






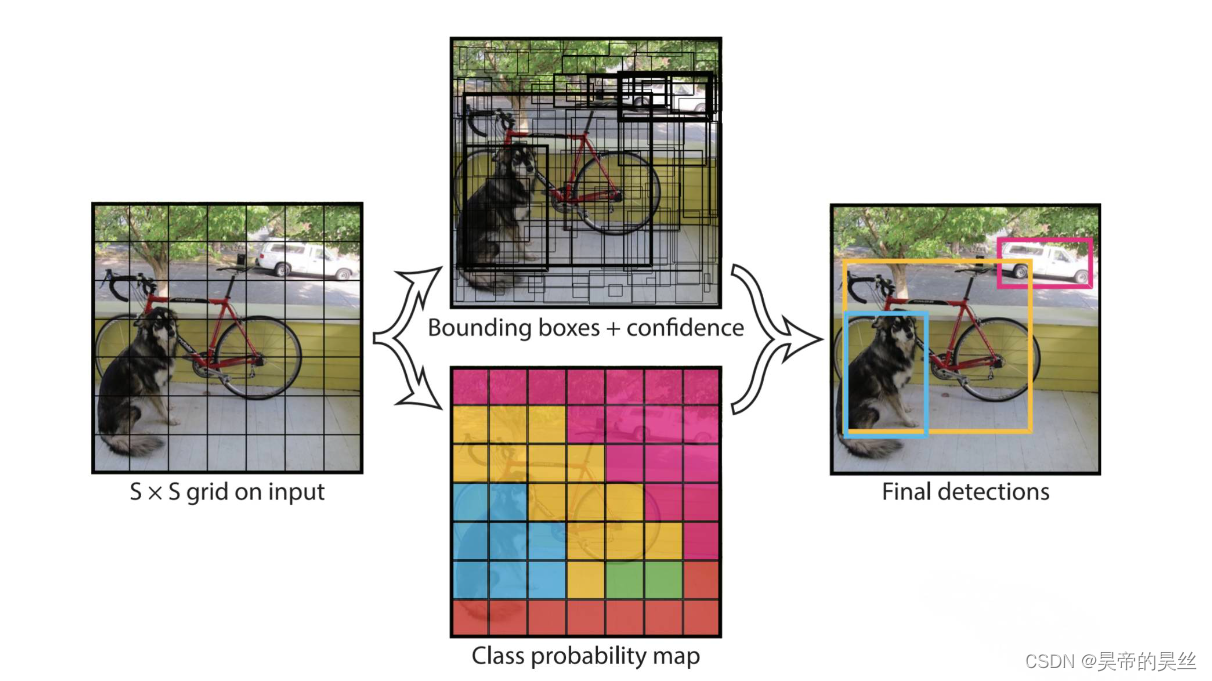
YOLO算法
最原始的是划窗法
在Faster R-CNN中,是通过一个RPN来获得目标的感兴趣区域,这种方法精度高,但是需要额外再训练一个RPN网络,这无疑增加了训练的负担。
c o n f i d e n c e = P r ( o b j ) ∗ I O U t r u t h p r e d confidence=Pr(obj)*IOU_{truth}^{pred} confidence=Pr(obj)∗IOUtruthpred
NMS非极大值抑制
我们把B1成为极大bounding box,计算极大bounding box和其他几个bounding box的IOU,如果超过一个阈值,例如0.5,就认为这两个bounding box实际上预测的是同一个物体,就把其中confidence比较小的删除。
损失函数
l
o
s
s
=
λ
c
o
o
r
d
∑
i
=
0
S
2
∑
j
=
0
B
l
i
j
o
b
j
[
(
x
i
−
x
^
i
)
2
+
(
y
i
−
y
^
i
)
2
]
+
λ
c
o
o
r
d
∑
i
=
0
S
2
∑
j
=
0
B
l
i
j
o
b
j
[
(
x
i
−
x
^
i
)
2
+
(
h
i
−
h
^
i
)
2
]
+
∑
i
=
0
S
2
∑
j
=
0
B
l
