







原文链接:Active querying approach to epidemic source detection on contact networks | Scientific Reports (nature.com)

1.摘要
如何确定流行病的起源(即“零号病人”)是一个难题,特别是当我们有大量的接触者网络和已知的感染者。这个问题引起了多个研究领域的关注。如果能及时找出疾病的来源,我们可以迅速采取措施,防止更多人受到感染。
大部分早期研究都是基于一个假设,即在试图找出疾病来源之前,我们可以了解网络中大部分人的健康状况。但我们的研究出发点不同,我们认为要查明每个人的健康状况是困难或昂贵的。所以,最初我们可能只知道很少一部分人的情况。更重要的是,我们甚至不确定流行病已经蔓延了多久。
在这样的背景下,我们认为有必要进一步查询其他人的健康状况。这让我们想到了“主动学习”的概念,因此我们提出了“主动查询”问题。在这个方法中,我们会在推断疾病来源和查询健康状况之间交替进行。我们使用贝叶斯方法来预测流行病已经蔓延了多久,然后决定下一步应该查询哪些人。
我们的研究发现,选择那些预测结果与大家的共识最不一致的人进行查询是最有效的方法。(一个个体关于是否被感染的预测从不同的潜在源头来看有很大差异,那么查询这个个体会提供最多的信息)这种方法既适用于静态网络,也适用于时间序列网络。我们还使用了三个真实的接触网络数据(猪的移动网络、性接触网络、马拉维一个村庄的面对面接触网络)来验证我们的方法。结果显示,通过主动查询,我们可以更准确地确定疾病的来源,即使我们只查询网络中的一小部分人。
(溯源问题的溯源是局部溯源,找到其中传播过程中的一个传染源还是零号病人?)

2.介绍
传染性疾病的传播是对人类、动物和经济的主要全球威胁之一。SARS-CoV-2病毒引发的大流行病酿成的惨痛后果,生动地展示了一种传染性疾病的地方性爆发如果不能得到控制会发生什么。然而,传染性疾病的传播并不仅限于人类。例如,在家畜饲养网络中,病原体通过家畜(如猪)在饲养场之间的移动而传播,这也是一种常见的情况^1-4^。从科学的角度来看,家畜中的疾病传播尤其引人关注,因为相较于人类,这些家畜接触网络背后的数据往往更容易获得。此外,从“一健康”^5^的观点看,监测家畜的移动是有意义的,因为动物和人类的健康是密切相关的。
总的来说,接触网络数据的日益增加已导致了许多关于网络传播过程的研究^6^。一个受到广泛关注的话题,至少引发了一篇综述文章^7^,是确定流行病的来源节点(也称为“零号病人”),或更普遍地说,确定传播过程的来源。能够识别或检测到地方性爆发的来源在接触者追踪努力中起到了重要作用^8^。一旦我们知道了爆发的来源,找到所有可能的下游接触者并采取适当的缓解措施就变得更容易。

源头推断:Shah 和 Zaman^9^ 在计算机病毒在静态网络上扩散的背景下首次正式介绍了源头推断问题。作者展示,在常规的树状结构中,一个节点作为源头的可能性与源头产生的、与给定感染树一致的感染序列数量成正比。(比较预测的感染序列和实际的感染路径,来判断哪个节点是最有可能的感染源源头)这个感染序列的数量可以看作是一个节点中心性度量,作者提议称之为“谣言中心性”。值得一提的另一种基于中心性的方法是Jordan中心性,其中最可能的源头被确定为到其他感染节点的最大距离最小的节点^10^。在元种群模型的背景下也有建议的基于距离的方法^11^,在那里,作者估计最可能的源头为使得观察到的感染节点集合相对于有效距离最“同心”的节点。另一个纯拓扑方法估计源头为产生最低成本的(时间性)Steiner树的节点,其中成本是树的边界权重之和^12^。与许多拓扑方法不同,这种方法适用于静态和时间性网络。而且,最后两种方法都不考虑传播动态。

 不同的、更有可能性的文献分支^13,14^ 使用著名的流行病传播模型来计算单个节点状态的概率,即,考虑到爆发的源头和起始时间,某个节点处于给定状态(例如,感染性)的概率。然后通过最大似然(或贝叶斯)估计来推断最可能的来源。通常,强烈的节点独立性假设被采用,既为了使节点状态概率的计算可行,又为了允许作为个别节点 状态概率乘积的源头可能性的计算。在计算节点状态概率的背景下,这种简化被称为基于个体的近似(IBA),并已广泛应用于静态^15-17^ 和时间性网络^14^。或者,可以避免所产生的近似误差,但计算代价更高,通过蒙特卡洛模拟计算个别节点状态的概率。这是本文将采取的方法,只有在近似源可能性为个体节点状态概率的乘积时才使用节点独立性假设。
不同的、更有可能性的文献分支^13,14^ 使用著名的流行病传播模型来计算单个节点状态的概率,即,考虑到爆发的源头和起始时间,某个节点处于给定状态(例如,感染性)的概率。然后通过最大似然(或贝叶斯)估计来推断最可能的来源。通常,强烈的节点独立性假设被采用,既为了使节点状态概率的计算可行,又为了允许作为个别节点 状态概率乘积的源头可能性的计算。在计算节点状态概率的背景下,这种简化被称为基于个体的近似(IBA),并已广泛应用于静态^15-17^ 和时间性网络^14^。或者,可以避免所产生的近似误差,但计算代价更高,通过蒙特卡洛模拟计算个别节点状态的概率。这是本文将采取的方法,只有在近似源可能性为个体节点状态概率的乘积时才使用节点独立性假设。

