







原文地址:DOI: 10.1103/PhysRevE.106.034315
1.摘要
众多复杂系统的动力学过程可以理解为在给定网络结构上相互作用的节点的动态演化。然而,从节点行为的时间序列中找到这样的交互结构和节点动态是困难的。传统方法要么专注于网络结构推断任务,要么关注动态重建问题,很少有方法能够在两者上都表现良好。本文提出了一个通用的框架,可以同时从观测到的节点时间序列数据中重建网络结构和节点动态。我们使用可微分的伯努利采样过程来生成候选网络结构,并使用神经网络来基于候选网络模拟节点动态。然后,我们使用随机梯度下降算法调整所有参数,以最大化定义在数据上的似然函数。实验证明,我们的模型可以高准确度地恢复各种网络结构和节点动态。它在二进制、离散和连续时间序列数据上也表现良好,并且重建结果对噪声和缺失信息具有鲁棒性。
(备注:复杂系统的动力学过程是指系统在时间上的演化过程,描述了系统内部组成部分之间的相互作用和变化。它涉及到系统中各个元素或节点的状态、属性或行为随时间的变化规律。
在定义复杂系统的动力学过程时,需要考虑以下几个方面:
1. 状态变量:系统的状态可以由一组状态变量来描述,这些变量可以是每个节点的状态,也可以是系统的整体属性。例如,在社交网络中,每个节点的状态可以表示为其活跃度或意见;在生态系统中,它们可以表示为物种的种群数量。
2. 相互作用:复杂系统的动力学建立在系统内部元素之间相互作用的基础上。这些相互作用可以是节点之间的直接联系(例如,网络中节点之间的连接),也可以是节点之间的间接影响(例如,节点之间的传播过程)。
3. 模型和规则:动力学过程可以通过一组模型和规则来描述。这些模型和规则可以是基于数学方程、概率模型、基于规则的系统等。它们可以包括节点之间的转移函数、更新规则、概率模型等,以描述系统如何从一个状态转移到另一个状态。
4. 时间尺度:动力学过程可以在不同的时间尺度上进行建模。有些系统可能是离散时间的,如每个时刻对应一个状态;有些系统可能是连续时间的,如具有连续状态变化的物理系统。
5. 非线性和复杂性:复杂系统的动力学过程通常具有非线性和复杂性。这意味着系统的行为不能简单地通过简单的线性关系来描述,而是涉及到相互作用的非线性效应和系统的整体行为。
总而言之,复杂系统的动力学过程是基于系统内部元素之间相互作用和变化的演化规律,涉及到状态变量、相互作用、模型和规则等要素。通过研究和理解系统的动力学过程,我们可以更好地理解复杂系统的行为和变化。)
(备注:似然函数是统计学中的一个概念,用于描述在给定一组观测数据时,模型参数的可能取值对应的概率密度或概率质量函数。似然函数通常表示为L(θ;x),其中θ表示模型的参数,x表示观测数据。
似然函数衡量了在已知观测数据的情况下,模型参数出现该取值的可能性大小。似然函数的取值越大,表示该参数取值对于解释观测数据的拟合程度越好。
最大化似然函数的目的是找到最符合已知观测数据的模型参数取值,以使得观测数据的出现概率最大化。简而言之,我们通过寻找能够使得观测数据发生概率最大化的参数取值,来确定模型的最佳参数估计。
在实际应用中,最大化似然函数所对应的参数估计方法被广泛使用,例如最大似然估计(Maximum Likelihood Estimation,MLE),它是一种常用的参数估计方法,用于确定统计模型的参数取值。)
2.介绍
活体细胞、大脑、人类社会、股票市场、全球气候系统等都是由许多非线性交互单元组成的复杂系统。通过将复杂系统分解为具有节点动态的静态网络,网络动力学系统模型成为描述复杂系统、理解其集体行为和控制其功能的重要工具。然而,构建这样的模型需要专业的先前知识和建模经验,这限制了这些方法的广泛应用。以无主观偏见地从复杂系统行为的时间序列数据中检索相互作用网络结构和节点动态,仍然是一项基本问题。
历史上,恢复网络结构和预测节点动态行为的重建或模拟以用于未来状态预测是不同的任务,它们被分开研究。首先,从时间序列数据中揭示网络结构非常重要,因为推断出的网络不仅可以帮助我们理解系统的行为,还可以提供关于复杂系统内部相互作用的因果结构的信息。可以通过直接计算某些统计量,扰动系统,优化评分函数,或将复杂的相互作用动力学扩展到一组基底函数,以及其他方法来获取相互依赖关系或因果结构。例如,ARNI(揭示网络相互作用的算法)方法不仅可以准确推断网络,还可用于各种非线性动力学。然而,一个缺点是模型的性能强烈依赖于基底函数的选择。如果缺乏对基底函数的先验偏见,那么这种方法将变得非常耗时,限制了其在更大系统中的应用。