i
j
o
b
j
(
C
i
−
C
^
i
)
2
+
λ
n
o
o
b
j
∑
i
=
0
S
2
∑
j
=
0
B
l
i
j
n
o
o
b
j
(
C
i
−
C
^
i
)
2
+
∑
i
=
0
S
2
l
i
o
b
j
∑
c
∈
classes
(
p
i
(
c
)
−
p
^
i
(
c
)
)
2
loss=\lambda_{coord}\sum_{i=0}^{S^2}\sum_{j=0}^{B}l_{ij}^{obj}[(x_i-\hat{x}_i)^2+(y_i-\hat{y}_i)^2]+\lambda_{coord}\sum_{i=0}^{S^2}\sum_{j=0}^{B}l_{ij}^{obj}[(x_i-\hat{x}_i)^2+(\sqrt{h}_i-\sqrt{\hat{h}}_i)^2]+\sum_{i=0}^{S^2}\sum_{j=0}^{B}l_{ij}^{obj}(C_i-\hat{C}_i)^2+\lambda_{noobj}\sum_{i=0}^{S^2}\sum_{j=0}^{B}l_{ij}^{noobj}(C_i-\hat{C}_i)^2+\sum_{i=0}^{S^2}l_i^{obj}\sum_{c \in \text{classes} }(p_i(c) - \hat{p}_i(c))^2