人们可能会疑惑,为什么要做节点独立性假设,因为直接模拟爆发并计算模拟结果与观测结果相等的次数是可能的。但是,当观察到的节点集增加时,模拟结果与观察结果匹配的可能性越来越小,这种方法的简单实现就变得不可行了。作为一个变通方法,Antulov-Fantulin等人^18^ 提议测量观察结果与给定来源的模拟结果之间的相似性(而不是相等性)。对于给定的来源,相似性越高,模拟结果对该来源的可能性的贡献就越大。Braunstein和Ingrosso^19^ 开发了一种完全不同的方法,他们使用了一个在时间性网络上的连续时间流行病模型的信念传播形式来模型可能性。尽管他们的方法不依赖于节点独立性假设,但它对于除树之外的所有网络仍然只是一个近似。

主动查询:前面提到的所有研究都假设接触网络中所有个体或大部分个体的状态(易感、传染、恢复等)是已知的,但如COVID大流行所示,这通常并不现实。一些研究^20-26^ 研究了在静态网络上的传播过程中选择有限数量观察者的最优问题。但是,这些研究假设在进行任何观察之前就已经选择了观察者。此外,它们依赖于知道确切的感染时间,而在某些情况下甚至是观察者的感染邻居。
最终更为现实的假设是,首先,只观察到一个节点的状态。这彻底改变了问题:我们是否应该只使用最初观察到的节点来确定最可能的来源?还是我们应该通过查询其他节点的状态来收集关于爆发的更多信息,以便我们可以缩小可能的来源范围?在本文中,我们主要关注第二个问题,并将在众所周知的易感-感染-恢复(SIR)传播模型的背景下定义主动查询问题。主动查询问题与决定查询哪些节点关于它们的状态以便尽可能多地了解真正的疫情来源有关。Zejnilović等人考虑了一个与确定性传播过程在静态网络上的顺序观察者选择相关的问题。Spinelli等人也在静态网络上研究了顺序观察者选择,但知道感染时间对他们的方法至关重要。这两种方法的主要缺点是它们不适用于时间性网络。
在本文中,我们提出了一个迭代的两步方法。首先,我们基于最初观察到的节点的状态执行推断步骤,这将产生一个关于可能的来源节点和爆发开始到首次检测之间可能的持续时间的双变量后验分布。其次,我们根据某种选择策略选择一个未观察到的节点并查询其状态(易感、感染或恢复)。新观察到的节点将增加关于爆发的证据,并可能改善关于真正的来源节点(以及疫情的真正持续时间)的推断。然后我们 ,迭代这个推断-查询周期,直到达到某个最大查询次数。对于查询步骤,我们提出了基于从主动学习文献中借来的思想的不同主动查询策略。这些策略完全基于节点状态概率,因此对底层网络的类型非常灵活。重要的是,它们可以应用于有向网络和时间性网络。主动查询策略将与简单的基线策略(如随机查询)进行比较。



