









HashMap底层核心知识总结
本文结合底层对HashMap核心知识进行归纳总结!!!
一、了解数据结构中的HashMap吗?介绍下他的结构和底层原理?
- HashMap是由数组+链表组成的数据结构(jdk1.8中是数组+链表+红⿊树的数据结构)
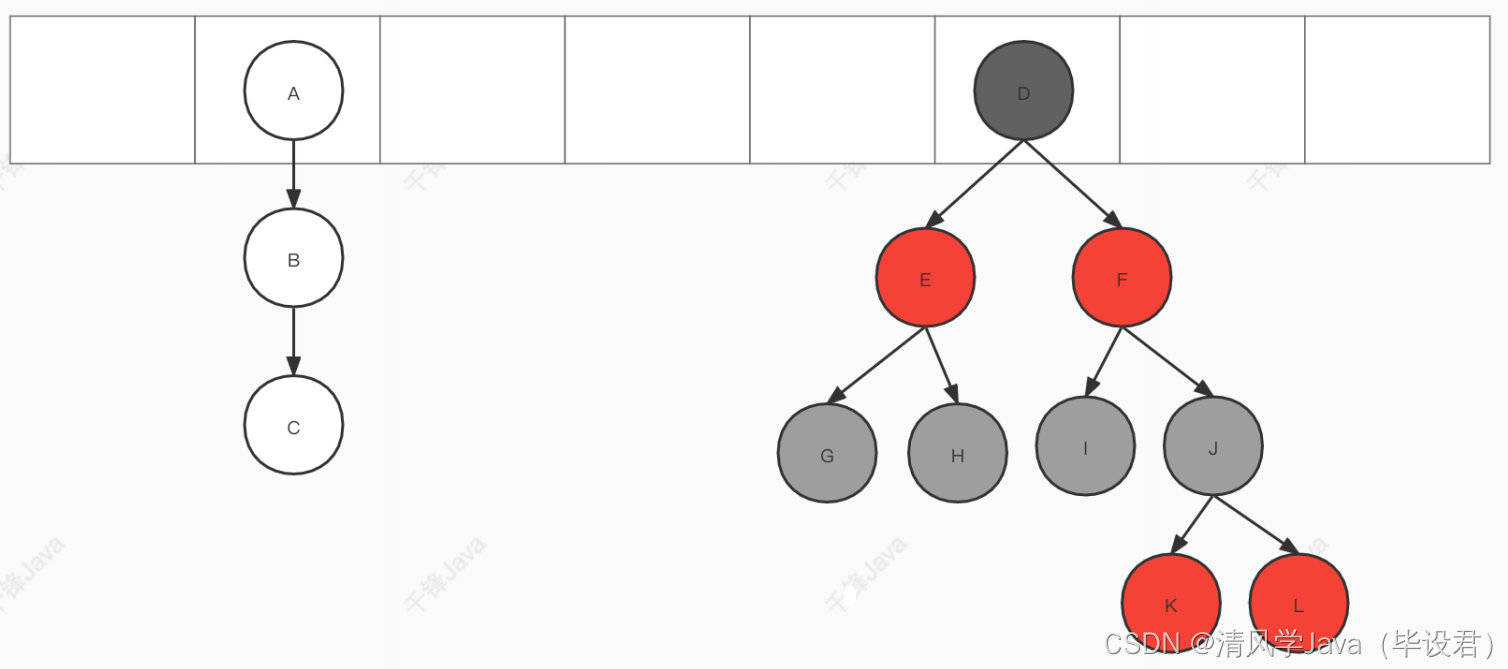
- 1.7 版本:根据hash(key)确定存储位置后,以链表的形式在该位置处存数据。此时数组该位置的链表存了多个数据,因此也称为桶存放的数据是⽤Entry描述。

- 1.8 版本:
存放的数据是⽤Node描述

链表有可能过⻓,所以在满⾜以下条件时,链表会转换成红⿊树:
链表⻓度>8
数组⼤⼩>=64 - 1.8版本:当红⿊树节点个数<6时转换为链表
二、HaspMap存储原理
往HashMap添加元素的时候,首先会调用键的hashCode方法得到元素的哈希码值,然后经过运算就可以算出该元素元素在哈希表中的存储位置。
情况1: 如果算出的位置目前没有任何元素存储,那么该元素可以直接添加到哈希表中。
情况2: 如果算出的位置目前已经存在其他的元素,那么还会调用该元素的equals方法与这个位置上的元素进行比较,如果equals方法返回的是false,那么该元素允许被存储,如果equals方法返回的是true,那么该元素被视为重复元素,不允许存储。
三、HashMap怎么设定初始容量大小的?
- 如果没有指定容量:则使⽤默认的容量为16,负载因⼦0.75。