loss=λcoordi=0∑S2j=0∑Blijobj[(xi−x^i)2+(yi−y^i)2]+λcoordi=0∑S2j=0∑Blijobj[(xi−x^i)2+(hi−h^i)2]+i=0∑S2j=0∑Blijobj(Ci−C^i)2+λnoobji=0∑S2j=0∑Blijnoobj(Ci−C^i)2+i=0∑S2liobjc∈classes∑(pi(c)−p^i(c))2
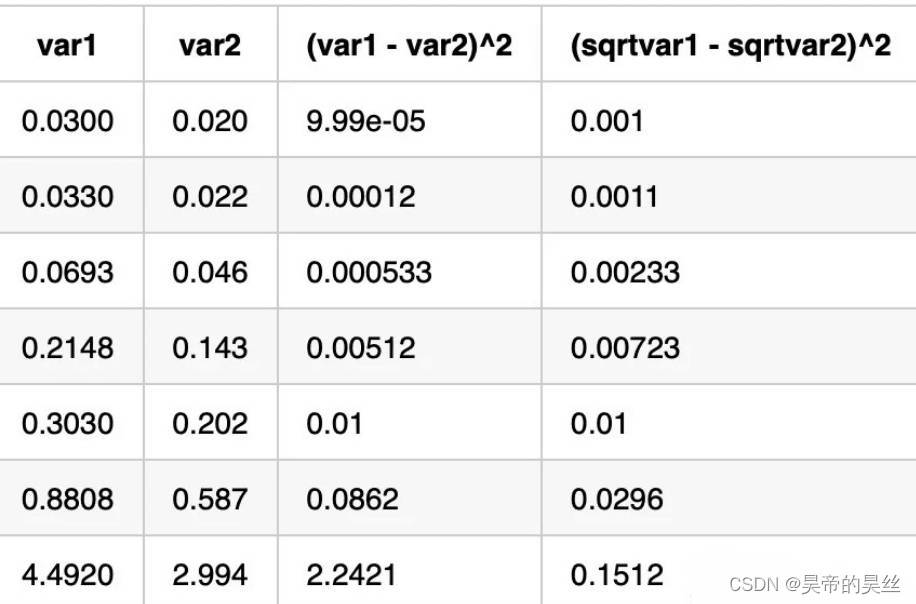
使用平方根的MSE而不是MSE其实就是像让模型对小尺度的物体更敏感。或者说,对大的和小的物体同样敏感。
让梯度更稳定,如果grid中不含有物体,它对1,2,3,5项没有影响,如果调节第四项,会让含有物体的grid的confidence发生改变,这可能使其他项的梯度剧烈变化,从而带来模型上的不稳定。
YOLO大致框架
backbone 特征提取
Neck 特征融合和增强
Head 检测和分类
Anchor boxes
引入了锚框(Anchor Boxes)的概念,即在每个网格单元中预定义一组不同尺度和长宽比的边界框。这种方法使得网络能够预测不同大小和形状的物体边界框,提高了检测多样性物体的能力。
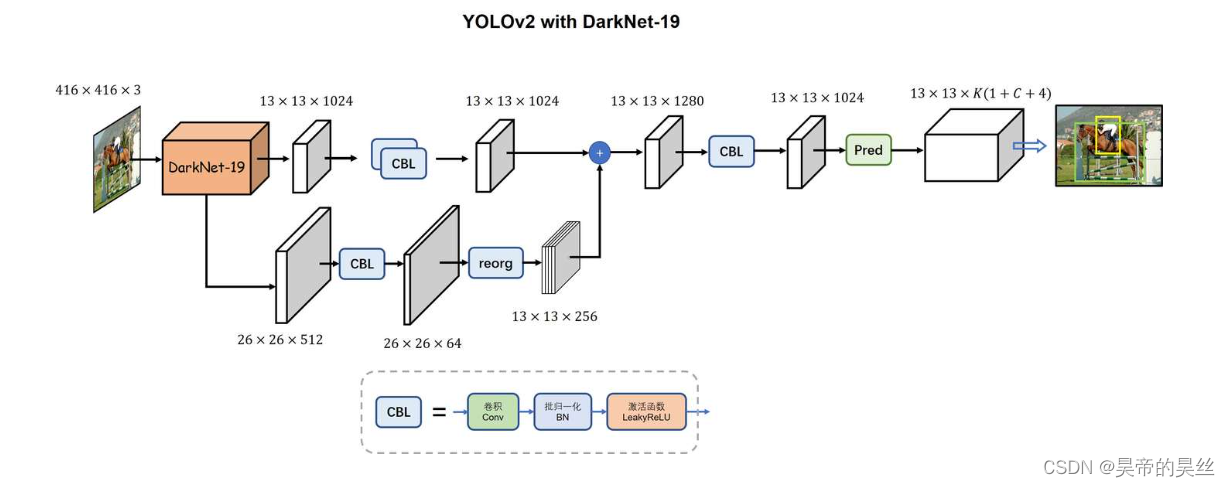
CBL 卷积层+批量化归一层+Leaky ReLU激活函数层
BN 批量归一化,帮助避免梯度消失或爆炸问题,加速模型的收敛过程。