另一方面,从时间序列数据中进行动力学重建也是研究的一个分支。根据Taken定理,一旦观察到的序列足够长,可以从时间序列数据中重建非线性系统的任何动力学行为。因此,发展了各种技术来构建模型以模拟数据背后的动力学行为,并预测系统的未来状态。然而,传统时间序列预测技术很难应用于复杂系统,因为随着要预测的变量数量增加和节点之间的长程相关性广泛存在,任务变得非常困难。在提供节点之间相互作用网络结构的情况下,图(神经)网络(GNN)模型特别设计用于处理这个任务。通过在给定网络上学习信息聚合和传播的复杂函数,GNN可以模拟这些网络上的任何复杂动力学。然而,大多数GNN模型都要求完全图,这限制了它们的广泛应用。
(备注:这句话指的是在预测的变量数量增加和节点之间存在长程相关性的情况下,预测任务变得更加困难。在复杂系统中,变量表示系统的不同特征或属性,它们可以是物理量、状态、行为等。当我们需要预测多个变量时,随着变量数量的增加,预测任务变得更加复杂。因为每个变量都可能受到其他变量的影响,并且彼此之间可能存在各种复杂的关联关系。
节点之间的长程相关性是指节点(在网络中代表变量的点)之间存在较远的相互关系。也就是说,某些节点之间的相互作用关系可能不仅限于直接相邻的节点,而是跨越较长的距离,甚至可能跨越整个网络。
由于变量之间的相互作用和节点之间的长程相关性,预测任务的复杂度和难度增加。需要采用更加高级和复杂的方法和模型来处理这种情况,例如机器学习、深度学习或图神经网络等技术,以更准确地预测多个相关变量的行为和相互作用。)
(备注:1. 异构图(Heterogeneous Graph):异构图是一种包含多种类型节点和边的图。不同类型的节点和边之间具有不同的语义和关系。例如,在社交网络中,用户节点、文章节点和评论节点可以被认为是不同类型的节点,而用户之间的关注关系、用户与文章之间的评论关系可以看作是不同类型的边。异构图广泛用于表示和分析复杂数据结构,如知识图谱和推荐系统。
2. 超图(Hypergraph):超图是一种比普通图更加灵活的图模型,其中边可以连接多个节点,而不仅仅是连接两个节点。换句话说,一个边可以连接任意数量的节点,这些节点共同构成了这条边。超图可以将多个节点之间的关系表示为一组节点的集合。超图的应用包括数据建模、知识表示和群体行为分析等领域。
异构图和超图提供了更丰富和灵活的图模型,能够更好地表示和处理复杂的实际问题。在实际应用中,它们可以用于描述和分析多层次、多类型和多重关联等复杂的数据关系。)
很少有研究提出同时执行网络重建和节点动态重建任务的方法,尽管某些网络推断算法能够预测节点状态,并且基于注意机制进行预测的深度学习模型也可以获得隐含的、时变的网络结构。推导出一个明确的网络的第一个框架是神经关系推断(NRI),它使用了一个编码器-解码器框架。然而,从时间序列数据中推断连接的复杂编码过程限制了其在更大网络上的可扩展性和准确性。
(备注:"基于注意机制进行预测的深度学习模型可以获得隐含的、时变的网络结构"意味着该模型可以从输入数据中学习到动态变化的网络结构,并通过注意机制来关注重要的节点和边。
深度学习模型是一种通过多层神经网络来学习输入数据特征和模式的机器学习算法。在图相关的任务中,深度学习模型可以解决包括图结构推断、节点分类和边预测等问题。
注意机制是一种用于选择性关注输入信息的技术,它可以使模型集中注意力于对当前任务更有价值的部分,而忽略其他无关的部分。在图数据中,注意机制可以被应用于节点和边的选择,以便模型更好地理解图结构和相关的特征。
当基于注意机制的深度学习模型应用于图相关任务时,它不仅能够预测目标变量(如节点的标签),还能同时学习到隐含的、时变的网络结构。这意味着模型可以在学习任务目标的同时,通过注意力的聚焦和动态调整,推断出图中节点之间的潜在联系和相互作用结构的变化。
通过注意机制,模型可以根据当前任务和输入数据的特点,自适应地学习和利用不同节点和边之间的关系。这为图分析任务提供了更多灵活性和准确性,并能够随着时间的推移捕捉到图的动态变化。)
本文提出了一个统一的框架,用于自动交互和动力学发现(AIDD)。这是一个通用的框架,可以通过时间序列数据学习复杂系统的相互作用结构和动态。AIDD采用轻量级网络生成器和基于马尔科夫动力学的通用动力学学习组件的设计,在适用于各种网络和动力学的同时,具有高准确性和稳健性,可以重构非常大的网络。整个框架可微分,因此可以通过自动微分和机器学习技术直接优化。除了网络推断和时间序列预测的任务外,我们提出了一种基于控制实验对学习的数据驱动模型进行测试的新方法。最后,我们在具有噪声、不完整和不连续数据的真实基因调控网络上验证了我们框架的有效性。结果表明可以获得较高的性能。
(备注:整个框架可微分意味着该框架中的各个组件和操作都是可导的,使得可以使用自动微分技术对模型参数进行优化。
