






一、前提声明
1、什么是BFS
BFS(广度优先搜索)算法是一种图搜索算法,用于在图或树数据结构中从一个指定的起始顶点开始,逐层扩展搜索,直到找到目标顶点。BFS 是一种层次遍历的算法,通常通过队列数据结构来实现。
BFS 的基本步骤如下:
1、将起始顶点放入队列中,并标记为已访问。
2、从队列中取出一个顶点,访问它的所有未访问的邻居,并将邻居加入队列。
3、标记已访问过的顶点,以防止重复访问。
4、重复步骤 2 和步骤 3,直到队列为空或找到目标顶点。
BFS 适用于解决如下问题:
图的遍历:查找图中的所有顶点。
最短路径问题:查找两个顶点之间的最短路径。
连通性问题:检查图中是否存在从一个顶点到另一个顶点的路径。
BFS 通常使用迭代方式实现,并且在使用队列的过程中保持层次遍历的顺序。这使得 BFS 对于需要按层级进行搜索的问题非常有用。
详细参考以下视频:
【动画演示什么是深搜和广搜 怎么入门搜索算法 这个视频告诉你】 https://www.bilibili.com/video/BV1zG41117YF/?share_source=copy_web&vd_source=307838fdbdb0dab7d7988f7b676ed038
2、什么是DFS
DFS(深度优先搜索)是一种图搜索算法,用于从图中的某个起始顶点开始,尽可能深入地探索图的分支,直到到达最深的节点,然后再回溯到上一层继续探索其他分支。DFS 使用栈或递归来实现。DFS 的基本思想是从一个起始节点出发,首先访问该节点,然后递归地访问其未访问过的相邻节点。这个过程一直持续到无法再深入为止,然后回溯到上一层,继续探索其他分支。
DFS 主要用于解决以下问题:
1、图的遍历:查找图中的所有顶点。
2、连通性问题:检查图中是否存在从一个顶点到另一个顶点的路径。
3、拓扑排序:对有向图进行拓扑排序。
以下是 DFS 的基本步骤:
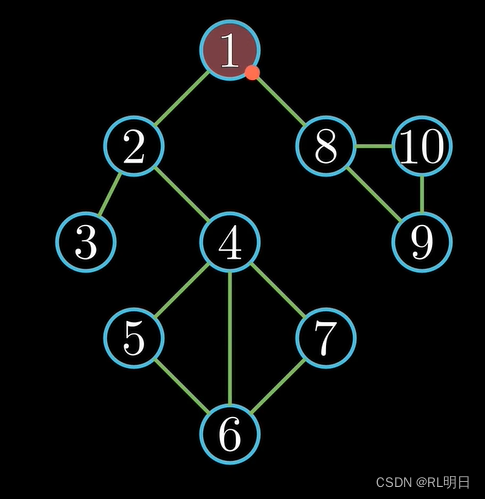
1、从图中指定顶点v出发,访问此顶点,然后依次从v的未被访问的邻接点出发深度优先遍历,直至图中所有与v有路径连通的顶点都被访问到;
·2、若此时图中尚有顶点未被访问,则选图中一个未曾被访问的顶点作起始点,重复步骤一,直至图中所有顶点都被访问到为止。
详细请看以下视频:
【DFS深搜解决迷宫问题(原理分析+代码实现)】 https://www.bilibili.com/video/BV1bK4y1C7W2/?share_source=copy_web&vd_source=307838fdbdb0dab7d7988f7b676ed038
3、什么是剪枝
剪枝搜索是一种在搜索算法中通过提前终止一些无效的分支(即"剪枝")来优化搜索效率的技术。剪枝搜索通常用于深度优先搜索(DFS)和广度优先搜索(BFS)等搜索算法中,以避免不必要的计算,提高算法的效率。
在搜索的过程中,当发现某个分支已经不能满足问题的解,或者可以通过一些判断条件确定某个分支不会包含最优解时,就可以剪枝,停止对该分支的进一步搜索。这样可以避免不必要的计算和遍历,提高算法的效率。
剪枝搜索常见的应用场景包括:
1、搜索树的深度限制: 在深度优先搜索中,可以设置一个最大深度,当搜索深度达到设定值时,就停止继续搜索,以避免过深的递归。
2、局部最优解的排除: 当搜索到一部分解时,通过某些条件判断这部分解不可能成为最优解,就可以剪枝,停止对这个分支的搜索。
3、对称性剪枝: 在某些问题中,问题的解具有对称性,可以通过对称性剪枝来避免重复搜索相同的解。
4、启发式搜索的优化: 在使用启发式搜索算法时,通过评估当前搜索状态的估计值,可以根据这个估计值来决定是否进行进一步搜索,从而实现剪枝。
剪枝搜索的实现方式会根据具体问题和算法的特点而有所不同,但总体思想是在搜索过程中通过一些判断条件提前终止不必要的搜索分支,以提高搜索效率。
4、什么是双向BFS
双向广度优先搜索(Bidirectional Breadth-First Search,双向BFS)是一种搜索算法,通常用于在图或树中找到两个节点之间的最短路径。与传统的广度优先搜索(BFS)不同,双向BFS从起点和终点同时进行搜索,直到两者相遇为止。
双向BFS的主要思想是从起点和终点分别开始进行广度优先搜索,逐层地向外扩展。当两个搜索方向的遍历相遇时,算法终止,因为这时找到了连接起点和终点的最短路径。
具体步骤如下:
1、从起点和终点同时开始,分别用两个队列(或集合)进行广度优先搜索。
2、在每一步中,分别从起点队列和终点队列中取出一个节点进行扩展。
3、对于起点和终点的扩展节点,分别判断是否相遇。如果相遇,则说明找到了最短路径。
4、如果没有相遇,则继续进行下一层的搜索。
