






视频时间定位旨在精确定位与查询描述匹配的视频片段。尽管最近短视频(例如,以分钟为单位)取得了进步,但长视频(如,以小时为单位)的时间基础仍处于早期阶段。现有的时间基础方法通常针对短格式视频(例如,以分钟为单位),并用少量帧(例如,128帧)来表征输入视频。然而,当涉及到长格式视频时间接地(LVTG)的情况时,将视频时间下采样(例如,以小时为单位)到如此少的帧可能会导致严重的信息丢失,并进一步导致性能急剧下降。为了应对这一挑战,一种常见的做法是采用滑动窗口,但由于窗口内的帧数量有限,滑动窗口可能效率低下且不灵活。
使用滑动窗口将长视频重新组织为短视频序列,并在每个窗口内执行时间定位。然而,如图上半部分所示的这种解决方案有三个主要缺点。(1) 推理效率低下:相邻窗口之间的重叠带来了多余的计算。此外,大量高度重叠的预测导致后处理(例如,非最大值抑制)耗时。(2) 训练不足:具有滑动窗口的网络一次只能扫描本地时间范围内的视频内容,而忽略了长范围的时间相关性。(3) 预测不灵活:预测被限制在一个窗口内,很难推广到持续时间长的片段。
在这项工作中,我们提出了一种基于锚点的端到端框架,称为SOONet,它通过只扫描一次长格式视频来促进高效准确的LVTG。如图1的下半部分所示,SOONet通过利用锚间上下文知识和锚内内容知识,遵循预排名、重新排名和回归的流程。
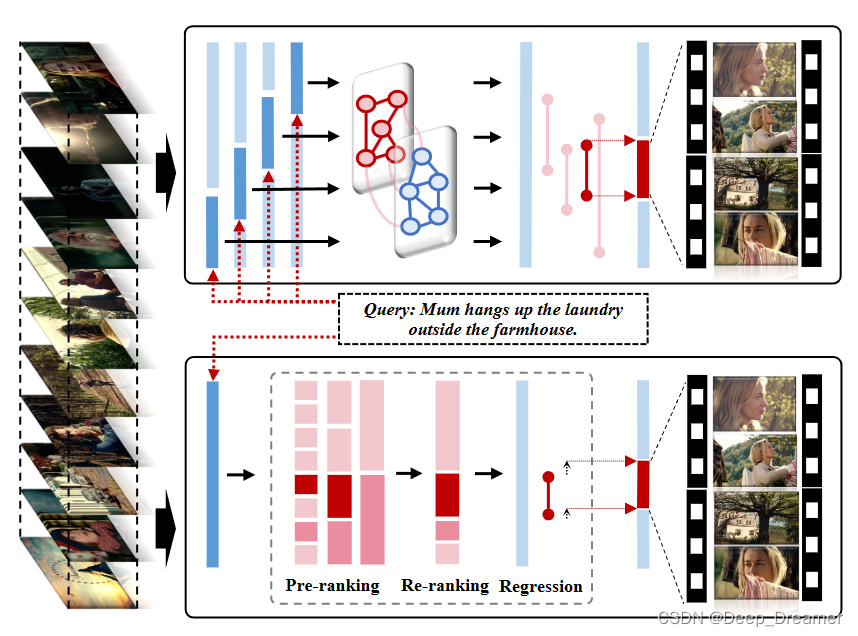
