了。
- LIME的总体目标是在局部忠实于分类器的可解释表示之上识别一个可解释的模型。
3.2 构建可解释的数据表示 [ 1 ] ^{[1]} [1]
原始的数据,或者模型使用的特征,往往不够直观、具体。我们需要将原始的数据,转化成一种便于解释的数据表示,从而辅助我们后续的模型预测结果解释。
文章中将原始数据转化成一组由基本元素构成的0-1表示。例如,对于文本来说,就是某个词是否出现这样的特征,对于图像来说,就是某个区域是否出现。文本0-1表示如下图所示:
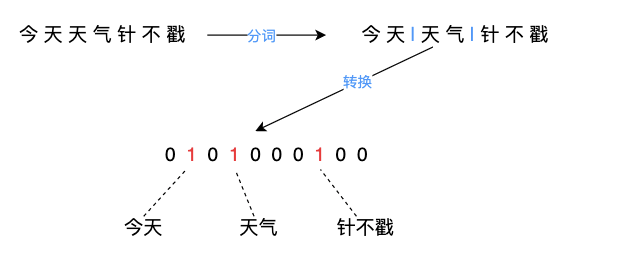
3.3 可解释性和忠实度的权衡
想要解释模型而且效果不能很差,所以在局部忠诚性和可解释性上做个取舍。文中定义了一个包括忠实度和可解释复杂度的度量函数
ξ
(
x
)
=
a
r
g
m
i
n
g
∈
G
L
(
f
,
g
,
π
x
)
+
Ω
(
g
)
\xi(x)=argmin_{g \in G} \mathcal{L}(f,g,\pi_x)+\Omega(g)
ξ(x)=argming∈GL(f,g,πx)+Ω(g)
其中:
- f f f 代表分类器,即需要被解释的复杂模型;
- g g g 代表解释器,通常为线性模型和决策树模型;
- G G G代表一类可解释的模型, g ∈ G g \in G g∈G ;
- Ω ( g ) \Omega(g) Ω(g) 是解释模型 g g g的复杂性度量,例如决策树的深度或线性模型非零权重的个数;
- x ∈ R d x \in \mathbb{R}^d x∈Rd 原始特征,例如RGB通道的像素值;
- x ′ ∈ R d ′ x^{\prime} \in \mathbb{R}^{d^{\prime}} x′∈Rd′ 可解释数据表示,例如超级像素是否存在;
- z ′ ∈ R d ′ z^{\prime} \in \mathbb{R}^{d^{\prime}} z′∈Rd′ 可解释数据表示的扰动数据;
- z ∈ R d z \in \mathbb{R}^d z∈Rd 扰动数据对应的原始特征;
- π x ( z ) \pi_x(z) πx(z) 作为实例 z z z 到 x x x 之间的接近度量,以便定义 x x x 周围的局部性。
3.4 局部采样
对原始的样本进行转换得到可解释的数据表示之后,对特征向量进行一些扰动,具体的,随机的对0-1向量中的1进行改变,改变的数量也随机。然后根据这些扰动后的向量,跟原向量的相似度,来使用不同的采样比例。直观上来讲,扰动的少的,采样会更多,扰动大的采样更少。