在机器学习中,优化是指通过调整模型参数来最小化(或最大化)定义的损失函数。传统的优化方法如梯度下降需要计算损失函数对参数的导数,然后根据梯度的方向进行参数更新。而自动微分是一种计算导数的技术,能够自动地计算出导数,无论函数是由基本运算符还是复杂的函数构建而成。
当整个框架是可微分的时候,我们可以使用自动微分和机器学习技术来直接对模型进行优化。具体而言,可以计算损失函数相对于模型参数的导数,然后通过反向传播算法对模型参数进行更新。这样,我们可以有效地使用梯度信息来指导模型参数的调整,以提高模型的性能和准确性。
通过将可微分的特性引入到框架中,我们能够结合机器学习技术进行端到端的模型训练和优化。这种方法具有许多优势,包括可自动处理复杂度高的模型结构、提高计算效率以及实现更好的模型性能等。
需要注意的是,整个框架可微分并不是所有模型和组件都可以直接进行优化。它通常指的是大部分或核心的组件是可导的,而其他非可导组件可能需要采取其他方法来进行处理,例如近似优化或使用梯度信息作为指导。)
(反向传播算法(Backpropagation algorithm)是一种用于训练神经网络的常见优化算法,通过计算损失函数对于网络参数的梯度,从输出层向输入层进行参数更新。
在神经网络中,网络通过输入数据进行前向传播,计算出每一层的输出值,并最终得到预测结果。然后,通过与真实标签或目标值进行比较,计算出损失函数的值,即网络预测结果与实际结果之间的差异。
反向传播算法的核心是使用链式法则来计算损失函数相对于每个参数的梯度。该算法首先从输出层开始,根据损失函数的梯度计算出每个输出层神经元的敏感度。然后,根据连接权重和激活函数的导数,将敏感度向前传递到前一层,逐层计算每个神经元的敏感度。最后,根据梯度下降法则,将这些梯度用于更新网络参数,以减小损失函数的值。
反向传播算法可以有效地利用链式法则和梯度信息,以一种逐层、逆推的方式对网络进行参数更新。通过反复迭代该过程,不断调整网络参数,使得网络的输出结果逐渐接近真实标签,从而提高网络的性能和准确率。
需要注意的是,反向传播算法通常与其他优化算法(如梯度下降法、随机梯度下降法)结合使用,以实现对神经网络模型的训练和优化。)
3.问题表述
假设要考虑的复杂系统在离散时间步下发展。因此,可以用来描述重构动力学的是
![]()
其中![]() 是系统在时间t的状态,N是节点数量,D是每个单独节点状态空间的维度,A是要重构的相互作用网络的邻接矩阵,ζt ∈ RN×D是施加在节点上的噪声。然而,公式(1)只能描述具有明确数学形式的动态过程,不能应用于由规则表或转移概率定义的动态过程,例如元胞自动机、布尔动力学或马尔可夫链。因此,我们使用更一般的形式,即马尔可夫链{Xt}来描述动力学。
是系统在时间t的状态,N是节点数量,D是每个单独节点状态空间的维度,A是要重构的相互作用网络的邻接矩阵,ζt ∈ RN×D是施加在节点上的噪声。然而,公式(1)只能描述具有明确数学形式的动态过程,不能应用于由规则表或转移概率定义的动态过程,例如元胞自动机、布尔动力学或马尔可夫链。因此,我们使用更一般的形式,即马尔可夫链{Xt}来描述动力学。
【数之道 18】"马尔可夫链"是什么?了解它只需5分钟!_哔哩哔哩_bilibili
(元胞自动机(Cellular Automaton)是一种离散的计算模型,它由一个规则网格组成,每个单元格可以处于不同的状态,并且通过确定性或随机的方式与其相邻单元格进行交互。元胞自动机广泛应用于模拟和研究复杂系统的动态行为,如生物学、物理学和社会科学等领域。
布尔动力学(Boolean Dynamics)是一种动力学模型,它使用布尔变量和逻辑运算描述系统的状态和状态之间的转换关系。每个布尔变量只能取两个值,例如0和1,代表不同的系统状态。布尔动力学常用于描述和分析基因调控网络和逻辑门电路等系统。
马尔可夫链(Markov Chain)是一种数学模型,用于描述具有一定内部状态变化规律的随机过程。马尔可夫链具有马尔可夫性质,即未来状态的条件概率只依赖于当前状态,而与过去状态无关。马尔可夫链在很多领域中都被广泛应用,如统计学、信息论和计算机科学等。)
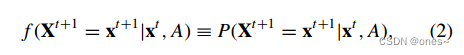
其中,f是待发现的动力学过程,xt = (x1t, x2t, ..., xnt) ∈ VN是观测到的时间序列,V是每个单独节点的状态空间,可以是连续值的RD或离散值的{0,1}D。在这里,我们使用D维的独热向量来表示具有D个元素的有限集合。一个独热向量是一个除了某个位置取1之外,所有位置都为0的向量,如果取1的位置是p,则该向量表示第p个元素。例如,(0, 0, 1)和(0, 1, 0)分别可以表示集合{a, b, c}中的a和b两个元素。P是条件概率。公式(2)与公式(1)兼容,但更加通用。甚至可以通过添加更多的隐藏辅助变量将其扩展到具有有限历史记录的非马尔可夫随机过程。
