






声明:本笔记来源于韦东山老师的《Arm架构与编程》
一. 嵌入式概念及硬件组成
1.1 嵌入式中的一些概念
1.1.1 MPU、MCU、SoC、Application Processors的概念
- CPU(Central Processing Unit):
中央处理器,在PC机它是一个独立的芯片。
在嵌入系统中,它是芯片里的一个单元,跟其他模块比如USB、UART、音频组成一个芯片。 - MPU(Mircro Processor Unit):
微处理器单元,其作用等同于在PC上使用的CPU,它也只仅仅是一个处理器,需要配合内存、Flash等外设才可以使用。
现在,除了个人电脑上的CPU,基本上找不到MPU了。并且我们一般不把电脑上的CPU当作MPU,毕竟它也是挺大的,并不“微小”。 - MCU(Micro Controller Unit):
微控制器单元,有时又称为单片机。
MCU内部集成了处理器和各类模块,比如USB控制器、UART控制器、内存、Flash等等。只需要外接少量的器件,就可以搭建一个电子系统。
C51芯片、STM32等芯片,都是MCU。
MCU芯片内部的内存或Flash,容量在几KB、几百KB、几MB的量级,一般不再需要外接内存或Flash。 - Application Processors:
手机中的主芯片跟MCU类似,也是集成了处理器和各类模块。但是它的性能已经极大提升,可以外接几GB的内存、几GB的Flash。
在手机中,这个主芯片一般用来处理显示、输入,运行用户的程序,所以称它为“Application Processors”。
“Application Processors”的概念可以扩展到其他场景,不再局限于手机。
跟MCU进行比较,Application Processors有以下不同:
a. 集成了更多的模块:
Application Processors内部集成了更多的模块,比如用于数据处理的DSP、用于图形显示的GPU,甚至有多个处理器。
这里又引入一个概念“片上系统”(SoC,System on Chip),SoC的本意是在一个芯片上就可以搭建完整的系统。
但是这个概念在日常使用中比较宽泛:MCU芯片也可以称为SoC,Application Processors也可以称为SoC,即使它们还必须外接内存/Flash等外设才可以运行。
在以前的文档中涉及SoC时,意指比较复杂的系统;这时候MCU不属于SoC,因为MCU比较简单。但是时代在发展,MCU也越来越复杂了,所以把MCU也当作SoC也是可以的。
b. 运行的操作系统不同:
MCU上一般不运行操作系统,或是运行一些资源耗费较小的小型实时操作系统(RTOS)。
MCU一般用来处理实时性要求高的事情,处理一些比较简单的事情。
Application Processors基本上都会运行比较复杂的操作系统(比如Linux),在操作系统上运行多个APP。
1.1.2 哈弗架构与冯诺依曼架构
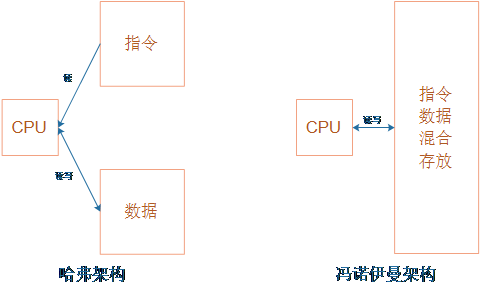
CPU架构可以分为哈弗架构与冯诺伊曼架构。
- 哈弗架构中指令与数据分开存放,CPU可以同时读入指令、读写数据。
- 冯诺伊曼架构中指令、数据混合存放,CPU依次读取指令、读写数据,不可同时操作指令和数据。
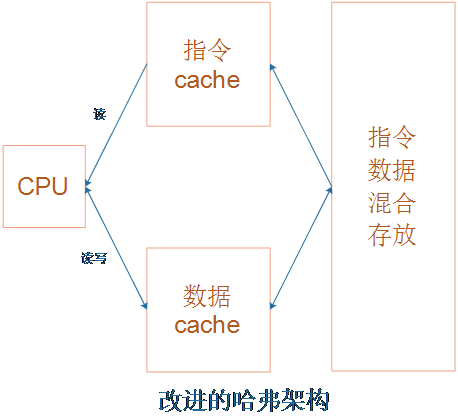
ARM公司的芯片,ARM7及之前的芯片是冯诺伊曼架构,ARM7之后使用“改进的哈弗架构”。
在“改进的哈弗架构”里,指令和数据在外部存储器中混合存放;CPU运行时,从指令cache中获得指令,从数据cache中读写数据。
1.1.3 指令集:CISC和RISC
CISC和RISC的区别
作者:gongxsh00
来源:CSDN
原文:CISC和RISC的区别_risc和cisc的区别-CSDN博客
CISC(Complex Instruction Set Computers,复杂指令集计算集)和RISC(Reduced Instruction Set Computers,精减指令集计算集)是两大类主流的CPU指令集类型。
其中CISC以Intel、AMD的X86 CPU为代表,而RISC以ARM、IBM Power为代表。开源的RISC-V也是RISC指令集。
RISC的设计初衷针对CISC CPU复杂的弊端,选择一些可以在单个CPU周期完成的指令,以降低CPU的复杂度,将复杂性交给编译器。
举一个例子:
下图是实现这样的乘法运算:a = a * b。它需要4个步骤:读出a的值、读出b的值、相乘、写结果到a。
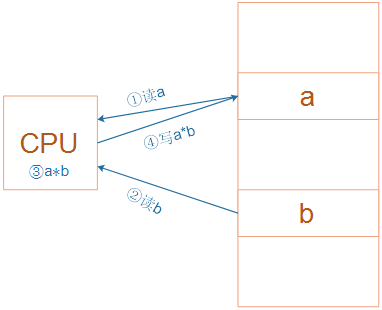
使用CISC提供的乘法指令,只需要一条指令即可完成这4步操作。当然,这一个指令需要多个CPU周期才可以完成。
而RISC不提供“一站式”的乘法指令,需调用四条单CPU周期指令完成两数相乘:
- 内存a加载到寄存器;
- 内存b加载到寄存器;
- 两个寄存器中数相乘;
- 寄存器结果存入内存a
按照此思路,早期的设计出的RISC指令集,指令数是比CISC少些。后来,很多RISC的指令集中指令数反超了CISC。因此,应该根据指令的复杂度而非数量来区分两种指令集。
当然,CISC也是要通过操作内存、寄存器、运算器来完成复杂指令的。它在实现时,是将复杂指令转换成了一个微程序,微程序在制造CPU时就已存储于微服务存储器。一个微程序包含若干条微指令(也称微码),执行复杂指令时,实际上是在执行一个微程序。这也带来两种指令集的一个差别,微程序的执行是不可被打断的,而RISC指令之间可以被打断,所以理论上RISC可更快响应中断。
在此,总结一下CISC和RISC的主要区别:
| 区别 | CISC | RISC |
| 指令能力 |
|
|
| 寻址方式 | 支持多种寻址方式 | 支持的寻址方式少 |
| 实现方式 | 通过微程序控制技术实现 | 增加了通用寄存器,硬布线逻辑控制为主,采用流水线方式执行。 |
| 研发周期 | 研制周期长 | 硬件简单,需要优化编译器 |
ARM公司的芯片都使用RISC指令集,对内存只有load/store操作,数据的处理是在CPU寄存器上进行。
1.2 嵌入式系统硬件结构与启动
1.2.1 XIP的概念
XIP: eXecute In Place, 本地执行。可以不用将代码拷贝到内存,而直接在代码的存储空间运行。
1.2.2 嵌入式系统硬件组成
一句话引出整个嵌入式系统: 支持多种设备启动
系统支持 SPI FLASH启动,这意味着可以运行SPI FLASH上的代码,但是SPI FLASH不是XIP设备, CPU无法直接执行里面的代码,问:
- CPU如何执行SPI FLASH上的代码?
- 一上电, CPU执行的第1个程序、第1条指令在哪里?
ARM板子支持多种启动方式:XIP设备启动、非XIP设备启动等等。比如:Nor Flash、SD卡、SPI Flash, 甚至支持UART、USB、网卡启动。这些设备中,很多都不是XIP设备
既然CPU无法直接运行非XIP设备的代码,为何可以从非XIP设备启动
上电后,CPU运行的第1条指令、第1个程序,位于片内ROM中,它是XIP设备。这个程序会执行必要的初始化:
- 比如设置时钟、设置内存;
- 再从"非XIP设备"中把程序读到内存;
- 最后启动这段程序。
片上系统(System on chip)框图:
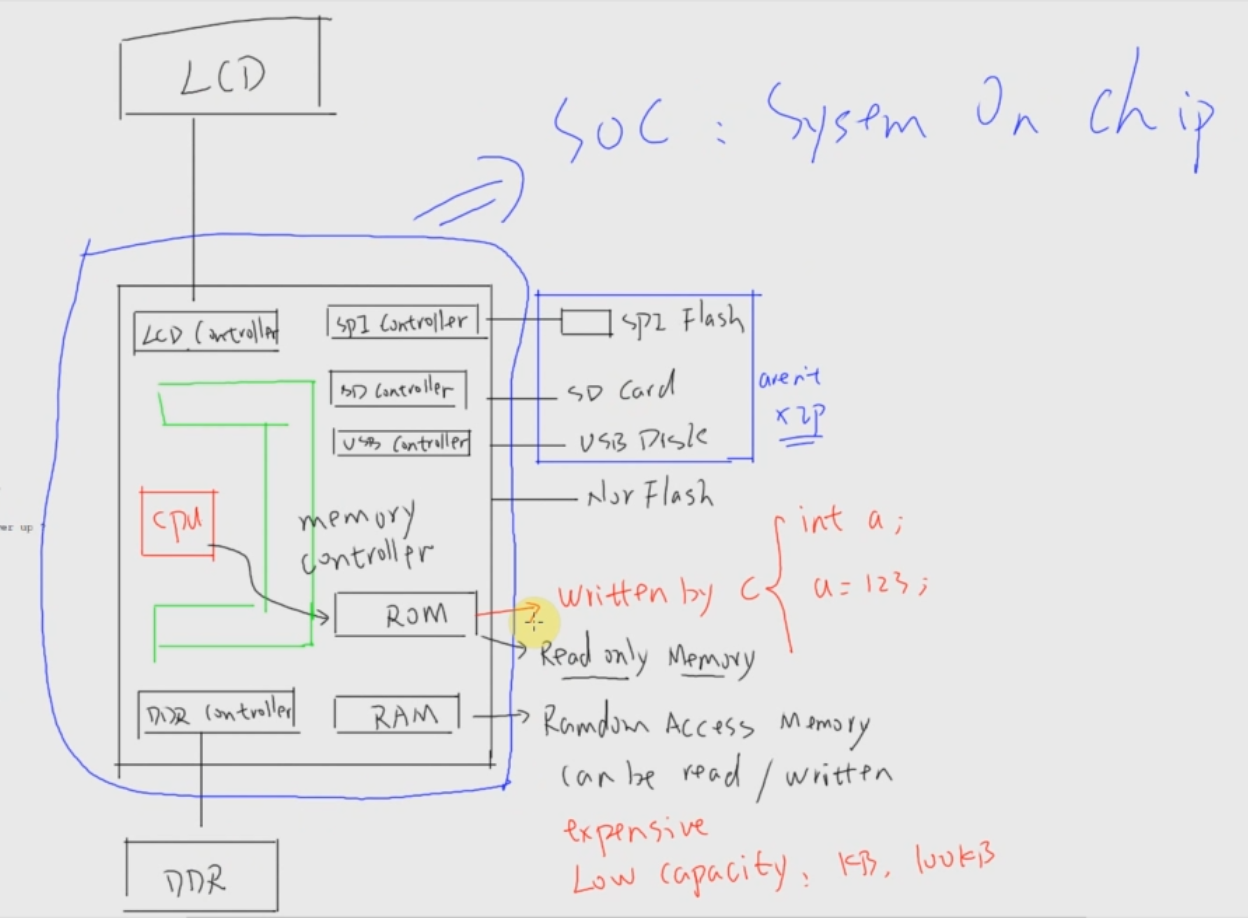
跟PC的类比:
CPU -----> 单独的芯片
启动设备 -----> BIOS芯片
DDR -----> 单独的可拔插式模块
存储设备 -----> SATA硬盘,可拔插
usb controller ...
1.2.3 嵌入式系统启动流程概述
结论:主芯片内部有ROM,ROM程序协助从非XIP设备启动。
1). ROM程序的主要任务
1. 初始化硬件
- 初始化时钟,提高CPU和外设的速度。
- 初始化内存:DDR需要初始化才能使用。
- 初始化其他硬件,如看门狗、SD卡等
2.从外设复制程序到内存
- 支持多种启动方式:SD卡、SPI FLASH、USB DISK等。
- 选择启动设备的方式:
- 通过跳线选择某个设备。
- 通过跳线选择一个设备列表,按列表顺序逐个尝试。
- 按固定顺序逐个尝试,不提供客户选择。
- 程序复制到内存的位置和长度:
- 程序包含头部信息,指定内存地址和长度。
- 程序被复制到内存固定位置,长度也固定。
- 程序在SD卡上的存储方式:
- 原始二进制(raw bin)。
- 作为文件保存在分区中。
2). 启动流程示例:以SD卡启动为例
1. 硬件初始化
- 初始化时钟系统,确保CPU和外设运行在合适的速度。
- 初始化DDR内存,使其可被使用。
- 初始化SD卡,确保数据传输的稳定性。
2. 选择启动设备
- 通过硬件跳线或预设顺序选择SD卡作为启动设备。
3.读取程序头部信息
- 从SD卡读取程序头部信息,获取程序的内存地址和长度。
4. 复制程序到内存
- 将SD卡上的程序按照头部信息指定的地址和长度复制到内存中。
5. 执行程序
- CPU从内存中读取并执行程序,完成启动过程。
二. 第一个裸机程序(点灯)
2.1 LED及其相关的硬件知识
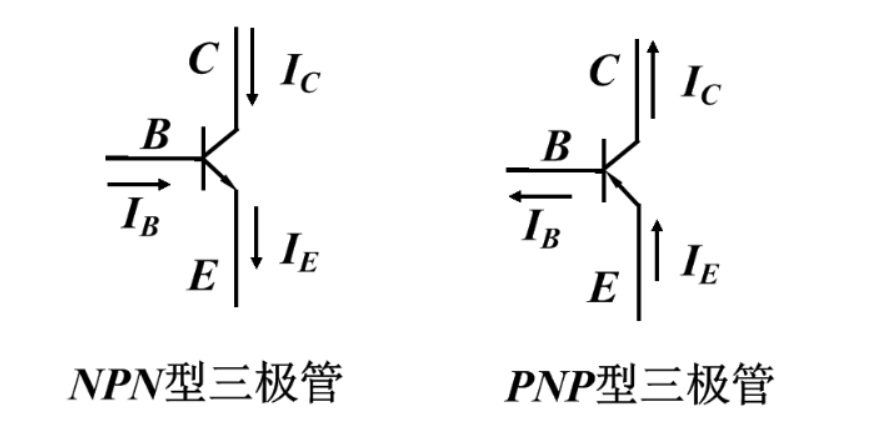
2.1.1 三极管的分类及其作用
三极管的分类:NPN型、PNP型。
三极管的三极:B(基极)、C(集电极)、E(发射极)。
导通条件:NPN(N管)基极给高电平,管子导通。PNP(P管)基极给低电平,管子导通。
电流流向参考以下图片。
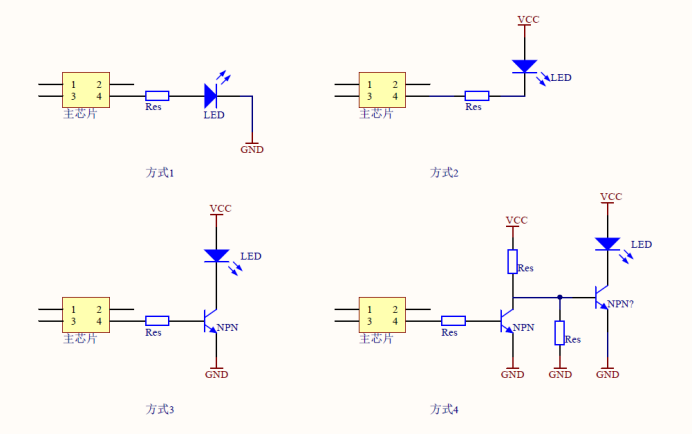
2.1.2 LED的驱动方式
常见的有四种。
- 方式1:使用引脚输出3.3V点亮LED,输出0V熄灭LED。
- 方式2:使用引脚拉低到0V点亮LED,输出3.3V熄灭LED。
有的芯片为了省电等原因,其引脚驱动能力不足,这时可以使用三极管驱动。
- 方式3:使用引脚输出1.2V点亮LED,输出0V熄灭LED。
- 方式4:使用引脚输出0V点亮LED,输出1.2V熄灭LED。
2.2 GPIO引脚操作方法概述
GPIO: General-purpose input/output(通用输入输出口)
2.2.1 GPIO模块一般结构
多组GPIO:每组包含多个GPIO。
使能:电源/时钟。
模式(Mode):引脚可用于GPIO或其他功能。
方向:引脚Mode设置为GPIO时,可以继续设置它是输出引脚,还是输入引脚。
数值:
- 对于输出引脚,可以设置寄存器让它输出高、低电平;
- 对于输入引脚,可以读取寄存器得到引脚的当前电平。
2.2.2 GPIO寄存器操作
1). GPIO寄存器配置步骤
芯片手册:介绍power/clock,可以设置对应寄存器使能某个GPIO模块(Module)。
引脚功能选择:一个引脚可以用于GPIO、串口、USB或其他功能,有对应的寄存器来选择引脚的功能。
方向寄存器:对于已经设置为GPIO功能的引脚,有方向寄存器用来设置它的方向:输出、输入。
数据寄存器:对于已经设置为GPIO功能的引脚,有数据寄存器用来写、读引脚电平状态。
2). GPIO寄存器的2种操作方法
原则:不能影响到其他位。
- 直接读写
//设置bit n:
val = data_reg;
val = val | (1<<n);
data_reg = val;
//清除bit n:
val = data_reg;
val = val & ~(1<<n);
data_reg = val;- set-and-clear protocol
//set_reg, clr_reg, data_reg:三个寄存器对应的是同一个物理寄存器。
//设置bit n:
set_reg = (1<<n);
//清除bit n:
clr_reg = (1<<n);2.3 基于STM32F103的LED操作方法
1. 首先查看原理图
找到你想要点亮的LED对应的GPIO口,以下图的RED LED为例:
可以看到,该 LED 连接到 PB0