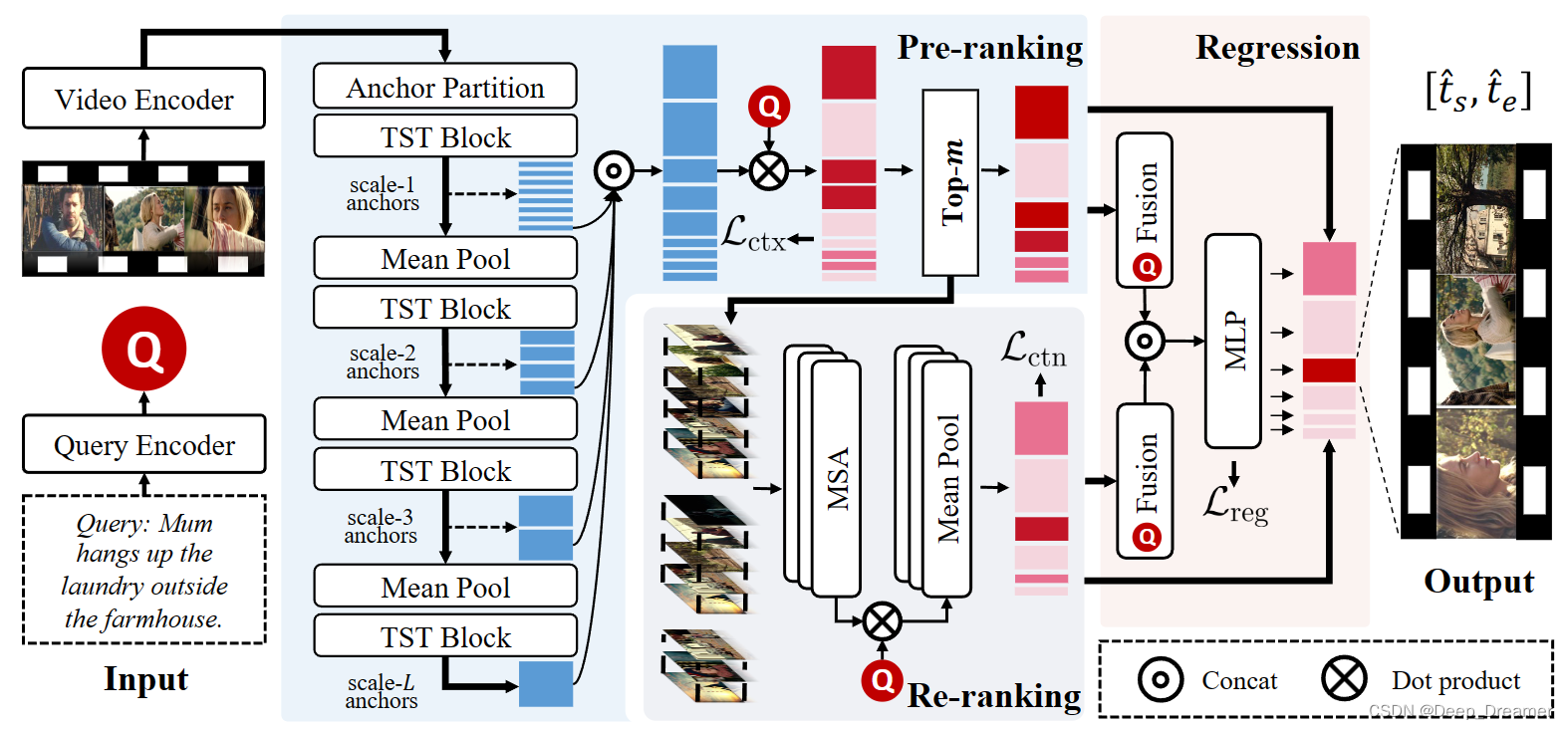
具体来说,我们首先通过锚划分层产生非重叠的锚序列,然后实现三个过程来获得最终预测:(1)通过级联的时间swin transformer块对锚之间的上下文知识建模来获取基于多尺度上下文的锚特征[12]。同时,通过对查询的基于上下文的匹配分数进行排序来获得粗略的锚秩。(2) 可以通过向锚补充详细的锚内内容知识来获得基于内容的锚特征和内容增强的锚排序 。我们从每个尺度中挑选出与查询高度对应的前m个锚点,形成锚点子集,然后在子集内实现重新排序,以降低计算复杂度。 (3) 采用边界回归来实现灵活的预测,同时利用锚间和锚内知识。为了充分利用长视频中丰富的跨模态语义关系,我们在一个训练步骤中用一批基于该视频的查询对一个视频进行采样,然后借助所提出的对偶形式近似秩损失同时优化全长锚秩和查询秩,从而实现了优越的跨模态对齐。
方法
我们的方法以长格式视频和句子查询作为输入,并以端到端的方式预测与查询语义相关的视频时刻。具体而言,我们的框架由三个模块组成:(1)锚知识预排序旨在通过使用级联的时间swin变换器块来对锚间上下文进行编码。然后,通过对与查询有关的基于上下文的匹配分数进行排序来获得粗略的锚秩。(2) 使用框架知识进行重新排序是为了对锚内内容知识进行建模,并计算与查询相关的基于内容的匹配分数。