双向BFS相对于单向BFS的优势在于,它可以在某些情况下显著减少搜索的空间复杂度,因为两个搜索方向的路径会相对较短。在最坏情况下,双向BFS的时间复杂度和空间复杂度仍然是指数级别的,但相比单向BFS,它在实际应用中通常能够提供更好的性能。
这种算法适用于问题的性质允许从两个方向同时进行搜索,并且找到最短路径的需求。在一些图论问题、游戏问题、网络问题等场景中,双向BFS都可以是一个有效的算法选择。
详细观看以下视频:
【7.14.3. 双向BFS的实现、特性和题解】 https://www.bilibili.com/video/BV1tS4y1m7jv/?share_source=copy_web&vd_source=307838fdbdb0dab7d7988f7b676ed038
5、什么是记忆化搜索
记忆化搜索(Memoization Search)是一种优化搜索算法的方法,通过在递归过程中保存已经计算过的结果,避免重复计算,从而提高算法的效率。这一方法通常用于解决具有重叠子问题性质的问题,例如动态规划中的子问题。
在记忆化搜索中,一般使用一个数据结构(通常是一个字典或数组)来存储已经计算过的结果,以便在需要时直接查找而不必重新计算。这样可以避免在递归过程中多次计算相同的子问题,减少时间复杂度。
常见的记忆化搜索的应用场景包括动态规划问题、递归问题等。通过记忆化搜索,可以在保持递归思想的同时,显著提高算法的效率。
6、什么是迭代加深搜索
迭代加深搜索(Iterative Deepening Search,简称IDS)是一种在深度优先搜索(DFS)的基础上进行改进的搜索算法。它通过限制搜索深度的上限,然后逐步增加深度,从而避免了传统深度优先搜索可能会陷入无限深度的分支的问题。
迭代加深搜索的基本思想是通过多次进行深度限制的深度优先搜索,从浅层次开始逐渐增加搜索深度。在每一次搜索中,算法都会尽量探索更深的层次,直到找到目标或达到当前深度的上限。如果目标未找到,就增加深度上限,再次执行深度优先搜索。这个过程会一直重复,直到找到目标为止。
迭代加深搜索的优点在于它在深度优先搜索的基础上引入了逐渐增加深度的机制,同时仍然保留了深度优先搜索的空间复杂度低的特性。由于逐渐加深搜索深度,迭代加深搜索可以在存在较大搜索空间的问题中更加高效地找到解。
7、什么是启发式搜索
启发式搜索(Heuristic Search)是一种基于启发式函数(Heuristic Function)的搜索算法,用于解决在搜索问题中找到最优解的问题。启发式函数是一种用于评估搜索状态的估价函数,它提供了一种估计从当前状态到达目标状态的代价或距离的方法。
启发式搜索的主要目标是在搜索过程中尽可能快地找到解决方案,尽管这个解决方案不一定是最优解。通过引入启发式函数,搜索算法可以优先探索具有更有希望的状态,从而加速找到解决方案的过程。
一种常见的启发式搜索算法是A算法(A-star algorithm),它结合了广度优先搜索和启发式函数。A算法使用两个评估函数:g(n) 表示从初始状态到达状态 n 的实际代价,h(n) 表示从状态 n 到目标状态的估计代价。A*算法选择下一个状态时,通过优先考虑 g(n) + h(n) 的值最小的状态,以便尽快找到目标。
启发式搜索在解决许多现实世界的问题中都表现得非常出色,例如路径规划、棋类游戏、迷宫问题等。启发式搜索允许在面对大规模搜索空间时更加高效地找到解决方案。
二、习题练习
1、洪水问题——BFS解法

def flood_problem(matrix):
if not matrix or not matrix[0]: # 如果输入的矩阵为空或者矩阵的第一行为空,直接返回0。
return 0
rows,cols = len(matrix),len(matrix[0]) # 获取矩阵的行数和列数
visited = [[False] * cols for _ in range(rows)] # 用于记录节点是否已访问,即初始化visited
# [[False,False,False,False,False],[False,False,False,False,False],[False,False,False,False,False],[False,False,False,False,False]]
count_lowlands = 0 # 记录低洼地数量
# 定义方向数值,表示上、下、左、右四个方向
direction = [(-1,0),(1,0),(0,-1),(0,1)]
# BFS遍历
def bfs(i,j):
queue = [(i,j)] # 接收到一个低洼初始点
visited[i][j] = True #将访问过的节点做标记