综上所述,本文的贡献如下:
我们重新考察了著名的源推断问题,其中在某个指定的时间观察到所有节点的状态,并分析了在流行爆发的不同阶段的源检测性能。在我们的问题设置中,流行的来源和开始时间都是未知的。这项分析的结果为查询结果提供了一个基准。
• 我们在源推断的背景下引入了活动查询问题,并提出了一套活动查询策略,这些策略受到了关于主动学习的工作的启发。
• 我们在三个真实世界的(时间戳)联系网络上评估了我们的活动查询方法:瑞士的猪移动网络、从互联网社区得到的性工作者与其客户之间的假设性接触网络,以及马拉维村的86名居民之间的接触网络。我们展示了我们对活动查询问题的计算方法如何能够快速和高效地遏制流行病,如果以一种聪明(主动)的方式查询流行病。此外,补充信息提供了关于众所周知的静态网络模型的结果。
在我们呈现和讨论我们工作的结果之前,我们将提供一些初步的概念,并正式介绍我们提出的推断-查询周期。
3.初步知识
在本节中,我们将正式提出网络的概念以及作为我们工作基础的SIR传播模型。然后,我们将描述我们的工作旨在解决的问题。
接触网络。传染病的传播是通过人与人或动物之间的(物理)接触进行的。这种接触可以被概念化为一个网络,其中个体是节点,联系是边。我们用 G(V, E) 表示网络(或图),其中 V 对应于大小为 N = |V| 的节点集,E 对应于大小为 |E| 的边集。网络上的传播过程的研究传统上集中在静态网络上,其中节点之间的联系随时间持续存在。在这种情况下,一个(无向)边简单地被定义为一个元组 (v, u) ∈ E,其中 v, u ∈ V 且 (v, u) = (u, v)。
最近,时间网络的研究受到了更多的关注,部分原因是这样的数据越来越多地变得可用。在我们的工作中,一个(时间)边被定义为一个3元组 (v, u, t) ∈ E,其中 t ∈ N 对应于一个离散的时间戳,定义了节点 v 和 u 何时接触。疾病在节点之间的传播受到联系的时间序列的约束。例如,节点 A 和 C 之间的传播级联是否存在不仅取决于边 (A, B, t1) 和 (B, C, t2) 的存在,还取决于是否 t1 < t2。注意在最后的表达式中的严格不等式,因为我们假设一个节点在一个时间步内不能被感染并进一步感染其他节点。
SIR 传播模型。在(静态)网络上的易感-感染-恢复(SIR)模型假定在每个时间 t,一个节点处于三个可能的状态中的一个(通常称为隔离室):易感(S)、感染(I)或恢复(R)。SIR 描述的动态过程是不可逆的,有两个可能的状态转换:易感节点以 kβ 的速率变得感染(S → I)如果网络中的 k 邻居处于感染状态,感染的节点以 µ 的速率恢复(I → R)(独立于其他节点的状态)。对于静态网络的分析(见补充信息),我们将传输和恢复事件建模为泊松过程,β 和 µ 的速率为常数,从而隐含地假定时间是连续的。对于经验性的时间联系网络的分析,我们将使用 SIR 模型的离散时间版本。我们将使用状态转移概率,而不是速率,这些概率描述了在一个时间步骤中转移到另一个状态的可能性。注意,上述约束条件使得传播级联不能在一个时间步内发生,这使得 SIR 模型实际上是一个易感-暴露-感染-恢复
4.问题的定义
考虑给定的一个联系网络G(V, E),其中的联系要么是静态的,要么是暂时的。我们进一步假设疾病根据已知参数β和µ的SIR模型传播。传播过程从某个时间t0的一个源节点q0开始,并持续一段时间T,直到在时间t0 + T被检测到。对于静态网络的分析(见补充信息),我们假设只有真正的源q0对我们来说是未知的,并且t0是已知的。对于经验性的暂时联系网络,我们放宽了这个假设,并假设q0、t0(以及因此的T)都是未知的。我们将流行病的来源和直到第一次观察为止的流行病持续时间建模为离散随机变量Q和T。Q的状态空间由所有节点V的集合组成,T的状态空间是集合T = {0, ..., K},其中K是一个足够大的整数。
在每个时点,V中的每个节点v都处于SIR模型的三种可能状态之一。我们用随机变量Xv(t)表示任何时间t > t0时节点v的状态,它可以取三个可能的值,Xv(t) ∈ {S,I, R}。在某个时间t1 = t0 + T,我们对网络中节点的状态进行了观察。我们将区分两种观察情况:(1)我们观察网络中所有节点的状态,这对应于在相关工作14,18,19中已经深入研究的问题;(2)我们最初只观察一个传染的或恢复的节点的状态,然后一次观察一个节点的状态。在这两种情况下,我们将观察到的节点集合表示为Ot1 ⊆ V,相应的证据表示为Et1 = {(v, xv(t1)) : v ∈ Ot1 }。在第一种情况下,我们简单地试图推断出最大后验概率(MAP)节点,在对T进行边缘化后。相比之下,在第二种情况下,我们交替进行推断和查询步骤。查询到的节点及其状态被逐步添加到Et1,直到我们最终有足够的节点来确定哪个节点可能是真正的源节点q0。因此,我们试图解决的主要问题是如何决定查询哪些未观察到的节点,以便以有效的方式找到真正的源节点q0(以及流行病的持续时间),即,尽可能少的查询。为了简单起见,我们假设所有的查询都在t1时进行,但是按顺序执行。
推断与查询.在本节中,我们描述了我们方法的三个主要组成部分。首先,我们引入了推断机制。其次,我们描述了在给定一个源节点和一个开始时间的情况下,如何计算单个节点状态概率的方法。最后,我们提出了三种主动查询策略。
推断:我们假设只知道传播过程的SIR参数。因此,我们的问题是在给定证据Et1的情况下,推断源节点Q和直到第一次观察的持续时间T。注意,一旦我们推断出T,我们也可以用t1 − T推断出开始时间。因此,我们试图计算所有节点V和所有持续时间T ∈ T上的联合后验分布P(Q, T | Et1 )。为了保持符号简洁,我们省略了对固定SIR参数β和µ的依赖。假设Q和T之间事先独立,并且Q上有一个均匀的先验分布,后验分布可以写成如下形式:

上述推断表达式的问题是,计算似然P(Et1 | Q, T),即在给定可能的源节点Q和直到第一次观察的持续时间T的情况下观察到Et1的概率,是不直接的,因为在一个网络系统中,节点的状态彼此不是独立的。对于大小为N的静态网络上的连续时间SIR过程,通过将问题建模为连续时间马尔科夫链可以计算确切的似然性(参见补充信息中的一个示例)。但是,这需要3N - 1个主方程,除了非常小的网络外,这是不切实际的。因此,似然值通常是基于简化的假设或通过蒙特卡洛模拟来计算的。一种常见的简化是假设节点状态彼此独立,这在网络环境下被称为均场近似。这使我们能够简单地将似然值计算为单个节点状态概率的乘积。尽管这是一个强烈的假设,但已经显示基于此独立性假设的推断通常对静态网络和时变网络上的流行病过程的来源产生良好的估计。
基于这个独立性假设,似然P(Et1 | Q = q, T = d)可以写为单个节点状态概率Pq,d(Xv(t))的乘积:=P(Xv(t)| Q = q, T = d)。只要事先已经计算出单个节点状态概率,这就允许有效地计算似然。为了避免数字下溢,我们应用log-sum-exp技巧来计算等式(1)中的后验分布(参见补充信息)。一旦我们计算出等式(1)中的后验,我们首先可以消除T,然后确定最可能的来源节点q,它具有最大的边缘后验概率,即,
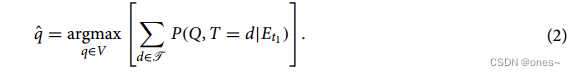
注意,所提出的推断机制在概念上等同于具有关于Q和T的先验的Naive Bayes分类器,其中特征向量由|Ot1|分类组件组成,目标类是V中的元素。
节点状态概率。本小节主要关心的是估计单个节点状态概率Pq,d(Xv(t)),因为它们构成了计算(近似)似然的关键组件。在我们的方法中,我们使用蒙特卡洛模拟来计算给定一个来源和直到第一次观察的持续时间的节点状态概率。更具体地说,我们随机模拟从来源Q=q开始,使用直到第一次观察的持续时间T=d,直到时间t1的大量n传播过程。如果nv,I(t)描述了节点v在时间t处是感染的模拟数(即Xv(t) = I),那么我们可以估计节点v在时间t处是感染的,给定来源q和持续时间d的概率为Pq,d(Xv(t) = I) = nv, I(t) / n。类似地,我们可以计算节点v是易感或已恢复的概率。

近年来,流行病模拟方法的研究一直是一个活跃的领域,并且已经为静态网络和时变网络实施了快速的事件驱动方法。这些新的实现使得在合理的时间内对现实网络进行大量蒙特卡洛模拟成为可能。在源检测的背景下,蒙特卡洛方法只应用在Antulov-Fantulin等人的工作中。18,Dutta等人的工作中。37,以及一个简单的确定性SI模型的情况下,其中一个数学技巧为模拟提供了一个快捷方式。21。我们使用Holme的实现为时变网络的事件驱动方法,其对于稀疏网络的每次模拟运行的最坏时间复杂度为O(N · log N · log C),其中C是同一对节点之间的最大联系数。然而,正如Holme所指出的,现实的网络,尤其是时间的网络,通常是分段的,这与现实的流行病参数一起,经常导致相对较小的爆发。因此,实践中的运行时间可能比最坏的情况要快得多。因为我们的方法要求对每一对源-持续时间(q,d)运行n次模拟,所以我们的方法对于单一证据Et1的总体复杂度是O(N^2 · log N · log C · n)。
我们可以写出模拟方法的总体时间复杂度为O(n · N^2 · log N · log C),忽略持续时间,因为|T|通常小于N。在补充信息中,我们回顾了计算节点状态概率的任务的另外两种方法,并将它们与我们在此使用的蒙特卡洛方法进行了比较。