- 如果指定了容量,则会初始化容量为:⼤于指定容量的,最近的2的整数次⽅的数。⽐如传⼊是10,则会初始化容量为16(2的4次⽅)。

该算法的逻辑是让⾼位1的之后所有位上的数都为1,再做+1的操作,实现初始化容量为:⼤于指定容量的,最近的2的整数次⽅的数。
四、HashMap的hash函数是如何设计的?

⽤key的hashCode()与其低16位做异或运算。这个扰动函数的设计有两个原因:
- 计算出来的hash值尽量分散,降级hash碰撞的概率
- ⽤位运算做算法,更加⾼效
这样答只是答了表象的东⻄,深层的内容是这样的:
⾸先我们要知道hash运算的⽬的是⽤来定位该数据要存放在数组的哪个位置,如何计算?

是通过n-1的操作与原hash值做“与”运算,其中n是数组的⻓度。相当于是更⾼效的%取模运
算。⽽n-1恰好是⼀个低位掩码。⽐如初始化⻓度是16,那n-1是15,即⼆进制的00001111。
此时得到了另⼀个问题的答案:那么为什么不能直接⽤key的hashCode()作为hash值,⽽⼀
定要^ (h >>> 16)?
因为如果直接⽤key的hashCode()作为hash值,很容易发⽣hash碰撞。
使⽤扰动函数^ (h >>> 16),就是为了混淆原始哈希码的⾼位和低位,以此来加⼤低位的随机性。且低位中参杂了⾼位的信息,这样⾼位的信息也作为扰动函数的关键信息。

