







什么是C++
C++ 就是C 语言的增强版,C++ 兼容所有的C 语言语法!!!
回顾C 语言的知识点:
1.数据类型 char ,short ,int ,float
2.运算符 + - * / % || ....
3.控制流 if ,for ,while ,switch ... .
----------------------
4.数组 (存放多个相同的数据类型) int a[10] ,char b[10]
5.指针 (作用:存放内存地址)
----------------------
6.函数
7.组合数据类型 (结构体,共用体,枚举)
8.宏定义
在C 的基础上进行 ++ = c++ :增加哪些知识点
1.命名空间 : 解决变量名冲突的问题
2.输入输出 : C++ 开发者觉得 printf ,scanf 不好用,就重写了 printf,scanf
3.引用 : 节省内存空间
4.函数重载 : 提高代码的复用性
5.类:(封装,继承,多态) :提高代码的复用性
6.友元 : 提高代码的访问权限
7.运算符重载 : 提高代码的复用性
8.模板: (函数模板,类模板) :提高代码的复用性
9.STL库 (链表,容器,队列,栈 (相当于数据结构)) :标准的数据结构接口
10.异常处理
------------------------------
提高代码的复用性 ????
为了少写一些代码!!!
提示:c++ 代码文件的后缀名为 xxxx.cpp
gcc 编译器,编译 C 语言代码的 ,不能编译 c++ 代码的
g++ 编译器,编译 C 语言和 c++ 的代码
C++ 中的输入输出
cout : 标准输出
cin : 标准输入
endl : 换行,刷新缓存区
------------------------------------
这个三个接口都是在 标准的 STD 库中。
使用 std::cout
std::cin
std::endl
------------------------------------
输入:std::cin >> 变量名
例子: 获取一个整形数据
int a=0;
std::cin >> a;
特点:会自动检查数据类型并输出
int a=100;
char c='A';
float b=3.14;
std::cout << a << c << b << std::endl;
cout 输出地址时注意事项:
#include <iostream>
int main()
{
int a=10086;
char b='A';
float c=3.14;
char buf[1024]={"hello"}; //怎么输出 这个数组的首地址 ??? printf("%p\n",buf);
//思考: 如何输出 数组的地址 !!! buf 地址类型 char *
std::cout << a << ":"<< b << ":" << c << std::endl;
//输出地址
std::cout << &a << ":"<< (void *)&b << ":" << &c << std::endl;
//输出
std::cout << &buf << std::endl;
//&a -> 地址类型 int *
//&b -> 地址类型 char * ,不能打印地址,因为当作他是一个字符串去处理了
//&c -> 地址类型 float *
//&buf -> 地址类型 char **
}
命名空间
作用:解决开发过程中变量名冲突的问题。
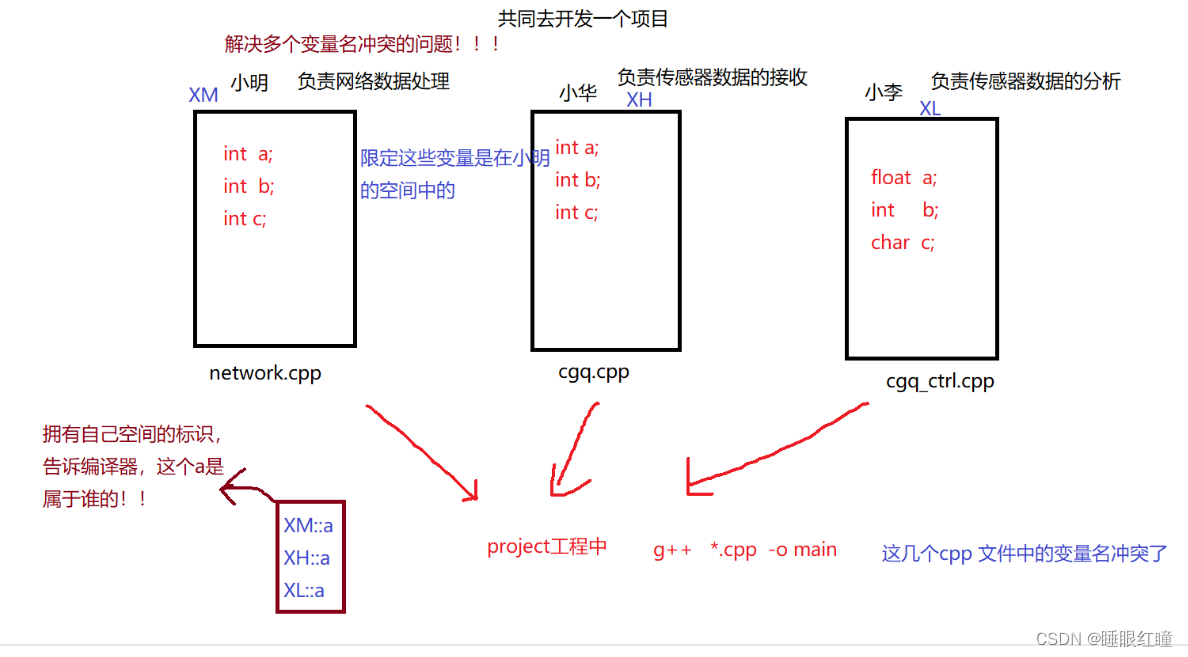
语法:
//定义
namespace 空间名
{
在该空间中的变量,函数...
}
//例子:定义小明的命名空间
namespace XM
{
int a;
int b;
int c;
}
命名空间的使用:
1.直接通过 域操作符 :: 引用空间中的内容
命名空间::变量名
例子::XM::a , XM::b ,XM::c
2.直接把整个空间的内容暴露出来 (当前程序可以看到空间中的所有内容)
using 命名空间名
例子: using namespace XM
3.暴露空间中的某一成员
using 命名空间::成员名
例子: using XM::a; (只暴露a变量)
匿名空间
作用:限制全局变量只能在当前文件中使用
提示: 功能与 静态全局变量类似 static int a = 100;
语法:
namespace
{
在该空间中的变量,函数...
}
例子:定义一个匿名空间
namespace
{
int a;
}
C 和 C ++ 的混合编程
当c++ 程序使用 C 语言接口需要声明为外部C 接口:
//声明为外部C 语言接口 ,标准写法!!
extern "C"
{
//添加 使用到的 C 语言接口头文件
}
命名空间的跨文件使用
在一个main.cpp 文件中 定义命名空间
namespace TS
{
int a=10086;
}
在另外一个文件中name.cpp声明命名空间,并说明a 是外部变量
//声明 TS 命名空间
namespace TS
{
extern int a; //声明 命名空间 TS 中的 a 是外部变量
}
回顾C 语言中的内存划分:
在C 语言中分配堆空间:
#include <stdlib.h>
void *malloc(size_t size); //分配size 大小的空间
void free(void *ptr); //释放空间
void *calloc(size_t nmemb, size_t size); //分配 nmemb * size 大小的空间
void *realloc(void *ptr, size_t size);//改变ptr 原来的空间大小为 size
void *reallocarray(void *ptr, size_t nmemb, size_t size);//改变 ptr空间大小为nmemb *size
c++ 中的内存分配
在c++ 中一般使用: new 去分配堆空间 , delete 去释放堆空间
语法:分配一个数据类型的空间
数据类型 *变量名 = new 数据类型;
//例子:分配一块int 整型的堆空间
int *p = new int; //一条龙服务器, 自己计算空间大小, 自己转换类型!!
int *p = new int(100); //初始化空间的内容
释放:
delete 指针变量名;
例子:
delete p;
语法:分配多个连续的数据类型空间
数据类型 *变量名 = new 数据类型[size]; -> size 需要分配多少个 数据类型的空间
//例子:分配 100 个 int 类型的空间
int *p = new int[100]; //只能单纯的分配堆空间,初始化动作需要用户自己去完成
释放堆空间:
delete []变量名
例子:
delete []p;
总结: malloc 和 new 的区别
1.分配一个数据空间的时候, new 可以对数据进行初始化, malloc 不行
2.在分配类的,空间时,new 会调用类中的构造函数, malloc 不行
所以在 c++ 中分配,堆空间时,采用 new !!
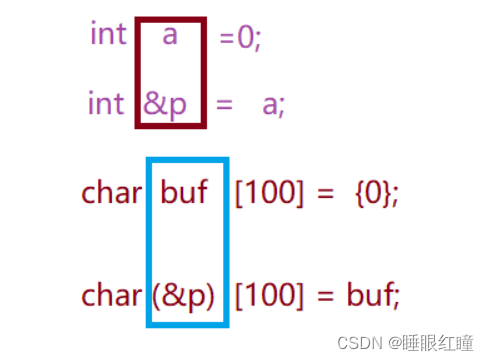
c++中的引用
回顾 C 语言中的指针: 操作内存上的数据。
引用:给已经的变量取一个别名,内存不会再为该引用分配新的内存空间,节省内存空间!!
语法:
数据类型 &引用名 = 引用的变量名
例子:
int a=100;
int &a1=a; //对 a 取一个别名为 a1
当引用作为函数参数
引用参数操作,原数据,这时候很容易,在函数中修改原数据,常量引用参数, 防止原数据被修改。
常量引用语法:
const 数据类型 &引用名
作用:防止函数修改原数据。
//对一个常量进行引用
const int &a = 100;
//当一个函数的参数是常量引用时我们可以传递变量,也可以传递常量
void add(const int &a,const int &b)
{
cout << a+b << endl;
}
int a=10,b=20;
add(a,b);
add(20,30);
-----------------------------
特殊写法:
数据类型 &&引用
int && a=100; (右值引用)
当引用作用函数的返回值
注意: 当引用作为返回值时,必须要确保当前的空间还是存在的!!
返回值的引用:一般为 静态变量,全局变量,堆空间, (传递的参数引用)
例子:
//引用作为返回值
int &ret1()
{
static int a=100;
return a; //返回a 的整个空间
}
----------------------------------------------
当一个函数返回的是引用,那么该函数可以作为左值使用
//例子:
int &ret2(int &a)
{
a = a+100;
return a;
}
int main()
{
int a=10;
ret2(a) = 10086; //把函数作为 左值使用 理解:a = 10086
cout << a << endl; // 10086
}
//练习:编写一个函数 返回一个参数的引用 ,该返回值可以 是a 也可以是常量
cout << ret(a);
cout << ret(100);
引用的注意事项:
1.引用必须初始化 (引用就是取别名,原来的对象都没有,哪里来别名??)
2.引用的类型必须要与被引用的变量数据类型一致 !