[
1
]
^{[1]}
[1]
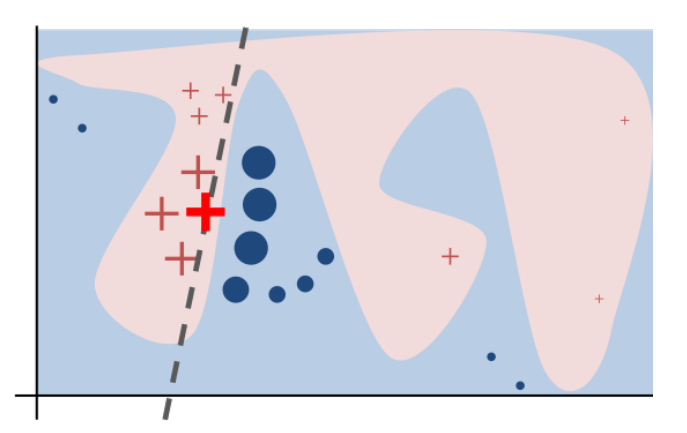
上图直观展示了采样的方法。黑盒模型的复杂决策函数 f f f用蓝色/粉色背景表示,这不能很好地用线性模型很好地近似。粗体的红十字是正在被解释的实例。LIME样本实例,使用f获得预测,并根据与被解释的实例的接近程度进行赋权(这里用大小表示)。虚线是学习到的局部(但不是全局的)忠实的解释。
3.5 稀疏线性解释
文章中使用稀疏线性解释器
g
(
z
′
)
=
w
g
⋅
z
′
g(z^{\prime})=w_g \cdot z^{\prime}
g(z′)=wg⋅z′,让
π
x
(
z
)
=
e
x
p
(
−
D
(
x
,
z
)
2
/
σ
2
)
\pi_x(z)=exp(-D(x,z)^2/\sigma^2)
πx(z)=exp(−D(x,z)2/σ2)这里
D
D
D是距离函数(文本是余弦距离,图像是
L
2
L_2
L2距离),然后,
L
\mathcal{L}
L可以就设计成一个带权重的最小二乘损失:
L
(
f
,
g
,
π
x
)
=
∑
z
,
z
′
∈
Z
π
x
(
z
)
(
f
(
z
)
−
g
(
z
′
)
)
2
.
\mathcal{L}(f,g,\pi_x)=\sum_{z,z^{\prime}\in Z} \pi_x(z)(f(z)-g(z^{\prime}))^2 .
L(f,g,πx)=z,z′∈Z∑πx(z)(f(z)−g(z′))2.
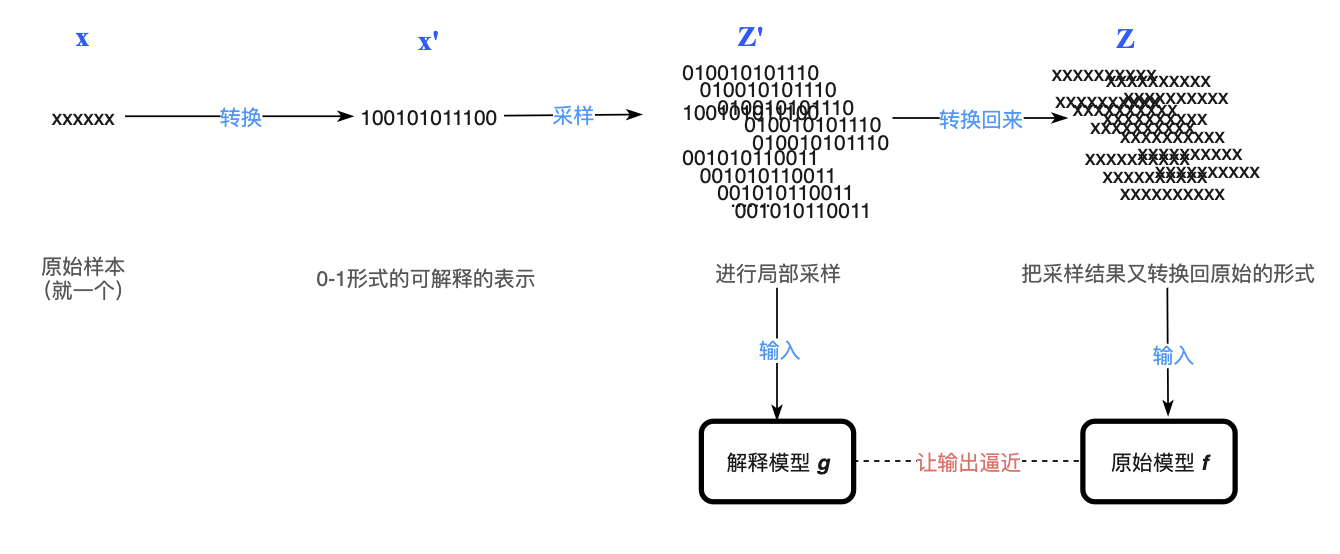
下图来自[1]中,直观展示LIME的训练过程。
下图是LIME的伪代码:
- 需要一个分类器,定义采样数量 N N N;
- 确定被解释实例 x x x和它的可解释版本 x ′ x^{\prime} x′;
- 定义一个样本间相似度计算方式 π x \pi_x πx,以及要选取的 K K K个特征来解释;
- 进行 N N N次扰动采样,每个邻居样本计算 z i ′ , f ( z i ) , π x ( z i ) z_i^{\prime},f(z_i),\pi_x(z_i) zi′,f(zi),πx(zi),并保存到 Z Z Z中;
- 利用Lasso回归计算解释器权重
w
w
w,这里
z
i
′
z_i^{\prime}
zi′是特征,
f
(
z
)
f(z)
f(z)是目标值。