Leaky ReLU 激活函数 引入非线性特性,帮助模型学习复杂的特征,同时防止梯度消失问题。
reorg
重组织(Reorganize)特征图,将低分辨率特征图重新排列为高分辨率特征图。
passthrough layer
通过将较早层的特征图与较晚层的特征图进行拼接,使得网络能够利用高分辨率的细节特征,提高了小物体的检测性能。
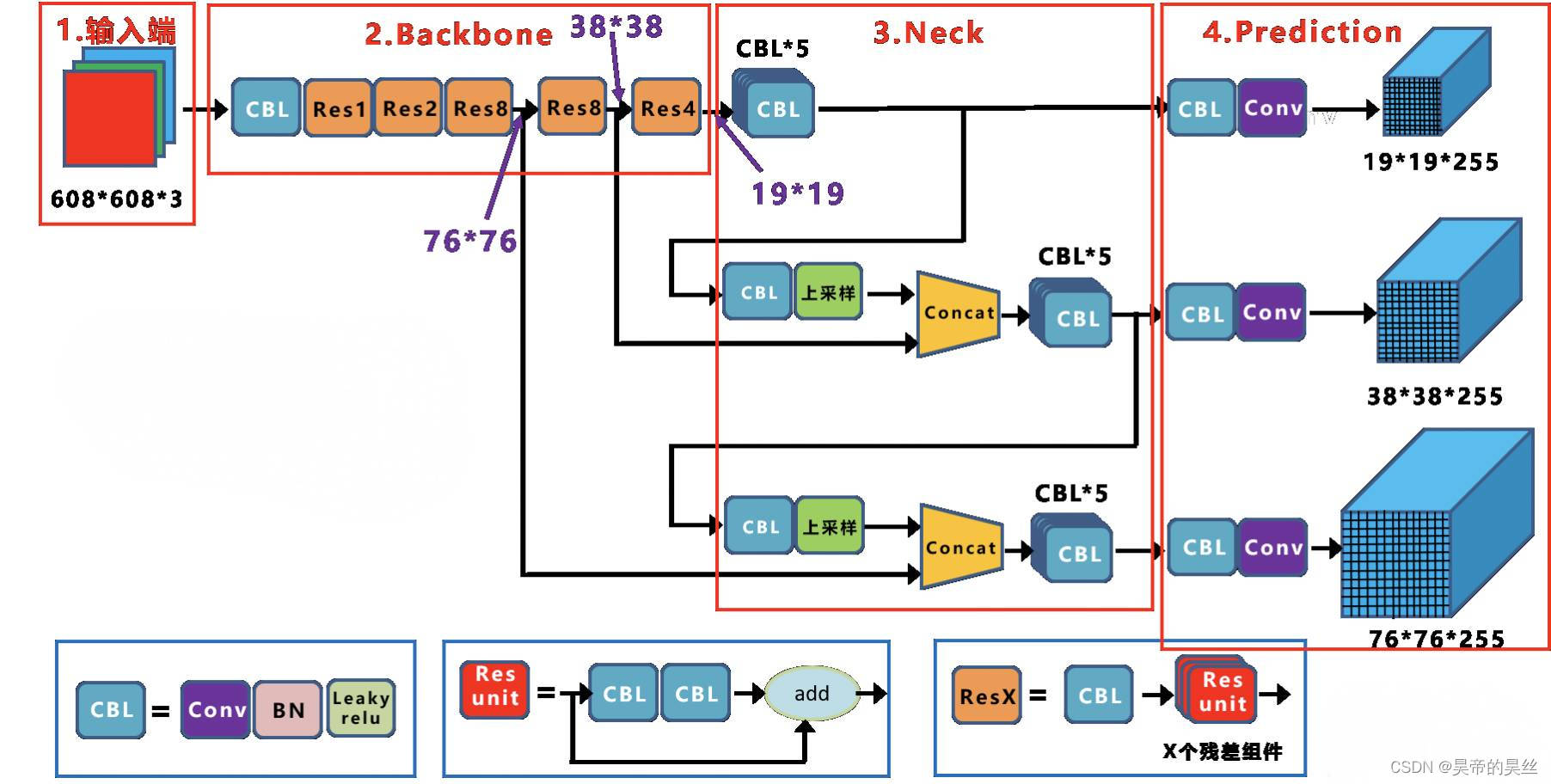
yolov3
darknet-53
Res unit通过引入跳跃连接,来帮助更深层次的网络更有效地训练,缓解梯度消失的问题。
Concat 张量拼接,会扩充两个张量的维度
add 张量相加,张量直接相加,不会扩充维度

yolov4
Mish 激活函数:在 CSPDarknet53 中,YOLOv4 使用了 Mish 激活函数,替代了一部分 Leaky ReLU 激活函数。Mish 函数在某些情况下能更好地捕捉复杂特征,提高模型性能。
f
(
x
)
=
{
x
,
i
f
x
≥
0
a
x
,
i
f
x
<
0
\begin{equation} f(x)=\left\{ \begin{aligned} x,\quad if\quad x\geq 0 \\ ax, \quad if \quad x<0\\ \end{aligned} \right . \end{equation}
f(x)={x,ifx≥0ax,ifx<0
其中a是一个小的常数,通常为0.01.