3.当引用被初始化后,就无法再次修改
c++ 中的多态
一个对象,作用于不同的事物会有多种状态。
多态:
静态多态 :在程序编译的时候,已经确定了将要执行的状态。
动态多态: 在程序运行的时候,才能确定将要执行的状态。
c++ 中的函数重载
函数重载:就是静态多态的一种设计方式。
c++ 在编译的时候就会**自动检查**,用户编写的函数,参数列表,对于各个不同参数的函数进行别名化,
来产生该函数的多种状态, 再根据用户传入的**参数**(自动推导类型),去调用不同**状态**的函数。
c++ 特有的 函数重载:
void pf(char a) //编译器自动生成 pf_char
{
cout << a << endl;
}
void pf(int a) //编译器自动生成 pf_int
{
cout << a << endl;
}
void pf(char *a) //编译器自动生成 pf_char*
{
cout << a << endl;
}
//调用
pf('A') -> 确定状态为 pf_char('A')
pf(100) -> 确定状态为 pf_int(100)
pf("hello") -> 确定状态为 pf_char*("hello")
函数重载的注意事项
1.函数重载必须函数名一样
2.函数重载是根据参数列表进行重载的(函数名相同,参数类型,个数不一样才能重载)
3.返回值不能作为重载的依据
4.调用重载函数时,需要注意调用的**歧义**
函数的默认参数
默认参数:在c++中定义函数的时候,可以使用默认参数进行,形参的赋值。
作用:简化函数的调用
//默认参数的填写顺序 必须要从 右 到 左
int pf(int a,int b,int c,int d=10)
{
cout << "a:" << a << endl;
cout << "b:" << b << endl;
cout << "c:" << c << endl;
cout << "d:" << d << endl;
}
int pf(int a,int b)
{
cout << "a:" << a << endl;
cout << "b:" << b << endl;
}
//注意:使用默认参数很容易与 函数重载发生歧义, 调用时注意处理即可
int main()
{
pf(100,200);
pf(100,200,300);//函数调用的传参顺序从 左 到 右
}
c++ 中的面向对象编程
C 语言面向过程:编写思维
例如:显示一张图片 :
1.打开LCD 设备 ,
2.对LCD 进行映射 ,
3.打开图片文件 ,
4.读取图片文件的信息 ,
5.对图片文件进行转码 ,
6.把数据放到映射地址中 ,
7,关闭LCD 设备 ,
8.解除映射
面向过程: 数据 + 算法 = 程序
C++中面向对象:
思考如果把图片显示的代码设计成一个 对象 (类)
分析:
1.初始化LCD 设备 ,设计init_lcd接口
2.设计一个显示接口 ,设计show接口
3.设计一个释放资源的接口 ,free_lcd接口
当我们把这些接口设计完毕后,那么我们的程序也就完成了。
面向对象: 对象+消息 = 程序
消息(各个对象的通信接口)
直接把他认为把我们之前的代码过程写入到类中即可
之前我们是写,程序 ,add,c show.c
现在我们是写 ,类, class add类 ,class show 类型
c++ 中类的特性
面向对象编程的核心知识点 : 类(封装,继承,多态)
封装:
1.把功能函数封装到类型里面
2.把数据成员封装到类里面,屏蔽外界对我们的干扰 。
为什么需要屏蔽??
:把一些对于外界没有意义的数据给屏蔽起来,保护类的稳定性
继承:
儿子从爸爸里面继承一些东西过来, (子类继承父类的接口,或数据)
*继承的优点: 继续父类已经做好的接口函数,提高代码复用性
多态:
同一事物对用于不同的对象,所得到的结果不一样。
*多态的优点: 提高代码复用性
面向对象的编程优点:
1.代码容易修改与维护 (需要修改类即可)
2.提高代码复用性 (继承,多态,函数重载,默认参数)
3.能够更好的设计复杂的程序 (因为在C++ 中很多库已经我们写好接口了直接调用即可)
c++ 中类的定义:
回顾C 语言中的结构体:
struct 结构体名
{
成员列表;
}
类的定义:
语法:
class 类名
{
成员列表;
}
最简单的类定义,定义出来的类是没有意义的,
因为所有的数据都是私有成员,外界无法访问。
一般类的定义:
class 类名
{
public: //共有成员,外界可以访问
protected: //保护成员,只有儿子可以访问
private: //私有成员,只有自己可以访问
};
//定义一个学生类
class student
{
public: //共有成员,外界可以访问
char name[100];
protected: //保护成员,只有儿子可以访问
int money;
private: //私有成员,只有自己可以访问
int age;
long long id;
};
类与结构体的区别:
1.类中可以设计成员的属性,对外界的访问权限进行控制
2.类中可以设计函数接口,提供用户使用
3.类的访问权限默认是provate (私有的)
4.结构体的访问权限默认的public(共有的)
5.结构体不能定义函数
c++ 类中的构造函数
构造函数的作用:
用于在定义对象的时候,初始化对象的信息。
构造函数的特点:
1.函数没有返回值
2.函数名必须与类名相同
3.构造函数在定义类的对象时会自动调用
构造函数的语法:
class 类名
{
public:
类名 () //构造函数
{
}
}
例子:
class base
{
public:
base() //构造函数
{
cout << "init base" << endl;
}
}
构造函数初始化的使用例子:
#include <iostream>
#include <string.h>
using namespace std;
//练习:定义一个 学生类,公有的姓名 , 保护的 money 私有的 ID , 设计一个构造函数初始化这些信息,
//并设计一个接口输出这些信息
class student
{
public:
student(const char *n,int m,long long i) //构造函数
{
strcpy(name,n);
money = m;
id = i;
}
//设计输出信息接口
void show()
{
cout << "name:" << name << endl;
cout << "money:" << money << endl;
cout << "id:" << id << endl;
}
char name[100];
protected:
int money;
private:
long long id;
};
int main()
{
//定义一个 student 的对象
student a("小陈",100,1314300); //传递参数给构造函数使用
// int *p = new int(100);
//调用show 接口显示信息
a.show();
}
提示:在类的内部一切数据成员都可以访问!!!
如果想要类外,访问类中的保护,私有成员,只能在类中设计,公共接口让用户访问。
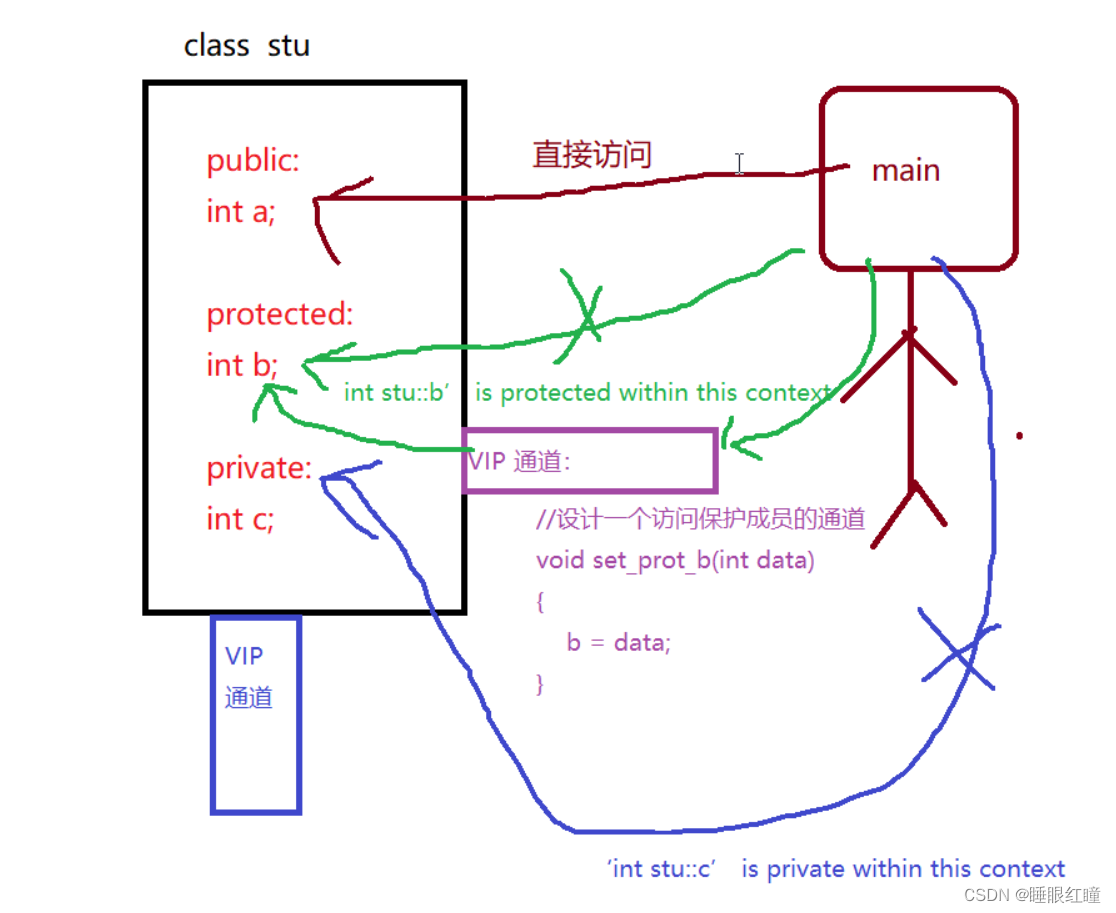
设计例子:
#include <iostream>
using namespace std;
class stu
{
public:
int a;
//设计一个访问保护成员的通道
void set_prot_b(int data)
{
b = data;
}
//设计一个访问私有成员的通道
void set_priv_c(int data)
{
c = data;
}
protected:
int b;
private:
int c;
};
int main()
{
//定义一个stu 的对象
stu a;
a.a = 10086; //访问共有成员
//a.b = 10010; //访问保护成员
//调用 stu 提供的接口去访问保护成员
a.set_prot_b(10010);
// a.c = 10000;
//调用 stu 提供的接口去访问私有成员
a.set_priv_c(10000);
}
new 和 malloc 的区别
#include <iostream>
using namespace std;
class base
{
public:
base()
{
cout << "我是构造函数" << endl;
}
base(int a,int b)
{
cout << "谢谢你给我的资源" << a << b<< endl;
}
private:
in a;
};
int main()
{
//为base 分配堆空间
base *p = (base *)malloc(sizeof(base));
//new 分配堆空间
base *p1 = new base; //调用默认的构造函数 无参
base *p2 = new base(100,200); //调用带参的构造函数
}
//总结: new会调用构造函数,malloc不会调用 ,且 new 可以传递参数给构造函数。
析构函数:
作用: 在对象死亡的时候会自动调用,用于回收该类,中分配的资源。 (堆空间,打开的文件…)
语法:
class 类名
{
public:
类名() {} //构造函数
~类名(){} //析构函数
}
//例子:
class base
{
public:
base() //构造函数
{
cout << " 创建对象 调用构造函数" << endl;
}
~base() //析构函数
{
cout << "对象死亡 调用析构函数" << endl;
}
};
特点:
函数名与类名相同在 "函数名" 前面添加 "~" , 函数没有返回值, 没有参数,
当对象销毁的时候系统自动调用
析构函数可以重载吗??
不行,因为函数重载是根据,参数列表的不同进行重载的,
构造函数根本都没有参数,怎么重载??