主动查询。到目前为止,我们已经描述了推断步骤和节点状态概率的计算。为了结束这一节,我们现在将介绍五种不同的策略,帮助我们决定查询哪些未被观察到的节点。关键的是,每当查询一个未被观察到的节点并知道了它在t1的状态时,证据Et1都会被扩展。每次查询步骤之后,我们都可以重新计算后验分布,然后下一个查询步骤将基于更新的后验。我们将考虑三种主动和两种基线查询策略。
不确定性采样:UCTY策略。直观地说,一个主动查询策略应该旨在查询我们最不确定状态的节点。这自然地导致了使用熵来衡量对一个节点状态的不确定性。为此,我们定义节点v的整体节点状态概率为0
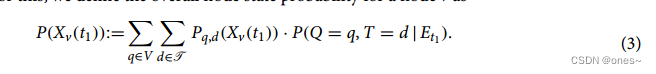
这是贝叶斯模型平均的一种形式,我们使用后验分布来衡量单个节点状态的概率。根据式(3)中的表达式,我们可以计算出每个节点的熵:
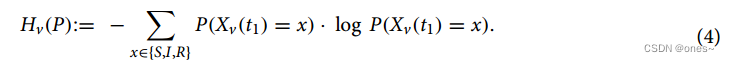
最后,我们查询熵最大的(未观察到的)节点,即
在主动学习社区中,这被称为不确定性抽样28,我们称之为UCTY策略。
激活节点采样:MAXP策略。我们提出的第二种主动策略试图查询具有传染性或已恢复的节点,即激活节点。其基本原理是,查询激活节点比查询易感节点提供更多信息,特别是在激活节点很少的小型疫情中。为此,我们只需查询具有最大感染或恢复概率的(未观察到的)节点,即:
我们将其称为MAXP策略。.0
不一样采样:AKLD策略。我们提议的第三种主动查询策略再次受到主动学习文献中的灵感,特别是查询委员会文献的灵感28,38。基本的想法是查询一个节点v,对于这个节点,不同的源-持续时间对(q,d)对v的状态持有强烈不同的“观点”。我们定义源-持续时间对关于某个节点v的观点为该节点的个体状态概率Pq,d(Xv(t1))。因此,我们的目标是查询有争议的节点。对于给定的(未观察到的)节点v和每个可能的源q ∈ V以及持续时间d ∈ T,我们可以计算节点状态分布在给定q和d时与根据等式(3)计算的整体节点状态分布之间的Kullback-Leibler (KL) 散度。
这里提到的MAXP策略和AKLD策略是两种不同的查询策略。MAXP策略可能是基于某种最大化准则,而AKLD策略则基于在不同的源-持续时间对之间存在不同意见的节点。Kullback-Leibler (KL) 散度是衡量两个概率分布之间差异的一种方法。
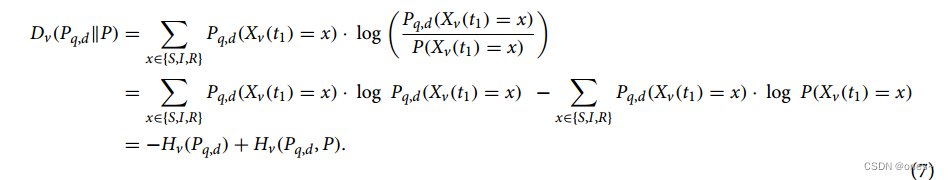
因此,kl散度对应于交叉熵Hv(Pq,d, P)(对于两个分布Pq,d和P)与单个节点状态分布Pq,d的熵Hv(Pq,d)之间的差。然后选择平均kl散度最大的未观测节点:
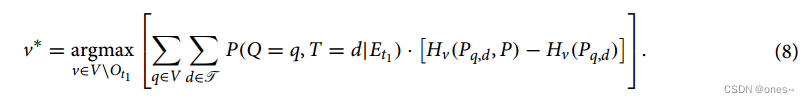
我们将此称为AKLD策略。
在算法(1)中,我们提供了AKLD策略的伪代码。很容易看出,AKLD的(最坏情况下)复杂度为O(N2)(前提是预先计算了总体概率分布P(Xv(t1)))。相比之下,UCTY和MAXP的复杂度仅为0 (N)。


基线策略:RANDOM和ONE-HOP。作为主动查询策略的基准,我们将考虑两种简单的基线策略。第一个基线策略,RANDOM,从所有可由任何可能的源在最早可能的启动时间到达的未观察到的节点中均匀随机选择下一个要查询的节点。第二个基线策略,ONE-HOP,从已观察到的、已激活的节点的直接邻居中均匀随机选择要查询的节点。只有在最早可能的启动时间和推断时间之间有联系时间的邻居才会被考虑。注意,对于所有五种策略,我们通过随机选择一个节点来打破平局。


