







一些工作能够检测包含特定动作的视频片段,一般称 为动作检测(action detection)或视频中的时序动作定位(Temporal Action Grounding in Videos,TAGV)
然而,
TAGV
受限于预先定义的动作类别集合,不能 完全覆盖所有的活动。因此,引入自然语言描述复杂多样的活动更为合理,视频中的时序定位(Temporal Sentence Grounding in Videos,
TSGV)就是这样一项
任务 :使一个句子查询与视频中具有相同语义的一个片段(也被称作时刻)相匹配。
TSGV
的目标是预测目标片段在
原视频中的起点和终点。

TSGV
可以 作为各种下游视觉 -
语言任务的中间任务,例如视 频问答和视频内容检索。
由于以下原因,
TSGV 更具挑战性 :
•
视频和句子查询都是具有丰富的语义和时序 性的。因此,视频和句子之间的匹配关系相当复杂,
需要以更精细的方式建模,以实现准确的时间定位。
•
与查询相对应的目标片段在空间和时间尺度上 是相当灵活的。如果通过滑动窗口获取候选视频片
段,计算成本会很高。因此,如何有效地全面覆盖目标片段,也是 TSGV
面临的挑战。
•
视频中的活动通常不是独立出现的,它们往往有内部的语义关联和时间上的相互依赖。因此,对
视频上下文信息在句子语义引导下的内在逻辑关系进行建模也十分重要。
根据是否生成候选片段和监督方 式的不同,可以将 TSGV
模型分为四大类。
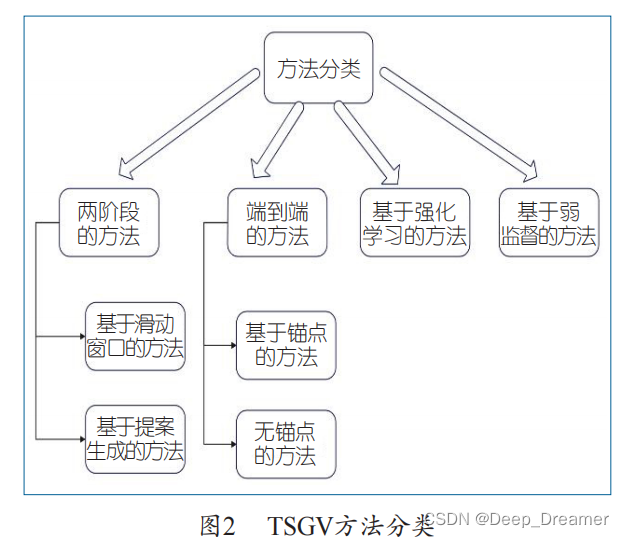
早期的 工作采用了两阶段的架构,即首先扫描整个视频, 并通过滑动窗口或提案生成网络(proposal generationnetwork)预先生成候选片段,然后根据跨模态匹配模块对候选片段进行排名。然而,候选片段的重叠导致了太多的冗余计算,而且单独的成对的片段查询匹配也可能忽略了上下文的视频信息。
一些研究人员开始尝试以端 到端方式解决 TSGV 问题。这种端到端模型没有预
先切割出候选片段作为模型的输入。有的方法采用
长短期记忆(
LSTM
)或卷积神经网络(
CNN
)依次
维护在每一时间步结束的多尺度候选片段,它们被
称为基于锚点(
anchor-based
)的方法。其他一些端
到端方法预测每个视频单元(即帧级或片段级)是
目标片段起点和终点的概率,或者根据整个视频和
句子查询的多模态特征直接回归目标起点和终点坐标。这些方法不依赖任何生成候选片段的过程,被称为无锚点(anchor-free
)的方法。
值得注意的是,有些工作借助深度强化学习技术解决 TSGV
问题,将这个任务视为一个顺序决策
过程,这也是无锚点的。除了上述三类全监督方法,为了减少标注真实标签的时刻边界所需的大量人力,也有人提出了只用视频级标注的弱监督方法。
两阶段方法
基于滑动窗口的方法
MCN
[23]
和