类中的大小计算
回顾结构体的大小结算
struct node
{
char a; //分配4个剩下 3 个
int b; //分配4个剩下 0 个
short c; //分配4个剩下 2 个
};
//大小为 12 个字节
//最大的类型是 int 所有根据 4 字节对齐的原则进行空间的分配 ,每次分配空间都只会分配 4个字节
//根据把数据类型从小到大排列,这样分配出来的结构体最小
struct node1
{
char a;
short c;
int b;
}; // 8 个
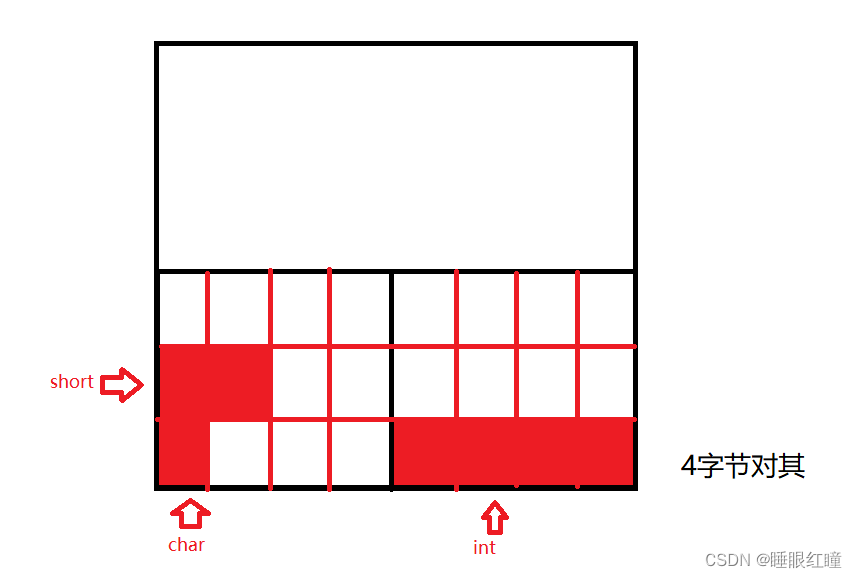
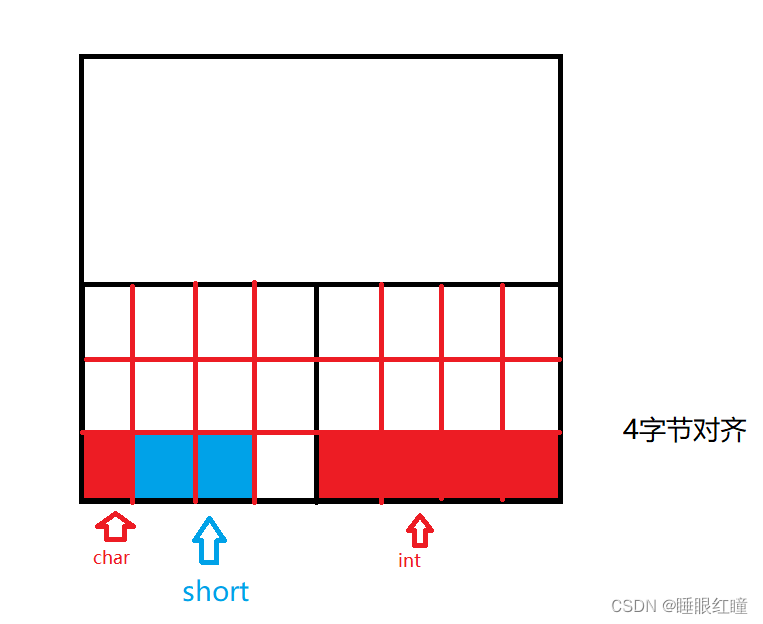
结构体中的数据是按照字节对齐的原则: 8 4 2 1 字节对齐,根据最大的数据类型的字节进行对齐。
类的大小计算
class base
{
char a;
int b;
short c;
} //12
//结论类的空间大小分配与 结构空间大分配是一样的。
所以在设计类中的数据成员时,应该把类型相同的数据放到一起,从小到大排列,这样分配出来的类所占用的空间最小。
带函数的类大小:
class base2
{
void test() //根本都没有分配空间,为什么 ???
{
int a1;//这些数据都是 test 函数里面的局部变量,没有调用 test 函数是不会分配任何空间的
short b1;
char c1;
}
int a; //4
short b; //4
char c;
}; //大小为8
结论:《类的大小与类中的函数成员无关》,因为函数中定义的变量,只有在函数调用时才会分配空间。
//空类
class base3
{
}; //大小为 1
//类的大小与成员属性无关
class base3
{
private:
char c; // 4
protected:
int b; // 4
public:
char a; // 4
}; //从上往下一直分配空间 12
构造函数的参数列表初始化
在构造函数中一种特效的初始化,类中成员方式 ,
提示:这种赋值方式并不是万能,对于一些用户自定义的数据类型无法初始化,例如:数组
例子:
class base
{
public:
//利用参数列表初始化
base(int a1,int b1):a(a1),b(b1){} //:a(a1),b(b1) 自动的把 a1 和 b1 的值赋值给 a 和b
void show()
{
cout << "a=" << a << "b=" << b << endl;
}
~base(){}
private:
int a;
short b;
};
int main()
{
base a(30,40);
a.show();
}
拷贝构造函数 (重点)
普通类的初始化 (浅拷贝-》系统默认生成的)
class base
{
public:
base(){cout << "默认构造函数" << endl;}
base(int a,int b):a(a),b(b){} //利用参数列表初始化的方式,形参可以与类中的成员同名。 系统会自动检测
//a->类中的成员(a->形参)
/*
base(int a,int b) //优先使用局部变量
{
a=a;
b=b;
}
*/
void show()
{
cout << a << endl;
cout << b << endl;
}
private:
int a;
int b;
};
int main()
{
base a(100,200);
a.show();
base b=a; //系统会自动的把 a 中的数据拷贝一份到 b 中
b.show();
}
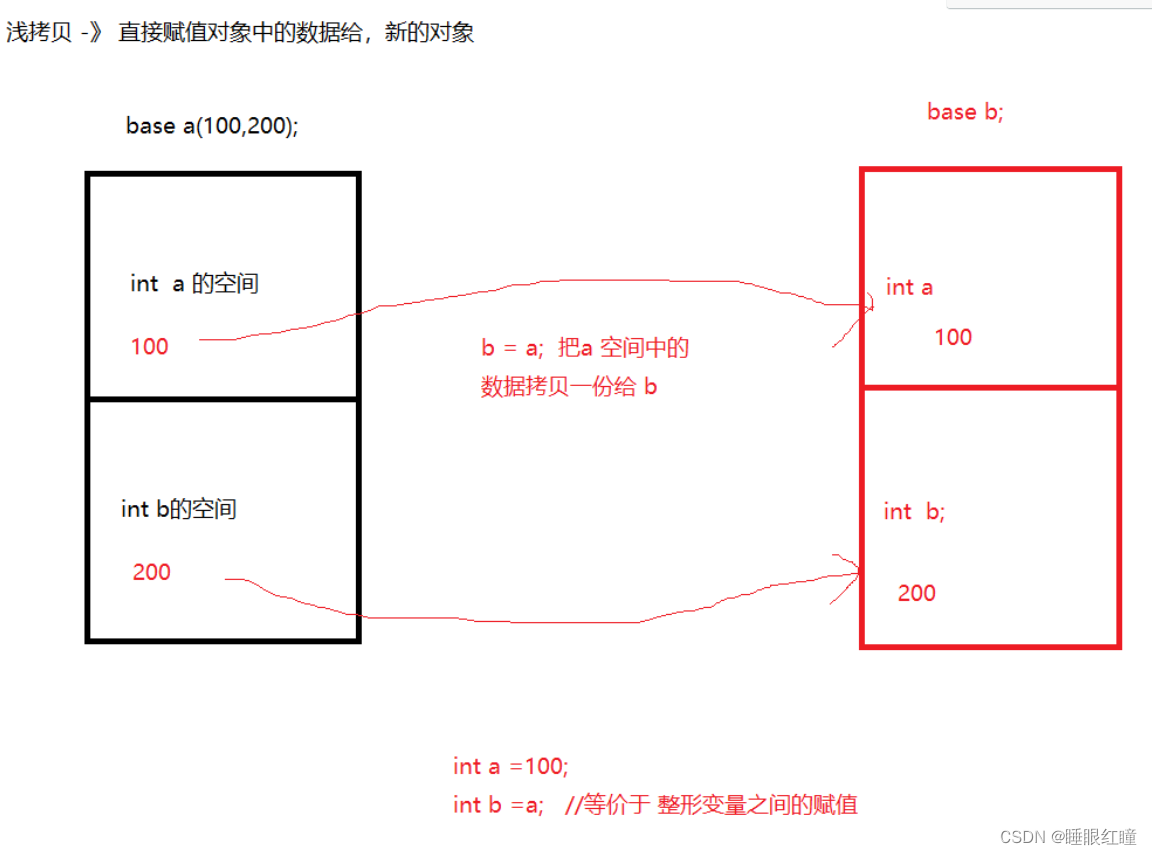
深拷贝
语法:
构造函数(类的引用)
{
}
---------------------------
例子:
MEM(MEM &)
{
cout << "调用深拷贝构造函数" << endl;
}
提示:
当用户定义了深拷贝构造函数后,系统默认的浅拷贝构造函数就不会再调用了。
拷贝构造函数什么时候调用???
用一个对象去初始化另外一个对象时,会自动调用拷贝构造函数,
当用户没有重写深拷贝,系统会自动调用,浅拷贝,
用户重写深拷贝后,就不会调用浅拷贝。
深拷贝例子:
#include <iostream>
#include <string.h>
#include <unistd.h>
using namespace std;
//在该类中分配一块堆空间
class MEM
{
public:
MEM(int size,const char *str):size(size) {
p = new char[size];
strcpy(p,str);
cout << "分配p的堆空间成功" << endl;
}
//深拷贝构造函数 (不用编译器默认的拷贝构造函数,自己实现拷贝构造函数,称为深拷贝构造函数
//注意:深拷贝的化要将所有的参数重新手动赋值,而对于在堆区申请空间的要重新申请空间
MEM(MEM &a){
cout << "调用深拷贝构造函数" << endl;
//分配一块新的堆空间
p = new char[size];
//把 a 对象中的内容也拷贝过来
strcpy(p,a.p);
size = a.size;
}
void show(){
cout << p << endl;
cout << size << endl;
cout << "堆空间的地址 " << (void *)p << endl;
}
~MEM()
{
delete p;
cout << "p的堆空间释放成功" << endl;
}
private:
char *p;
int size;
};
int main()
{
MEM a(1024,"hello");
a.show();
MEM b=a;
b.show();
}
注意:
当类中分配了 “新”(new) 的堆空间, 就不可以使用系统默认的浅拷贝方式,
否则在释放内存空间时会造成重复释放的问题,用深拷贝方式可以解决这一问题
原理
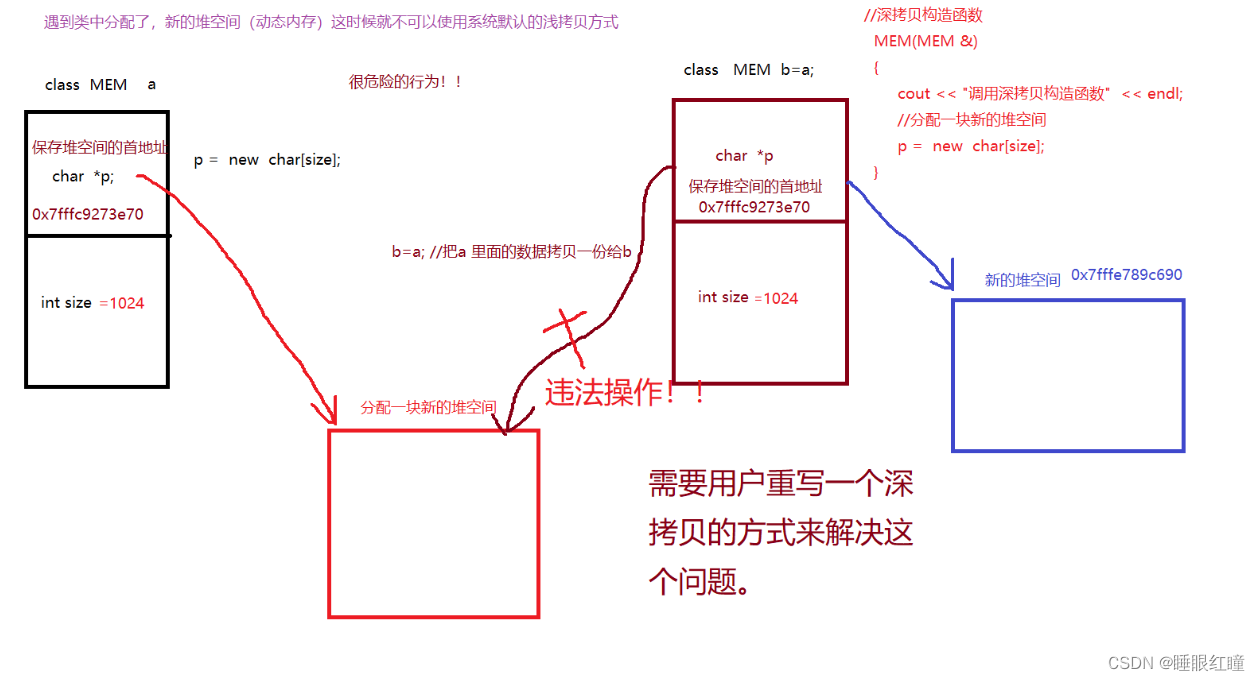
类的继承
作用:
1.提高代码的复用性
2.有利于软件版本的升级
继承:
从父类中获取一些功能接口或数据,在子类中直接使用,提高代码的复用性。
派生的时候必须要符合正常思维逻辑。
继承的语法:
class 类名:继承方式 父类名
{
//当前子类的成员
}
例子:
class person //普通人物属性
{
private:
int power;
int speel;
int life;
public:
person(){};
person(int p,int s,int l);
void show_ps();
~person();
};
//派生出来的法师类
class Master : public person
{
private:
public:
Master(/* args */){};
~Master(){};
//设计法师的技能
void atck()
{
cout << "黑龙波" << endl;
}
};
类继承成员属性的访问权限
class base
{
public: //共有成员,类外可以访问
int a;
protected: //保护成员 , 类外不可以访问 ,但子类可以访问
int b;
private: //私有成员,只有当前类可以访问
int c;
};
//子类继承 base
class new_base : public base
{
public:
void set_base() //设置base 的属性
{
a = 100;
b = 200;
// c = 300; 私有成员只能,在基类(原类)中访问
}
};
int main()
{
//类外的访问权限, 类外只能访问,共有成员!!!