f
(
x
)
=
x
∗
t
a
n
h
(
l
n
(
1
+
e
x
)
)
f(x)=x*tanh(ln(1+e^x))
f(x)=x∗tanh(ln(1+ex))
Mish 提供了更平滑的梯度和更强的非线性表达能力,在一些复杂任务中能表现出更好的性能。
CSP_X跨阶段连接会使得特征在不同阶段之间交换和融合,从而增加了特征的多样性和丰富度。提高了网络对目标的感知范围和理解能力。 每个CSP1_x模块后跟着的CBL序列有助于增强特征的非线性表达能力,使得网络可以更好地捕获图像中的复杂模式和结构。
SPP
- 将输入特征图进行不同尺度的池化(如 1x1, 5x5, 9x9, 13x13 等),然后将池化后的特征图拼接起来。
- 增强特征图的感受野,使得模型能够更好地捕捉到不同尺度下的特征信息。
- 有助于提高模型对不同大小目标的检测能力,特别是在存在多尺度对象时表现更好。
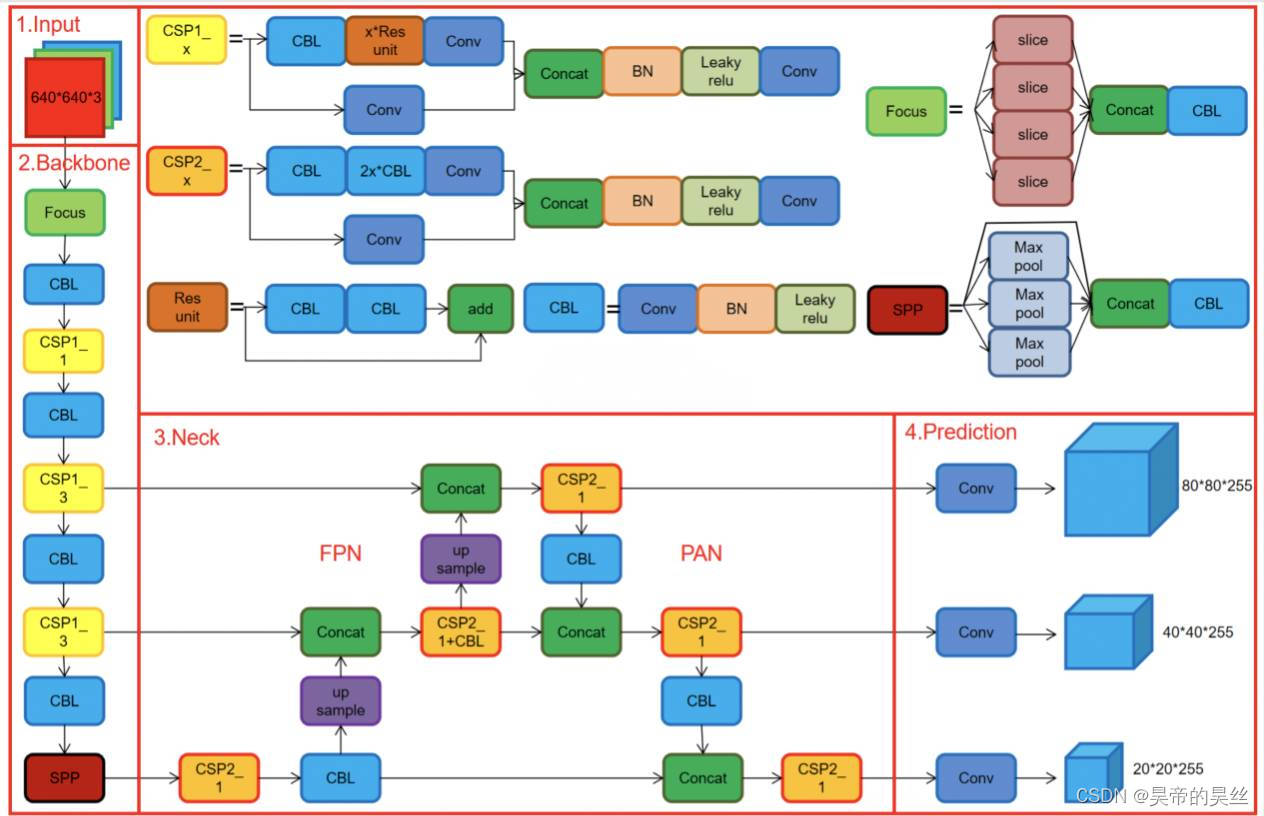
focus slice+concat拼接+CBL
将4×4×3的特征图经过切片处理,变成2×2×12的特征图。将608×608×3 的三通道图像输进 Focus 结构,经过切片操作,先变成304×304×12 的特征图,之后,经过使用 32 个卷积核的卷积操作,最终变成 304×304×32 的特征图。
CSP1_x主要用于增加网络的感知范围和特征传递效率,而CBL主要用于增强特征提取过程中的非线性表达能力和稳定性。