通过对基于上下文的匹配分数和基于内容的匹配分数求和来对锚候选者进行重新排序。(3) Boundary Regression旨在调整锚点边界,同时利用锚点间上下文和锚点内内容。我们的方法输出前n个锚点的调整边界作为最终预测。
Feature Extractor
给定未修剪的视频V={ft}T T=1和句子查询Q={wm}M M=1,其中T和M分别表示帧数和字数,LVTG任务需要定位与查询相对应的目标时刻(τs,τe)。为了实现这一点,我们采用现成的预训练模型来提取视觉特征V={v1,v2,…,vN}∈RN×Das以及文本特征Q={qcls,q1,q2,…,qM}∈R(M+1)×D。N、 M分别表示提取的帧特征和词特征的数量,D表示特征维度。查询特征q在 根据预训练模型的类型,以不同的方式提取查询特征q。对于用多模态预训练的模型(例如,CLIP[16]),我们取出嵌入类令牌的qcls作为查询特征。而对于其他模型(例如,BERT[3]),我们将单词嵌入通过可训练的LSTM[7]层来获取查询特征。然后,我们将视频特征V和查询特征q馈送到我们的网络中以用于下一过程。
Pre-ranking with Anchor Knowledge
多尺度锚生成。由于全局自注意的计算复杂度是序列长度的二次方,因此标准转换器在建模长格式视频的全长帧序列时计算量很大。为了减轻计算负担,我们首先使用单个卷积层从连续帧中产生不重叠的基础锚。配方如下:

其中E0∈RN C0×D,C0表示基础锚的长度。然后,我们采用具有池化层的L个级联的时间swin变换器块来编码锚间上下文知识,并获得基于多尺度上下文的锚特征E=[E1;E2;…;EL],其中L表示尺度的数量。每个锚点特征ei∈E对应于一个唯一的剪辑建议(ti s,ti E)。对于第l个比例的锚,相应的锚长度为

临时摆动变压器块。我们已经将Swin Transformer[12]中提出的基于移位窗口的自注意方法纳入一维序列编码中。该技术在本地窗口中有效地实现了自我关注,同时也在连续窗口之间建立了连接,以增强建模能力。通过这种方式,计算复杂度是随着序列长度线性缩放的。具体地说,每个时间摆动变换器块由局部窗口自注意层(W-MSA)、移位窗口自关注层(SW-MSA)和两个多层感知器(MLP)组成,它们可以公式化为:

对于每个基于上下文的锚特征ei∈E,通过计算锚特征和查询特征之间的余弦相似性,然后通过Sigmoid函数将其缩放到[0,1]来获得基于上下文的匹配分数:

最后,可以通过按降序对Sctx进行排序来获取粗略的锚秩。
Re-ranking with Frame Knowledge
为了减轻由预排名模块中的锚划分和池化操作引起的时间信息损失,重新排名模块对锚内的详细内容进行建模,并对候选锚进行重新排名。给定粗略的锚秩,我们首先从每个尺度分别收集前m个锚的索引,以建立锚子集,然后对于该子集中第l个尺度的第i个锚,我们获取锚内帧特征Vi={vk i}Clk=1,并采用标准的多头自注意模块(MSA)对锚内帧相关性进行建模:
其中fpos是用于注入位置信息的可训练位置嵌入。通过首先计算每个帧特征和查询特征之间的余弦相似度,然后对逐帧相似度进行平均,并通过Sigmoid函数将其缩放到[0,1],来获得第i个锚点的基于内容的匹配分数:

我们将基于上下文的分数和基于内容的分数相加,作为重新排序的最终匹配分数:
Boundary Regression
为了实现灵活的定位,使用边界回归模块向内或向外调整锚点边界。对于锚子集中第l尺度的第i个锚,给定基于上下文的锚特征ei和基于内容的锚特征576 Vi,我们将它们与查询融合以获得多模态融合特征,并将其通过MLP报头来预测开始和结束偏差:


在给定原始锚边界(ti s,ti e)的情况下,我们分别添加预测的开始和结束偏差,以获得调整后的边界:

最后,我们输出顶部Nanchor的调整后的边界(Dir ts,Dir te)作为最终预测。
Training
采用两个损失项来优化网络:(1)跨模态对准损失Lalign和(2)边界回归损失Lreg。总损失是两个损失项的加权组合:

Cross-modal Alignment Loss
我们将跨模态对齐丢失定义为基于上下文的对齐丢失Lctx和基于内容的对齐丢失Lctn的组合:

对于Lctx和Lctn,我们提出了一种双重形式的近似秩损失,该损失采用两个近似NDCG[14]损失项来同时优化锚秩和查询秩。我们首先回顾了近似NDCG损失,并引入了对偶形式的近似秩损失,然后给出了Lctxan和Lctn的形式定义。
NDCG损失。给定大量的候选锚点,我们的目标是获得这样一个锚点秩:与查询语义相关的锚点应该排在不相关的锚点之前。为了实现这一目标,而不是现有方法中常用的逐点或成对秩损失,我们采用列表式ApprovxNDCG损失来从全局角度优化锚秩:

其中S表示候选锚的匹配分数,K是候选锚的数量,Zm是最佳秩的贴现累积增益。yi表示第i个锚点和查询之间的匹配度,该匹配度等于它们的边界框的时间IoU:

πi是第i个锚的秩的可微近似:

其中α表示温度参数。对于每个主播,ApproxNDCG损失将其与所有其他主播进行比较,以决定其排名,充分利用了长视频中的语义关系。
双重形式近似秩损失。除了锚点秩优化之外,考虑到长格式视频数据集的独特性,我们引入了一种“一个视频带批量查询”的数据采样策略,该策略在一个训练步骤中对一个视频和基于该长视频的一批查询进行采样,并使用另一个ApprovxNDCG损失来同时优化查询秩:

其中Sa和Sq分别表示锚候选和查询候选的匹配分数。现在,我们将基于上下文的对齐丢失Lctx和基于内容的对齐丢失Lctn定义为:

其中Sactx和Sactn分别表示基于上下文的全长锚匹配分数和基于内容的mL长度锚匹配分数。同样,Sqctx和Sqctn分别表示基于上下文和基于内容的查询匹配分数。
Boundary Regression Loss
我们将边界回归损失定义如下:

其中,(Plot ti s,Plot ti e)是第i个锚的调整后的边界。IoU损失[25]用于回归锚点边界和地面实况时刻之间的开始和结束偏差:


我们提出了一个端到端的框架SOONet,用于长视频的快速时间基础。它能够通过一次性网络执行对一个小时长的视频进行建模,缓解了滑动窗口管道造成的效率低下问题。此外,它将锚间上下文知识和锚内内容知识与精心定制的网络结构和训练目标相结合,从而实现准确的时间边界定位。在MAD和Ego4数据集上进行的大量实验证明了我们的SOONet在准确性和效率方面的优势。














 2818
2818











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