while queue:
x,y = queue.pop(0) #从队列中移除头部第一个元素,并将坐标付给x,y,队列:尾部进,头部出
#开始上下左右搜索
for dx,dy in direction:
nx,ny = dx + x,dy + y
#判断新位置是否在矩阵范围内,并且是未访问过,且是低洼带
if 0 <= nx < rows and 0 <= ny < cols and not visited[nx][ny] and matrix[nx][ny] == 1:
queue.append((nx,ny))
visited[nx][ny] = True
# 遍历整个数组
for i in range(rows):
for j in range(cols):
if matrix[i][j] == 1 and not visited[i][j]:
bfs(i,j)
count_lowlands += 1
return count_lowlands
if __name__ == '__main__':
matrix = [
[0, 1, 1, 0, 0],
[1, 0, 0, 0, 1],
[0, 1, 0, 0, 1],
[0, 1, 1, 1, 0]
]
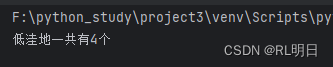
result = flood_problem(matrix)
print(f'低洼地一共有{result}个')
2、迷宫问题——DFS解法与BFS解法
问题:
给定一个二维迷宫,其中 0 表示通路,1 表示墙壁。起点为 (0, 0),终点为 (3,2),求从起点到终点的最短路径。
maze = [
[0, 0, 1, 0],
[0, 0, 0, 0],
[0, 0, 1, 0],
[0, 1, 0, 0],
[0, 0, 0, 1]
]
1、DFS栈的解法
DFS 通常不是最优选择,因为它可能会首先探索一个路径直到底部,然后回溯并探索另一路径,这可能导致找到的路径并非最短。通常,广度优先搜索 (BFS) 更适合解决这类最短路径问题。
def shortest_path_dfs(maze, start, end):
if not maze or not maze[0]:
return None
rows, cols = len(maze), len(maze[0])
visited = [[False] * cols for _ in range(rows)] # 记录节点是否已访问
path = [] # 记录路径
# 定义方向数组,表示上、下、左、右四个方向
directions = [(-1, 0), (1, 0), (0, -1), (0, 1)]
# 定义DFS栈的解法
def dfs_stack():
stack = [(start, [start])] # 元组的第一个元素是位置,第二个元素是到达该位置的路径
visited[start[0]][start[1]] = True
while stack:
(x, y), current_path = stack.pop()
if (x, y) == end:
return current_path
for dx, dy in directions:
nx, ny = x + dx, y + dy
# 判断新位置是否在矩阵范围内,并且未访问过且是通路
if 0 <= nx < rows and 0 <= ny < cols and not visited[nx][ny] and maze[nx][ny] == 0:
stack.append(((nx, ny), current_path + [(nx, ny)]))
visited[nx][ny] = True
return []
path = dfs_stack()
return path
if __name__ == '__main__':
# 示例迷宫
maze = [
[0, 0, 1, 0],
[0, 0, 0, 0],
[0, 0, 1, 0],
[0, 1, 0, 0],
[0, 1, 0, 1],
[0, 0, 0, 1]
]
# 起点和终点
start = (0, 0)
end = (3, 2)
# 调用DFS栈的解法
result_path = shortest_path_dfs(maze, start, end)
# 输出路径
print("路径:", result_path)

2、DFS递归解法
def find_path_dfs(maze,start,end):
if not maze or not maze[0]:
return None