5.实验结果
结果 本节分为四个部分。首先,我们介绍用于评估我们方法的三个网络。其次,我们用动物运输网络的一个示例来说明我们的方法是如何工作的。第三,我们介绍源推断问题的结果,其中网络中的所有节点的状态都被观察到。这些结果将作为查询结果的基准,因为观察到所有节点的状态对应于可以获得的最大信息量。最后,在第四部分,我们将主动查询结果与完全观察到的推断性能进行比较。一个好的查询策略是在几次查询后接近完全推断性能的策略。
数据。我们在三个实证时变网络上评估我们的方法。第一个网络代表瑞士报告的猪的移动,我们缩写为PIG。我们假设疾病只能从来源地传播到到达地,而不能反过来,因此网络是有向的。我们考虑从2015年1月1日到2017年12月31日的时间段,由此产生的网络包含8,176个节点和149,960个带时间戳的边,时间分辨率为每日。
第二个网络代表性工作者与其客户之间的性接触,由Rocha等人引入30,31。我们将其缩写为ESCORT网络。这是一个无向的、二部的网络,时间分辨率为每日,与以前的研究18,31一样,我们丢弃了数据的前1000天。由此产生的网络有14,783个节点和43,906个带时间戳的边,跨越1,232天(大约3.4年)。
第三个网络代表面对面接触,通过接近度传感器测量,位于马拉维的一个村庄的86位居民之间,由Ozella等人引入32。我们将此网络缩写为MALAWI网络。原始数据的时间分辨率为20秒,这对我们的目的来说太细了。因此,我们汇总数据以获得每小时的时间分辨率。如果两位居民在给定的一个小时内至少有两次接触(以20秒为单位),则两者之间存在一个边。由此产生的(无向)网络有86个节点和5,854个带时间戳的边,跨越321小时(大约13天)。
示例。图1展示了我们的方法,更具体地说是AKLD查询策略,如何应用于PIG网络上的一个爆发。面板(c)显示,在最初观察到节点2被感染后,边际源后验认为节点2是最有可能的源。然后,AKLD决定查询非常中心的节点1,因为可能的源似乎对其状态存在最大的分歧。节点1被发现是被感染的,成为最可能的源(面板(d))。注意这是如何使节点29成为一个不可能的源,具有零后验概率。这是因为节点29只通过节点2到被感染的节点1有一个(静态的)路径。但它不是一个尊重时间的路径(在图中未显示),因此不是一个可能的传播路径。AKLD接下来查询真正的源节点0,这只留下两个可能的源,节点0和4(面板(e))。注意在这个示例中,两次查询足以非常确定地确定源节点。实际上,观察网络中所有节点的状态后的最终后验(面板(f))与两次查询后的后验并无太大不同。
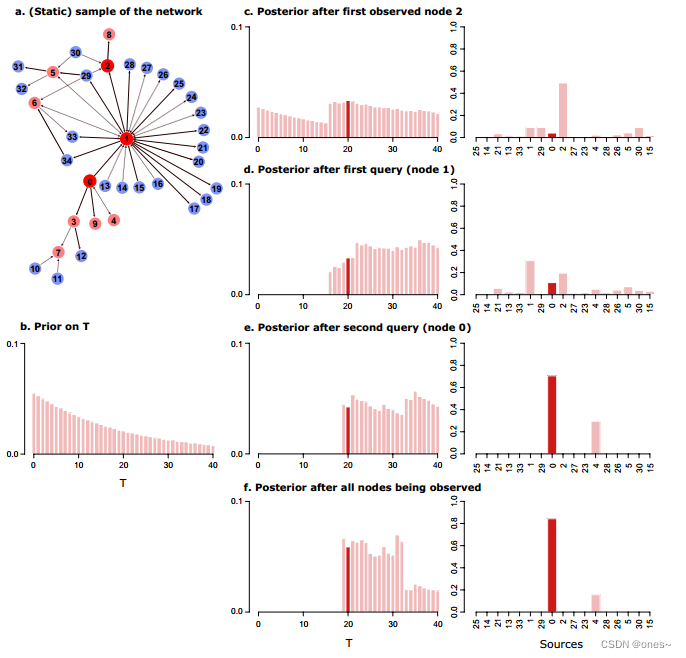
图1. 我们的推断-查询循环在PIG网络上的一个爆发中的应用示例。
(a) PIG网络的静态样本显示所有被感染的节点(红色)以及所有到被感染节点的进入和/或出去的边的节点(蓝色)。被感染节点的节点标签表示节点被感染的顺序。因此,节点0是这次爆发的真正来源,它首先感染节点1。
(b) 对于首次观察时间T的截断几何先验分布。
(c) 在最初观察到节点2后,T和源Q的边际后验分布。真正的来源和真正的T用较深的红色显示。
(d) 在AKLD决定的第一次查询(节点1)之后,T和Q的边际后验分布。
(e) 在第二次查询(节点0)后,T和源Q的边际后验分布。
(f) 在网络中所有节点都被观察后,T和源Q的边际后验分布。
基于完全观察到的节点集的来源推断。首先的结果关注基于完全观察到的节点集Ot1 = V来推断一次流行病的来源。为此,我们针对上述介绍的三个实证网络进行了500组不同的实验,涉及到第一次观察T的不同持续时间和不同的流行病设置。每个实验包括:(1)从随机选择的来源节点和开始时间模拟一个基础真实爆发,且在推断时间t0 + T时最终的爆发规模至少有10个节点;(2)基于完全观察到的节点集进行来源推断。对于PIG和MALAWI网络,我们设置流行病参数β和µ,使得R0 ≈ 1.5 和 R0 ≈ 2。对于ESCORT网络,我们复制Antulov-Fantulin et al.18的实验设置,设β = 0.3 和 µ = 0.01。
对于PIG和MALAWI网络,我们使用均值等于T真实值的T上的几何先验,截断在真实T的两倍值处。对于ESCORT网络,我们再次遵循Antulov-Fantulin et al.18,并在区间[t0 - 25, t0 + 25]上放置一个可能的开始时间的均匀先验。我们的方法的第一步包括基于从每个可能的来源Q和每个T模拟爆发情境来计算单个节点状态概率。我们为每对(Q, T)模拟n = 10,000次。此模拟过程所消耗的平均CPU时间显示在补充图S16中。
我们推断方法的关键输出是公式(1)中的双变量后验,我们可以边缘化它来获得边缘来源后验。我们使用这个边缘后验分布来计算三个不同的衡量标准,以评估来源推断性能。首先,我们计算真实来源q0在排序和排名的来源后验分布中的排名。然后,我们计算所有实验的真实来源的平均排名。其次,我们计算精确度,它简单地是真实来源排名为1的实验的比例。最后,我们计算95%的可信集大小(CSS)26,39,在我们的情况下,它简单地是至少有95%的后验概率的最小节点集的大小。
结果显示在图2中。不出所料,所有三个性能指标都表明,对于较大的T,来源推断变得更加困难。换句话说,爆发有更长的时间发展,推断哪个节点开始了爆发就变得更加困难。此外,与ESCORT和特别是MALAWI网络相比,在PIG网络上推断真实的来源节点要容易得多。更深入地观察PIG网络(R0 = 1.5)的结果发现,在T = 20时,有77.4%的实验在观察到所有节点状态后只剩下一个来源节点作为可能的来源(图中未显示)。这一比例在T = 180时减少到48.4%。很明显,当可以观察到所有节点时,推断真实来源相对容易。这部分可以解释为PIG网络是有向的,这导致可能的传播路径存在强烈的拓扑约束。此外,对网络的(静态)密度进行比较表明,MALAWI网络(0.08)的密度比PIG(0.0007)和ESCORT(0.0003)网络的密度大两个数量级。在补充信息中,我们提供了当我们的方法应用于著名的静态网络模型时的来源推断结果,并显示。
一项有些违反直觉的结果是,在PIG网络上,当基本再生数R0 = 2时,相比于R0 = 1.5更容易推断出源头。一个可能的解释是PIG网络上的疫情并没有演变成超出相对小而局部规模的爆发。例如,从图2我们可以看到超过30个的疫情规模是不太可能的,这与网络的大小相比是极其小的。在这种规模下,实际上观察到更多被感染的节点可能对源头推断是有利的。这一发现与Antulov-Fantulin等人在文献18中的结果是一致的,他们展示了在四连通格子图上,当传播概率较大时,源头的可检测性是更高的。