然而,在公式(2)中推断概率是困难的,特别是当N很大时。幸运的是,复杂系统的相互作用通常是局部化的,这意味着P(Xt+1 = xt+1|xt, A)可以分解为局部转移概率。
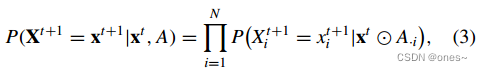
其中,⊙表示按元素乘积,A·i表示矩阵A的第i列,而![]() 是表示节点i的所有邻居节点状态组合的向量。然后,继续进行以下计算。
是表示节点i的所有邻居节点状态组合的向量。然后,继续进行以下计算。
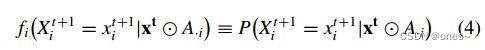
(备注:独热向量(One-Hot Vector)是一种表示离散分类变量的编码方式。它是一个二进制向量,该向量所有的元素都为0,除了一个位置上的元素为1。这个位置对应于输入的类别或标签。
独热向量的长度与类别的数量相等。如果有D个类别,那么独热向量的长度就是D。每个类别对应着一个唯一的位置。
例如,如果有一个三个类别的离散变量:红、绿、蓝。那么用独热编码表示时,红可以表示为[1, 0, 0],绿可以表示为[0, 1, 0],蓝可以表示为[0, 0, 1]。
独热向量编码的主要优势是能够保留变量之间的非线性关系,且易于使用和解释。在机器学习和深度学习中,独热向量通常用于将分类变量输入到模型中,以便进行有效的计算和训练。)
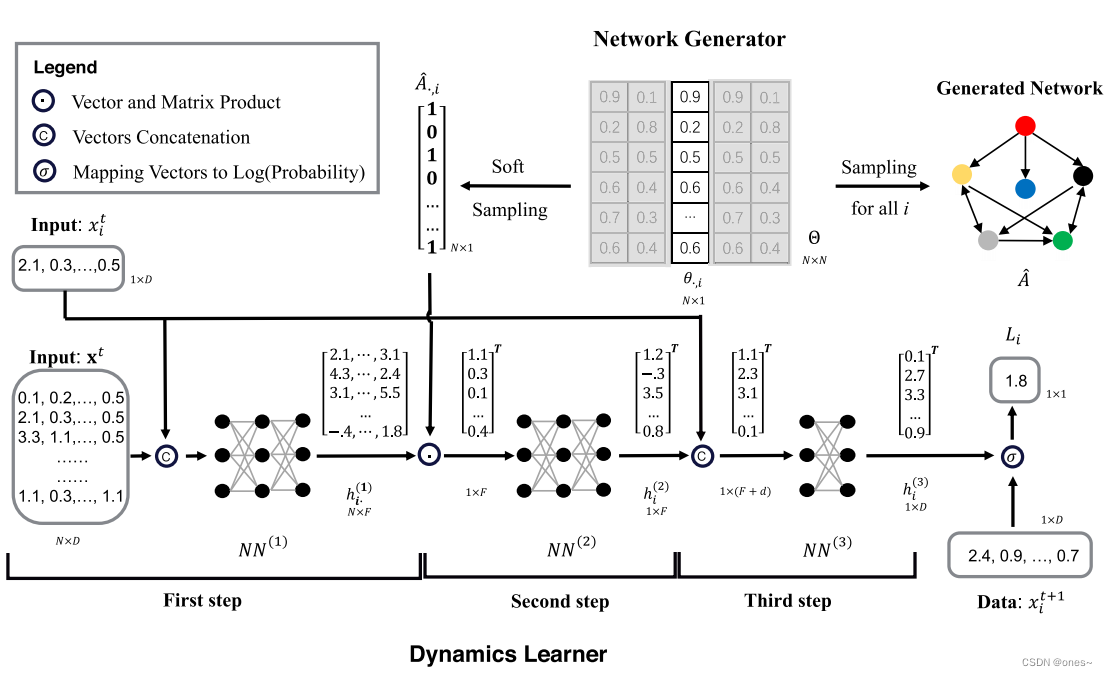
图1显示了自动化交互和动力学发现(AIDD)框架的架构。上方的行概述了网络生成器如何对节点i采样邻接矩阵的一列,并根据N×N维参数矩阵η以ith N行列向量表示节点i的ˆA·i取值为1的概率来重建整个网络。底部的行显示了动力学学习器如何预测节点i在下一个时间步的状态的对数概率。我们还在每个单元旁边显示了所有输入和输出向量(矩阵)及其大小。
动力学学习器的第一步将所有节点的输入数据转换为它们的节点表示h(1),第二步将邻接矩阵Aˆ·i的第i列与所有节点的表示h(1)相乘,输入到第二个神经网络NN(2)中生成一个具有所有邻居信息的新表示h(2)i;第三步将h(2)i和xti连接起来,输入到第三个神经网络NN(3)中生成代表节点i在下一步的预测状态的h(3)i。然后,根据h(3)i和xt+1i计算对数似然。最后,通过深度学习框架(例如PyTorch)自动执行反向传播算法。
每个神经网络NN(1,2)是一个具有F = 256个隐藏单元和ReLU激活函数的三层前馈网络,而NN(3)有两层。
4.网络生成
与文献[26]中描述的使用复杂的神经网络架构生成候选网络的方法不同,我们直接对邻接矩阵中的每个元素进行采样,其中Aˆij∼伯努利(θij),其中θij∈[0,1]表示Aˆ的第i行第j列的条目取值为1的概率。为了使采样过程可微分,我们使用了Gumbel-softmax技术[26,42]来生成邻接矩阵[30]:
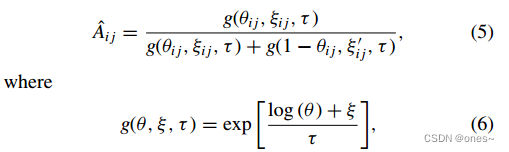
其中 ξij,ξi j ∽ 是符合标准Gumbel分布的随机数, τ是温度参数,用于调节采样结果的分布均匀性,在本文中始终为1。由公式(5)生成的随机数具有与Bernoulli(θij)类似的分布,尤其在τ较小时更为相似。模拟采样过程是可微分的,因此可以传递梯度。当 τ → 0时,ˆAij以概率θi j恰好等于1,或以概率1−θi j等于0。
(备注:直接对邻接矩阵中的每个元素进行采样意味着我们针对每个节点对应的行和列,通过随机抽样的方法确定该节点与其他节点是否存在连接关系。具体而言,我们使用Bernoulli分布来决定节点对之间是否存在边连接,其中每个元素根据概率θij进行采样,如果采样结果大于等于0.5,则将该元素设置为1,表示存在连接;如果采样结果小于0.5,则将该元素设置为0,表示不存在连接。通过这种方式,我们可以获取一个候选的邻接矩阵,用于后续的网络动力学学习和优化过程。)
通过这种方式,与编码器-解码器框架(例如参考文献[26])相比,我们的框架在灵活性和计算效率方面有了很大的改进,并且可以应用于非常大的网络。此外,噪声ξij的引入可以推动网络生成器在优化过程中跳出局部最小值。
5.节点动态模拟
根据公式(3),动力学学习部分也可以将其分解为逐节点的局部动力学。每个局部节点动力学可以由前馈神经网络建模。
为了模拟每个节点中各种类型的非线性复杂节点动力学,我们采用了图神经网络框架。图神经网络(Graph Neural Network,GNN)是一种特殊类型的神经网络,可以处理图结构化数据[22]。它在给定的图结构上构建一个参数化的消息传递过程,并通过与真实网络动态过程进行比较,并通过反向传播算法调整参数以模拟真实网络动态过程[26]。