rows,cols = len(maze),len(maze[0])
visited = [[False] * cols for _ in range(rows)]
path = []
#定义方向组,表示上下左右
directions = [(-1,0),(1,0),(0,-1),(0,1)]
#定义DFS函数
def dfs(x,y):
if x == end[0] and y == end[1]:
path.append((x,y))
return True
visited[x][y] = True
for dx,dy in directions:
nx,ny = dx + x,dy + y
# 判断新位置是否在矩阵范围内,并且未访问过且是通路
if 0 <= nx < rows and 0 <= ny < cols and not visited[nx][ny] and maze[nx][ny] == 0:
path.append((x,y))
if dfs(nx,ny):
return True
path.pop() #删除最后一个元素,回溯
return False
dfs(start[0],start[1])
return path
if __name__ == '__main__':
# 示例迷宫
maze = [
[0, 0, 1, 0],
[0, 0, 0, 0],
[0, 0, 1, 0],
[0, 1, 0, 0],
[0, 0, 0, 1]
]
# 起点和终点
start = (0, 0)
end = (3, 2)
# 调用DFS解法
result_path = find_path_dfs(maze, start, end)
# 输出路径
print("路径:", result_path)3、BFS队列解法
from collections import deque
def shortest_path_bfs(maze, start, end):
if not maze or not maze[0]:
return None
rows, cols = len(maze), len(maze[0])
visited = [[False] * cols for _ in range(rows)] # 记录节点是否已访问
# 定义方向数组,表示上、下、左、右四个方向
directions = [(-1, 0), (1, 0), (0, -1), (0, 1)]
# 使用BFS队列的解法
queue = deque([(start, [])]) # 元组的第一个元素是位置,第二个元素是到达该位置的路径
visited[start[0]][start[1]] = True
while queue:
(x, y), current_path = queue.popleft()
if (x, y) == end:
return current_path + [(x, y)] # 找到终点,直接返回路径
for dx, dy in directions:
nx, ny = x + dx, y + dy
# 判断新位置是否在矩阵范围内,并且未访问过且是通路
if 0 <= nx < rows and 0 <= ny < cols and not visited[nx][ny] and maze[nx][ny] == 0:
queue.append(((nx, ny), current_path + [(x, y)]))
visited[nx][ny] = True
return None # 没有找到路径,返回None
if __name__ == '__main__':
# 示例迷宫
maze = [
[0, 0, 1, 0],
[0, 0, 0, 0],
[0, 0, 1, 0],
[0, 1, 0, 0],
[0, 1, 0, 1],
[0, 0, 0, 1]
]
# 起点和终点
start = (0, 0)
end = (3, 2)
# 调用BFS解法
result_path = shortest_path_bfs(maze, start, end)
# 输出路径
print("路径:", result_path)

3、数独游戏—剪枝
数独是一种逻辑游戏,要求在9×9的网格中填入数字1到9,使得每行、每列和每个3×3的小九宫格中都包含1到9的所有数字,而且不重复。求解下列数独。
[5, 3, 0, 0, 7, 0, 0, 0, 0],
[6, 0, 0, 1, 9, 5, 0, 0, 0],
[0, 9, 8, 0, 0, 0, 0, 6, 0],
[8, 0, 0, 0, 6, 0, 0, 0, 3],