base a;
a.a = 100;
// a.b = 200;
// a.c = 300;
cout << sizeof(base) << endl;
cout << sizeof(new_base) << endl;
}
//总结: 假设想要在派生类中,访问父类的成员,那么必须把父类的成员,
// 设置为 public(共有) 或者 protected (保护属性)
利用参数列表初始化父类的私有成员

类中的继承,构造函数与析构函数
调用顺序:
构造函数:先调用父类的构造函数,再调用子类的构造函数
析构函数:先调用子类的析构函数,再调用父类的析构函数
注意:当重写父类的构造函数后,记得添加父类的默认构造函数,
不然子类无法调用父类的构造函数,导致程序错误。
总结共有继承的权限问题
1.共有继承中,派生类可以访问:父类的共有和保护成员
2.共有继承中,类外可以访问: 父类的共有成员,子类中的共有成员。
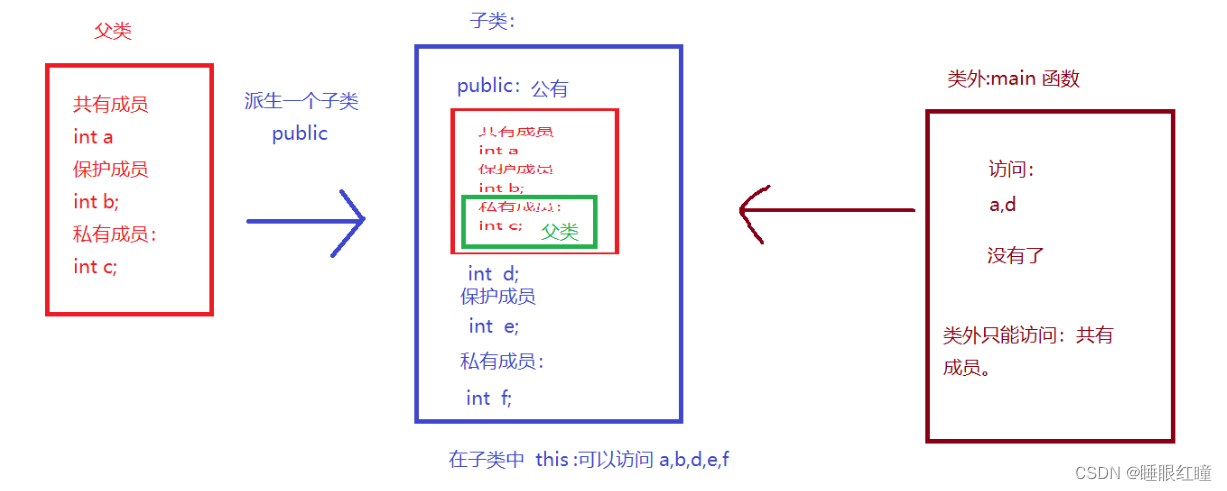
所以在类中,一般的继承方式都是使用公共继承方式。
不同继承方式访问权限
继承方式:
public (共有继承) , protected (保护继承), private (私有继承)
总结不同的继承方式规律:
1.不管使用哪一种继承方式都不会影响子类访问父类的,保护 和 共有成员 的权限。
2. 只有 公共继承 的 共有成员 类外才可以访问 !!!
3.不同的继承方式,就是用来说明,父类在子类中是属于哪一个成员属性。
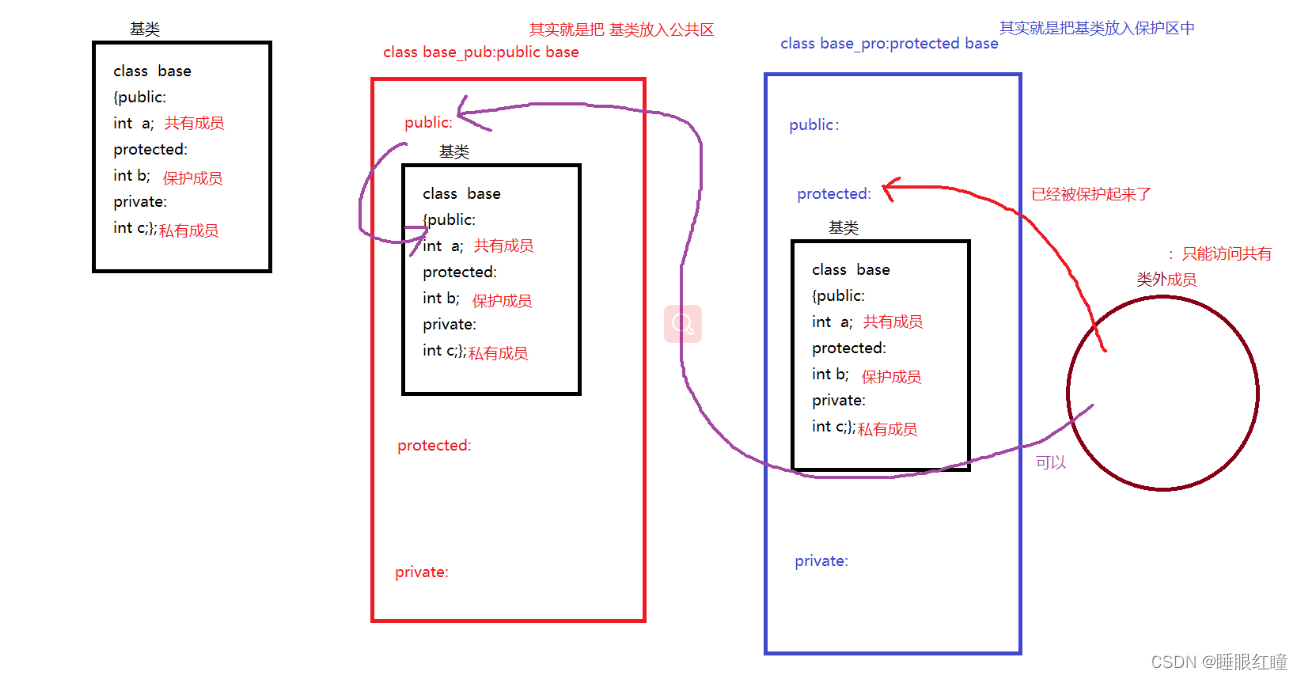
那么保护继承 和 私有继承的作用呢
在多级继承中,
假设想要派生类,访问得到,基类中的保护与 共有成员则用保护继承。
假设不想让派生类,放到得到,基类中的保护 与 共有成员,则用私有继承。
继承中的隐藏问题
类的隐藏:1.当子类的函数名 与 父类中的函数名相同时,子类会把父类的方法给隐藏掉。
2.当想要调用隐藏掉的父类接口时,需要使用 :: (域操作符指定调用父类的接口)
3.类继承中的函数方法不可以重载, 只有子类中写了与父类同名的函数,就会把父类的函数给隐藏
4.当子类 与 父类的 变量名,相同时,优先使用子类自己的变量成员, (域操作符指定使用父类的成员也可以)
#include <iostream>
using namespace std;
class base
{
public:
void show()
{
cout << "base" << endl;
}
int a=100;
};
class new_base:public base
{
public:
void show(int a)
{
cout << "new_base" << a << endl;
}
void show()
{
cout << "new_base" << endl;
}
int a=200;
};
//隐藏并不是覆盖!!!
int main()
{
new_base a;
a.show(100); // new_base 100
a.show(); // new_base 把父类的函数给隐藏了
//在子类中调用父类的接口 ,使用与操作符,指定调用父类的接口
a.base::show();
cout << a.a << endl; //隐藏了父类的成员变量 a
cout << a.base::a << endl; //指定使用父类中的成员变量 a
}
多继承
一个派生类可以继承多个父类,来获取多个父类的功能函数,与成员变量,提高代码的复用性 。
语法:
class 类名: 继承方式 父类名, 继承方式 父类名...
{
};
base : public base_a ,public base_b
构造函数执行顺序: base_a -> base_b -> base
析构函数执行顺序: base -> base_b -> base_a
多继承中的参数列表初始化:
#include <iostream>
using namespace std;
class base
{
public:
base() {cout << "base" << endl;}
base(int a):a(a){cout << "初始化 a" << endl;}
~base(){cout << "析构 base" << endl; }
private:
int a;
};
class base1
{
public:
base1(){cout << "base1" << endl;}
base1(int a):b(a){cout << "初始化 b" << endl;}
~base1(){cout << "析构 base1" << endl;}
private:
int b;
};
//定义一个new_base 同时继承 ,base 与 base1
class new_base:public base1,public base
{
public:
new_base() {cout << "new_base" << endl;}
new_base(int a,int b):base(b),base1(a){}
~new_base(){cout << "析构 new_base" << endl; }
};
int main()
{
// new_base a;
new_base b(10,20);
}
多级继承
BASE
BASE_A:public BASE
BASE_B:public BASE_A
构造函数的顺序:BASE -> BASE_A -> BASE_B
析构函数的顺序: BASE_B -> BASE_A -> BASE
多级继承的参数列表初始化:
#include <iostream>
using namespace std;
class base
{
public:
base(){ cout << "base" << endl;}
~base(){cout << "析构base" << endl;}
base(int a):a(a){}
private:
int a;
};
class base_A :public base
{
public:
base_A(){cout << "base_A" << endl;}
~base_A(){cout << "析构base_A" << endl;}
base_A(int a,int b):base(a)
{
this->b = b;
}
private:
int b;
};
class base_B:public base_A
{
public:
base_B(){cout << "base_B" << endl;}
~base_B(){cout << "析构base_B" << endl;}
base_B(int a,int b,int c):base_A(a,b)
{
this->c = c;
}
private:
int c;
};
int main()
{
// base_B a;
base_B b(10,20,30);
}
菱形继承

菱形继承的二义性解决方式
1.利用域操作符,指定使用的成员。
2.在子类中把父类的成员给隐藏
3.利用虚继承的方式 让 父类不会 分配两次空间。 (**最nice的解决方案**)
虚继承的语法:
class 类名:virtual public 基类名
{
}
//例子:
BASE
BASE_A:virtual public BASE
BASE_B:virtual public BASE
#include <iostream>
using namespace std;
class BASE
{
public:
void show()
{
cout << "show base" << endl;
}
char *p=NULL;
BASE(/* args */)
{
cout << "BASE" << endl;
p = new char[1024];
cout << "堆空间分配" << (void *)p << endl;
}
~BASE()
{
cout << "析构 BASE" << endl;
cout << "堆空间释放" << (void *)p << endl;
delete p;
cout << "释放成功" << endl;
}
};
//虚继承 BASE
class BASE_A: virtual public BASE
{
public:
BASE_A(/* args */)
{
// cout << "BASE_A" << endl;
}
~BASE_A()
{
// cout << "析构 BASE_A" << endl;
}
};
//虚继承 BASE
class BASE_B: virtual public BASE
{
public:
BASE_B(/* args */)
{
//cout << "BASE_B" << endl;
}
~BASE_B()
{
// cout << "析构 BASE_B" << endl;
}
};
//菱形继承
class BASE_ALL:public BASE_A,public BASE_B
{
private:
public:
BASE_ALL(){cout << "BASE_ALL" << endl;}
~BASE_ALL(){cout << "析构 BASE_ALL" << endl;}
};
int main()
{
BASE_ALL a;
//使用分配出来的堆空间 ???