在我们的GNN框架中,我们将消息传递过程分解为三个步骤,如图1所示。对于任何节点i,第一步是对其与任何其他节点j∈[0,N]之间的交互进行编码,形成一个抽象表示向量:
![]()
具有维度F(本文中设置为F = 128)的表示向量。通过对所有j进行迭代计算,我们得到一个矩阵:
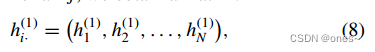
具有维度F × N的矩阵。这个隐藏变量表示与节点i的所有可能交互。第二步是根据前一步生成的候选邻接矩阵Aˆ.,i,过滤掉与节点i不相邻的节点的无关信息:
![]()
其中,具有维度F的h(2)i也是聚合了所有邻居节点信息后的节点i的抽象表示向量。最后一步是生成一个新的隐藏表示向量,准备进行输出:
![]()
在这里,我们还将xti输入到NN(3)中来提高预测准确性。在公式(8)、(9)和(10)中,NN(k)(k = 1, 2, 3)表示具有参数{φ(k)}的前馈神经网络,它们的结构几乎相同(具有F个隐藏单元和ReLU激活函数)。NN(1,2)有三层,NN(3)有两层。请注意,参数φ(k)在所有节点之间共享(对于任何节点i和步骤k,φ(k)i = φ(k)),这可以大大减少参数的数量。如引用文献[40,41]所示,公式(8)、(9)和(10)可以模拟具有公式(3)形式的任何网络动力学。
最后,我们将节点i的隐藏表示h(3)i映射到取值为x时节点状态Xˆt+1i的对数概率(对数似然)上。
![]()
其中,σ是用于将h(3)i和xi映射到对数概率的函数,函数形式取决于节点状态值范围V。
如果V = RD,其中D是值的维度,那么σ的形式为标准正态分布的对数log N(μ, 1),其中μ是作为NN(3)输出的均值向量μ=h(3)i,方差为1(或我们也可以考虑log-laplacian形式logL(μ, 1)),不同的分布将影响目标函数的形式,如下一小节中所讨论的。
如果V = {0, 1}D,h(3)i是表示离散值的one-hot向量,则σ是一个log-softmax函数:σ(x; h(3)i) = log[exp(h(3)i)/∑Dj=1 exp(h(3)j)],而NN(3)的输出h(3)i表示ˆXt+1i取每个可能值的对数概率。
为了在时间步t + 1生成节点状态,我们可以根据独立节点i的概率P(ˆXi)对值进行采样。通过这种方式,我们可以模拟所有节点的单步动态。
总体上,第一步是将每个节点和可能的邻居的输入信息编码成表示形式,第二步是从邻居中聚合信息,最后一步是生成输出。这种设计已被证明适用于学习各种复杂的网络动力学。
6.目标函数
利用可以生成候选网络和节点动力学的模型,我们可以将网络和节点动力学重构问题转化为优化问题,通过最小化以下目标函数:
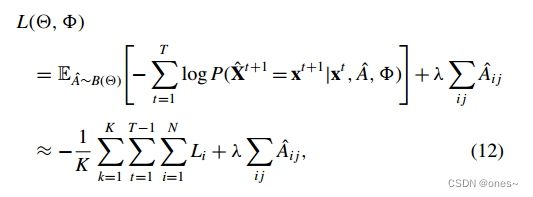

这是局部对数似然,K是在给定η的情况下Aˆ矩阵的样本数量,ˆAk是样本矩阵的第k个样本,xti是节点i在时间t上的观测向量。B代表伯努利分布。我们在相同的参数η下对K个候选网络进行采样,以评估动力学模拟器以提高准确性。因此,目标函数包含两个项,前者是对数似然,可以拆分为局部对数似然。后者是结构损失,用于使网络稀疏,避免过度拟合。参数λ可以调整结构损失的相对重要性。
容易推导出,如果状态空间V = RD,并且σ采用正态或拉普拉斯分布形式,则局部对数似然(13)为:
![]()
其中,如果采用高斯分布,则p = 2,Li为均方误差(MSE);如果使用拉普拉斯分布,则p = 1,Li为平均绝对误差(MAE)。而h(3)i是最后一层的输出,表示高斯(拉普拉斯)分布的均值向量μ。
然后,通过调整候选邻接矩阵中的θ·i参数和动力学模拟器中的φ参数来优化目标函数(14),从而获得适应观测数据的网络动力学[43]。我们使用随机梯度下降算法进行优化。
7.实验


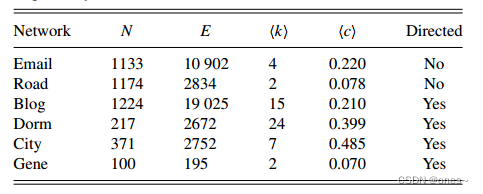



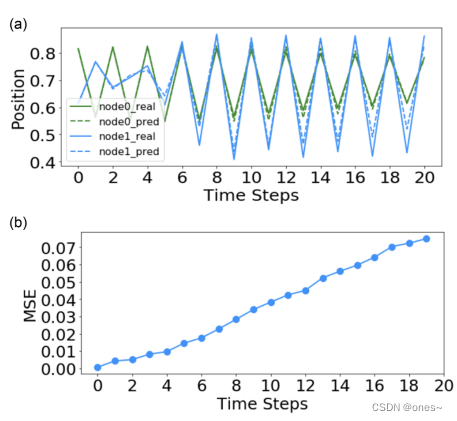






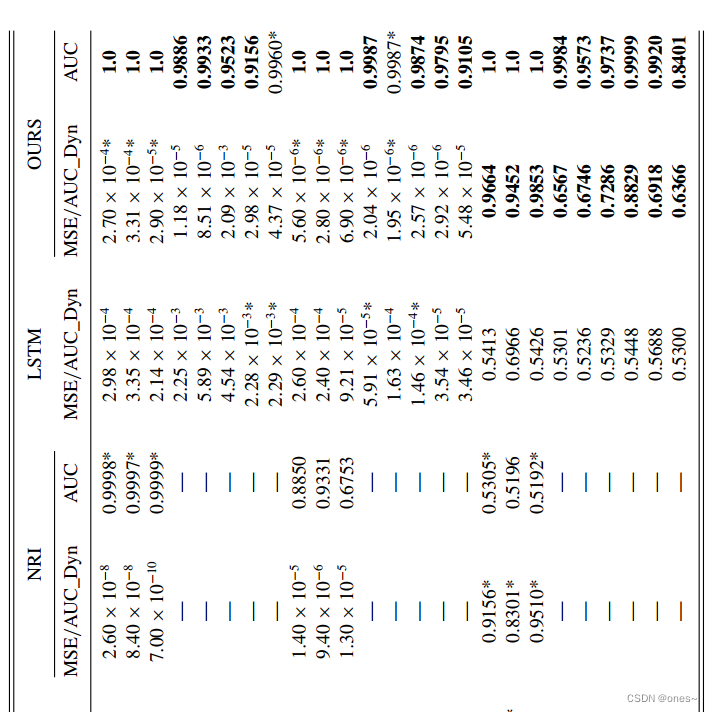
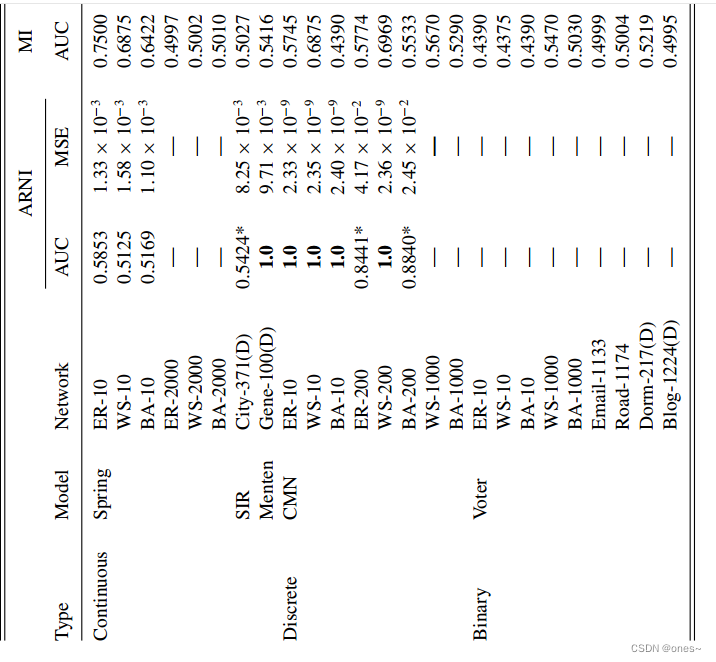
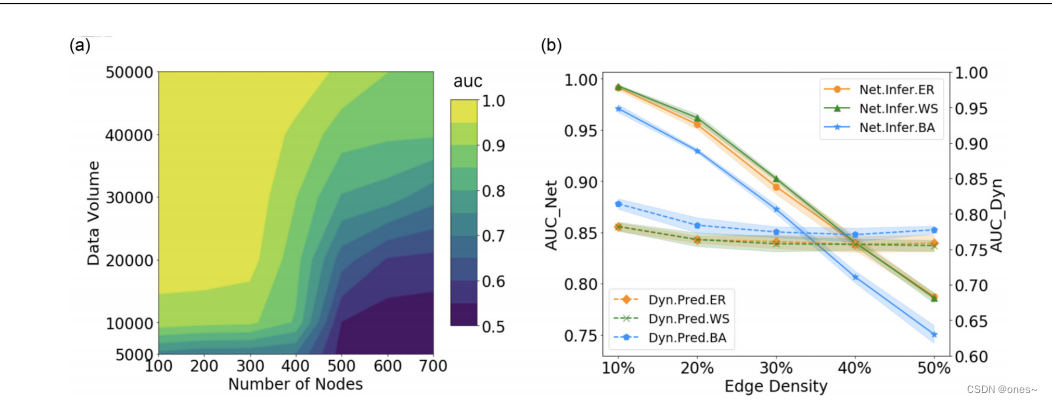
表II. 各种动力学规则的函数,其中 X_i 代表 i 的状态,N_i 代表 i 的邻居。


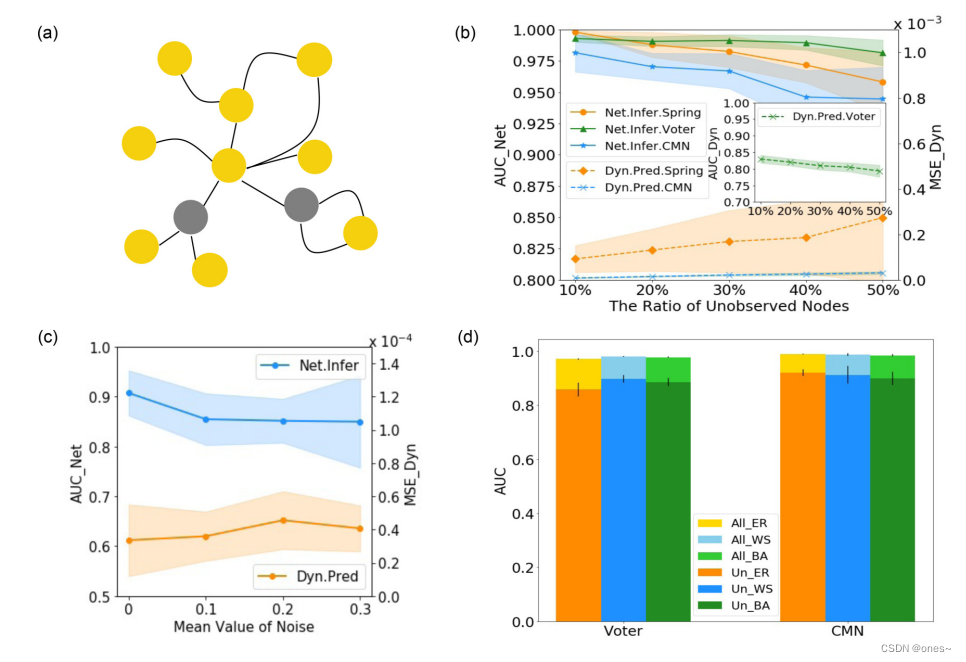

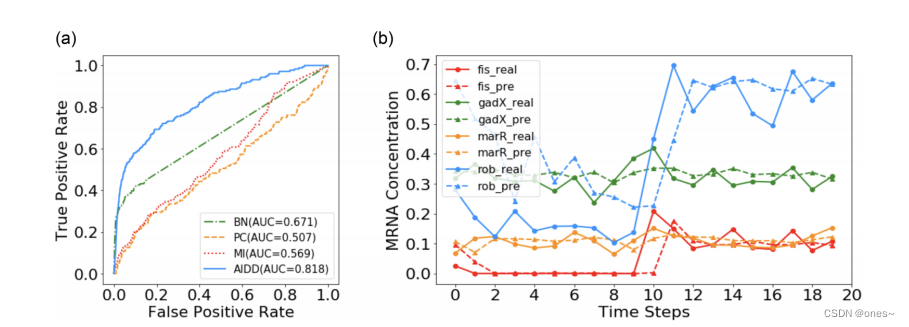