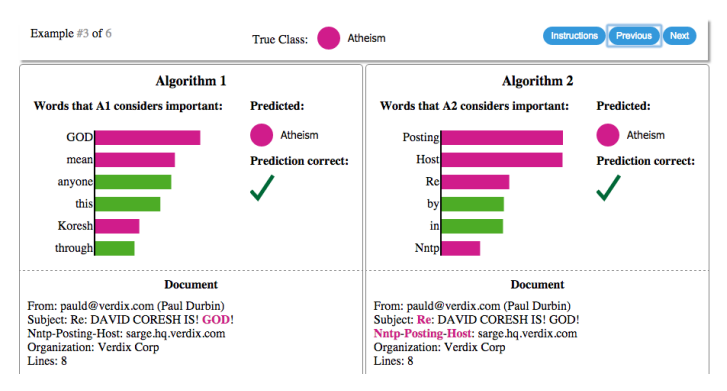
3.6 使用SVM进行文本分类
3.7 使用深度网络进行图像分类

4. Submodular Pick解释模型
虽然对单一预测的解释为用户提供了对分类器可靠性的一些理解,但对于评估整个模型的信任度是不够的。作者建议通过解释一组单独的实例来给出对模型的全局理解。这种方法仍然是与模型无关的。需要考虑的问题是如何用最高的效率,检查最少的样本,就能够最全面地检查模型的可靠性,即,挑选最少的样本,让他们对特征空间的覆盖程度最大。下图是一个大致思路,(这里f1,…,f5是可解释的特征)
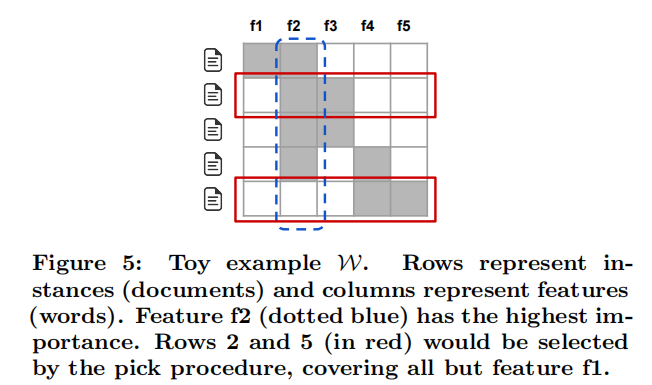
尽管对多个实例的解释可能很有洞察力,但这些实例需要明智地选择,因为用户可能没有时间来检查大量的解释。我们用预算
B
B
B来表示人类所拥有的时间/耐心,它表示他们为了理解一个模型而愿意看的解释的数量。给定一组实例X,我们将拾取步骤定义为选择B个实例供用户检查的任务。下图是Submodular Pick算法的伪代码:
- 给出了一组实例的解释 X X X,给出选择实例个数 B B B;
- 使用算法1给出 W W W矩阵(如上图所示);
- 使用特征重要性函数 I I I计算每个可解释特征的特征重要性( I 1 , ⋯ , I d ′ I_1,\cdots, I_{d^{\prime}} I1,⋯,Id′);
-
c
c
c是定义覆盖范围的集合函数,使用文中公式(4)贪婪优化选中的实例集合
V
V
V.

参考文章
[1] 知乎—LIME:我可以解释任何一个分类模型的预测结果
[2] CSDN—【论文阅读·2】”Why Should I Trust You?” Explaining the predictions of Any Classifier















 1575
1575











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