//cout << "堆空间1" << (void *)a.BASE_A::p << endl;
//cout << "堆空间2" << (void *)a.BASE_B::p << endl;
//cout << "堆空间" <<(void *)a.p << endl;
a.BASE_B::show();
}
证明虚表的存在
#include <iostream>
using namespace std;
class base
{
public:
void show()
{
cout << "show base" << endl;
}
};
class base1
{
public:
virtual void show() //定义为虚方法 ,凡是有 virtual ,系统就会产生一个虚表
{
cout << "base1 base" << endl;
}
};
int main()
{
cout << sizeof(base) << endl; //1
cout << sizeof(base1) << endl; //8
}
虚函数:
虚函数的定义:
virtual 返回值类型 函数名(参数列表)
例子:
virtual void show() //虚函数
{
}
1.当类中含有一个虚函数时,系统就会自动分配一个虚表指针 (*vptr);
2.用户定义的所有的虚函数都在,虚表中
3.虚函数指针,保存在对象空间的最前面
4.子类会把父类的虚表指针也继承下来,子类与父共用一个虚表 (实现多态的条件)
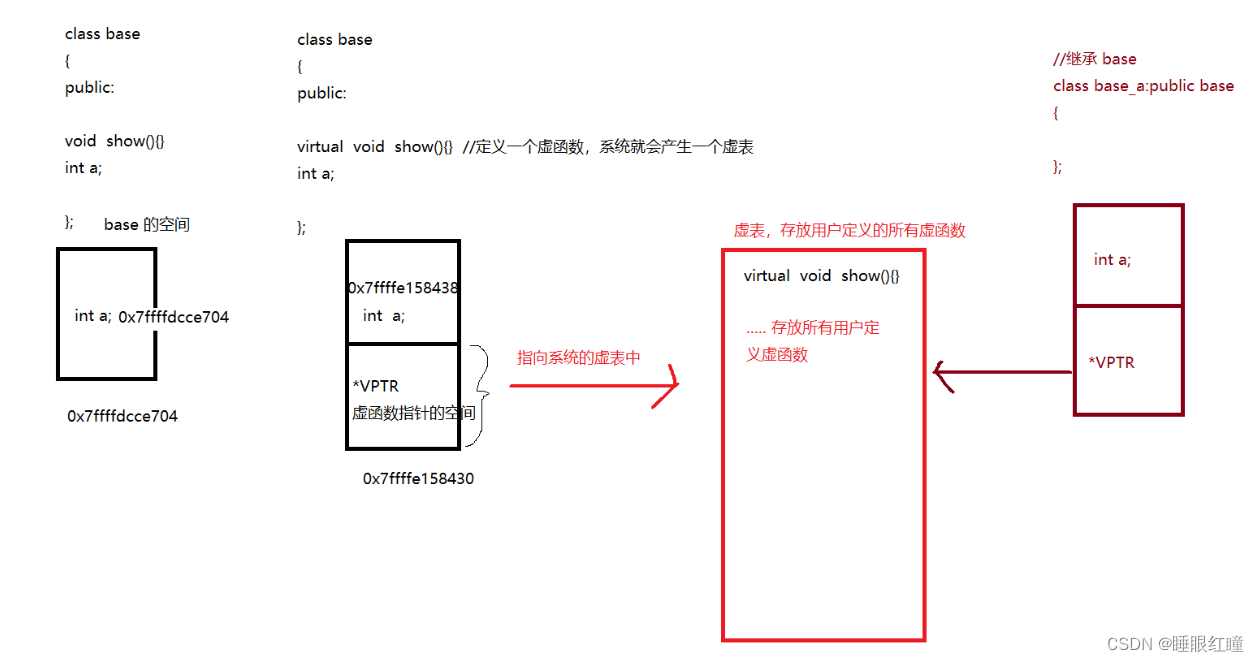
多态
作用:提高代码的复用性
什么是多态:
一个对象,作用于不同的事物,所得到的结果不一样。 (有多种状态)
静态多态:在程序编译的阶段已经确定好,将要执行的状态。 (函数重载)
动态多态:在程序运行的时候,才能确定,执行的状态。 (虚函数:派生类覆盖子类的虚方法,通过子类调用派生类重写后的虚方法)
多态的应用案例??
例如:一个人,工作有不同的职业,这时候就可以使用多态 .
一个游戏角色,有不同的装备,这时候也就可以使用多态.
利用虚函数实现多态的条件
1.要有虚函数
2.继承
3.派生类中实现父类的虚函数接口
4.把派生类的对象 赋值给 基类的 指针 或 引用,再通过基类的指针
或 引用调用 派生类重写的接口!!!
纯虚函数 与 抽象类
语法:
用法格式为:virtual 函数返回类型 函数名(参数表) =0;
例子:
virtual void show()= 0;
当一个类中,拥有一个存虚函数,那么这个类就是一个抽象类,抽象类不能创建对象 (实例化)
抽象类的作用:
设计代码的预留接口,让派生类去实现。
例如:一个人工作work ,那么工作什么东西?跟不都不知道,所以这个人不能实例化(创建对象)。 要派生以后,确定这个人是做什么事情再可以创建对象。
注意: 抽象类可以派生子类,如果子类没有对父类的纯虚函进行实例化,那么派生出来的子类还是一个抽象类。 (只有把纯虚函数进行重写后,才能创建对象)
类中的静态成员
回顾C 语言中的静态成员的特点:
1.静态成员只能被初始化一次
2.改变,变量的生命周期 (把栈区改为数据段)
3.静态全局变量,限制只能在本文件中使用
类中的静态成员:
0.静态成员,数据空间,不包含在对象空间中。 (静态:数据段中)
1.类中的静态成员只能在类外初始化
int base::b = 100;
2.静态成员数据可以直接通过类名去访问(一定要是共有成员),因为他的空间,不是在类中分配的。
(静态成员,是先于类存在的)
cout << base::b << endl;
3.静态成员数据,是该类的《所有对象》 共有的。
静态成员函数:
1.静态成员函数,不能访问非静态数据 (因为非静态数据,都是要创建对象的时候才出现的。而静态成员函数是先于类存在的)
2.静态成员函数,不能使用 this 指针。 (因为静态数据,不是在类的空间中的,this是指向当前类)
3.静态成员函数,是先于类存在的,所有我们可以直接调用该方法。
类中的const 成员
回顾 C 语言的 const :
const int *p; 常量指针, 不能修改,指向的内容的值
int * const p; 常量指针,不能修改, 指针的指向
int const *p; 常量指针,不能修改,指向的内容的值
const int * const p;常量指针,不能修改,指向的内容的值 ,不能修改, 指针的指向
看 *p 有没有在一起,在一起就是内容不可能,没在一起就是,指向不可以改变。
类中的常量成员
作用: 提高程序的稳定性与安全性。
常量成员:
1.类中有常量成员,必须要初始化,否则无法创建对象。 (构造,默认值)
2.常量成员初始化后就不能再次修改。
常量函数:
1.成员函数后面加 const 就变成常量函数
2.常量函数不可以 修改类中的 所有成员。
3.如果用户想要这个常量函数,去修改类中的成员必须在,该成员前加 mutable 关键字
class base1
{
public:
void show() const //定义一个常函数
{
cout << "a="<< a << endl;
cout << "b="<< b << endl;
// a = 200;
b = 300;
cout <<"a="<< a << endl;
cout << "b="<< b << endl;
}
int a=100;
mutable int b=200; //允许常函数,去修改他的值
};
常对象:
1.利用const 去修饰对象,就是常对象
2.常对象,只能调用常函数。
3.常对象,不能修改公共成员变量。 (mutable 关键字 ,可以帮到你)
c++ 文件IO
<iostream>库自动定义了一些标准对象:
cout, ostream类的一个对象,可以将数据显示在标准输出设备上. -> printf
cerr, ostream类的另一个对象,它无缓冲地向标准错误输出设备输出数据. -> perror
clog, 类似cerr,但是它使用缓冲输出.
cin, istream类的一个对象,它用于从标准输入设备读取数据. -> scanf
文件操作
<fstream>库允许编程人员利用**ifstream**和**ofstream**类进行文件输入和输出.