CSP2_x位于较深的网络层级,通常位于网络的中间或末尾部分。它主要负责处理较高级别的语义特征,例如对物体形状、结构等更抽象的特征的感知。
YOLOv1-YOLOv5之间的对比如下表所示:
| model | backbone | neck | head |
|---|---|---|---|
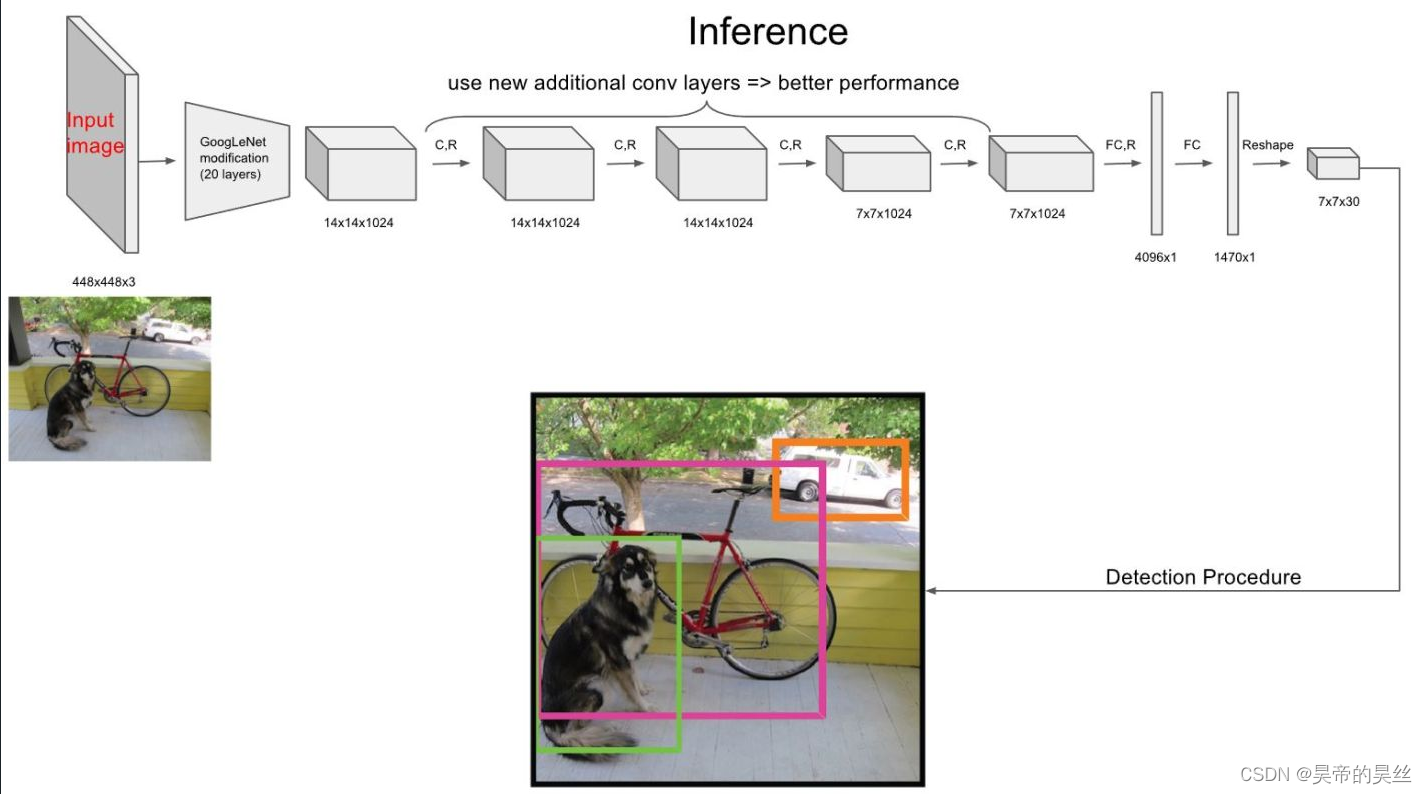
| yolov1 | googleNet(24Conv+2FC+reshape;Dropout防止过拟合;最后一层使用线性激活函数,其余层都使用ReLU激活函数); | 无 | IOU_Loss、nms;一个网格只预测了2个框,并且都属于同一类;全连接层直接预测bbox的坐标值; |
| yolov2 | Darknet-19(19Conv+5MaxPool+AvgPool+Softmax;没有FC层,每一个卷积后都使用BN和ReLU防止过拟合(舍弃dropout);提出passthrough层:把高分辨率特征拆分叠加大到低分辨率特征中,进行特征融合,有利于小目标的检测); | 无 | IOU_Loss、nms;一个网络预测5个框,每个框都可以属于不同类;预测相对于anchor box的偏移量;多尺度训练(训练模型经过一定迭代后,输入图像尺寸变换)、联合训练机制; |