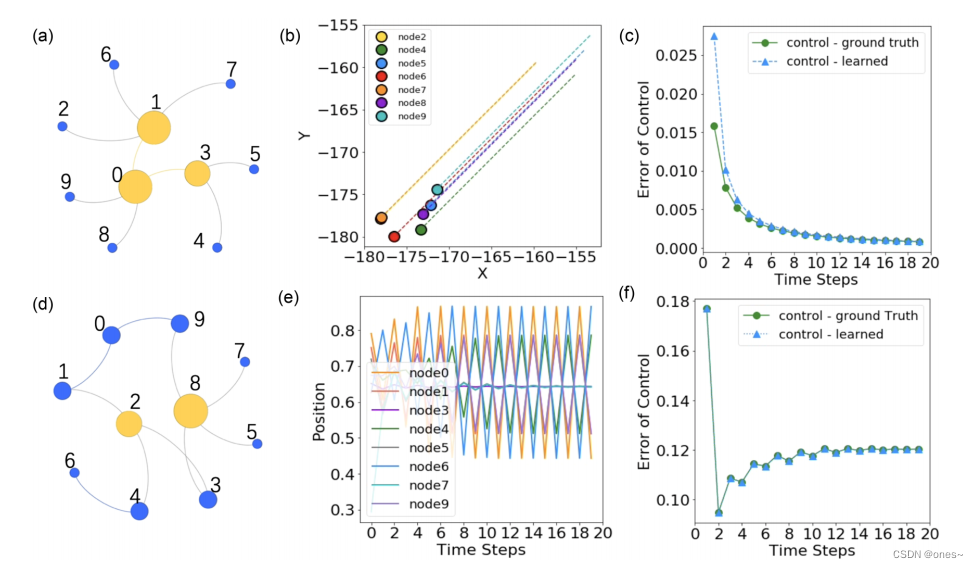

8.总结


9.代码
import numpy as np
from scipy import *
import pandas as pd
import datetime
import pickle
import time
from scipy.integrate import odeint
import argparse
import sys
import random
parser = argparse.ArgumentParser()
parser.add_argument('--times', type=int, default=5000, help='sample times,default=5000')
parser.add_argument('--sample_freq', type=int, default=50, help='sample frequency')
args = parser.parse_args()
# load city data
df1 = pd.read_csv('./city_data/county_city_province.csv')
df2 = pd.read_csv('./city_data/citypopulation.csv')
cities1 = set((df1['CITY']))
cities2 = set((df2['city']))
cities = set(list(cities1) + list(cities2))
nodes = {}
city_properties = {}
id_city = {}
for ct in cities:
nodes[ct] = len(nodes)
city_properties[ct] = {'pop': 1, 'prov': '', 'id': -1}
for i in df2.iterrows():
city_properties[i[1][0]] = {'pop': float(i[1][1])}
for i in df1.iterrows():
dc = city_properties.get(i[1]['CITY'], {})
dc['prov'] = i[1]['PROV']
dc['id'] = i[1]['CITY_ID']
city_properties[i[1]['CITY']] = dc
id_city[dc['id']] = i[1]['CITY']
def flushPrint(variable):
sys.stdout.write('\r')
sys.stdout.write('%s' % variable)
sys.stdout.flush()
def generate_network():
df = pd.read_csv('./city_data/city_flow_v1.csv')
flows = {}
for n, i in enumerate(df.iterrows()):
if n % 1000 == 0:
flushPrint(n / len(df))
cityi = (i[1]['cityi.id'])
cityj = (i[1]['cityj.id'])
value = flows.get((cityi, cityj), 0)
flows[(cityi, cityj)] = value + i[1]['flowij']
if cityi == 341301:
print(flows[(cityi, cityj)])
# save to flux matrix
matrix = np.zeros([len(nodes), len(nodes)])
self_flux = np.zeros(len(nodes))
pij1 = np.zeros([len(nodes), len(nodes)])
for key, value in flows.items():
id1 = nodes.get(id_city[key[0]], -1)
id2 = nodes.get(id_city[key[1]], -1)
matrix[id1, id2] = value
for i in range(matrix.shape[0]):
self_flux[i] = matrix[i, i]
matrix[i, i] = 0
if np.sum(matrix[i, :]) > 0:
pij1[i, :] = matrix[i, :] / np.sum(matrix[i, :])