**fstream** : 文件的读写操作库
**ifstream**:读操作库
**ofstream**:写操作库
操作一个文件的流程:
1.打开文件
2.读取/写入文件
3.关闭文件
打开文件的构造函数:
fstream( const char *filename, openmode mode ); //读写操作打开
ifstream( const char *filename, openmode mode ); //读操作打开
ofstream( const char *filename, openmode mode );//写操作打开
filename:文件的路径名
mode:权限
| ios::app | 以追加的方式打开,写 |
|---|---|
| ios::ate | 打开文件并把光标偏移到文件末尾 |
| ios::binary | 以二进制模式打开文件 |
| ios::in | 为读取打开文件 |
| ios::out | 为写入打开文件 |
| ios::trunc | 如果文件存在,则覆盖 |
写入文件的demo:
#include <iostream>
#include <fstream> //文件操作头文件
using namespace std;
int main()
{
//往一个文件中写入数据
ofstream w_file("my.txt",ios::out);
w_file << "hello"; //写入hello ,利用重载后的符合进行写入
//关闭文件
w_file.close();
}
读取文件的demo:
ifstream r_file("my.txt",ios::in);
char buf[1024]={0};
while (r_file >> buf)
{
//把文件的内容读取到buf 中
cout << buf << endl;
}
r_file.close();
利用 ifstream 类中提供的open 方法打开的文件:
ifstream fd; //定义一个对象
//打开一个文件
fd.open("my11111.txt",ios::in);
//判断文件是否打开
if(!fd.is_open())
{
cerr << "打开文件失败" << endl;
return 0;
}
else
{
cout << "打开文件成功" << endl;
}
//进行读取操作
while (1)
{
char a = fd.get(); //读取一个字符
cout << a << endl;
if(fd.eof())
{
break;
}
}
fd.close();
c++ 中的友元
回顾C++ 中的类成员访问权限:
class base
{
public: //公有:类内 ,类外,子类都可以访问
protected: //保护 :类内,子类可以访问
private: //私有 :类内 可以访问
}
友元:
作用:用于访问类中的 所有数据成员。 (公有,保护,私有都可以访问)
缺点: 破坏类的封装,所以万不得已不要使用友元。
友元函数:
1.友元函数,不属于当期类中。
2.友元函数,需要在类中声明。
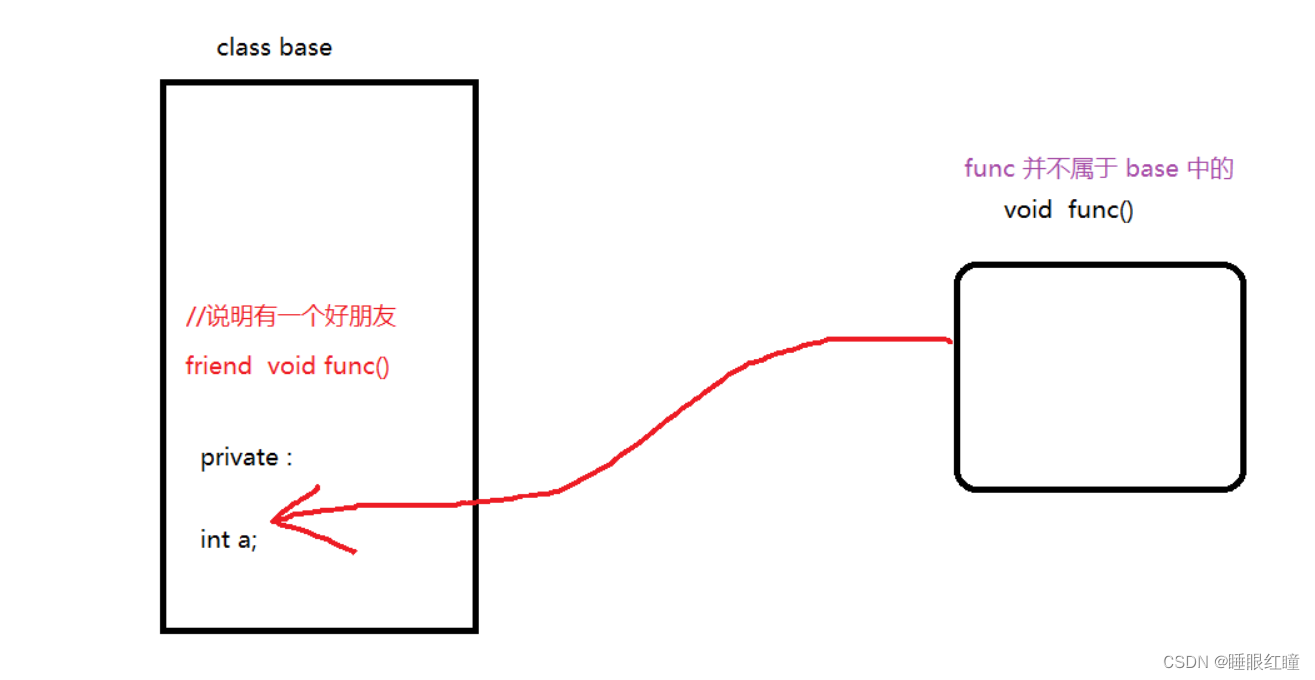
语法:
friend 函数的声明
例子:
friend void func();
class base
{
//声明一个友元函数
friend void func(base &a);
private:
int a;
};
//定义函数
void func(base &a)
{
a.a = 100; //访问私有成员
cout << a.a << endl;
}
int main()
{
base a;
func(a);
a.func(a); //func 不属于,base 类中的函数
}
友元可以继承吗??
不可以,友元,只与声明他的类有关系!!
友元可以一对多,多对一吗?
肯定可以的!!!
友元类:
作用: 在类中访问其他类的所有数据成员 (公用,保护,私有)
语法:
friend 类名
例子: 声明base 类是当前类的友元
friend class base
例子:声明两个类互为友元
#include <iostream>
using namespace std;
//前向声明
class base_A; //老版本的编译器,需要前向声明,才能够在 base 中声明 base_A 为他的友元。
class base
{
private:
int a;
//声明一个友元
friend class base_A;
public:
//访问 base_A 的私有成员
void show_base_A(base_A &a); //单纯的声明 ,因为base_A 还没有定义
};
class base_A
{
public:
void show_base(base &a) //直接在 类内,去访问,base a 的成员
{
a.a = 100; //访问 base 的私有成员
cout << a.a << endl;
}
//声明 base 是base_A 的友元
friend class base;
private:
int b;
};
//在 base_A 定义后;再实现
void base::show_base_A(base_A &a)
{
a.b = 10086;
cout << a.b << endl;
}
int main()
{
base a;
base_A b;
b.show_base(a);
a.show_base_A(b);
}
声明类中的成员函数为友元:
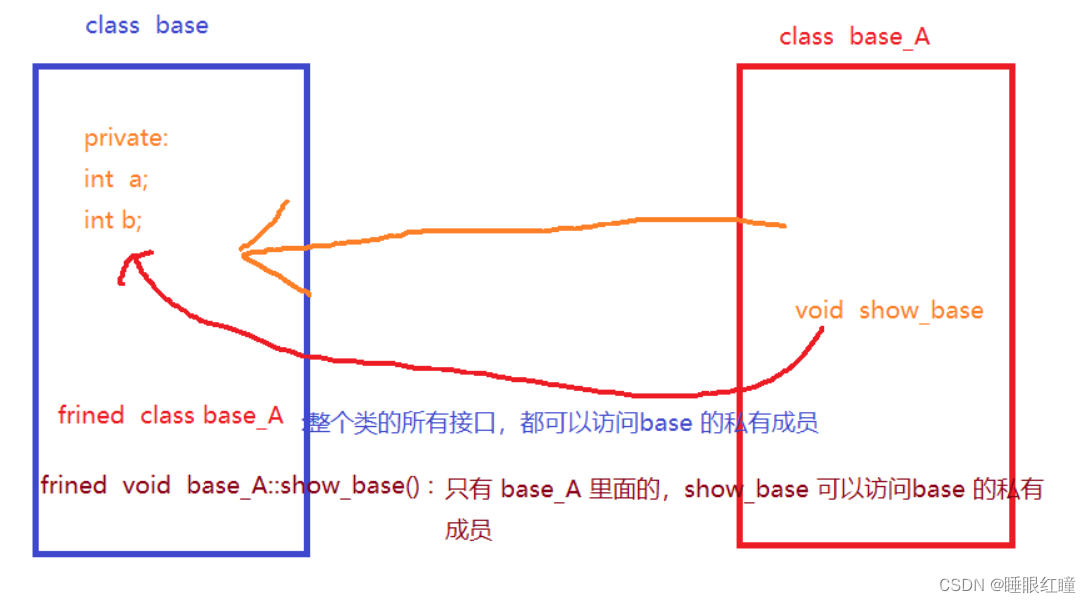
#include <iostream>
using namespace std;
class base_A
{
public:
void show();
void show_base();
};
class base
{
private:
int a;
//声明 base_A 是他的友元
//friend class base_A;
friend void base_A::show_base(); //只声明 base_A 中的 show_base 为友元
};
void base_A::show()
{
/*
base a;
a.a = 100;
cout << a.a << endl;
*/ //不能访问 ,base 的私有成员
}
void base_A::show_base()
{
base a;
a.a = 100;
cout << a.a << endl;
}
int main()
{
}
运算符重载
什么是运算符重载??
重新定义运算符的功能,(因为之前使用的运算符功能是有限的,
例如无法实现两个字符串的相加,
两个类的相加,这时候我们就需要重新定义运算符的功能)
int a=10;
int b=20;
int sum=a+b; //对于基本的数据类型操作是没有问题的
class A
{
pulbic:
A(int a):a(a){}
int a;
}
A a;
A b;
A c = a+ b;//不行的,因为 A 不是基本的数据类型 ,必须要对 + 号进行重载
运算符重载的格式:
返回值类型 operator 运算符符号(参数表)
例子:
A operator +(base a)
{
}
可以重载的运算符:
1,那些运算能重载
双目运算符 (+,-,*,/, %) operator+
关系运算符 (==, !=, <, >, <=, >=)
逻辑运算符 (||, &&, !)
单目运算符 (*, &, ++, --)
位运算符 (|, &, ~, ^, <<, >>)
赋值运算符 (=, +=, -=, .....)
空间申请运算符 (new , delete)
其他运算符 ((), ->, [])
2,那些运算符不能重载
.(成员访问运算符)
.*(成员指针访问运算符)
::(域运算符)
sizeof(数据类型长度运算符)
?:(条件运算符, 三目运算符)
运算符的重载方式:
类内重载方式:
base operator+(base tmp) :可以使用 this 指针。
调用规律:
base c=a+b; -> a.operator+(b) 调用的时候就是这种形式的。
规则:a是调用者,b是参数。
类外的重载方式:
base operator+(base a,base b) :没有this 指针
规则: a 是参数1 b 是参数2
注意:这两种方式都可以对运算符进行重载,选择哪一种方式,需要自己去决定那个比较合适,就选那个。
双目算符重载:
#include <iostream>
using namespace std;
class base
{
public:
base(){};
base(int a):a(a){};
int a;
//重载加法运算符
base operator+(base a)
{
base c=this->a + a.a;
return c;
}
//重载减法运算符
base operator-(base a)
{
base c = this->a - a.a;
return c;
}
};
int main()
{
base a(10);
base b(20);
base c=a+b;
cout << c.a << endl;
base d=a-b;
cout << d.a << endl;
}
关系运算符的重载:
class base
{
public:
base(){};
base(int a):a(a){};
int a;
//类内的重载方式
bool operator>(base b)
{
if(this->a > b.a)
{
return true;
}
else
{
return false;
}
}
};
//类外重载方式
bool operator==(base a,base b)
{
if(a.a == b.a )
{
return true;
}
else
{
return false;
}
}
单目运算符重载 : a++,++a
class base
{
public:
base(){};
base(int a):a(a){};
int a;
//重载单目运算符 a++ ,先用值在自加
base operator++(int)
{
cout << "调用a++" << endl;
//先保存 a 的值
base tmp;
tmp.a = this->a;
//自加
this->a++;
return tmp; //返回还没加的值
}
//重载单目运算符 ++a
base operator++()
{
cout << "调用++a" << endl;
this->a++; //增加
return *this; //返回本身
}
};
输入输出的运算符重载
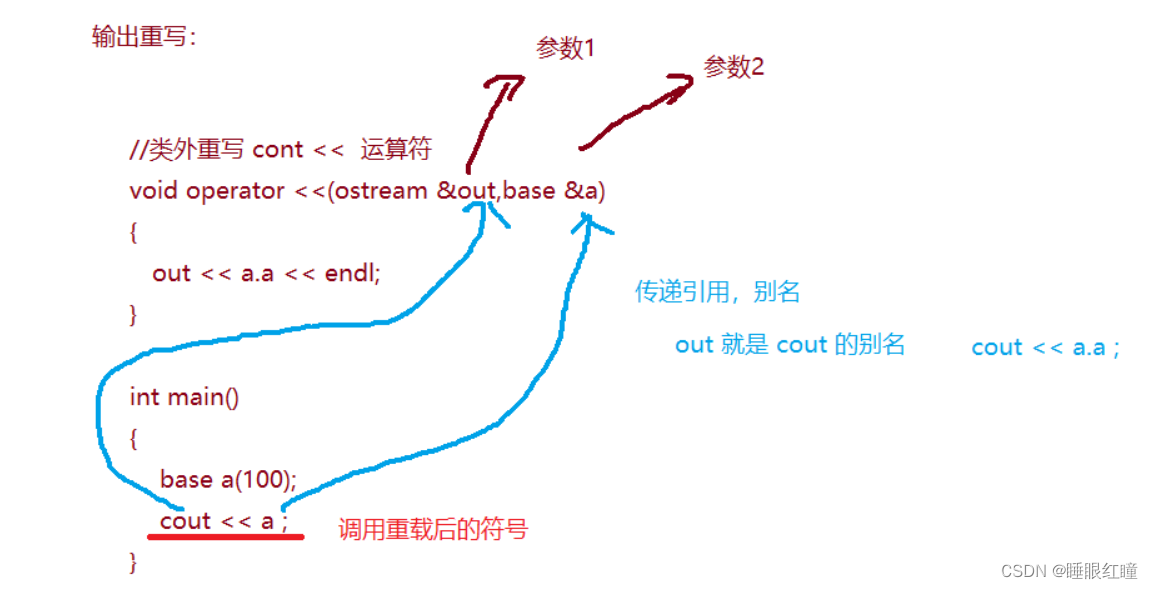
#include <iostream>
using namespace std;
class base
{
private:
int b=200;
public:
base(){}
base(int a):a(a){}
int a;
friend ostream & operator <<(ostream &out,base &a);
};
//类外重写 cont << 运算符
ostream & operator <<(ostream &out,base &a)
{
out << "a:"<< a.a << endl;
out << "b:"<< a.b << endl;
return out;
}
//类外重写 cin >> 运算符
istream &operator>>(istream &in,base &a)
{
cout << "请输入a 的值" << endl;
in>>a.a;
cout << "请输入b 的值" << endl;
in >>a.b;
}
int main()
{
base a(100);
cout << a << 10 << endl;
}
string 类使用
构造函数:
语法:
string();
string( size_type length, char ch );
string( const char *str );
string( const char *str, size_type length );
string( string &str, size_type index, size_type length );
字符串的构造函数创建一个新字符串,包括:
以length为长度的ch的拷贝(即length个ch)
以str为初值 (长度任意),
以index为索引开始的子串,长度为length, 或者
重载的运算符:

类型转换:
data
语法:
const char *data(); //把 string 类转换成 字符串数组 char buf[]
data()函数返回指向自己的第一个字符的指针.