主动查询。在建立了完全推断结果作为基准后,我们现在展示主动查询的结果。实验设置与前一节类似。在生成一个与上述规格相同的真实疫情爆发后,我们在时间t1进行推断和查询过程。过程从在所有激活节点中均匀随机选取一个作为首个观察节点开始。然后,迭代进行推断和查询,直到达到指定的查询数量。对于PIG和ESCORT网络,我们在每个实验中进行30次查询,而对于MALAWI网络,我们继续查询直到每个节点都被观察到(85次查询)。同样,我们使用平均排名、精度和平均CSS来衡量每个查询过程中的源头推断性能。不同查询策略消耗的平均CPU时间显示在补充图S16中。很明显,模拟过程比查询和推断过程要昂贵得多。此外,AKLD比其他查询策略贵一个数量级。
首先,我们对比五种查询策略的性能。图3显示了所有五种策略在小T值时的查询曲线。为了将查询结果与完全推断性能相关联,我们总是用水平虚线指示完全推断性能。从这个图可以明显看出,AKLD是主导策略,很少表现得比其他策略差。相反,与其他两种主动策略MAXP和UCTY相比,AKLD往往能带来实质性的改进。因此,在本节的剩余部分我们将专注于AKLD策略。所有五种策略的结果显示在补充图S13–S15中。
其次,我们对AKLD与其他三个网络的两种基准策略ONE-HOP和RANDOM进行了广泛比较。图4展示了PIG网络的结果。结果显示,即使在大的T值时,AKLD和基准方法之间也有显著的差异。还有两个其他有趣的效应。首先,相对较小且分散的疫情爆发似乎有利于ONE-HOP基准策略超过RANDOM策略。其次,虽然两种基准策略似乎随时间恶化(曲线越来越远离完全推断性能),但AKLD似乎没有受到这种效应的强烈影响,即使在只进行了30次查询后的T = 180时仍能接近完全推断性能。