df = pd.read_csv('./city_data/Pij_BAIDU.csv', encoding='gbk')
cities = {d: i for i, d in enumerate(df['Cities'])}
pij2 = np.zeros([len(nodes), len(nodes)])
for k, ind in cities.items():
row = df[k]
for city, column in cities.items():
i_indx = nodes.get(city, -1)
if i_indx < 0:
print(city)
j_indx = nodes.get(k, -1)
if j_indx < 0:
print(k)
if i_indx >= 0 and j_indx >= 0:
pij2[j_indx, i_indx] = row[column] / 100
if i_indx == j_indx:
pij2[i_indx, j_indx] = 0
bools = pij2 <= 0
pij = np.zeros([pij1.shape[0], pij1.shape[0]])
for i in range(pij1.shape[0]):
row = pij1[i]
bool1 = bools[i]
values = row * bool1
if np.sum(values) > 0:
ratios = values / np.sum(values)
sum2 = np.sum(pij2[i, :])
pij[i, :] = (1 - sum2) * ratios + pij2[i, :]
zeros = np.argwhere(np.sum(pij, axis=1) == 0).reshape(-1)
for idx in zeros:
pij[idx][idx] = 1
print(np.sum(pij, 1)) # Testing normalization
# > 0.02210023336 2%
pij_c = (pij > 0.02210023336) + 0
pij_c = pij_c.astype(int)
pij_c2 = np.zeros((pij_c.shape[0],pij_c.shape[0]))
for i in range(pij_c.shape[0]):
pij_c2[i, :] = pij_c[i, :] / np.sum(pij_c[i, :])
print(np.sum(pij_c2,1))
# return pij
return pij_c2.T
def diff(sicol, t, r_0, t_l, gamma, pijt):
sz = sicol.shape[0] // 3
Is = sicol[:sz]
Rs = sicol[sz:2 * sz]
ss = sicol[2 * sz:]
I_term = Is.dot(pijt) - Is * np.sum(pijt, axis=0)
S_term = ss.dot(pijt) - ss * np.sum(pijt, axis=0)
R_term = Rs.dot(pijt) - Rs * np.sum(pijt, axis=0)
cross_term = r_0 * Is * ss / t_l
delta_I = cross_term - Is / t_l + gamma * I_term
delta_S = - cross_term + gamma * S_term
deta_R = Is / t_l + gamma * R_term
output = np.r_[delta_I, deta_R, delta_S]
return output
def generate_data(matrix):
experiments = pd.read_pickle('./city_data/parameters/experiments_ti_tr_120_new.pkl')
experiments = experiments + pd.read_pickle('./city_data/parameters/experiments_ti_tr_120_new_2.pkl')
experiments = experiments + pd.read_pickle('./city_data/parameters/experiments_ti_tr_120_new_3.pkl')
best_para = experiments[0]
fit_param = sorted([(vvv[1], i) for i, vvv in enumerate(best_para)])