**查找: **
size_type find( const char *str, size_type index );
//从 index 位置开始找 ,找 str 字符串
插入:
basic_string &insert( size_type index, const char *str );
//在index 的位置插入 str
长度:
长度(length)
语法:
size_type length();
length()函数返回字符串的长度. 这个数字应该和size()返回的数字相同.
替换:
basic_string &replace( size_type index, size_type num, const char *str );
//index 位置 替换 num 字符, 从 str中替换
什么是模板
做好的一个样式,用户使用的时候直接去套用就可以了。
模板是不能直接使用的,必须实例化才可以使用

c++中的模板
函数模板:
作用: 提高代码的复用性
如果要一个函数实现多种数据的处理,函数重载的方式去进行。
为了通用性更加强,c++ 就引用入了函数模板的功能。 在调用的时候,根据传递的数据类型,系统自动推导数据类型。
语法:
通用类型定义 :声明一个模板类型为 T
template<typename T>或 template<class T>
函数的定义
例子:
template<class T> //声明一个模板类型为T
T swap(T &a,T &b) //声明一个模板函数,有一个通用类型 T
{
}
模板函数的例子:
#include <iostream>
using namespace std;
//交互两个数的值 ,整形,字符,字符串,浮点型
template <class T> //声明一个通用类型 T
void myswap(T &a,T &b) //定义了一个模板函数
{
//打印数据类型
// cout << typeid(a).name() << endl;
T tmp = a;
a = b;
b= tmp;
return ;
}
int main()
{
int a=10,b=20;
myswap(a,b); //已经根据自动推导,确定了 T 的类型为 int
cout << a << ":" << b << endl;
char a1='A',b1='C';
myswap(a1,b1); //已经根据自动推导,确定了 T 的类型为 char
cout << a1 << ":" << b1 << endl;
string a2="asd" ,b2="123";
myswap(a2,b2); //已经根据自动推导,确定了 T 的类型为 string
cout << a2 << ":" << b2 << endl;
}
//练习: 定义一个模板函数实现两个数据的相加
模板函数 与 普通函数的区别:
*普通函数调用时,可以发送自动类型转换。
*模板函数在调用时,不会发生自动类型转换,自会发生类型的推导。
解决方法: 1.指定模板的类型,不需要自动推导
2.再定义一个模板类型,让系统成功推导
#include <iostream>
using namespace std;
/*
template <class T> //声明一个模板类型 T
T add(T a,T b)
{
return a + b;
}
*/
template <class T,class T1> //声明一个模板类型 T
T add(T a,T1 b)
{
cout << typeid(a).name() << endl;
cout << typeid(b).name() << endl;
return a + b;
}
/*
int add(int a,int b)
{
return a+b;
}
*/
int main()
{
cout << add(10,3.14) << endl; //发生自动推导的过程中,无法确定 T 的类型,模板无法实例化。
cout << add<float,float>(10,3.14) << endl; //指定类型
}
模板函数 与 普通函数的 调用规则:
- 当模板函数 与 普通函数都能实现 功能时,优先使用普通函数.
- 当用户只想调用模板函数时,可以使用 <> 进行指定。
- 当模板函数比普通函数更好匹配时,优先调用,模板函数 (编译器很醒目的!!)
- 模板函数也可以重载
#include <iostream>
using namespace std;
template <class T>
T add(T a, T b)
{
cout << "调用模板函数" << endl;
return a+b;
}
int add(int a,int b)
{
cout << "调用普通函数" << endl;
return a+b;
}
int main()
{
cout << add(10,20) << endl;
cout << add<>(10,20) << endl; //指定,参数,调用模板函数
cout << add(3.14,6.66) << endl; //编译器,比你聪明!!
}
模板函数的局限性:
对于用户自定义的数据类型,模板函数是无法进行,数据操作的。
对于特殊数据类型的处理方法:
#include <iostream>
using namespace std;
class base
{
public:
base(){}
base(int a):a(a){}
/*
bool operator>(base &b)
{
if(this->a > b.a)
{
return true ;
}
else
{
return false;
}
}*/
friend bool big(base &a,base &b);
private:
int a;
};
//重写模板函数的特效情况
bool big(base &a,base &b)
{
if(a.a > b.a)
{
return true;
}
else
{
return false;
}
}
template <class T>
bool big(T &a,T &b)
{
if(a > b)
{
return true;
}
else
{
return false;
}
}
//练习:解决用户自定义类型的模板比较问题!!!
int main()
{
// int a=10,b=20;
base a(100),b(20);
if(big(a,b))
{
cout << "A BIG" << endl;
}
else
{
cout << "B BIG" << endl;
}
}
模板类
当一个类中函数一个模板的数据类型,该类就是模板类,模板没有实例化前,不能定义对象。
语法:
template <class 模板类型>
class 类名
{
模板类型 变量名
}
-------------------------------
例子:
template <class T>
class base
{
public:
T a;
}
模板类没有自动推导的功能!!!!!
#include <iostream>
using namespace std;
//定义一个模板类
template <class T>
class base
{
public:
base(){}
base(T a):a(a){}
T a; //类中含有一个模板类型,该类就是模板类
};
int main()
{
base<int> a(10); //没有自动推导,必须要指定类型,才能创建对象!!
cout << a.a << endl;
}
模板类与模板函数的区别:
1.模板类没有自动推导的功能, 模板函数有。
2.模板类可以使用默认类型
//定义一个模板类
template <class T=int> //定义一个模板类型,并赋值他的默认类型为 int
class base
{
public:
base(){}
base(T a):a(a){}
T a; //类中含有一个模板类型,该类就是模板类
};
//定义模板类对象的时候,必须要有 <>
base<> a(10); //使用默认类型
练习: 定义一个模板类,一个姓名 N_T ,年龄 A_T ,并为姓名和年龄赋值默认参数 string,int ,创建该模板类的对象,输出数据。
#include <iostream>
#include <string.h>
using namespace std;
//模板类的默认参数填写,必须要从 右 -》 左
template <class N_T=string,class A_T=int>
class person
{
public:
person(){}
person(N_T a,A_T b):a(a),b(b){}
void show()
{
cout << "姓名"<< a << endl;
cout << "年龄"<< b << endl;
}
private:
N_T a;
A_T b;
};
int main()
{
//模板参数的传递是从左 -> 右
person<> a("小明",18);
a.show();
}
模板类作为函数的参数传递:
注意:如果一个类是模板类,就无法直接通过类名作为参数的传递。
解决方法:
1.在函数的参数列表中,对模板类,的类型进行指定。
2.继续把类型模板化 。
3.设计一个模板函数。 把整个类型模板化
#include <iostream>
#include <string.h>
using namespace std;
//定义一个模板类
template <class T=int> //定义一个模板类型,并赋值他的默认类型为 int
class base
{
public:
base(){}
base(T a):a(a){}
T a; //类中含有一个模板类型,该类就是模板类
};
//1.直接指定 T 的类型
void show_base(base<int> &p)
{
cout << p.a << endl;
}
//2.继续参数 T 模板化
template <class T>
void show_base1(base<T> &p)
{
cout << p.a << endl;
}
//3.直接把参数模板化
template <class T>
void show_base2(T &p) //模板函数,是在调用的时候才生成的 ,这里只是单纯的声明
{
cout << p.a << endl;
}
int main()
{
base<> a(10086);
show_base(a);
show_base1(a);
show_base2(a);
}
最常用的是第一种解决方法,直接指定类型
模板的成员函数的类外编写:
#include <iostream>
using namespace std;
template <class T=int>
class base
{
public:
base(){}
base(T a); //声明
void show(); //声明
T data;
};
//类外实现,模板类的函数接口
template <class T>
base<T>::base(T a)
{
data = a;
}
template <class T>
void base<T>::show()
{
cout << data << endl;
}
int main()
{
base<int> a(10);
a.show();
}
模板类的继承
注意事项:
1.当一个派生类继承的基类是模板类是,必须要对基类的类型进行指定
2.可以继续把类型模板化
#include <iostream>
using namespace std;
//设计一个模板类
template <class T>
class base
{
public:
T a;
};
//派生一个子类
template <class T>
class new_base:public base<T> //继续把 new_base 模板化
{
public:
T b;
void init(int a,int b)
{
this->a = a;
this->b = b;
}
void show()
{
cout << this->a << endl;
cout << this->b << endl;
}
};
class base_A:public base<int> //直接指定 base 中的类型
{
public:
int b;
void init(int a,int b)
{
this->a = a;
this->b = b;
}
void show()
{
cout << this->a << endl;
cout << this->b << endl;
}
};
int main()
{
new_base<int> a;
a.init(10,20);
a.show();
base_A b;
b.init(30,40);
b.show();
}
vector 容器接口:
构造函数:
vector(); //默认构造
vector( size_type num, const TYPE &val ); //把 num 个 val 值放到容器中
vector( const vector &from ); //拷贝构造函数,实现深拷贝
vector( input_iterator start, input_iterator end) //利用迭代器,赋值区间元素
使用STL库的时候记得添加头文件!!
