






研究背景意义
FPGA由于其并行计算与高能效特点,用于CNN加速可以用较高的能效实现较低延迟提高性能;目前在FPGA上实现CNN加速器面临着许多问题:
- 需要进行并行架构探索,内存带宽优化,时序面积优化和软硬件接口开发,时间开销大;
- 针对问题1有些学者提出了自动编译器,虽然减少了设计时间,但是这些特定网络加速器应用于其他网络是都必须重新配置FPGA;并且当网络更新时也必须同步更新RTL代码和编译;
作者研究了通用的CNN加速器,采用FPGA overlay技术,FPGA硬件电路实现一旦固定不需要改变;操作者在上位机上完成网络的设计和训练,将最终的模型编译为指令输入到加速器中实现推理加速,避免了FPGA重配置和编译;
指令集
指令集架构

上图是OPU的指令架构;在OPU中,指令分为C-type和U-type两种指令类型;C-type表示了指令的具体功能,作者将CNN推理计算中所有必须的操作设计成C-type指令,具体如下:
- 内存读取;转换数据从外部存储器到板载存储器。接收到的数据将被重新组织并分发到三个 目标缓冲区,分别对应于特征映射(FM)、内核权重和指令 。
- 内存写入;将计算结果块发送回外部存储器。
- Data Fetch;执行从板载FM和内核缓冲区读取数据,然后将数据提供给PE阵列。它的工作模式可以通过在行和列地址计数器、读取步幅和数据重组模式上设置约束参数来灵活调整。
- Compute;一个PE计算两个长度为N的一维向量的内积,目前基于广泛使用的cnn架构的微架构实现将其设置为16(应该指的是一次并行输入16通道)。这充分保证了对不同网络的设计空间探索。根据参数的设置,可以总结出不同模式下的pe结果。
- 后处理;包括池化、激活、数据量化、中间结果相加和Residual操作。当触发后处理时,执行前面提到的几种操作的特定组合。
- 指令读取;从指令缓冲区中读取新的指令块,并将其定向到目标操作模块。
U-type指令提供C-type指令需要的参数,多个u型指令组合在一起,可以为一个c型操作更新完整的参数表。1条C-type和N条U-type指令构成一个指令单元,多个指令单元构成一个指令块,用指令最高位(32位)来指示指令块的结束。OPU以块为单位将指令分发给指令处理单元,再由指令处理单元将不同的操作指令分发给具体的操作模块。 每个C-type指令都映射到一个操作模块,指令对各个模块进行单独控制,大大简化了整个硬件控制框架,增强了体系结构对不同网络配置的适用性。
指令控制逻辑(没看懂)
通过指令出发条件(TCI)来控制指令执行。不同操作类型指令可以并行读取但并不立即执行,通过TCI来控制其触发条件。
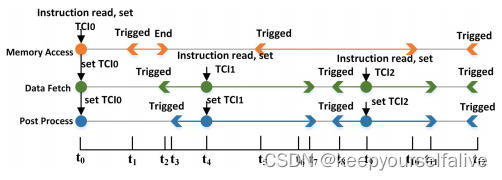
在读取第一条指令后,所有三个操作的初始TCI0都设置为0。在t1,内存访问被触发,然后执行t1−t2。数据提取在完成内存操作时触发,后处理在t3时触发。下一条指令读到更新TCI1用于数据获取和后处理,可以在t3和t7之间的任何时间点执行。此外,我们存储当前TCI,以避免在模块连续以一个模式操作时重复设置相同的条件(在时间t0和t5,内存访问由相同的TCI触发)。这使指令序列缩短了10倍以上。
推理计算加速
计算并行
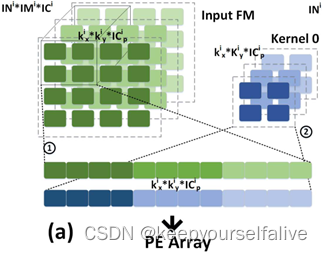
像素并行:卷积计算过程中,卷积核需要用K×K大小的窗口中多个权重值与输入特征图K×K大小的窗口进行乘法运算,多个乘法运算无数据依赖,可并行进行;缺点:单周期读地址不连续(行列方向上都需要读取数据)加大访存开销;无法适应不同Kernel尺寸,针对一种大小卷积核设计的像素并行操作无法适用于其它卷积核大小计算操作;