itm = best_para[fit_param[0][1]]
t_days = 300
steps = 1000 # 1000
r0 = itm[0][0][0].item()
t_l = itm[2][1]
gamma = itm[2][2]
timespan = np.linspace(0, t_days, steps)
for i in range(args.times):
if i % 100 ==0:
print(10*i)
Is0 = np.zeros(len(nodes))
Ss0 = np.ones(len(nodes))
Rs0 = np.zeros(len(nodes))
#Randomly select a city
city_chose = random.randint(0, 370)
Is0[city_chose] = random.uniform(1, 10) * (1e-4)
Rs0[city_chose] = random.uniform(1, 10) * (1e-4)
Ss0[city_chose] = 1 - Is0[city_chose] - Rs0[city_chose]
#odeint ,Solve differential equations
result = odeint(diff, np.r_[Is0, Rs0, Ss0], timespan, args=(r0, t_l, gamma, matrix))
sz = result.shape[1] // 3
Is = result[:, :sz] # infected
Rs = result[:, sz:2 * sz] # recover
Ss = result[:, 2 * sz:3 * sz] # susceptible
len_node = Is.shape[1]
Is_list = np.zeros((1000 // args.sample_freq, len_node))
Rs_list = np.zeros((1000 // args.sample_freq, len_node))
Ss_list = np.zeros((1000 // args.sample_freq, len_node))
for j in range(Is_list.shape[0]):
Is_list[j] = Is[args.sample_freq * j, :]
Rs_list[j] = Rs[args.sample_freq * j, :]
Ss_list[j] = Ss[args.sample_freq * j, :]
Is_data2 = Is_list[:, :, np.newaxis]
Rs_data2 = Rs_list[:, :, np.newaxis]
Ss_data2 = Ss_list[:, :, np.newaxis]
simu = np.concatenate((Is_data2, Rs_data2, Ss_data2), axis=2)
if(i==0):
simu_all = simu
else :
simu_all = np.concatenate((simu_all,simu),axis=0)
print(simu_all.shape)
results = [matrix, simu_all]
return results
for exp_id in range(1,11):
edges= generate_network()
start_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
print('start_time:', start_time)
print('Simulating time series...')
result=generate_data(edges)
print('Simulation finished!')
data_path = './data/SIR_id'+str(exp_id)+'.pickle'
with open(data_path, 'wb') as f:
pickle.dump(result, f)
end_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
print('end_time:', end_time)

















 7688
7688











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