2. 使能GPIO时钟
同样的,以上图的 GPIOB 为例子,在芯片手册中找到对应的寄存器 使能 GPIOB 这一组 GPIO 口:

3. 将 GPIOB_0 设置为GPIO,且用作输出
在数据手册中找到对应的 GPIOx_CRL 寄存器,该寄存器由两位控制GPIO口的作用:
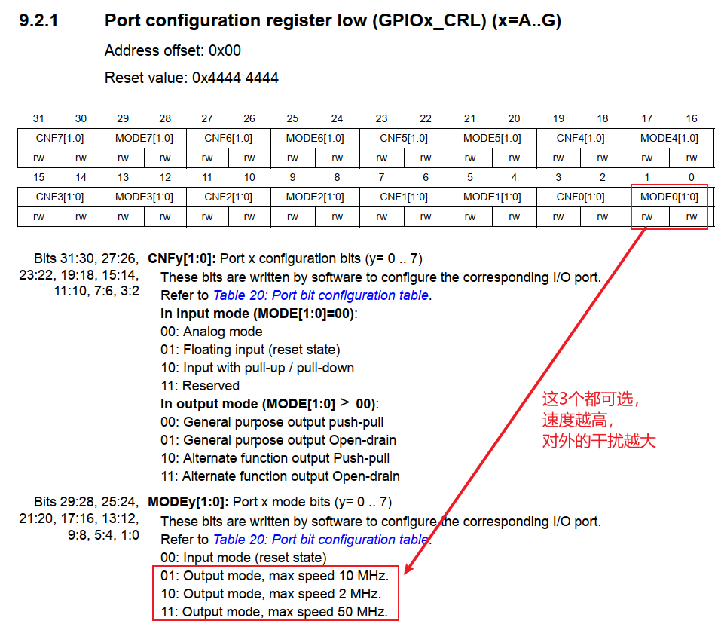
4. 设置对应端口的输出电平
分为两种方法:
a. 直接操作ODR寄存器,将对应的位写入 1 或 0(低效)
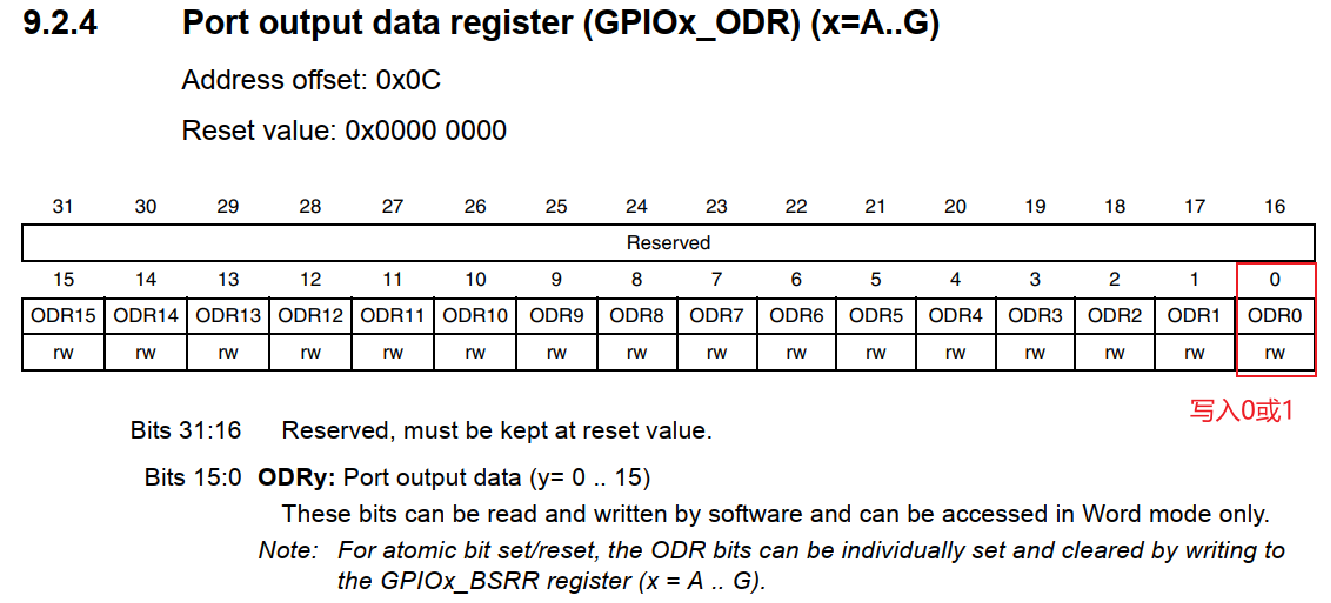
b. 操作BSRR寄存器,只需要写入一次即可,只有对应的位为 1 才会生效:BR对应位置写 1 ,则 ODR 对应位置会被清 0 ;BS对应位置写 1,则 ODR 对应位置会被置 1,这是由内部硬件电路实现的 (高效)

2.4 基于STM32F103的LED编程
2.4.1 如何访问寄存器?
用指针:
int a;
unsigned int *p = &a; // p等于“a的地址”
*p = val; // 写这个地址,就是写a
val = *p; // 读这个地址,就是读a
unsigned int *p = 0x40010800; // p等于某个寄存器的地址
*p = val; // 写这个地址,也就是写这个寄存器
Val = *p; // 读寄存器2.4.2 main函数编写
// RCC_APB2ENR寄存器地址为 RCC 基地址 + 偏移量(offset)
// CRL,ODR 寄存器同理
#define RCC_APB2ENR (0x40021000 + 0x18)
#define GPIO_BASE (0x40010C00)
#define GPIOB_CRL (GPIO_BASE + 0)
#define GPIOB_ODR (GPIO_BSE + 0x0c)
// 模拟延迟
void delay(volatile int i)
{
while(i--);
}
int main()
{
volatile unsigned int *pRccApb2Enr;
volatile unsigned int *pGpiobCrl;
volatile unsigned int *pGpioOdr;
pRccApb2Enr = (unsigned int *)RCC_APB2ENR;
pGpiobCrl = (unsigned int *)GPIOB_CRL;
pGpioOdr = (unsigned int *)GPIOB_ODR;
/*
1.使能 GPIOB 时钟,从 2.3 一节第 2 步可以看出:
APB2ENR[8:2] 是 GPIO[G:A] 的时钟控制位
对应的将 APB2ENR[3] 写 1 即可打开 GPIOB 时钟
*/
*pRccApb2Enr |= (1 << 3);
/*
2.设置 GPIO 为输出功能
同理,根据 2.3 一节第 3 步骤可以得到:
*/
*pGpiobCrl |= (1 << 0); // 设置 GPIOB_0 为输出
while(1)
{
*pGpiobOdr |= (1 << 0); // 输出高电平
delay(100000);
*pGpiobOdr &= ~(1 << 0); // 输出低电平
}
}2.4.3 启动文件 start.s 编写
PRESERVE8 ;使用 8 字节对齐
THUMB ;使用 THUMB 指令集
AREA RESET, DATA, READONLY ;一段只读属性的数据段
_Vectors DCD 0;
DCD Reset_Handler ;中断向量表
AREA |.text|, CODE, READONLY ;一段只读的代码段
Reset_Handler PROC
IMPORT main ;导入外部函数 main
LDR SP, =0x20000000+0x100 ;设置栈
BL main
ENDP ;结束代码段
END ;汇编文件结束语句注:根据后续学习完善 start.s
三. ARM架构
3.1 地址空间
3.1.1 ARM CPU
ARM CPU 只需要向 Memory Controller 发送地址信息,Memory Controller 就会根据地址选择不同的设备,且不区分内存和 IO 设备,如下图所示:

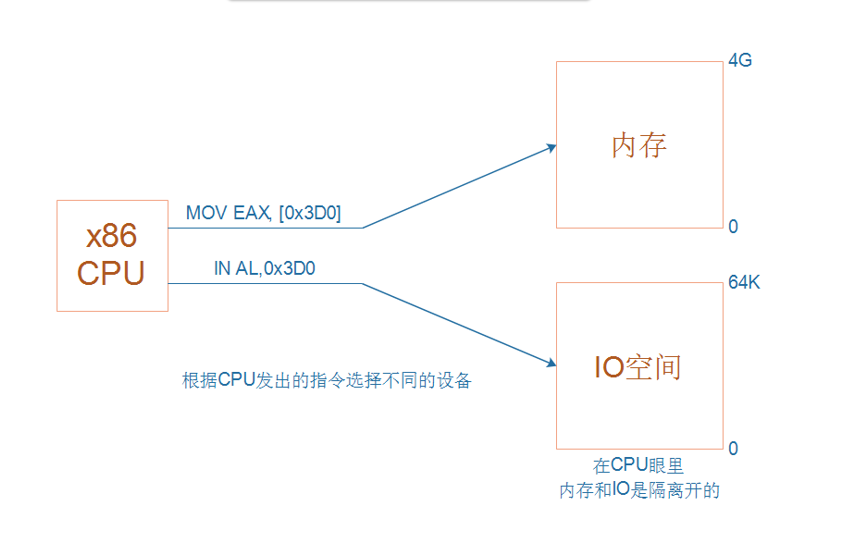
3.1.2 x86 CPU
x86 CPU 则需要区分内存和 IO 设备,需要用不同指令访问这俩者的地址空间,如下图所示:
3.2 CISC 与 RISC
参考 1.1.3 小节,不再赘述。
3.3 ARM内部寄存器
根据上述介绍,我们知道 ARM 架构使用的指令集是 RISC 指令集,而 RISC 对内存只有load/store操作,数据的运算都是在CPU内部实现。
那么,在 CPU 中进行数据运算时,数据储存在哪呢?
答:储存在 ARM CPU 内部的寄存器中。
3.3.1 CPU 内部的寄存器
无论是cortex-M3/M4,还是cortex-A7,CPU内部都有R0、R1、……、R15寄存器;它们可以用来“暂存”数据。
对于R13、R14、R15,还另有用途:
- R13:别名SP(Stack Pointer),栈指针
- R14:别名LR(Link Register),用来保存返回地址
- R15:别名PC(Program Counter),程序计数器,表示当前指令地址,写入新值即可跳转
另外,还有一个特殊的寄存器 PSR(Program Stauts Register),即程序状态寄存器,此寄存器在 cortex-M3/M4 与 cortex-A7 稍有区别,接下来两小节将介绍。
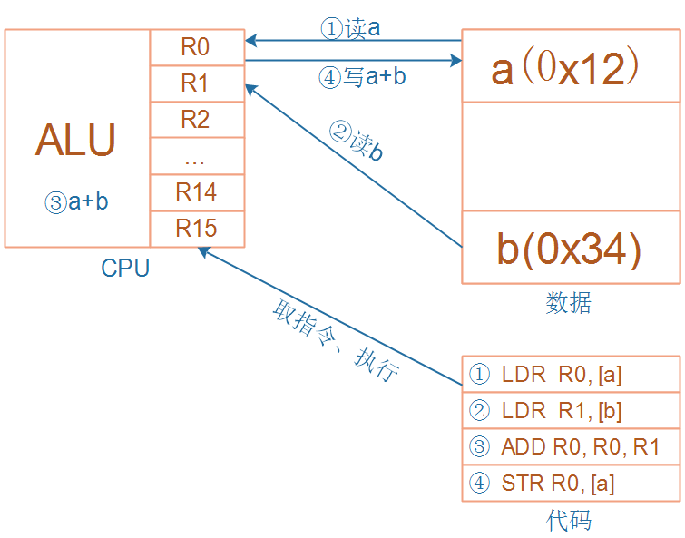
上图,演示了在进行 a+b 运算的整个过程,以及所使用的寄存器。
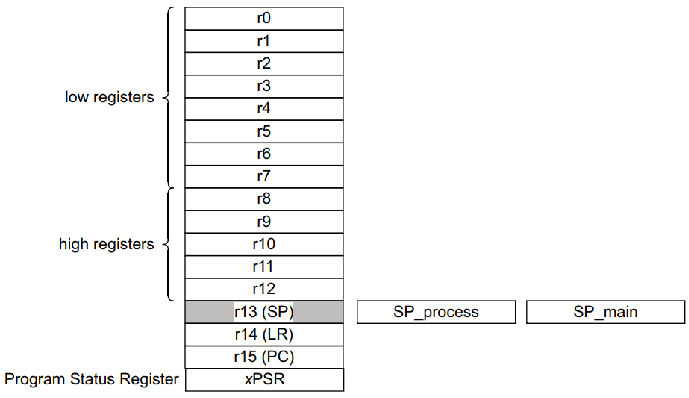
3.3.2 Cotex-M3/M4/A7 CPU内部寄存器
1). Cotex-M3/M4 内部寄存器图示:
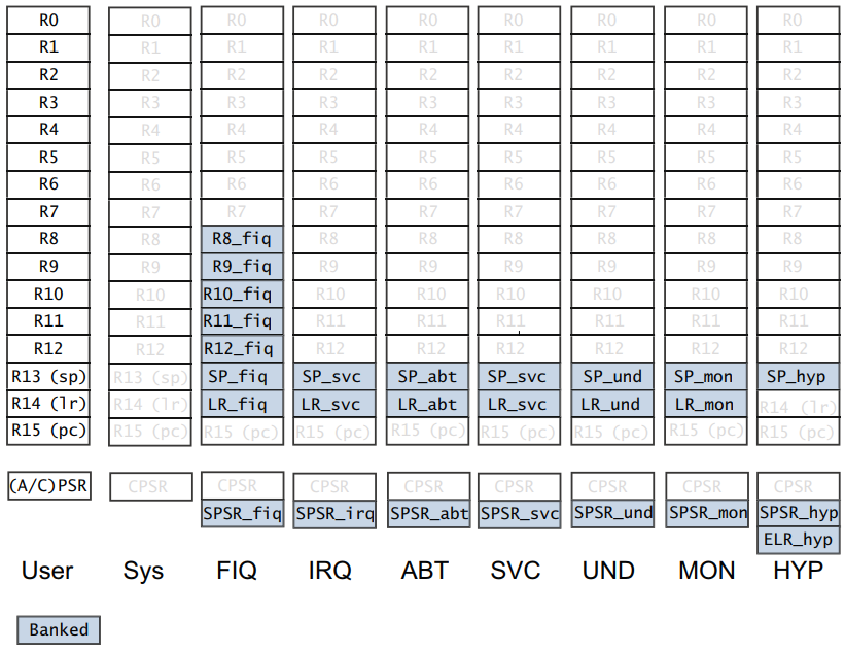
2). Cotex-A7 内部寄存器图示:
因为,A7 支持模式切换,所以对应的几种模式都有自己特殊的寄存器(图中用阴影部分标识),后续学习后会详细介绍。
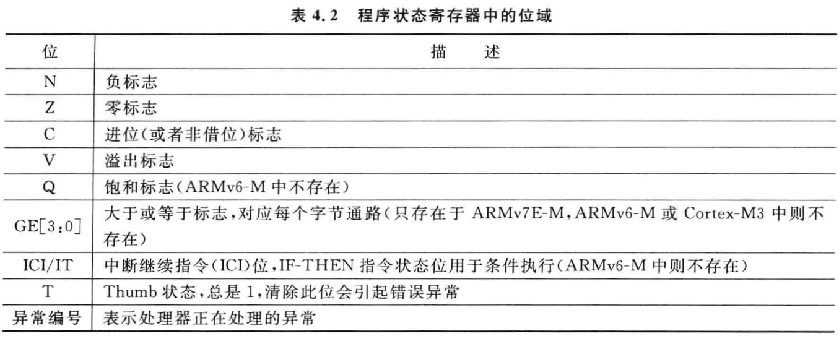
3.3.3 PSR(Program Stauts Register),程序状态寄存器
问:当我们在程序中比较两个数时,结果保存在哪?
答:对于 M3/M4 架构与 A7 架构的 CPU 来说稍微有些不同:
- M3/M4 保存在 APSR 中;
- A7 保存在 CPSR 中。
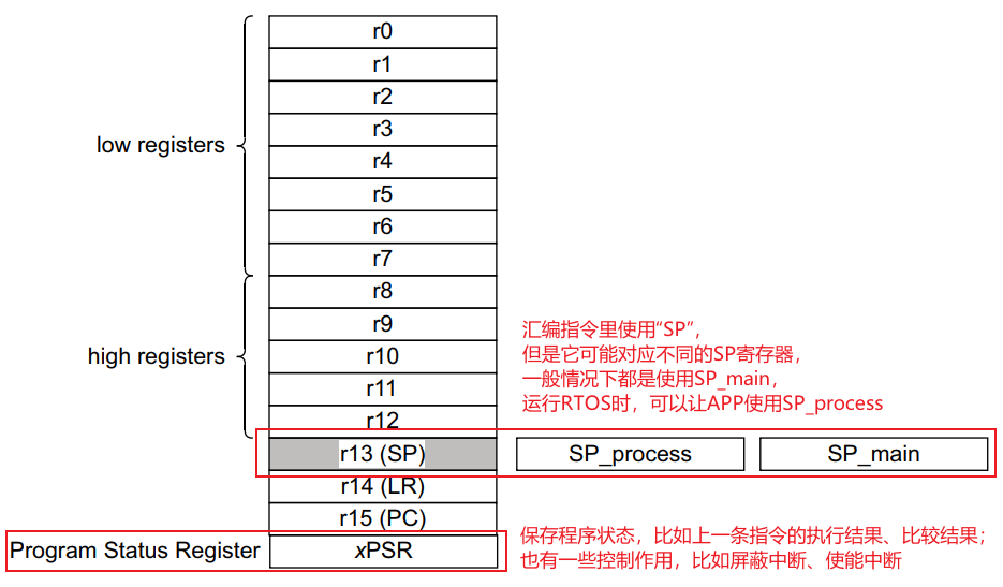
1) Cotex-M3/M4 的 PSR
对于cortex-M3/M4来说,xPSR实际上对应3个寄存器:
- APSR:Application PSR,应用PSR
- IPSR:Interrupt PSR,中断PSR
- EPSR:Exectution PSR,执行PSR
这3个寄存器的含义如下图所示:
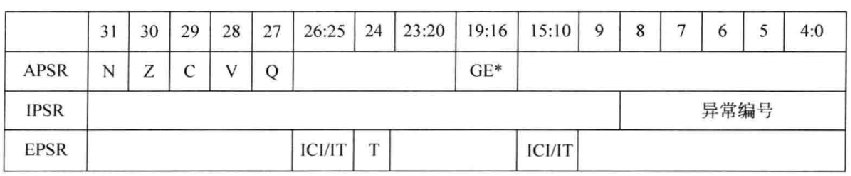
这3个寄存器,可以单独访问:
MRS R0, APSR ;读APSR
MRS R0, IPSR ;读IPSR
MSR APSR, R0 ;写APSR这3个寄存器,也可以一次性访问:
MRS R0, PSR ; 读组合程序状态
MSR PSR, R0 ; 写组合程序状态所谓组合程序状态,如下图所示:

2). Cotex-A7 的 PSR
A7只有一个 Current Program Status Register(当前程序状态寄存器),即 CPSR:


3.4 ARM汇编
3.4.1 ARM汇编概述
1). ARM 指令集与 Thumb 指令集
一开始,ARM公司发布两类指令集:
- ARM指令集,这是32位的,每条指令占据32位,高效,但是太占空间
- Thumb指令集,这是16位的,每条指令占据16位,节省空间
要节省空间时用Thumb指令,要效率时用ARM指令。
2).指令集的区分
一个CPU既可以运行Thumb指令,也能运行ARM指令。
怎么区分当前指令是Thumb还是ARM指令呢?
程序状态寄存器中有一位,名为“T”,它等于1时表示当前运行的是Thumb指令。
3). 调用 Thumb 和 ARM 函数
假设函数A是使用Thumb指令写的,函数B是使用ARM指令写的,怎么调用A/B?
可以通过向程序计数器(Program Counter, PC)写入函数A或B的地址来调用它们。但是,如何让CPU在执行函数A时进入Thumb状态,在执行函数B时进入ARM状态呢?
可以通过以下方式操作:
- 调用函数A时,让PC寄存器的 BIT0 等于1,即:
PC = 函数A地址 + (1 << 0); - 调用函数B时,让PC寄存器的 BIT0 等于0,即:
PC = 函数B地址。
这种方法虽然可行,但操作较为繁琐。
所以,ARM公司推出了 Unified Assembly LanguageUAL,统一汇编语言
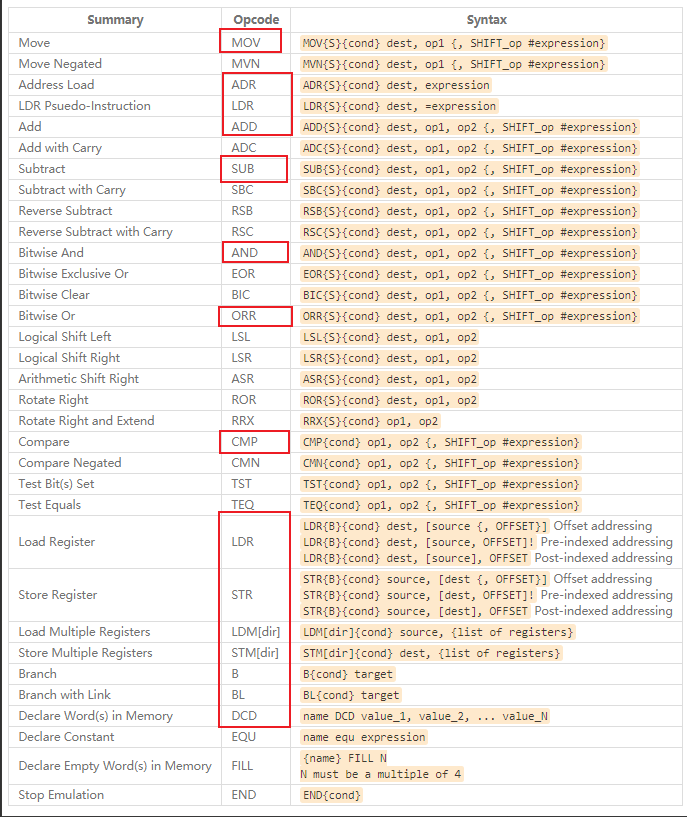
4). Thumb2 指令集
它支持16位指令、32位指令混合编程。
我们使用 Thumb2 指令集的时候不需要区分 指令集,只需要如下图框选所示的几条汇编指令:
3.4.2 汇编指令格式
汇编指令可以分为几大类:数据处理、内存访问、跳转、饱和运算、其他指令;
以“数据处理”指令为例,UAL汇编格式为:
![]()
- Operation表示各类汇编指令,比如ADD、MOV;
- cond表示conditon,即该指令执行的条件;
- S表示该指令执行后,会去修改程序状态寄存器;
- Rd为目的寄存器,用来存储运算的结果;
- Rn、Operand2是两个源操作数
3.4.3 各类汇编指令简介
1). 数据处理指令简介
![]()
- Operation表示各类汇编指令,比如ADD、MOV;如下图:
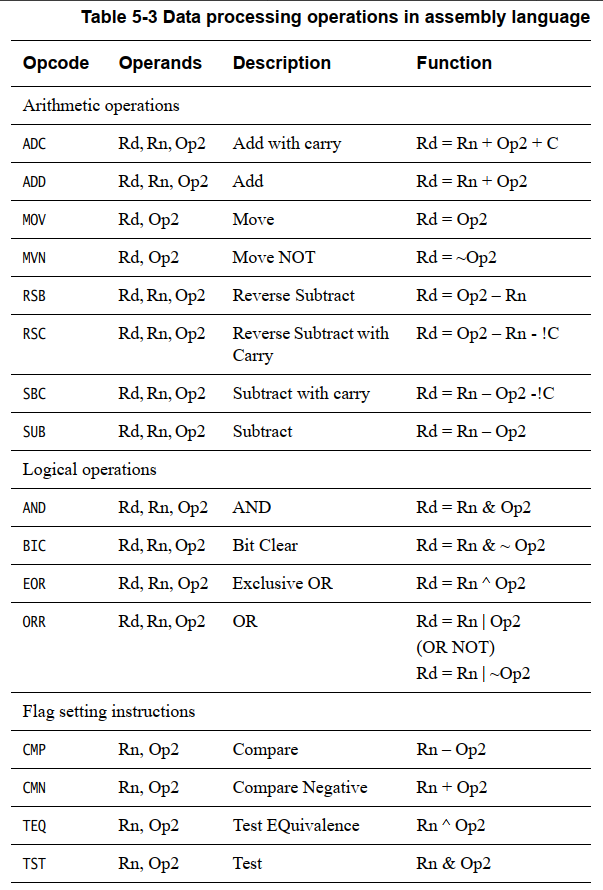
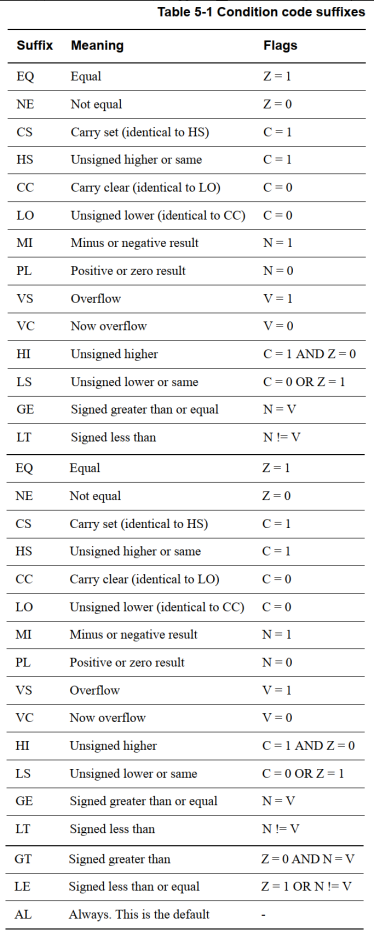
- cond 有多种取值,如下图:
2). 内存访问指令简介
其中:{T} 代表使用 用户模式 访问寄存器
- LDR:Load Register;

- STR:Store Register;

- LDM:Load Multiple Register;

- STM:Store Multiple Register。
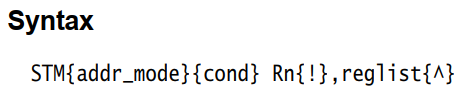
addr_mode:
- IA - Increment After, 每次传输后才增加Rn的值(默认,可省)
- IB - Increment Before, 每次传输前就增加Rn的值(ARM指令才能用)
- DA – Decrement After, 每次传输后才减小Rn的值(ARM指令才能用)
- DB – Decrement Before, 每次传输前就减小Rn的值
! : 表示修改后的Rn值会写入Rn寄存器, 如果没有"!", 指令执行完后Rn恢复/保持原值
^ : 会影响CPSR, 在讲异常时再细讲
3). 分支跳转指令

3.4.4 立即数
假设这样一条指令: MOV R0, #VAL
意图是把VAL这个值存入R0寄存器。
问:VAL可以是任意值吗?
答:不可以,必须是立即数。
问:为什么?
答:假设VAL可以是任意数,”MOV R0, #VAL”本身是16位或32位,哪来的空间保存任意数值的VAL?
所以,VAL必须符合某些规定。

3.4.5 伪指令
1). LDR伪指令
去判断一个VAL是否立即数,麻烦!
并且我就是想把任意数值赋给R0,怎么办?
可以使用伪指令:
LDR R0, =VAL“伪指令”,就是假的、不存在的指令。注意LDR作为“伪指令”时,指令中有一个“=”,否则它就是真实的LDR(load regisgter)指令了。
编译器会根据 VAL 的值来决定如何替换这个伪指令:
如果VAL是立即数:编译器会将其替换为MOV指令,直接将值加载到寄存器。
LDR R0, =0x12 ; 立即数替换为:
MOV R0, #0x12如果VAL不是立即数:编译器会将其替换为通过内存访问的LDR指令。制
LDR R0, =0x12345678 ; 不是立即数替换为:
LDR R0, [PC, #offset] ; 使用Load Register读内存指令读出值其中offset是链接程序时确定的,编译器会在程序某个地方保存这个值。
Label
DCD 0x12345678 ; 编译器在程序某个地方保存有这个值2). ADR 伪指令
示例:
ADR R0, Loop
Loop
ADD R0, R0, #1它是“伪指令”,会被转换成某条真实的指令,
比如:
ADD R0, PC, #val ; val在链接时确定
Loop
ADD R0, R0, #1四. C 语言与汇编深入分析
4.1 汇编_反汇编_机器码
4.1.1 程序处理的四个步骤
第一个点灯程序涉及两个文件:
- Start.s (启动文件)
- main.c (c 源码文件)
他们的处理过程如下:

我们想深入理解 ARM架构,想深入理解汇编与 C,想深入理解栈的作用,想深入理解 C 语言的实质,就必须把最终生成的可执行程序,反汇编之后,阅读得到的汇编代码。
“汇编”、“反汇编”的概念:
- 汇编
汇编文件转换为目标文件(里面是机器码)。 - 反汇编
可执行文件(目标文件,里面是机器码),转换为汇编文件。
4.1.2 KEIL 下如何反编译
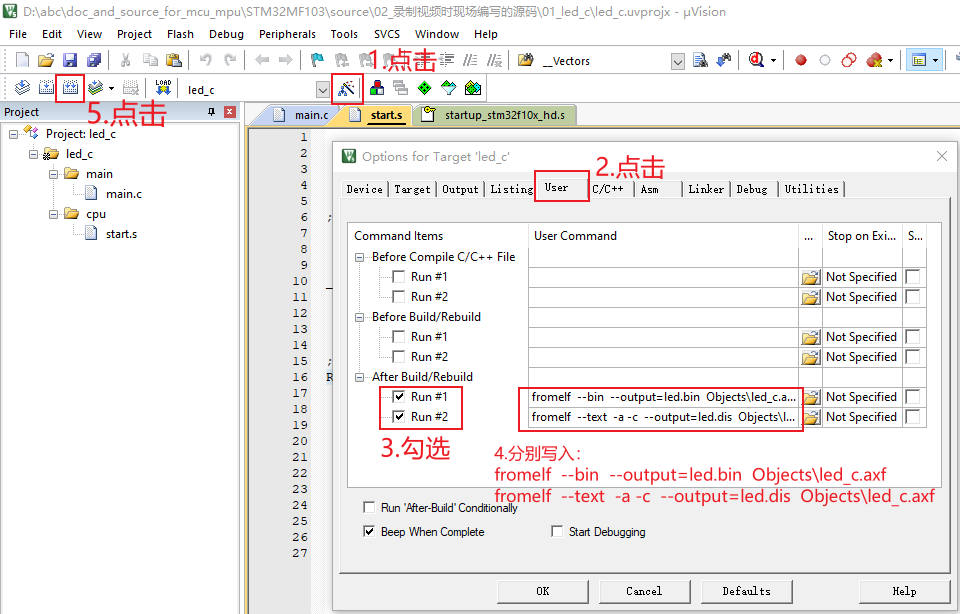
在 KEIL 的 User 选项中,如下图添加这两项:
fromelf --bin --output=led.bin Objects\led_c.axf
fromelf --text -a -c --output=led.dis Objects\led_c.axf然后重新编译,即可得到二进制文件 led.bin (以后会分析)、反汇编文件 led.dis。
如下图操作:
4.1.3 GCC 下反汇编
使用GCC工具链编译程序时,在Makefile中有这一句:
$(OBJDUMP) -D -m arm led.elf > led.dis # OBJDUMP = arm-linux-gnueabihf-objdump它就是把可执行程序 led.elf,反汇编,得到 led.dis。
4.1.4 机器码与汇编
前面介绍过伪指令,伪指令是实际不存在的ARM命令,编译器在编译时转换成存在的ARM指令。
我们代码中的ldr r1, =0x????????这条伪指令的真实指令是什么呢?
对于我们使用的2款板子,汇编代码如下(如果你的板子不是这2款之一,请灵活变通,知识是一样的):
LDR SP, =(0x20000000+0x10000) // STM32F103
ldr sp, =(0x80000000+0x100000) // IMX6ULL1). STM32F103 反汇编
我们摘取前面一小段,第一列是地址,第二列是机器码,第三列是汇编:
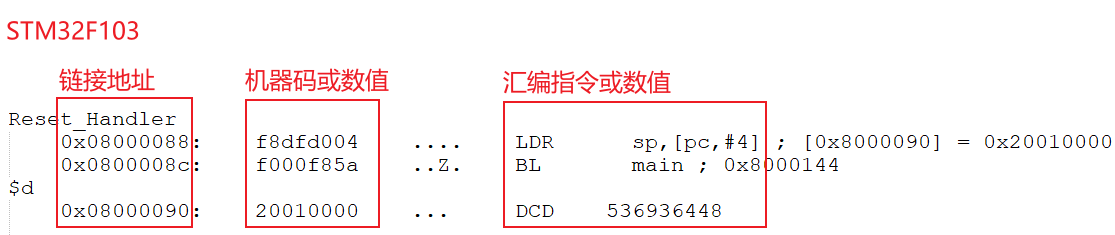
2). IMX6ULL 反汇编