CTRL
[16]
是开创性的工作,它们定义 了TSGV
任务并构建了基准数据集。
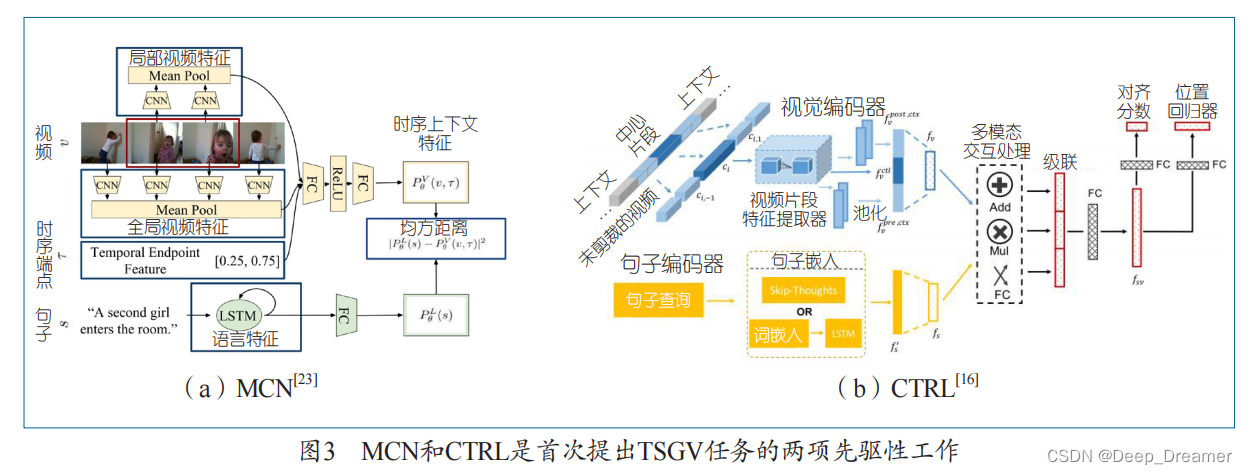
Hendricks
等人
[23] 提出 MCN
,它通过滑动窗口机制采样得到候选片段, 然后将视频片段表示和查询表示嵌入到同一个向量 空间。在这个空间中,句子查询和相应的目标视频 片段之间的 L2
距离被最小化,以监督模型的训练(参 见图 3
(a))。
Gao
等 人
[16]
提出了
CTRL
,这是第一个将 R-CNN[20]
从物体检测适应到
TSGV
的方法。
CTRL
利用滑动窗口获得不同长度的候选片段。如图
3
(b)
所示,它利用多模态处理模块将候选片段的表征与 句子表征相融合,然后将融合后的表征送入另一个 全连接层,以预测候选片段的对齐分数以及候选段 和目标段之间的位置偏移。
考虑到基于滑动窗口方法的缺点,一些研究致 力于减少候选片段的数量,被称为提案生成法。这
种方法仍然采用两阶段方案,但通过不同种类的提 案网络来避免密集的滑动窗口采样。
尽管两阶段方法取得了一定的成功,但也有一些 缺点。为了达到较高的定位精度(即候选片段中至少
应该有一个接近真实标注),候选片段的长度和位置
分布应该是多样化的,从而不可避免地增加了候选片
段的数量,导致后续匹配过程的计算效率低下。
端到端方法
基于锚点的模型
TGN
[5]
是一个典型的端到端深度神经网络结构, 它可以单程内定位目标时刻,而不用处理大量重叠 的预分割候选片段。TGN
通过细粒度逐词帧交互动 态匹配句子和视频单元。在每个时间步,定位器会 同时对结束于该时间步的一组不同时长的候选片段 进行评分。
Yuan
等人
[73]
提出了
SCDM,利用分层的时间卷
积网络进行目标片段定位,如图
4
所示,这个多
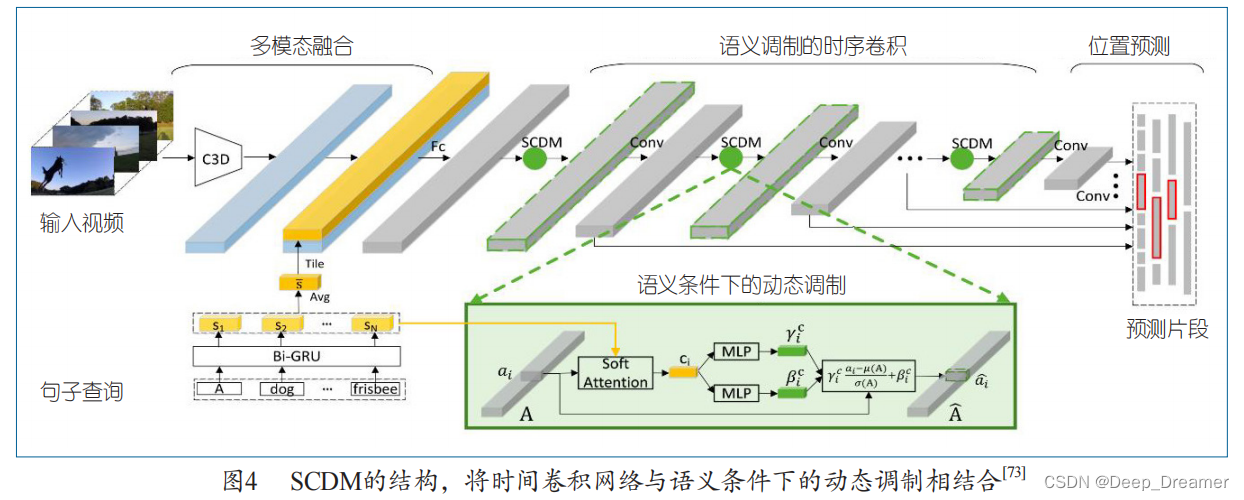
模态融合模块以细粒度的方式融合整个句子和每 个视频片段。将融合的表示作为输入,语义调制
的时间卷积模块在时间卷积过程中进一步关联与 句子相关的视频内容,动态调制与句子相关的时
间特征图。
尽管基于锚点的方法取得了卓越的性能,但其 性能对人工设计的启发式规则(即锚点的数量和尺
度)很敏感。因此,这种基于锚点的方法不适用于 视频长度可变的情况。同时,虽然不需要像两阶段 方法那样进行预分割,但它的结果仍取决于被提案 出的候选片段的排名,这也会影响其效率。
无锚点的模型
无锚点的方法没有对大量的候选方案进行排 名,而是着眼于更精细的视频单元,如帧或片段,
旨在预测每一帧
/
片段是目标片段的起点和终点的 概率,或者直接从全局角度回归起点和终点。
Yuan
等人提出了
ABLR
[75]
。为了保留上下文信 息,ABLR
首先通过双向
LSTM