输入输出特征图并行:输入特征图单个通道需要与多个卷积核对应通道进行乘法运算,,输入特征图的多个通道需要与卷积核的多个通道进行乘累加运算,这些乘法运算无数据依赖,可以并行进行;优点:一次只读取1x1xn的数据,与卷积核大小解耦;读取地址连续的特征图数据,减小访存次数与能耗;本文采用输入输出特征图并行进行并行计算加速。
PE计算加速阵列
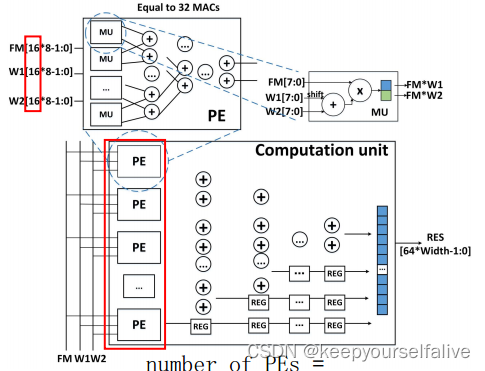
PE计算加速阵列:整个PE加速阵列由Tn个PE计算单元构成,而PE计算单元由Tm个DSP和一个加法树组成。Tn代表了输出通道并行度(图中大红框),Tm代表了输入通道并行度(图中小红框)。一个周期内Tm个通道的特征图和2个Tm通道的权重数据在一个PE单元内完成运算获得2×Tm个运算结果,并在各自的Tm个通道上完成累加,得到2个输出通道的特征图数据,Tn个PE计算单元可在一个时钟周期内输出为2×Tn个输出通道的特征图数据。这样相比于串行计算,速度提升了2*Tm*Tn倍。本文中,为了适应CNN中不同层的多种输入输出通道数量,设计了六种[Tm,Tn]对:[512,2],[256,4],[128,8],[64,16],[32,32],[16,64];Tm*Tn=1024为MACs总数保持不变。
数据加载策略
data fetch
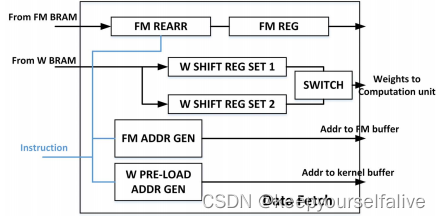
FM ADDR GEN:接受指令,产生读地址to FM buffer;FM REARR & FM REG:读出来的FM数据拷贝到这里,挑选当前计算块所需的数据,喂给计算单元; PRE-LOAD ADDR GEN:产生权重的地址;W SHIFT REG SET:利用移位寄存器,存储权重,因为权重需要32个时钟周期才能全部load完。
数据内存管理
特征图重排
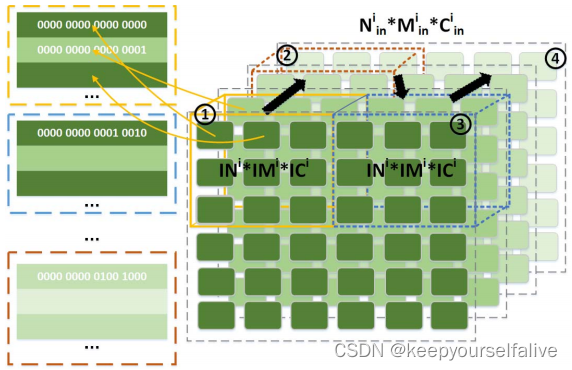
整读取连续地址空间数据比读取跳跃地址空间数据效率更高;片上存储资源有限,特征图读入片内需要分块,为了保证计算结果正确,还要对分块进行填充;特征图数据按照[分块,行,列,并行输入通道]优先级存储在片外存储器中;
权重重排(文章内没有)
按照[分块,行,列,并行输出通道(卷积核),并行输入通道]优先级存储在片外存储器中。
特殊结构加速
Inception Module
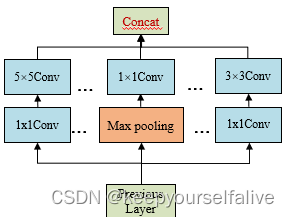
Inception Module:使用1×1卷积降低输入通道数减少参数量,再使用Concat合并输出通道;
通过将不同通道输出放在相邻地址实现Concat,省去计算操作开销;