为什么一样的指令,在两块板子上所使用的机器码不同呢?
因为 STM32F103 是使用的是 Thumb/Thumb2 指令集
而 IMX6ULL 是使用的 ARM 指令集
3). Thumb/Thumb2 指令集
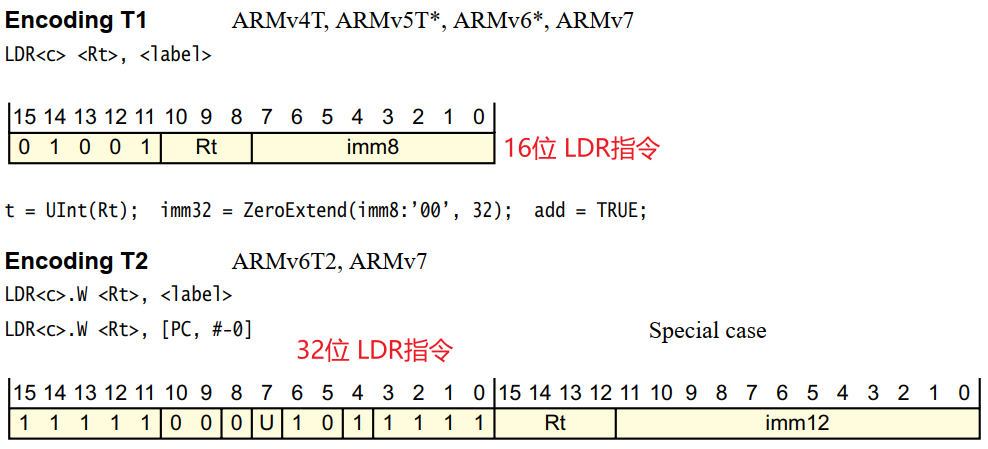
4). ARM 指令集

5). PC 指令的值
结论:PC=当前指令 +4 或 8
为什么?
- CORTEX M3/M4
使用Thumb2指令集,一条指令是16位或32位。 - CORTEX A7默认使用ARM指令集,一条指令是32位的。
- 流水线ARM指令采用流水线机制:
- 当前执行地址A的指令,
- 同时已经在对下一条指令进行译码
- 同时已经在读取下下一条指令:PC = A + 4 (Thumb/Thumb2指令集)、PC = A + 8 (ARM指令集)
4.2 C 语言和汇编分析
4.2.1 汇编如何调用 C 函数
1). 函数不需要参数调用方法
BL main2). 函数需要参数调用方法
在 ARM 中有个 ATPCS 规则 (ARM-THUMB procedure call standard(ARM-Thumb过程调用标准)
它约定了 R0-R15 寄存器的用途
- r0-r3:调用者和被调用者之间传参数
- r4-r11: 函数可能被使用,所以在函数的入口保存它们,在函数的出口恢复它们。
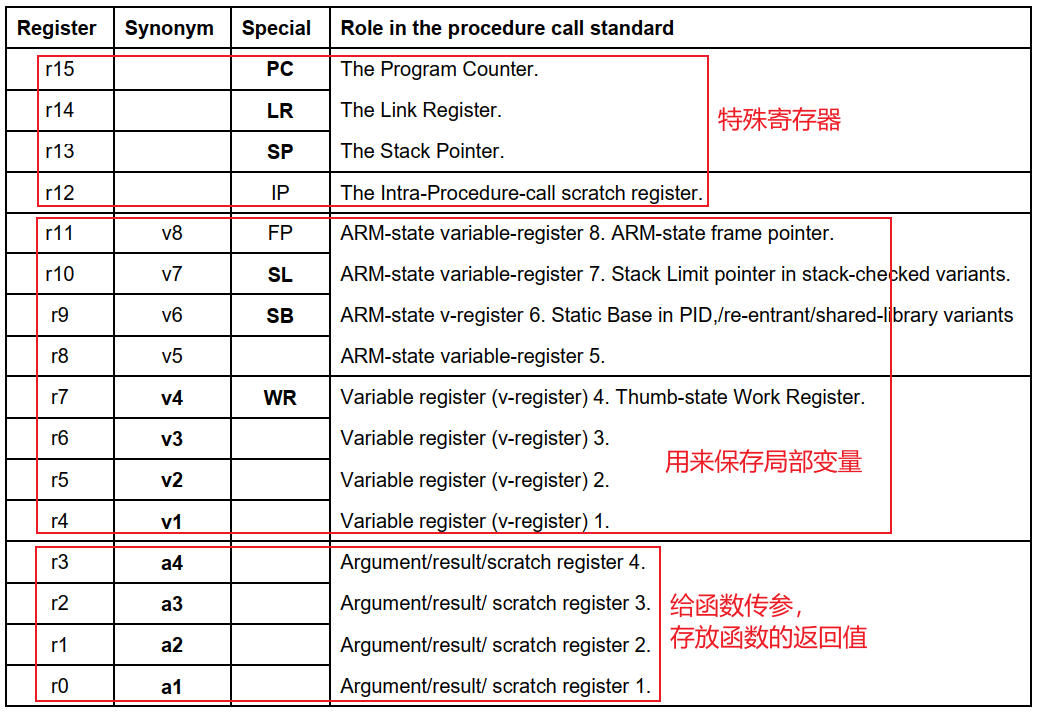
那么假设需要传递的参数大于四个,那么该如何传递参数呢?
在参数传递时,将所有参数看作是存放在连续的内存字单元中的字数据。
然后,依次将各字数据传送到寄存器 R0,R1,R2,R3 中,如果参数大于四个,将剩余的字数据传送到数据栈中,入栈顺序与参数顺序相反,即最后一个字数据最先入栈。
---- 《ARM体系结构及编程》杜春雷
4.2.2 C 的反汇编码及 Flash 上的内容
1). 反汇编示例

