







最近做的研究需要用到文本的分词,而英文文本的分词方法和中文文本的分词方法是不一样的,英文文本分词有训练好的模型可以直接使用,例如nltk,但是在看网上的教程基本上没有比较完整的,所以这里整理了一下,希望对有需要的同学有一定的帮助,可以少走一些坑。
一、nltk为什么需要离线下载
通过实验发现,使用正常下载方式过程会非常非常慢,最关键的是最后会报错无法加载成功,即使换成了国内源也是一样的,无法成功。命令如下:
import nltk
nltk.download()
二、nltk离线下载及使用流程(亲试成功)
1、使用命令行安装nltk
为了提高下载速度,可以使用国内源下载,例如下面的代码使用了清华源,其它的可以参考博客
pip install nltk -i https://pypi.tuna.tsinghua.edu.cn/simple这个就是不使用国内源的,速度会慢很多
pip install nltk

2、在git上下载nltk_data
下载分支gh-pages-old
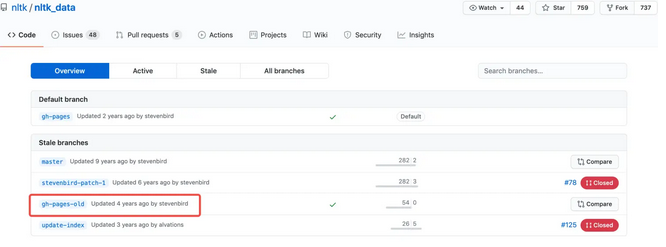
然后将文件夹解压,并重新命名为nltk_data
3、将nltk_data/packages中子目录,移动到nltk_data目录下
原始目录结构
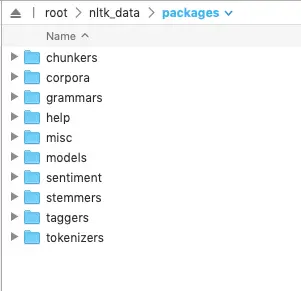
修改后的目录结构
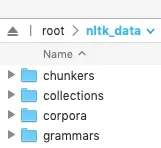
此时:nltk_data包含子目录chunkers, grammars, misc, sentiment, taggers, corpora, help, models, stemmers, tokenizers.
原文说明如下
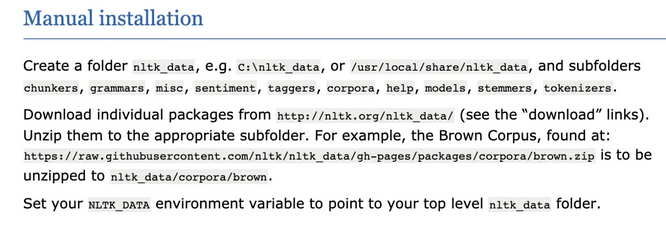
4、放入目录比如/root/nltk_data中
这里可以先随便放一个目录,如果后面报错了,再放到指定的目录,每个人电脑上的情况不太一样。如果有同学将文件下载在了windows上,可以借助工具将文件放到linux上,例如我使用的是xftp。免费的,非常方便。

5、配置环境变量
首先需要找到刚才nltk_data目录位置,不知道的小伙伴,可以先进入该目录,然后使用pwd命令查看
![]()
然后就是切换到root账户的家目录里去找到我们要修改的文件 .bashrc
cd ~编辑 .bashrc 文件
使用 gedit 或者直接使用 vi 进行编辑,gedit是可视化编辑,比较好操作
vi .bashrcgedit .bashrc
打开文件后,在文件最下面输入语句,$PATH: 后面的就是你要添加的环境变量,此处有大坑,切记,网上看到的 = 号两边是有空格的,我直接复制来用,执行到后面,就报 PATH 变更错误,一定一定一定不能有空格。注意格式,不对会报错的哦。
export PATH="/your/pwd/address/nltk_data:$PATH"以上保存退出后,执行以下语句生效并查看效果
source ~/.bashrc
echo $PATH以上命令能执行成功的话基本上就是安装成功了 但是路径可能不对,就是成功安装了,但是系统找不到,所以需要接下来的步骤
6、验证是否安装成功
新建一个文件py或者ipynb都可以,然后输入以下代码:
import nltk
nltk.data.find('.')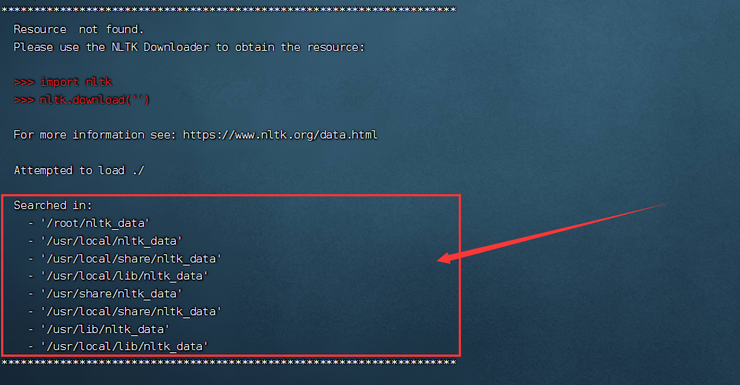 如果出现上述类似的内容,则需要将词库放到搜索路径,即上面红框任意一个路径都可以。复制文件可以使用mv 命令
如果出现上述类似的内容,则需要将词库放到搜索路径,即上面红框任意一个路径都可以。复制文件可以使用mv 命令
挪动文件之后需要重新配置环境变量,因为文件的路径已经变了,所以需要回到第五步再配置一遍。
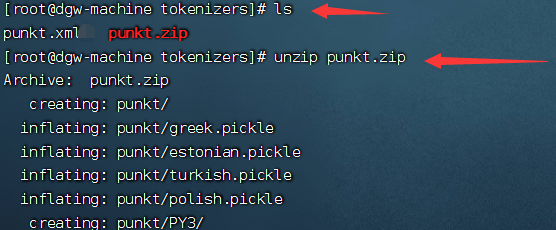
7、解压punkt
找到 nltk-data 中 punkt 所在目录:
![]()
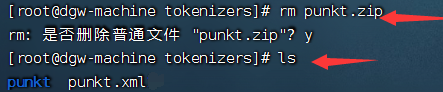
将punkt.zip压缩包进行加压,然后再将其删除即可!
8、nltk库测试
import nltk
# 下载词性标注器
#nltk.download('averaged_perceptron_tagger')
text = "I love natural language processing"
tokens = nltk.word_tokenize(text)
tags = nltk.pos_tag(tokens)
# 输出分类结果
for word, pos in tags:
print(word, pos)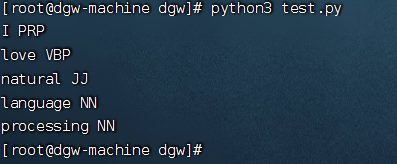
测试成功!
参考链接:

















 3406
3406

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