Residual Module
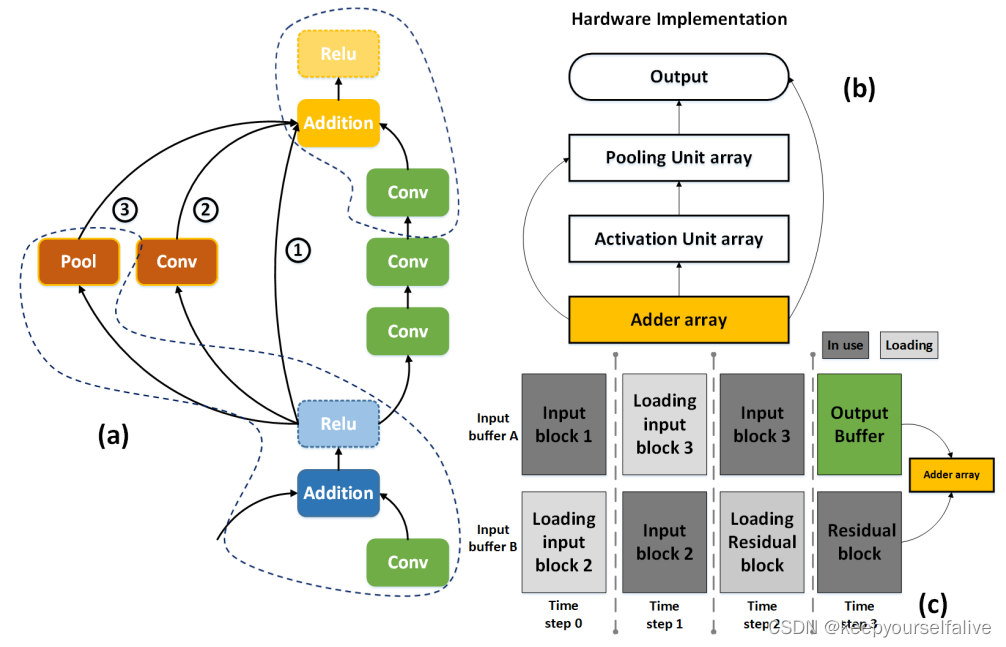
残差模块涉及大量矩阵逐元素加法,片外数据交互需求增加;文章内将残差计算嵌入到后处理流水线操作中,利用乒乓操作,在BufferA进行卷积操作时,BufferB加载残差边,抵消读取耗时。
编译优化
操作融合_P-fusion
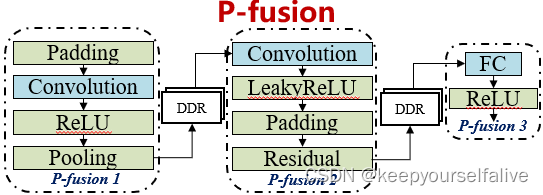
把卷积、全连接的层和池化、填充激活这些层融合成一个连续的块,与外部存储器的数据交互只发生在向量计算处,避免在卷积计算中间过程发生和外部存储器的数据交互;
操作融合_BN融合
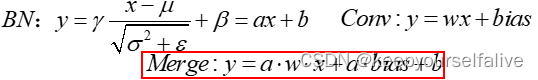 https://blog.csdn.net/qq_50465411/article/details/132024167?spm=1001.2014.3001.5502
https://blog.csdn.net/qq_50465411/article/details/132024167?spm=1001.2014.3001.5502
操作融合_输入共享
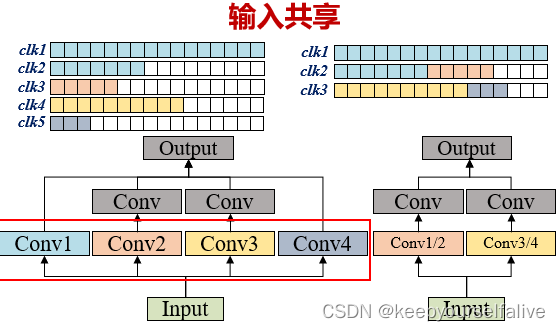
权重重排设计,对于一层特征图输入,由于采用了输出通道并行计算方式,一个特征图输入通道与多个卷积核通道并行计算,有的卷积核通道数很少,导致PE阵列没有填满,把不满足输入通道并行数量(Tm)的卷积核拼接在一起;
数据量化
不同权重、特征图层数据分布有差异,逐层确定量化方式。
第一层通道扩容
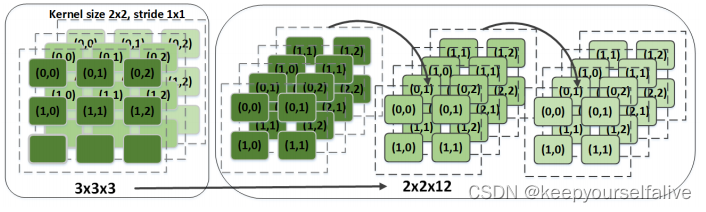
同输入共享原理,由于第一层输入图通道数很低(RGB图为3通道),所以将卷积核(?)进行重拍,根据卷积核滑窗的方式,将不同的滑窗当作不同的通道进行通道扩容。满足输入通道并行的计算需求。
特征图分块
以吞吐量为引导的分块方式;(没有考虑分块填充问题?)
单层分块计算延迟:
![]()
吞吐量:

最优化表达式:
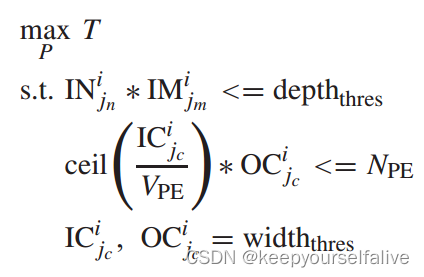















 2511
2511











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