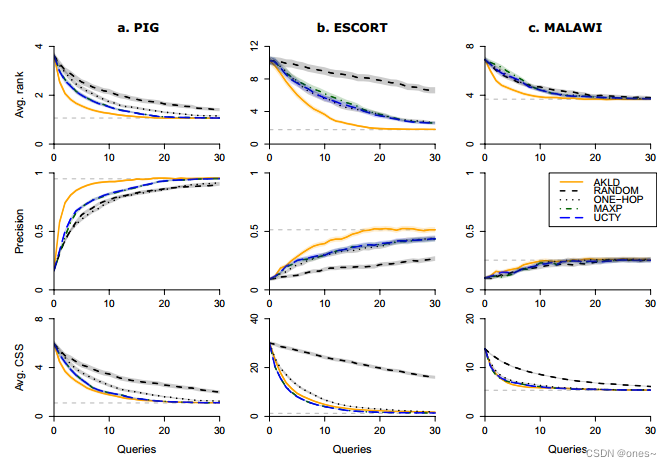





图5展示了ESCORT网络的结果。在这里,与基线相比,AKLD策略也可以带来显著的改进,尤其是在精确度方面。请注意,相对于平均排名,精确度对异常值的鲁棒性要强得多。这就是为什么精确度曲线仍然接近完全推断性能,而平均排名曲线在后期T远离完全推断性能的原因。也可以看出,随机策略的曲线几乎是平的,特别是在后期T。这是因为在这个网络上,有许多实验有大量可能的源头,因此随机策略通常从一个大的节点池中抽样,其中许多节点并不特别有信息量。最后,我们看到,对于后期T,我们需要为所有三种策略查询超过30个节点,才能达到完全推断性能。


图6展示了MALAWI网络的结果。首先,我们注意到与其他两种情况相比,源推断明显更加困难,这是我们在上一节已经观察到并讨论过的结果。其次,虽然AKLD仍然似乎是最好的策略,但与其他策略相比,特别是与ONE-HOP策略相比,它的好处是边际的。
最后,虽然我们在这里继续查询,直到所有节点都被查询和观察到,但从图中很明显,大约查询三分之一的节点在大多数情况下就足够达到完全推断性能。
我们在补充资料中提供了进一步的结果。首先,可以在补充图S17和S18中找到R0=1.5的AKLD查询曲线与R0=2时的对比。如同完全推断结果一样,更高的R0导致PIG网络的查询结果更好。相比之下,更高的R0导致MALAWI网络上的查询结果略有下降。其次,我们测试了T的不确定性对PIG网络的影响,与T已知相比。不出所料,知道T的真实值相比于T未知,可以略微提高源推断结果(见补充图S19)。
最后,补充资料还提供了对静态网络模型查询方法的广泛评估。
6.讨论
这篇论文的主要目的是在接触网络上的流行病源推断的背景下提出并研究一个主动学习问题,即主动查询问题。这个思路是从一组一个或少数几个已观测到的节点开始查询未观测到的节点的状态,以尽可能少的查询来尽可能多地了解爆发的来源。我们提出了三种主动查询策略,其中两种基于信息论原理,并将它们与简单的基线查询策略进行比较。从分析中最引人注目的结果是AKLD策略,该策略选择具有最大平均KL-散度的节点,其散度是在单个节点状态预测和共识预测之间,总体上是占主导地位的策略,在我们分析的三个实证网络中有两个显示出有前途的结果。AKLD策略可以解释为一个由委员会学习策略,其中委员会是可能的源-持续时间对集。实际上,该策略查询有争议的节点,因此可能比其他策略更快地缩小寻找真正的来源的搜索范围。
我们定义的主动查询问题设置,以及我们提出的解决主动查询问题的方法,试图尽可能地普遍并接近实际应用。首先,我们假设我们不能访问大部分(或所有)节点的流行病状态的完整快照,这是相关工作经常做的假设。我们也不假设观察到感染时间或知道爆发的开始时间。其次,我们的方法足够通用,可以应用于静态或时间、无向或有向接触网络。进一步的泛化,例如到加权网络,相对直接。虽然主要文本关注应用于时间接触网络,但我们还在补充材料中提供了大量关于静态网络模型的结果。第三,我们提出一个贝叶斯推理机制,其中可以使用非平凡的先验分布来模拟关于可能的来源和流行病持续时间的先验知识。为了使推断成为可能,我们使用了一个节点独立性假设,类似于朴素贝叶斯做出的独立性假设。这种独立性假设在源推断文献中很常见,并已被证明在源检测中工作得很好。我们的推断和查询程序的关键是能够在给定源和持续时间的情况下计算单个节点状态概率。在这里,我们使用高效的事件驱动大规模蒙特卡洛模拟,而不是使用确定性消息传递算法来避免由于用于此类确定性方法的节点独立性假设而造成的偏见概率估计。蒙特卡洛程序,尽管在计算上比确定性方法昂贵得多,但通常在实际目的中可以在合理的时间内运行。这种方法的一个方便的副作用是,蒙特卡洛模拟是模型不可知的,因此,任何可以高效模拟的传播模型都可以使用。模拟方法和AKLD的时间复杂度都包含一个因子,该因子在N中是二次的。因此,我们的方法可能对于真正的大型网络是不切实际的。在这种情况下,模拟过程的并行化是直接的,或者作为替代方案,我们可以使用确定性方法,例如针对时间网络的IBA,其总体时间复杂度(O(N · C))比蒙特卡洛模拟小得多。对于查询,我们可以使用UCTY或MAXP策略,其时间复杂度在N中是线性的。


















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