网络对视频和句子 进行编码。然后,引入多模态协同注意力机制,既 生成能反映全局视频结构的视频注意力,还生成能 突出时间定位关键细节的句子注意力。最后,设计 了一个基于注意力的坐标预测模块,对时刻坐标进 行回归。
与基于锚点的方法相比,无锚点的方法具有更 高的计算效率和对可变时长视频的鲁棒性。虽然无
锚点的方法具有这些显著的优势,但它很难捕捉到 多模态交互的片段级特征。
基于强化学习的方法
作为另一种无锚点方法,基于强化学习的框架将 这样的任务视为一个连续的决策过程。每一步的行动 空间是一组人为设计的基本操作(如移位、缩放)
He
等人
[22]
首先引入深度强化学习技术解决 TSGV 任务,将
TSGV
形式化为一个顺序决策问
题,在每个时间步骤中,观察网络输出环境的当 前状态,供演员 -
评论员(
actor-critic
)模块生
成行动策略,在此基础上,智能体执行行动来调 整时间边界。
弱监督方法
之后,
TSGV
被扩展到训练阶段无法获得基准 事实片段位置的弱监督场景下,即弱监督 TSGV
。弱 监督方法大致可分为基于多实例学习(Multi-Instance Learning,
MIL
)和基于重建两类。
一些工作
[12, 17, 43, 55]
采用多实例学习,整个视频 被视为具有袋级标注的实例袋,对实例(视频段提案) 的预测被聚合为袋级预测.
TGA
[43]
是一种典型的基于
MIL
的方法,它通 过将视频和其对应描述的匹配分数最大化,同时将
视频和其他描述的匹配分数最小化来学习视频层面 的视觉 -
文本对齐。它提出了文本引导的注意力 (Text-Guided Attention
,
TGA
)来获得特定文本的 全局视频表征、学习视频和视频级描述的联合表征。
评估
指标
TSGV
有两类指标,即
mIoU
(即平均
IoU
)和 R@n
, IoU
=
m
。
IoU
在物体检测中被广泛用于评估两 个边界框之间的相似性,TSGV
也类似,采用时序 IoU 衡量片段相似性。指标
mIoU
通过平均所有样本 的时序 IoU
来评估结果。另一个常用的指标是
R@
n
, IoU=
m
[25]
。对于样本
i
,如果当前
n
个被检索的片段 中存在一个与基准片段的时间 IoU
超过
m
的片段时, 则视为检索成功。R@
n
, IoU
=
m
是检索成功的样本占 所有样本的百分比。研究者习惯设置 n
∈
{1, 5, 10}
和
m
∈
{0.3, 0.5, 0.7}
。通常,当方法采用无提案方式(即 属于无锚点或基于强化学习的框架)时,n
=1
。
时空定位
视频中的时空语句定位是
TSGV
的另一个扩展,它主要从视频中通过自然语言描述将
指定对象或实例定位为连续的时空管道(即边界框
序列)。















 739
739











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