构造例子:
//定义一个vector 容器 ,vector 模板类
vector<int> a(5,100); //指定容器存放 ,int 类型的数据
STL库中的迭代器:
迭代器: 相当于一个专用指针,指向 容器中的数据。
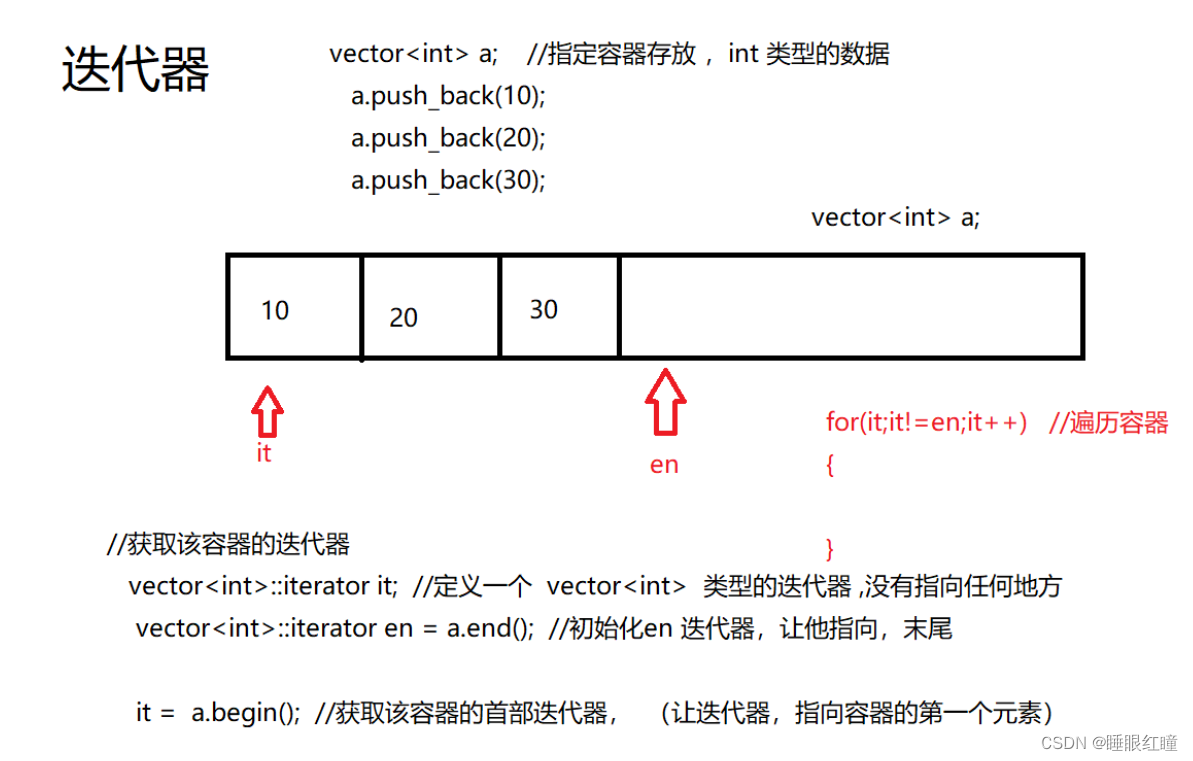
begin 函数
语法:
iterator begin();
begin()函数返回一个指向当前vector起始元素的迭代器.例如,下面这段使用了一个迭代器来显示出vector中的所有元素:
vector<int> v1( 5, 789 );
vector<int>::iterator it; //定义一个迭代器
for( it = v1.begin(); it != v1.end(); it++ )
cout << *it << endl;
end 函数
语法:
iterator end();
end() 函数返回一个指向当前vector末尾元素的下一位置的迭代器.注意,如果你要访问末尾元素,需要先将此迭代器自减1.
其他函数接口:
size 函数
语法:
size_type size();
size() 函数返回当前vector所容纳元素的数目
at函数
语法:
TYPE at( size_type loc ); -》 等价于 []
insert 函数
语法:
iterator insert( iterator loc, const TYPE &val );
void insert( iterator loc, size_type num, const TYPE &val );
void insert( iterator loc, input_iterator start, input_iterator end );
insert() 函数有以下三种用法:
在指定位置loc前插入值为val的元素,返回指向这个元素的迭代器,
在指定位置loc前插入num个值为val的元素
在指定位置loc前插入区间[start, end)的所有元素
erase 函数删除
语法:
iterator erase( iterator loc );
iterator erase( iterator start, iterator end );
erase函数要么删作指定位置loc的元素,要么删除区间[start, end)的所有元素.返回值是指向删除的最后一个元素的下一位置的迭代器.例如:
push_back 函数
语法:
void push_back( const TYPE &val );
push_back()添加值为val的元素到当前vector末尾
deque 容器的使用
deque与vector区别:
vector对于头部的插入删除效率低,数据量越大,效率越低
deque相对而言,对头部的插入删除速度回比vector快,vector访问元素时的速度会比deque快,这和两者内部实现有关。
deque与vector区别:
支持头部直接操作:
pop_front
语法:
void pop_front();
pop_front()删除双向队列头部的元素。
push_front
语法:
void push_front( const TYPE &val );
push_front()函数在双向队列的头部加入一个值为val的元素。
SET 容器的使用
set基本概念
简介:
所有元素都会在插入时自动被排序
本质:
set/multiset属于关联式容器,底层结构是用二叉树实
现。
set和multiset区别:
set不允许容器中有重复的元素
multiset允许容器中有重复的元素
构造函数:
构造:
set<T> st; //默认构造函数:
set(const set &st); //拷贝构造函数
赋值:
set& operator=(const set &st); //重载等号操作符
插入和删除:
iterator insert( iterator i, const TYPE &val ); //从 i 的位置插入的数据 val
void insert( input_iterator start, input_iterator end );//插入一个区间的数据
pair insert( const TYPE &val );//插入一个数据
erase
语法:
void erase( iterator i ); //删除i位置(迭代器)的数据
void erase( iterator start, iterator end ); //删除迭代器中的一个区间
size_type erase( const key_type &key );//根据数值删除
查找接口:
find
语法:
iterator find( const key_type &key );
在当前集合中查找等于key值的元素,并返回指向该元素的迭代器;如果没有找到,返回指向集合最后一个元素的迭代器。
利用set 容器插入用户的自定义数据类型:
#include <iostream>
#include <set>
using namespace std;
class person
{
public:
person(){};
person(string n,int a):name(n),age(a){};
string name;
int age;
};
//重写比较接口 !!!!!!重点
class comparePerson
{
public:
bool operator()(const person& p1, const
person &p2)
{
//按照年龄进行排序 降序
return p1.age < p2.age;
}
};
int main()
{
//定义一个 set 容器 , 利用 comparePerson 的方式进行数据的比较
set<person,comparePerson> a;
person p("小明",18);
person p1("小飞",20);
person p2("小彭",16);
//插入 ,无法插入,因为 set 容器比较不了, person 数据类型的大小
a.insert(p);
a.insert(p1);
a.insert(p2);
//遍历
set<person,comparePerson>::iterator it = a.begin();
for(it;it!=a.end();it++)
{
cout << it->name <<":" <<it->age << endl;
}
}
Lists 容器的使用
构造函数:
函数原型:
list<T> lst; //list采用采用模板类
实现,对象的默认构造形式:
list(beg,end); //构造函数将[beg,end)区间中的元素拷贝给本身。
list(n,elem); //构造函数将n个elem拷贝给本身。
list(const list &lst); //拷贝构造函数
插入方法:
push_back
语法:
void push_back( const TYPE &val ); //尾插
--------------------------------------------------------------------------------
void push_front( const TYPE &val ); //头插
iterator insert( iterator pos, const TYPE &val );//在pos 的位置插入val
void insert( iterator pos, size_type num, const TYPE &val );//在pos的位置插入 num 个val
void insert( iterator pos,input_iterator start,input_iterator end );//在pos的位置插入区间为 start -》 end 的值
删除方法:
unique
语法:
void unique(); //只会删除相邻重复的
void unique( BinPred pr );
unique()函数删除链表中所有重复的元素。如果指定pr,则使用pr来判定是否删除。
//指定元素位置删除
iterator erase( iterator pos );
iterator erase( iterator start, iterator end );
erase()函数删除以pos指示位置的元素, 或者删除start和end之间的元素。 返回值是一个迭代器,指向最后一个被删除元素的下一个元素。
//删除多个重复
remove
语法:
void remove( const TYPE &val );
stack 栈
什么是栈?
一种先进后出的数据结构。
构造函数:
stack<T> stk; //stack采用模板类
实现, stack对象的默认构造形式
stack(const stack &stk); //拷贝构造函数
栈的操作:
bool empty(); //判断当前栈是否为 NULL
void pop(); //出栈
void push( const TYPE &val ); //入栈
size_type size(); //返回当前栈的大小
TYPE &top(); //取出栈顶的元素
//操作例子
while( !s.empty() ) {
cout << s.top() << " "; //取出栈顶的元素
s.pop(); //出栈
}
queue 队列
概念:Queue是一种先进先出(First In First Out,FIFO)的数据结构。
构造函数:
queue<T> que; //queue采用模板类
实现,queue对象的默认构造形式
queue(const queue &que); //拷贝构造函数
队列的操作:
TYPE &back(); //back()返回一个引用,指向队列的最后一个元素。
bool empty(); //判断队列是否为NULL
TYPE &front(); //front()返回队列第一个元素的引用。
void pop(); //出队
void push( const TYPE &val ); //入队
size_type size(); //求队列的大小
map 容器:
map/ multimap容器
map基本概念
简介:
map中所有元素都是pair
pair中第一个元素为key(键值),起到索引作用,第二个元素为value(实值)
所有元素都会根据元素的键值自动排序
本质:
map/multimap属于关联式容器,底层结构是用二叉树
实现。
优点:
可以根据key值快速找到value值
map和multimap区别:
map不允许容器中有重复key值元素
multimap允许容器中有重复key值元素
构造函数:
构造:
map<T1, T2> mp; //map默认构造函数: T1 -> key T2->value
map(const map &mp); //拷贝构造函数赋值:
map& operator=(const map &mp); //重载等号操作符
插入数据接口:
语法:
//在pos 的位置中插入一个 pair对组(key:value)
iterator insert( iterator pos, const pair<KEY_TYPE,VALUE_TYPE> &val);
//插入区间 start -> end
void insert( input_iterator start, input_iterator end );
//直接插入一个 pair对组(key:value)
pair<iterator, bool> insert( const pair<KEY_TYPE,VALUE_TYPE> &val );
//插入的写法
//第一种插入方式
m.insert(pair<int, int>(1, 10));
//第二种插入方式
m.insert(make_pair(2, 20));
//第三种插入方式
m.insert(map<int, int>::value_type(3,30));
//第四种插入方式
m[4] = 40;
printMap(m);
**插入的时候需要注意:key 必须是唯一的,value 可以重复
删除操作:
void erase( iterator pos ); //删除pos 位置的 对组
void erase( iterator start, iterator end );//删除start -> end
size_type erase( const KEY_TYPE &key );//直接删除一个对组的值
查找操作:
find
语法:
iterator find( const KEY_TYPE &key );
find()函数返回一个迭代器指向键值为key的元素,如果没找到就返回指向map尾部的迭代器。
map 的操作例子:
//练习: 在map 容器中存入一个对组为 string(姓名),int(年龄) 的数据。
#include <iostream>
#include <map>
using namespace std;
int main()
{
//定义一个map 容器
map<string,int> a;
//插入到 map 容器中
a.insert(pair<string, int>("小明", 10));
a.insert(make_pair("小鹏",20));
a.insert(map<string, int>::value_type("小丽",30));
a["小美"] = 40;
//遍历map 容器
map<string,int>::iterator it = a.begin();
for(it;it!=a.end();it++)
{
cout << it->first << ":" << it->second << endl;
}
cout << "______________" << endl;
//删除一个map 中的一个对组
a.erase("小明");
it = a.begin();
for(it;it!=a.end();it++)
{
cout << it->first << ":" << it->second << endl;
}
cout << "______________" << endl;
//查找一个数据
map<string,int>::iterator fi = a.find("小美");
cout << fi->first << ":" << fi->second << endl;
}
STL相关资料:https://www.aliyundrive.com/s/bJfmmBWF7CS















 4541
4541











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











