







GAN
安装过程
本次StyleGAN2的结构解读主要是基于paddleGAN(可以使用百度的算力,所以没有选pytorch),代码直接通过git clone 到本地 按照github上的readme安装相应的包即可。
结构分析
StyleGAN2主要可以分为映射网络,生成网络组成。下面主要分析生成器网络。
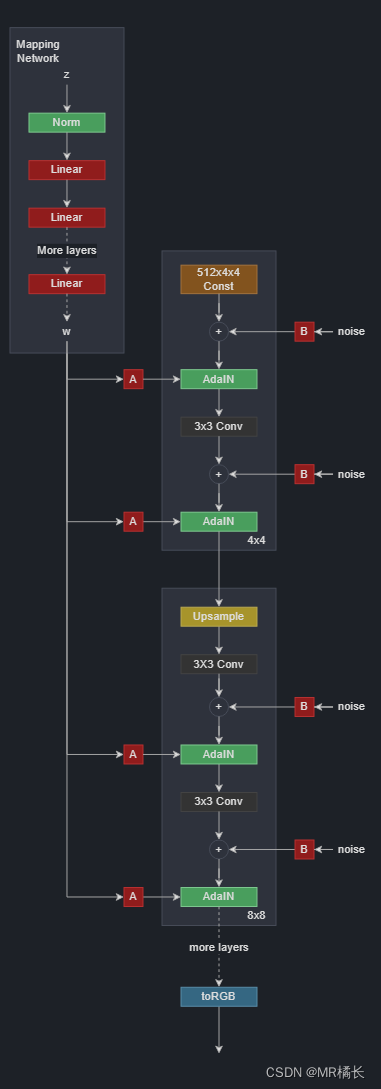
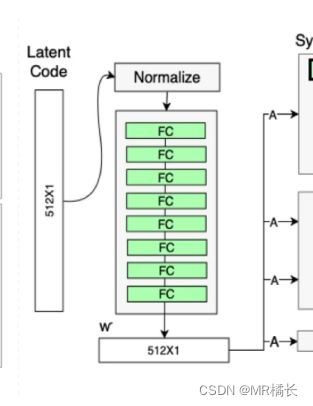
映射网络
映射网络(Mapping Network)是StyleGAN2中的一个重要组成部分,它将输入的潜在向量(Latent Vector)映射到一个更高维度的向量空间中,使得生成器能够更好地控制图像的各个方面。
映射网络主要由多个全连接层组成,这些层的作用是将输入的潜在向量映射到一个更高维度的向量空间中。StyleGAN2采用了多个映射网络,每个映射网络的深度和层数不同,以便生成器能够更好地控制不同层次的图像特征。
生成器结构
PaddleGAN关于styleGAN2的模型构建部分代码在:\PaddleGAN\ppgan\models\generators\generator_styleganv2.py
def forward(
self,
styles,
return_latents=False,
inject_index=None,
truncation=1.0,
truncation_cutoff=None,
truncation_latent=None,
input_is_latent=False,
noise=None,
randomize_noise=True,
):
# 输入映射为w,默认为8层全连接层
if not input_is_latent:
styles = [self.style(s) for s in styles]
if truncation < 1.0: # # 该操作使得latent code w在平均值附近,生图质量不会太糟
style_t = []
if truncation_latent is None:
truncation_latent = self.get_mean_style()
cutoff = truncation_cutoff
for style in styles:
if truncation_cutoff is None:
style = truncation_latent + \
truncation * (style - truncation_latent)
else:
style[:, :cutoff] = truncation_latent[:, :cutoff] + \
truncation * (style[:, :cutoff] - truncation_latent[:, :cutoff])
style_t.append(style)
styles = style_t
if len(styles) < 2: # 如果输入1个隐层码
inject_index = self.n_latent
if styles[0].ndim < 3: # 如果输入的是w,ndim=2,维度为(batch,512)
latent = styles[0].unsqueeze(1).tile((1, inject_index, 1))
# 将w升维、复制为(batch,18,512)维度
else: # 如果输入的是w+,维度为(batch,18,512),直接用就行
latent = styles[0]
else: # 如果输入2组w
if inject_index is None:
inject_index = random.randint(1, self.n_latent - 1)
# 返回 [1, 17] 之间的随机整数,我叫它i吧
latent = styles[0].unsqueeze(1).tile((1, inject_index, 1))
# 第1个w升维为(batch, i, 512)
latent2 = styles[1].unsqueeze(1).tile(
(1, self.n_latent - inject_index, 1))
# 第2个w升维为(batch, 18-i, 512)
latent = paddle.concat([latent, latent2], 1)
# 将2个w concat为(batch, 18, 512)维度
# 这里应该指的是style mixing,在第i层前用A图的latent code控制生图的低分辨率特征;
# 在第i层后用B图的latent code控制高分辨率图特征,从而混合了A、B两张图
# if not input_is_affined_latent:
# latent是一个(batch, 18, 512)
styles = self.style_affine(latent)
# 下面主要的是生成的图像的代码部分
image = self.synthesis(styles, noise, randomize_noise)
if return_latents:
return image, latent
else:
return image, None
self.synthesis的代码
def synthesis(self,
latent,
noise=None,
randomize_noise=True,
is_w_latent=False):
out = self.input(latent[0].shape[0])
if noise is None:
if randomize_noise:
noise = [None] * self.num_layers
# noise = [paddle.randn(getattr(self.noises, f"noise_{i}").shape) for i in range(self.num_layers)]
else:
noise = [
getattr(self.noises, f"noise_{i}")
for i in range(self.num_layers)
]
#这里是生成器的第一层和第二层,用于生成最低分辨率的图像
out = self.conv1(out, latent[0], noise=noise[0])
skip = self.to_rgb1(out, latent[1])
i = 2
'''
是否使用了concatenate操作。如果使用了,那么在这个循环中,网络会对两个不同的分辨率的特征图进行concatenate操作,
即将低分辨率的特征图和高分辨率的特征图按照空间位置进行连接,从而获得更高维度的特征图。
而如果没有使用concatenate操作,那么网络就直接将低分辨率的特征图进行上采样,然后与高分辨率的特征图进行相加,
从而得到更高分辨率的特征图
'''
if self.is_concat:
noise_i = 1
for conv1, conv2, to_rgb in zip(self.convs[::2], self.convs[1::2],
self.to_rgbs):
out = conv1(out, latent[i],
noise=noise[(noise_i + 1) // 2]) ### 1 for 2
out = conv2(out, latent[i + 1],
noise=noise[(noise_i + 2) // 2]) ### 1 for 2
skip = to_rgb(out, latent[i + 2], skip)
i += 3
noise_i += 2
else:
# 8次循环 ,每次循环处理的是一个分辨率层
for conv1, conv2, noise1, noise2, to_rgb in zip(
self.convs[::2], self.convs[1::2], noise[1::2], noise[2::2],
self.to_rgbs):
out = conv1(out, latent[i], noise=noise1)
out = conv2(out, latent[i + 1], noise=noise2)
skip = to_rgb(out, latent[i + 2], skip)
i += 3
'''
每次处理一个分辨率层的生成,而在StyleGAN2中,每个分辨率层对应了3个潜码向量,
分别是w、c和y,所以在每次循环中需要将i增加3,以便获取下一个分辨率层的3个潜码向量。
'''
return skip # image = skip
下面是生成器的详细结构,生成器以学习常数开始。然后它有一系列的块。每个块的特征图分辨率加倍每个块输出一个 RGB 图像,然后将它们按比例放大并求和以获得最终的 RGB 图像。
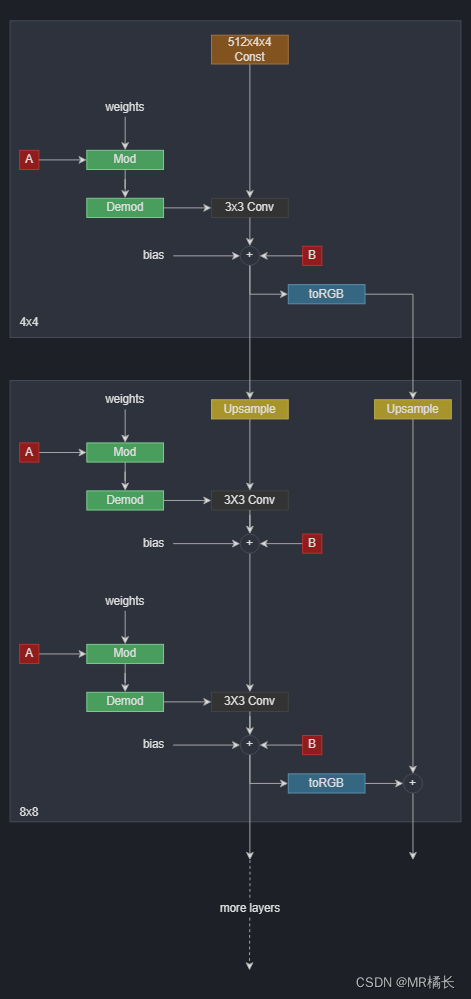
#这里是就是不断地增加分辨率,每次循环处理的是一个分辨率层
for conv1, conv2, noise1, noise2, to_rgb in zip(
self.convs[::2], self.convs[1::2], noise[1::2], noise[2::2],
self.to_rgbs):
out = conv1(out, latent[i], noise=noise1)
out = conv2(out, latent[i + 1], noise=noise2)
skip = to_rgb(out, latent[i + 2], skip)
ToRGB层由一个全连接层,一个自定义卷积层和一个激活函数层组成,包含可学习参数bias。
如果在调用 ToRGB 时指定了 skip 参数,那么该模块还会进行上采样操作并将上一层的特征图与当前层的特征图进行相加,以便更好地保留高分辨率细节、
class ToRGB(nn.Layer):
def __init__(self,
in_channel,
style_dim,
upsample=True,
blur_kernel=[1, 3, 3, 1]):
super().__init__()
if upsample:
self.upsample = Upfirdn2dUpsample(blur_kernel)
self.conv = ModulatedConv2D(in_channel,
3,
1,
style_dim,
demodulate=False)
self.bias = self.create_parameter((1, 3, 1, 1),
nn.initializer.Constant(0.0))
def forward(self, inputs, style, skip=None):
out = self.conv(inputs, style)
out = out + self.bias
if skip is not None:
skip = self.upsample(skip)
out = out + skip
return out















 938
938











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