五、JDK1.8相比1.7,做了哪些优化?
1.8除了引⼊了红⿊树,将时间复杂度由O(n)降为O(log n)以外,还将1.7的头插法改为1.8的尾插法。
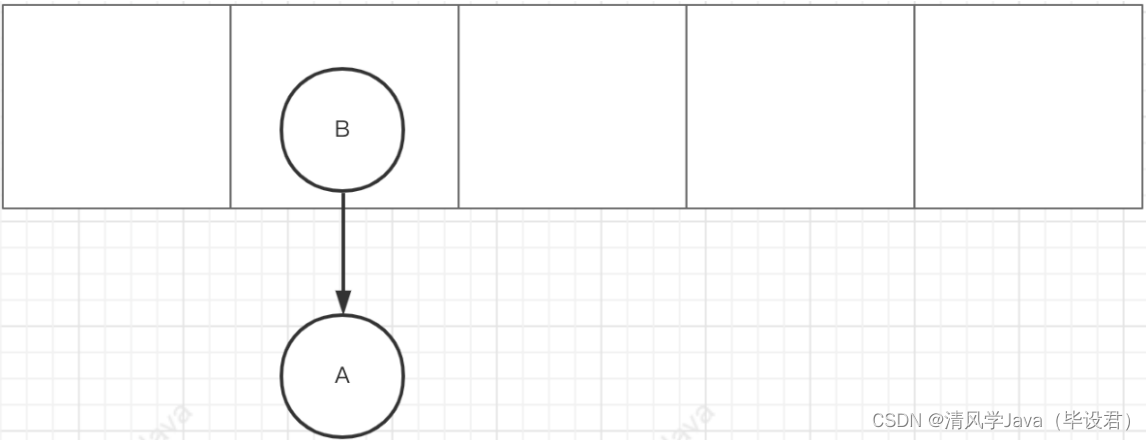
头插法:
作者认为,后插⼊的数据,被访问的概率更⾼,所以使⽤了头插法,但头插法会存在遍历时死循环的情况。
扩容之前:
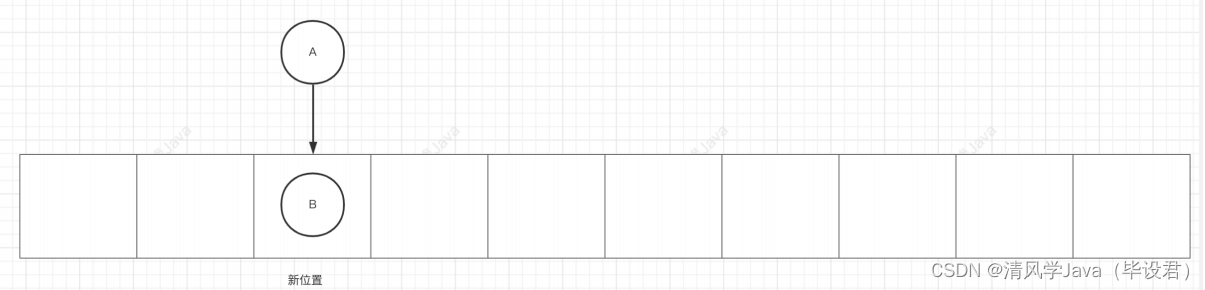
扩容之后:获得新的index,头插法会导致链表反转:
/**
* Transfers all entries from current table to newTable.
*/
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i]; //此处如果发⽣并发,线程1执⾏反转过程中线程2执⾏
newTable[i] = e;
e = next;
}
}
}
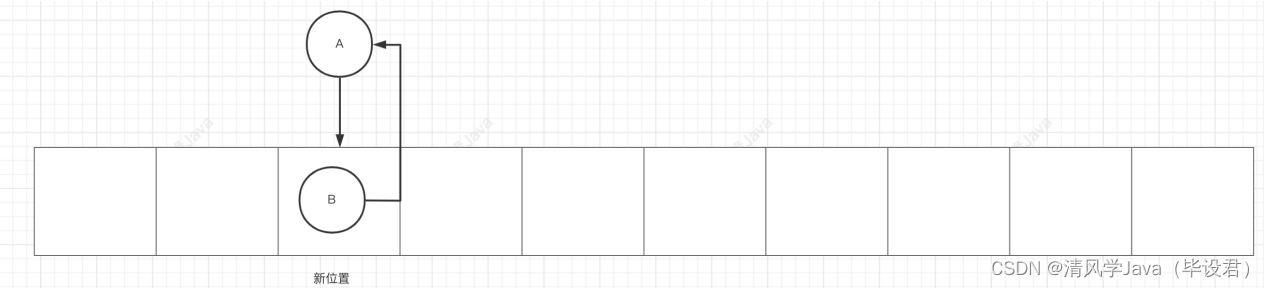
当线程1执⾏反转过程中线程2执⾏,就可能会出现如下情况,造成链表成环的死循环问题。
尾插法:
在扩容时会保持链表元素原先的顺序,因此不会出现链表成环的死循环问题。
六、HashMap怎么实现扩容?
HashMap执⾏扩容关系到两个参数:
- Capacity:HashMap当前容量
- loadFactor:负载因⼦(默认是0.75) 当HashMap容量达到Capacity*loadFactor时,进⾏扩容。
1.7和1.8版本的扩容区别:
- 1.7版本
先扩容,再插⼊数据。扩容时会创建⼀个为原数组的2倍⼤⼩的数组,然后将原数组的元素重新hash,存进新数组。 - 1.8版本
先插⼊数据,再执⾏扩容。扩容时会创建⼀个为原数组的2倍⼤⼩的数组,然后将原数组的元素存进新数组。不同的是1.8使⽤位移操作创建2倍⼤⼩的新数组。
七、插⼊数据时扩容的重新hash是怎么做的?
- 1.7:需要再做⼀次hash
/**
* Adds a new entry with the specified key, value and hash code to
* the specified bucket. It is the responsibility of this
* method to resize the table if appropriate.
*
* Subclass overrides this to alter the behavior of put method.
*/
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
- 1.8:不需要做hash,通过原⽅式获取存储位置
newTab[e.hash & (newCap - 1)] = e;
由于newCap为新数组的⼤⼩,因此在做与操作时,在没有改变key的hash的情况下,改变了与数的值来获取新的存储位置,效率更⾼。⽽且位预算的newCap-1 实际上由于2的幂的关系,-1的操作实际上就是在⾼位补1,效率更⾼。
八、为什么重写equals⽅法后还要重写hashCode⽅法?
因为在put的时候,如果数据已经存在,就需要把⽼的数据return,存⼊新的数据。那如何判断数据已存在呢?是通过先⽐较hash值,如果hash值相同,再⽤equals判断。
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
重写equals和hashCode⽅法的⽬的就是根据对象的属性来进⾏判断对象是否相同,⽽⾮根据对象的内存地址来判断。
public class User {
private int id;
private String name;
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
User user = (User) o;
return id == user.id && Objects.equals(name, user.name);
}
@Override
public int hashCode() {
return Objects.hash(id, name);
}
}















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