| yolov3 | Darknet-53(53*Conv,每一个卷积层后都使用BN和Leaky ReLU防止过拟合,残差连接); | FPN(多尺度检测,特征融合) | IOU_Loss、nms;多标签预测(softmax分类函数更改为logistic分类器); |
| yolov4 | CSPDarknet53(CSP模块:更丰富的梯度组合,同时减少计算量、跨小批量标准化(CmBN)和Mish激活、DropBlock正则化(随机删除一大块神经元)、采用改进SAM注意力机制:在空间位置上添加权重); | SPP(通过最大池化将不同尺寸的输入图像变得尺寸一致)、PANnet(修改PAN,add替换成concat) | CIOU_Loss、DIOU_nms;自对抗训练SAT:在原始图像的基础上,添加噪音并设置权重阈值让神经网络对自身进行对抗性攻击训练;类标签平滑:将绝对化标签进行平滑(如:[0,1]→[0.05,0.95]),即分类结果具有一定的模糊化,使得网络的抗过拟合能力增强; |
| yolov5 | CSPDarknet53(CSP模块,每一个卷积层后都使用BN和Leaky ReLU防止过拟合,Focus模块); | SPP、PAN | GIOU_Loss、DIOU_Nms;跨网格匹配(当前网格的上、下、左、右的四个网格中找到离目标中心点最近的两个网格,再加上当前网格共三个网格进行匹配); |















 1796
1796











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