[4, 0, 0, 8, 0, 3, 0, 0, 1],
[7, 0, 0, 0, 2, 0, 0, 0, 6],
[0, 6, 0, 0, 0, 0, 2, 8, 0],
[0, 0, 0, 4, 1, 9, 0, 0, 5],
[0, 0, 0, 0, 8, 0, 0, 7, 9]
这是一个典型的搜索与剪枝问题,可以用深度优先搜索(DFS)算法来解决,这个程序使用深度优先搜索算法,通过递归填充数独中的数字,同时进行剪枝,最终得到解答。
'''
在递归算法中,return False 通常表示当前的尝试未成功,需要进行回溯操作。回溯是一种算法思想,它涉及
到返回到先前的状态,撤销之前所做的一些操作,然后尝试其他可能的选择。
在解数独的例子中,当在某个位置尝试填充数字时,如果发现当前的填充方式无法满足数独规则,就会执行
return False。这时,程序会回溯到上一层递归,继续尝试其他数字或回到更上一层递归。
'''
# 判断是否有重复数字
def is_valid(board,row,col,num):
# 检查行中是否有重复数字
if num in board[row]:
return False
# 检查列中是否有重复数字
if num in [board[i][col] for i in range(9)]:
return False
# 检查3*3九宫格中是否有重复数字
start_row,start_col = 3 * (row // 3),3 * (col // 3)
for i in range(3):
for j in range(3):
if board[start_row+i][start_col+j] == num:
return False
return True
def solve_sudu(board):
for row in range(9):
for col in range(9):
if board[row][col] == 0: # 未填数字位置
for num in range(1,10):
if is_valid(board,row,col,num):
board[row][col] = num
if solve_sudu(board): # 递归调用
return True # 所有的空格都填满,有解,退出返回结果
board[row][col] = 0 # 回溯
return False # 所有的数字都尝试过了,无解,回归到上一层递归if solve_sudu(board):
return True # 所有的空格都填满,有解
if __name__ == '__main__':
# 示例数独
sudoku_board = [
[5, 3, 0, 0, 7, 0, 0, 0, 0],
[6, 0, 0, 1, 9, 5, 0, 0, 0],
[0, 9, 8, 0, 0, 0, 0, 6, 0],
[8, 0, 0, 0, 6, 0, 0, 0, 3],
[4, 0, 0, 8, 0, 3, 0, 0, 1],
[7, 0, 0, 0, 2, 0, 0, 0, 6],
[0, 6, 0, 0, 0, 0, 2, 8, 0],
[0, 0, 0, 4, 1, 9, 0, 0, 5],
[0, 0, 0, 0, 8, 0, 0, 7, 9]
]
solve_sudu(sudoku_board)
# 输出解答
for row in sudoku_board:
print(row)
可以多调试一下了解算法思想,特别是结合return Flase的回溯思想
4、单词接龙—双向BFS
给定两个单词(beginWord和endWord)和一个字典,找到从beginWord到endWord 的最短转换序列的长度。转换需遵循如下规律;
1.每次转换只能改变一个字母。
2.转换过程中的中间单词必须是字典中的单词。
说明:
如果不存在这样的转换序列,返回0。·所有单词具有相同的长度。
所有单词只由小写字母组成。字典中不存在重复的单词。
你可以假设beginWord和endWord是非空的,且二者不相同。
如题:
beginWord = "hit"
endWord = "cog"
wordList = ["hot", "dot", "dog", "lot", "log", "cog"]
求最短转换路径长度。
from collections import defaultdict,deque
def ladderLength(beginWord,endWord,wordList):
if endWord not in wordList and not beginWord and not endWord and not wordList:
return 0
# 构建通用状态字典,用于存储中间状态对应的单词列表
# word_dict={*ot': ['hot', 'dot', lot'], 'h*t': ['hot'], 'ho*: ['hot'], 'd*t': ['dot'],......
word_dict = defaultdict(list) # 构建一个默认value为list的字典
for word in wordList:
for i in range(len(word)):
word_dict[word[:i] + '*' + word[i+1:]].append(word)
# 双向BFS队列和访问集合
begin_queue = deque([(beginWord,1)]) # deque([('hit',1)])
end_queue = deque([(endWord,1)])
begin_visited = set([beginWord]) # {'hit'}
end_visited = set([endWord])
while begin_queue and end_queue:
# 从起点开始扩展
current_word,level = begin_queue.popleft() # current_word:'hit',level: 1
for i in range(len(current_word)):
intermediate_word = current_word[:i] + '*' + current_word[i+1:] # intermediate_word: '*it'
for next_word in word_dict[intermediate_word]:
if next_word in end_visited:
return level + end_queue[-1][1] # 相遇,返回总层数
if next_word not in end_visited:
begin_queue.append((next_word,level + 1))
begin_visited.add(next_word)
# 从终点开始扩展
current_word, level = end_queue.popleft()
for i in range(len(current_word)):
intermediate_word = current_word[:i] + '*' + current_word[i + 1:]
for next_word in word_dict[intermediate_word]:
if next_word in begin_visited:
return level + begin_queue[-1][1] # 相遇,返回总层级
if next_word not in end_visited:
end_queue.append((next_word, level + 1))
end_visited.add(next_word)
return 0 # 无法找到转画序列
if __name__ == '__main__':
# 示例
beginWord = "hit"
endWord = "cog"
wordList = ["hot", "dot", "dog", "lot", "log", "cog"]
result = ladderLength(beginWord, endWord, wordList)
print("最短转换序列长度:", result)

5、斐波那契数列—记忆化搜索
斐波那契数列中的每个数字都是前两个数字之和,即F(n) = F(n-1) + F(n-2),其中 F(0) = 0,
F(1) = 1。计算斐波那契数列的第 10 项。
# 记忆化搜索的斐波那契数列计算
def fibonacci(n, memo={}):
# 如果已经计算过该值,直接返回
if n in memo:
return memo[n]
# 斐波那契数列的基本情形
if n == 0:
return 0
elif n == 1:
return 1
# 计算并保存结果
result = fibonacci(n-1, memo) + fibonacci(n-2, memo)
memo[n] = result
return result
if __name__ == '__main__':
# 计算斐波那契数列的第 10 项
result = fibonacci(10)
print("斐波那契数列第 10 项:", result)
6、八数码—迭代加深搜索
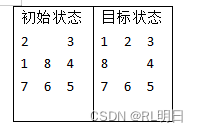
一个经典的使用迭代加深搜索的例子是在八数码问题中找到最短路径。八数码问题是一个经典的拼图问题,目标是将一个3x3的九宫格中的数字从初始状态调整为目标状态。在每一步中,只允许交换空格与相邻数字的位置。求解下述八数码的最短路径。
'''
初始状态
2 3
1 8 4
7 6 5
目标状态
1 2 3
8 4
7 6 5
'''
def iterative_deepening_search(start_state, target_state, max_depth):
for depth in range(1, max_depth + 1):
result = depth_limited_search(start_state, target_state, depth)
if result is not None:
return result
return None
def depth_limited_search(current_state, target_state, depth, current_depth=0, path=[]):
if current_depth == depth:
return None
if current_state == target_state:
return path + [current_state]
for neighbor_state in get_neighbors(current_state):
if neighbor_state not in path:
result = depth_limited_search(neighbor_state, target_state, depth, current_depth + 1, path + [current_state])
if result is not None:
return result
return None
def get_neighbors(state):
# 根据八数码问题定义获取当前状态的相邻状态
neighbors = []
zero_index = state.index(0)
row, col = zero_index // 3, zero_index % 3
# 上下左右移动空格
for dr, dc in [(0, 1), (0, -1), (1, 0), (-1, 0)]:
new_row, new_col = row + dr, col + dc
if 0 <= new_row < 3 and 0 <= new_col < 3:
new_index = new_row * 3 + new_col
new_state = list(state)
new_state[zero_index], new_state[new_index] = new_state[new_index], new_state[zero_index]
neighbors.append(tuple(new_state))
return neighbors
if __name__ == '__main__':
# 示例:解决八数码问题
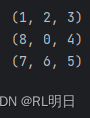
start_state = (2, 3, 1, 8, 0, 4, 7, 6, 5) # 初始状态
target_state = (1, 2, 3, 8, 0, 4, 7, 6, 5) # 目标状态
max_depth_limit = 30 # 设置最大深度限制
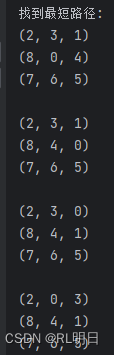
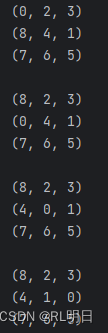
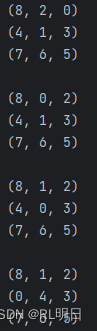
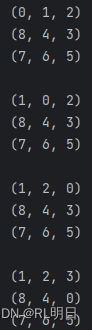
result_path = iterative_deepening_search(start_state, target_state, max_depth_limit)
if result_path is not None:
print("找到最短路径:")
for state in result_path:
print(state[:3])
print(state[3:6])
print(state[6:])
print()
else:
print("未找到最短路径")
7、八数码—启发式搜索
'''
初始状态
2 3
1 8 4
7 6 5
目标状态
1 2 3
8 4
7 6 5
'''
from queue import PriorityQueue
def heuristic(state, target):
distance = 0
for i in range(3):
for j in range(3):
value = state[i][j]
if value != 0:
try:
target_row, target_col = divmod(target.index(value), 3)
except ValueError:
continue
distance += abs(i - target_row) + abs(j - target_col)
return distance
def print_move(state):
for row in state:
print(row)
print()
def a_star_search(initial_state, target_state):
frontier = PriorityQueue()
frontier.put((0, initial_state, []))
explored = set()
while not frontier.empty():
_, current_state, path = frontier.get()
if current_state == target_state:
return path + [(current_state, "Goal")]
if current_state in explored:
continue
explored.add(current_state)
for neighbor_state, move in get_neighbors(current_state):
if neighbor_state not in explored:
new_path = path + [(current_state, move)]
cost = len(new_path) + heuristic(neighbor_state, target_state)
frontier.put((cost, neighbor_state, new_path))
return None
def get_neighbors(state):
neighbors = []
zero_row, zero_col = find_zero_position(state)
for dr, dc, move in [(0, 1, "Right"), (0, -1, "Left"), (1, 0, "Down"), (-1, 0, "Up")]:
new_row, new_col = zero_row + dr, zero_col + dc
if 0 <= new_row < 3 and 0 <= new_col < 3:
new_state = list(map(list, state))
new_state[zero_row][zero_col], new_state[new_row][new_col] = new_state[new_row][new_col], 0
neighbors.append((tuple(map(tuple, new_state)), move))
return neighbors
def find_zero_position(state):
for i in range(3):
for j in range(3):
if state[i][j] == 0:
return i, j
if __name__ == '__main__':
# 示例:解决八数码问题
initial_state = (
(2, 3, 0),
(1, 8, 4),
(7, 6, 5)
)
target_state = (
(1, 2, 3),
(8, 0, 4),
(7, 6, 5)
)
result_path = a_star_search(initial_state, target_state)
if result_path is not None:
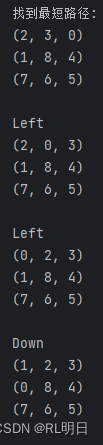
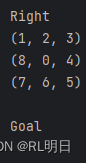
print("找到最短路径:")
for state, move in result_path:
print_move(state)
print(move)
else:
print("未找到最短路径")















 4380
4380











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