2). 烧写在 Flash 上的内容
| 地址 | Flash内容 |
| 0x08000000 | 00000000 |
| 0x08000004 | 08000009 |
| 0x08000008 | f8dfd004 |
| 0x0800000c | f000f80c |
| 0x08000010 | 20010000 |
| 0x08000014 | bf00b501 |
| 0x08000018 | 1e419800 |
| …… | …… |
3). 启动流程
上电后:
1. 设置栈:CPU 会从 0x08000000 读取值,用来设置 SP (我们的程序里再次设置了SP)
2. 跳转:CPU 从 0x08000004 得到地址值,根据它的BIT0切换为 ARM 状态或 Thumb 状态,然后跳转
- 对于cortex M3/M4,它只支持 Thumb 状态,所以 0x08000004 上的值 bit0 必定是 1
- 0x08000004 上的值 = Reset_Handler + 1
3. 从Reset_Handler继续执行
五. 寄存器编写 USART
5.1 串口编程步骤
1. 根据原理图确定串口引脚
2. 使能 USART 和 对应的 GPIO 时钟
3. 配置 GPIO 复用为 USART
4. 设置串口参数
- 波特率
- 数据位
- 校验位
- 停止位
5. 根据状态寄存器读写数据
5.2 STM32F103 串口框架
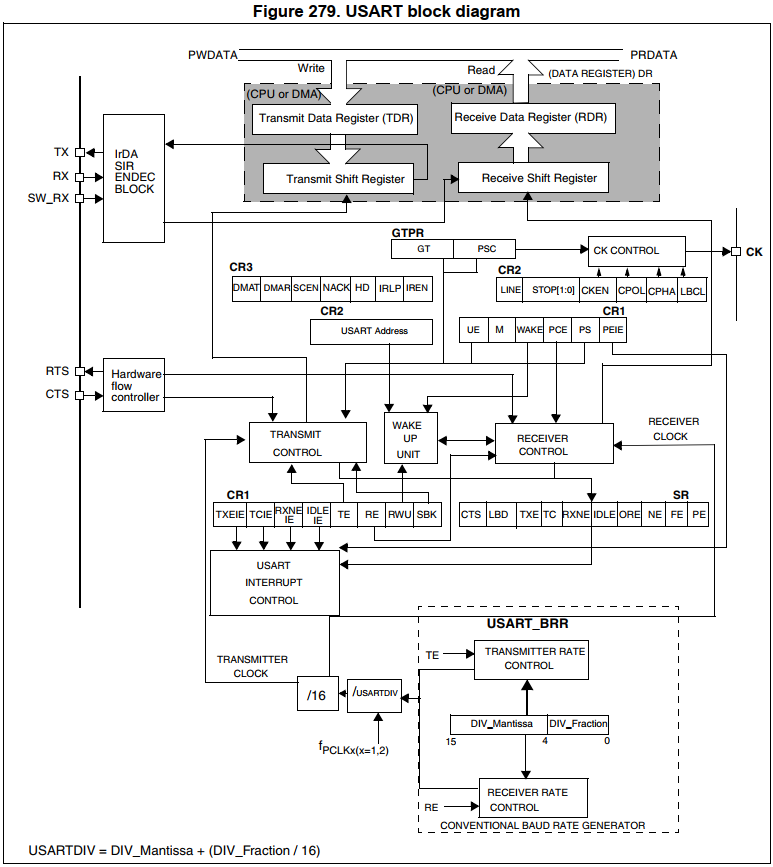
5.3 具体源码
// USART1
// PA9 TX PA10 RX
#include "uart.h"
#define USART1_BASR 0x40013800 // USART1寄存器基地址
#define GPIOA_BASE 0x40010800 // GPIOA寄存器基地址
#define RCC_BASE 0x40021000 // RCC寄存器基地址
#define RCC_APB2ENR (RCC_BASE + 0x18) // APB2外设使能寄存器地址
#define GPIOA_CRH (GPIOA_BASE + 0x04) // GPIO端口控制高寄存器偏移地址
#define DIV_Mantissa 4
#define DIV_Fraction 5
typedef unsigned int uint32_t;
typedef struct
{
volatile uint32_t SR; /*!< USART 状态寄存器, Address offset: 0x00 */
volatile uint32_t DR; /*!< USART 数据寄存器, Address offset: 0x04 */
volatile uint32_t BRR; /*!< USART 波特率寄存器, Address offset: 0x08 */
volatile uint32_t CR1; /*!< USART 控制寄存器1, Address offset: 0x0C */
volatile uint32_t CR2; /*!< USART 控制寄存器2, Address offset: 0x10 */
volatile uint32_t CR3; /*!< USART 控制寄存器3, Address offset: 0x14 */
volatile uint32_t GTPR; /*!< USART 保护时间和预分频寄存器,Address offset: 0x18 */
} USART_TypeDef;
void Uart_Init(void)
{
// 开启 GPIOA 和 UASRT1 的时钟
USART_TypeDef* usart1 = (USART_TypeDef *)USART1_BASR;
volatile uint32_t *pReg;
pReg = (volatile uint32_t *)RCC_APB2ENR;
*pReg |= ((1 << 14) | (1 << 2));
// 配置 GPIOA9 和 GPIOA10
pReg = (volatile uint32_t *)GPIOA_CRH;
*pReg &= ~((3 << 4)|(3 << 6)); // 清零
*pReg |= ((1 << 4)|(2 << 6)); // 配置 GPIOA9 为复用推挽输出, 速度为 10MHZ
*pReg &= ~((3<<8) | (3<<10)); // 清零
*pReg |= (0<<8) | (1<<10); // 配置 GPIOA10 为浮空输入
// 配置 USART1 参数
/*
* USARTDIV = DIV_Mantissa + (DIV_Fraction / 16)
* 波特率 = fck / (16 * USARTDIV)
* fck = 8000000
* 波特率 = 115200
*
*/
usart1->BRR = (DIV_Mantissa<<4) | (DIV_Fraction);
usart1->CR1 = (1<<13) | (0<<12) | (0<<10) | (1<<3) | (1<<2);
usart1->CR2 &= ~(3<<12);
}
int getchar(void)
{
USART_TypeDef *usart1 = (USART_TypeDef *)0x40013800;
while ((usart1->SR & (1<<5)) == 0);
return usart1->DR;
}
int putchar(char c)
{
USART_TypeDef *usart1 = (USART_TypeDef *)0x40013800;
while ((usart1->SR & (1<<7)) == 0);
usart1->DR = c;
return c;
}
六. 重定位
参考:【理解ARM架构】 散列文件 | 重定位_散列文件 scatter file-CSDN博客
6.1 段的概念——重定位引入
6.1.1 问题引入
在串口程序中添加全局变量,把它打印出来,看看会发生什么事。
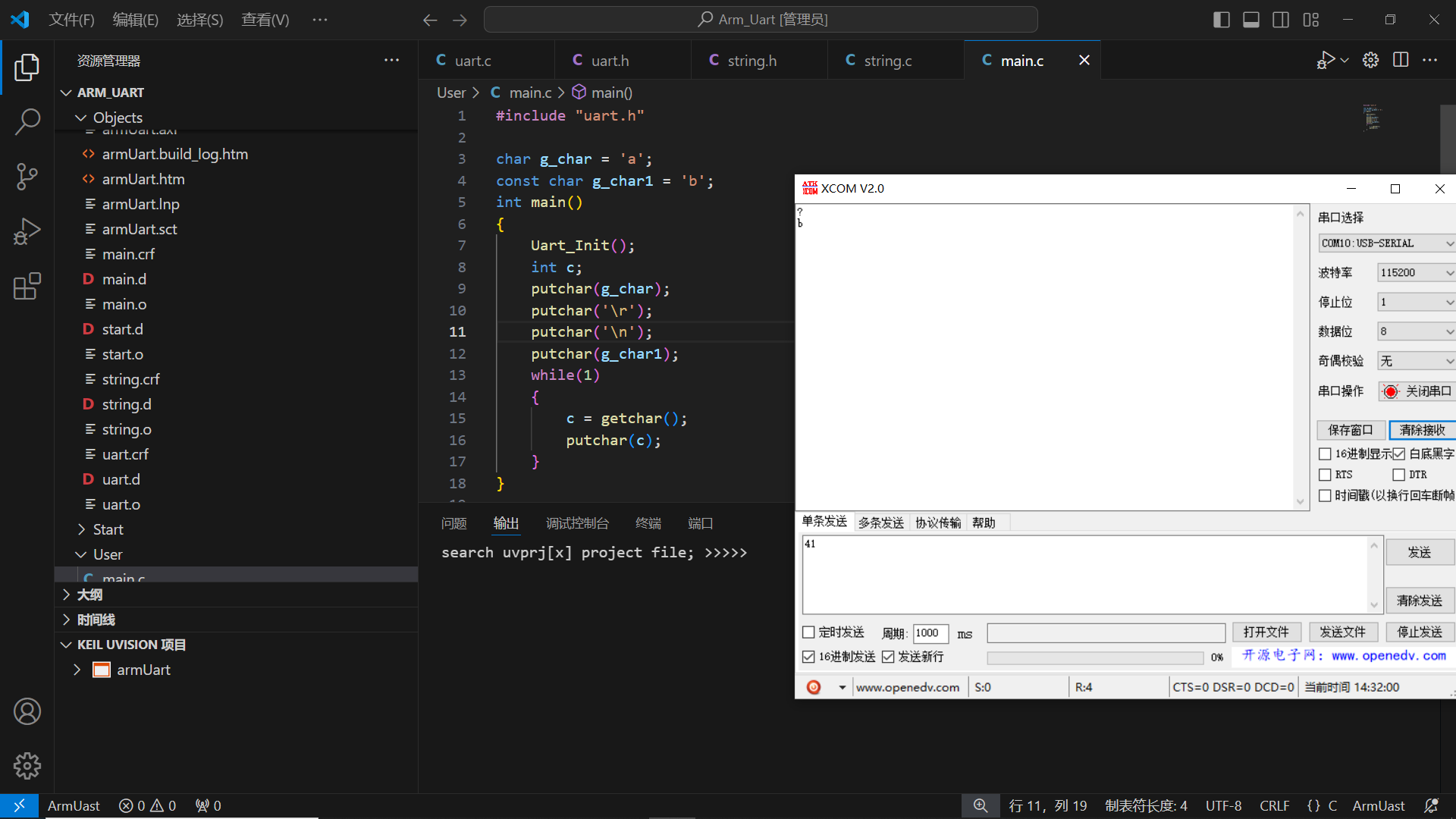
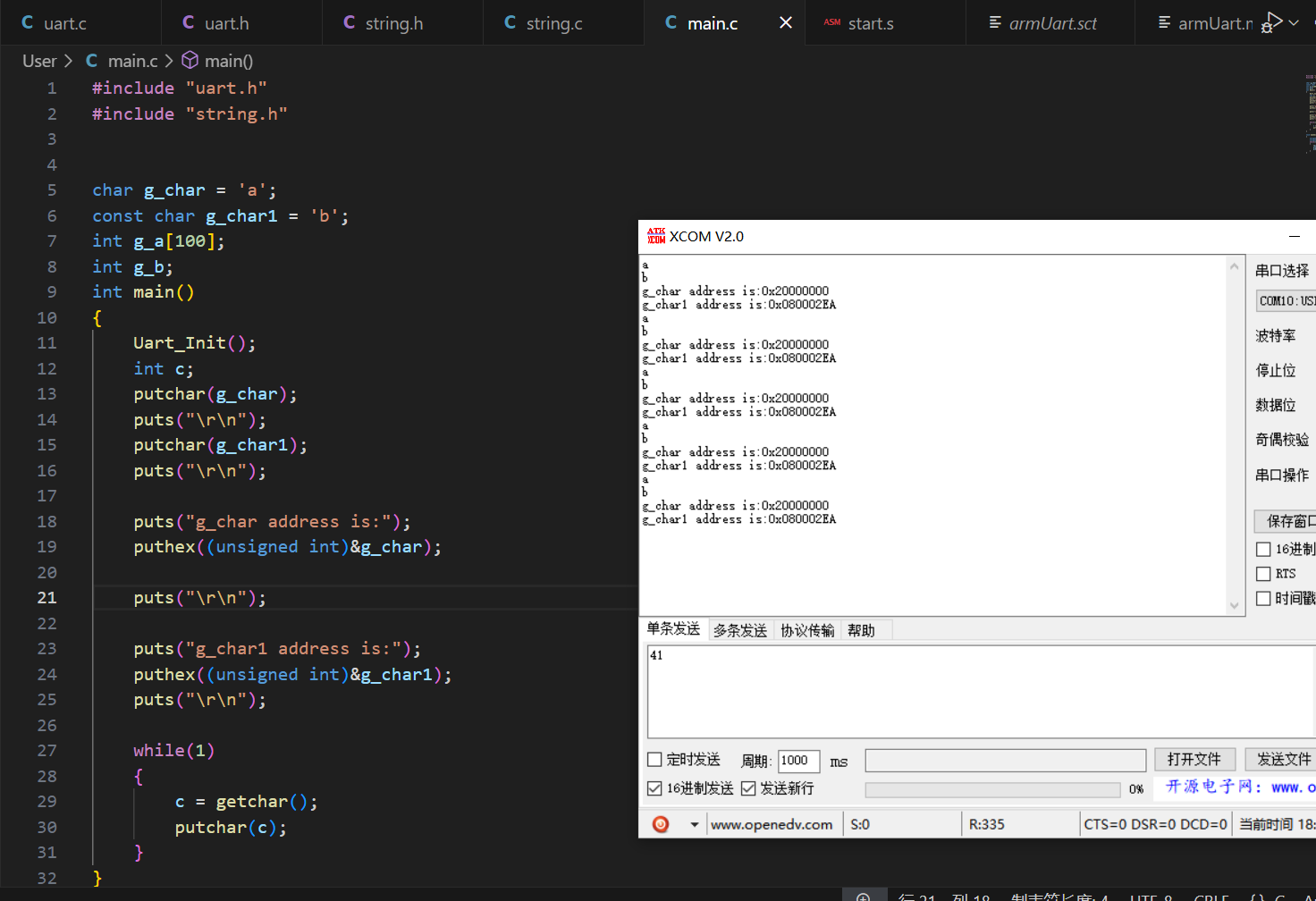
通过上图可以看到,直接输出 g_char 会乱码,而 g_char1 却不会;
为什么会有这样的现象?
接下来我们可以输出他们的地址,进行分析:
需要一个输出16进制以及输出字符串的函数:
#include "uart.h"
void puts(const char * s)
{
while(*s)
{
putchar(*s);
s++;
}
}
void puthex(unsigned int val)
{
int i,j;
puts("0x");
for(i = 7; i >= 0; i--)
{
j = (val >> (i*4)) & 0x0f;
if(j >= 0 && j <= 9)
putchar(j + '0');
else
putchar('A' + j - 0x0A);
}
}
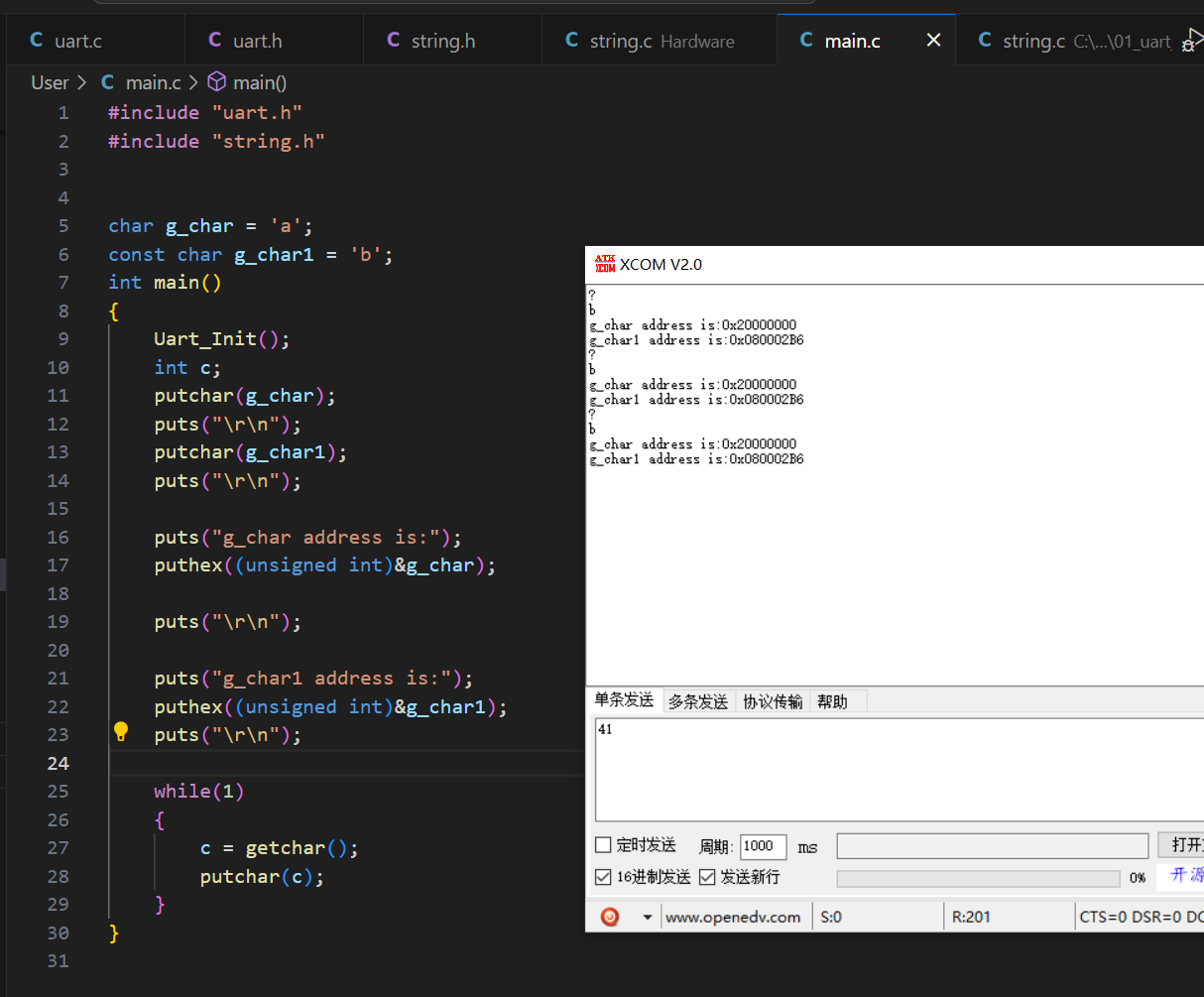
很明显的,出现乱码的变量储存地址是 RAM 地址;
而正常输出的变量储存地址是 ROM 地址。
因为全局变量是可读可写的话,编译器会生成一个位于 RAM 的链接地址,但是这个变量存储在 FLASH 区,所以我们要在启动文件进行一个数据段的重定位,否则程序运行的时候区读取链接地址会出现乱码。
6.1.2 段的概念
代码段、只读数据段、可读可写的数据段、BSS段
char g_Char = 'A'; // 可读可写,不能放在ROM上,应该放在RAM里
const char g_Char2 = 'B'; // 只读变量,可以放在ROM上
int g_A = 0; // 初始值为0,干嘛浪费空间保存在ROM上?没必要
int g_B; // 没有初始化,干嘛浪费空间保存在ROM上?没必要所以,程序分为这几个段:
- 代码段(RO-CODE):就是程序本身,不会被修改
- 可读可写的数据段(RW-DATA):有初始值的全局变量、静态变量,需要从ROM上复制到内存
- 只读的数据段(RO-DATA):可以放在ROM上,不需要复制到内存
- BSS段或ZI段:
- 初始值为0的全局变量或静态变量,没必要放在ROM上,使用之前清零就可以
- 未初始化的全局变量或静态变量,没必要放在ROM上,使用之前清零就可以
- 栈:局部变量保存在栈中,运行时生成
- 堆:一块空闲空间,使用malloc函数来管理它,malloc函数可以自己写
6.1.3 重定位
保存在 ROM 上的全局变量的值,使用前要复制到 RAM ,这就是数据段重定位;
想要把代码移动到其他位置,这就是代码段重定位。
6.2 重定位要做的事
6.2.1 程序中含有什么?
- 代码段:如果它不在链接地址上,就需要重定位
- 只读数据段:如果它不在链接地址上,就需要重定位
- 可读可写的数据段:如果它不在链接地址上,就需要重定位
- BSS段:不需要重定位,因为程序里根本不保存BSS段,使用前把BSS段对应的空间清零即可
6.2.2 谁来做重定位?
- 程序本身:它把自己复制到链接地址去
- 一开始,程序可能并不位于它的链接地址上,为什么它可以执行重定位的操作?
- 因为重定位的代码是使用“位置无关码”写的
- 什么叫位置无关码:这段代码扔在任何位置都可以运行,跟它所在的位置无关
- 怎么写出位置无关码:
- 跳转:使用相对跳转指令,不能使用绝对跳转指令
- 只能使用branch指令(比如
bl main),不能给PC直接复制,比如ldr pc, =main
- 只能使用branch指令(比如
- 不要访问全局变量、静态变量
- 不使用字符串
- 跳转:使用相对跳转指令,不能使用绝对跳转指令
6.2.3 怎么做重定位和清除 .BSS 段
- 核心:复制
- 复制的三要素:源、目的、长度
- 怎么知道代码段/数据段保存在哪?(加载地址)
- 怎么知道代码段/数据段要被复制到哪?(链接地址)
- 怎么知道代码段/数据段的长度?
- 怎么知道 .BSS 段的地址范围:起始地址、长度?
- 这一切
- 在keil中使用散列文件(Scatter File)来描述
- 在GCC中使用链接脚本(Link Script)来描述
6.2.4 加载地址和链接地址的区别
程序运行时,应该位于它的链接地址处,因为:
- 使用函数地址时用的是"函数的链接地址",所以代码段应该位于链接地址处
- 去访问全局变量、静态变量时,用的是"变量的链接地址",所以数据段应该位于链接地址处
但是: 程序一开始时可能并没有位于它的"链接地址":
- 比如对于STM32F103,程序被烧录器烧写在Flash上,这个地址称为"加载地址"
- 比如对于IMX6ULL/STM32MP157,片内ROM根据头部信息把程序读入内存,这个地址称为“加载地址”
当加载地址 != 链接地址时,就需要重定位。
6.3 散列文件的使用和分析
6.3.1 重定位的实质:移动数据
把代码段、只读数据段、数据段,移动到它的链接地址处。也就是复制!数据复制的三要素:源、目的、长度。
- 数据保存在哪里?加载地址
- 数据要复制到哪里?链接地址
- 长度
在keil中,使用散列文件来描述。在STM32F103这类资源紧缺的单片机芯片中,
- 代码段保存在Flash上,直接在Flash上运行(当然也可以重定位到内存里)
- 数据段保存在Flash上,使用前被复制到内存里
6.3.2 散列文件示例
1). 示例代码
; *************************************************************
; *** Scatter-Loading Description File generated by uVision ***
; *************************************************************
LR_IROM1 0x08000000 0x00080000 { ; load region size_region
ER_IROM1 0x08000000 0x00080000 { ; load address = execution address
*.o (RESET, +First)
.ANY (+RO)
.ANY (+XO)
}
RW_IRAM1 0x20000000 0x00010000 { ; RW data
.ANY (+RW +ZI)
}
}2). 散列文件语法
一个散列文件由一个或多个 Load region 组成:
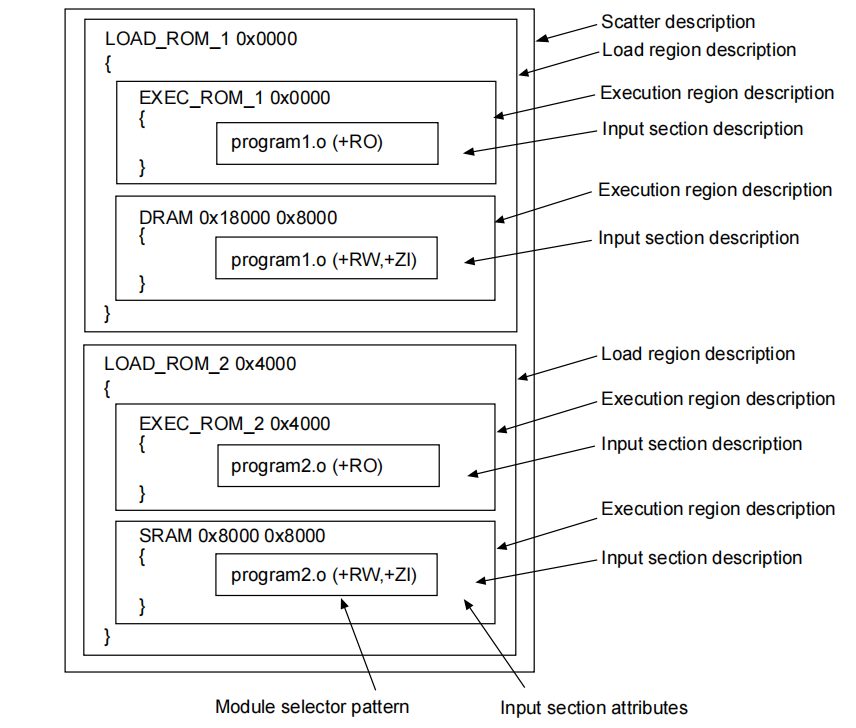
如上图,一个散列文件由一个或多个Load region(加载域)组成,加载域中含有一个或多个Execution region(可执行域),可执行域中含义一个或多个input section(输入段)。
- 加载域描述了Flash中一块区域的位置,包括该区域中有什么内容及位置(加载地址),而且还可以控制这些内容放置在哪里(加载地址)。
- 可执行域描述了RAM中程序运行时,该区域包含的内容(输入段),并且可以控制区域所在的位置(链接地址)。
- 输入部分描述了可执行域中包含哪些数据类型。
6.3.3 散列文件解析

如上图就是散列文件里的内容,LR_IROM1是加载域的名称,0x08000000是加载域的加载地址,也就是Flash中代码存放的起始地址,后面是加载域的大小。
第一个可执行域:
加载域中有两个可执行域,ER_IROM1是第一个可执行域的名称,起始地址是0x08000000(链接地址),里面包含多个输入段信息,该地址和加载地址重合,所以这个可执行域不用重定位。
- *.o :所有objects文件,就是链接之前的二进制目标文件。
- *:所有objects文件和库,在一个散列文件中只能使用一个*。
- .ANY:等同于*,优先级比*低;在一个散列文件的多个可执行域中可以有多个
.ANY。
*.o (RESET, +First)表示将所有objects文件中的RESET域放在可执行的起始(+First)位置。
*(InRoot$$Sections)是如果我们写了main函数,编译器自己会执行的一套东西。
.ANY (+RO)表示所有objects文件和库中的只读数据段放在这个可执行域中,挨着前面的输入段放置,和我们前面分析的一样,只读数据段并不需要重定位。
.ANY (+XO)并没有涉及到,也不用管它。
第二个可执行域:
RW_IRAM1是第二个可执行域的名称,起始地址是0x20000000(链接地址),位于RAM中,里面包含一个输入段信息,这个执行域需要进行重定位。
.ANY (+RW +ZI)表示所有objects文件和库中读写数据段和BSS或者ZI段,放在这个可执行域中。
6.3.4 如何获得 region 的信息
1). 可执行域信息
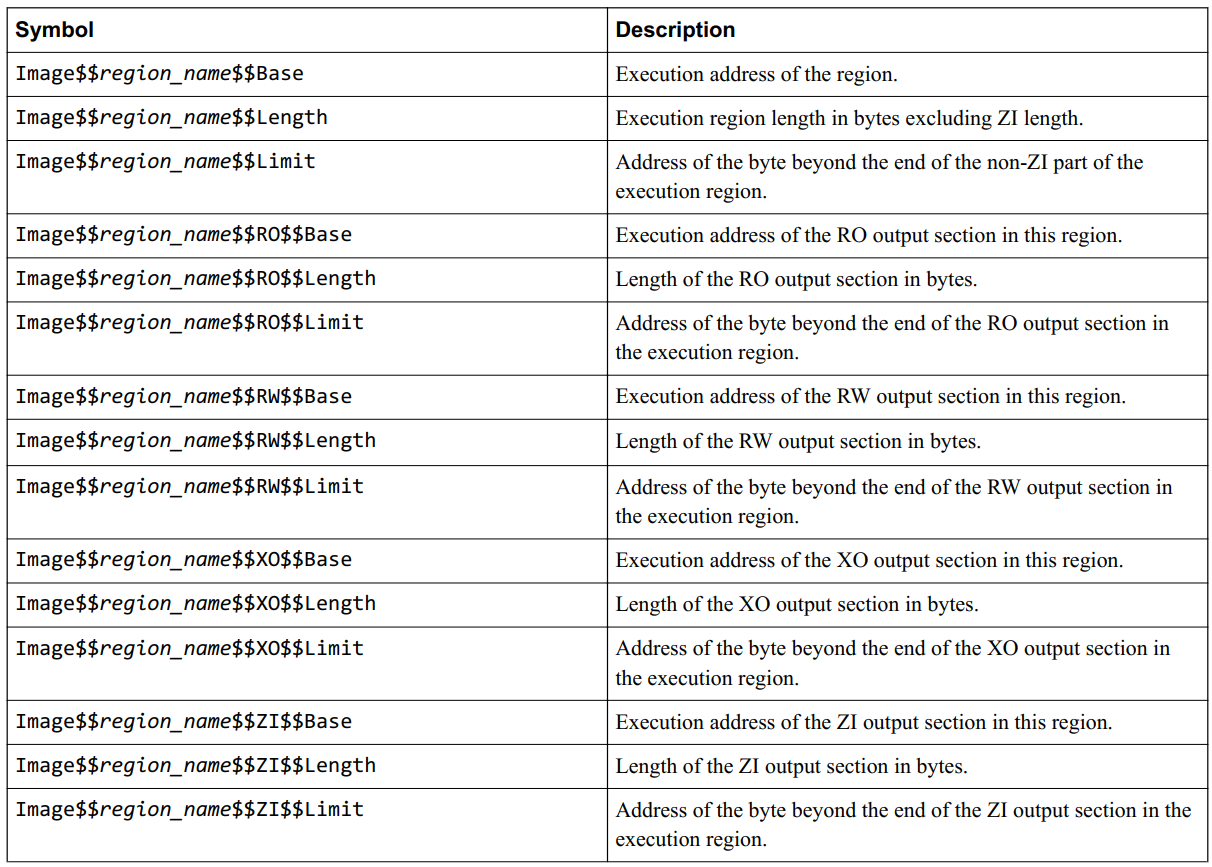
2). 加载域信息
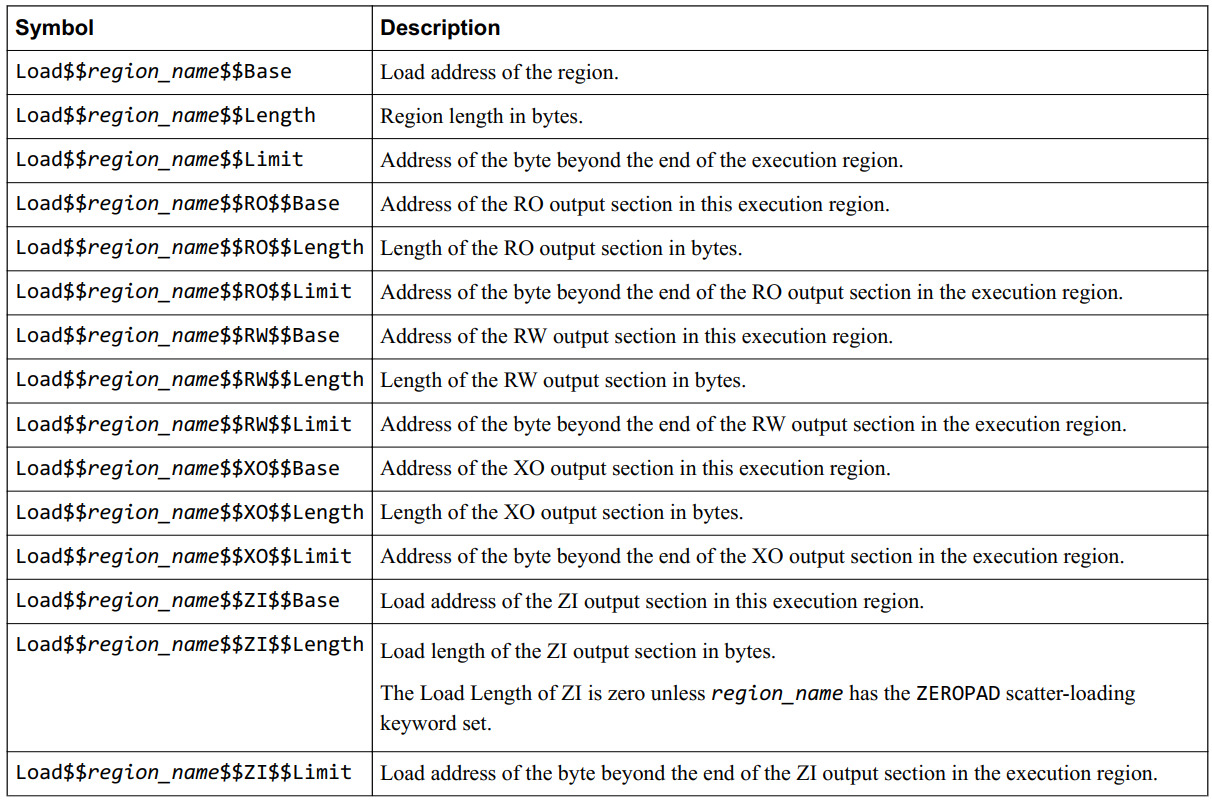
3). 在汇编中如何使用这些信息
示例如下:
IMPORT |Image$$RW_IRAM1$$Base|
IMPORT |Image$$RW_IRAM1$$Length|
IMPORT |Load$$RW_IRAM1$$Base|
LDR R0, = |Image$$RW_IRAM1$$Base| ; DEST
LDR R1, = |Load$$RW_IRAM1$$Base| ; SORUCE
LDR R2, = |Image$$RW_IRAM1$$Length| ; LENGTH4). C 语言如何使用这些信息
1. 声明为外部变量。
注意:使用时需要使用取址符:
extern int Image$$RW_IRAM1$$Base;
extern int Load$$RW_IRAM1$$Base;
extern int Image$$RW_IRAM1$$Length;
memcpy(&Image$$RW_IRAM1$$Base, &Image$$RW_IRAM1$$Length, &Load$$RW_IRAM1$$Base);2. 声明为外部数组
注意:使用时不需要使用取址符:
extern char Image$$RW_IRAM1$$Base[];
extern char Load$$RW_IRAM1$$Base[];
extern int Image$$RW_IRAM1$$Length;
memcpy(Image$$RW_IRAM1$$Base, Image$$RW_IRAM1$$Length, &Load$$RW_IRAM1$$Base);6.4 重定位 .RW data
6.4.1 实现一个 memcpy 函数
void mymemcpy(void * dest, void * src, unsigned int len)
{
unsigned char *pcDest = (unsigned char *) dest;
unsigned char *pcSrc = (unsigned char *) src;
while(len--)
{
*pcDest = *pcSrc;
pcSrc++;
pcDest++;
}
}
6.5.1 在启动文件调用 memcpy 进行重定位
PRESERVE8
THUMB
AREA RESET, DATA, READONLY
_Vectors DCD 0;
DCD Reset_Handler
AREA |.text|, CODE, READONLY
Reset_Handler PROC
IMPORT main
IMPORT mymemcpy
IMPORT |Image$$RW_IRAM1$$Base| ;链接地址(目标地址)
IMPORT |Image$$RW_IRAM1$$Length| ;长度
IMPORT |Load$$RW_IRAM1$$Base| ;加载地址(源地址)
LDR SP, =0x20000000+0x100 ; 进行调用之前一定要设置栈
LDR R0, =|Image$$RW_IRAM1$$Base|
LDR R1, =|Load$$RW_IRAM1$$Base|
LDR R2, =|Image$$RW_IRAM1$$Length|
BL mymemcpy
BL main
ENDP
END
即可成功对可读可写代码段进行一个重定位:
6.5 清除 .BSS 段
6.5.1 什么是 BSS 段
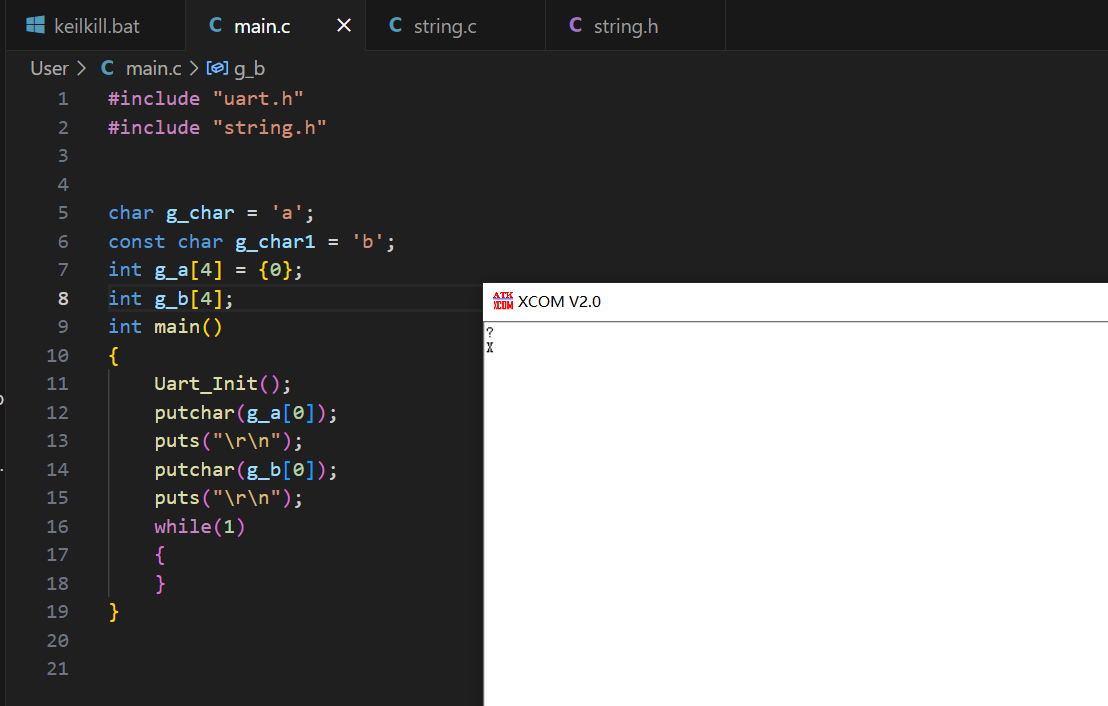
程序里的全局变量,如果它的初始值为0,或者没有设置初始值,这些变量被放在BSS段里,也叫ZI段。
int g_A = 0; // 放在BSS段
int g_B; // 放在BSS段BSS段并不会放入bin文件中,否则也太浪费空间了。
在使用BSS段里的变量之前,把BSS段所占据的内存清零就可以了。
注意:对于keil来说,一个本该放到BSS段的变量,如果它所占据的空间小于等于8字节自己,keil仍然会把它放在data段里。只有当它所占据的空间大于8字节时,才会放到BSS段。
int g_A[3] = {0, 0}; // 放在BSS段
char g_B[9]; // 放在BSS段
int g_A[2] = {0, 0}; // 放在data段
char g_B[8]; // 放在data段6.5.2 为什么要清零 BSS 段
如上图所示:本应该被初始化为 0 的 数据变成了乱码,这是因为 BSS 段的变量并不会在 bin 文件保存为 0;
当程序启动时,链接器会根据链接脚本将BSS段链接到RAM中。由于BSS段中的变量在二进制文件中没有被保存,所以在程序上电时,这些变量的值是未定义的,可能是随机的“乱码”;
我们需要在程序启动时把他初始化为 0 。
6.5.3 清零 BSS 段
1). BSS 段位于哪里?占多大字节?
在散列文件中,BSS段(ZI段)在可执行域RW_IRAM1中:
LR_IROM1 0x08000000 0x00080000 { ; load region size_region
ER_IROM1 0x08000000 0x00080000 { ; load address = execution address
*.o (RESET, +First)
*(InRoot$$Sections)
.ANY (+RO)
.ANY (+XO)
}
RW_IRAM1 0x20000000 0x00010000 { ; RW data
.ANY (+RW +ZI)
}
}BSS段(ZI段)的链接地址(基地址)、长度,使用下面的符号获得:

2). 汇编清零 BSS 段
IMPORT |Image$$RW_IRAM1$$ZI$$Base|
IMPORT |Image$$RW_IRAM1$$ZI$$Length|
LDR R0, = |Image$$RW_IRAM1$$ZI$$Base| ; DEST
LDR R1, = |Image$$RW_IRAM1$$ZI$$Length| ; Length
BL memset3). C 语言清零 BSS 段
- 方法1
声明为外部变量,使用时需要使用取址符:
extern int Image$$RW_IRAM1$$ZI$$Base;
extern int Image$$RW_IRAM1$$ZI$$Length;
memset(&Image$$RW_IRAM1$$ZI$$Base, 0, &Image$$RW_IRAM1$$ZI$$Length);- 方法2
声明为外部数组,使用时不需要使用取址符:
extern char Image$$RW_IRAM1$$ZI$$Base[];
extern int Image$$RW_IRAM1$$ZI$$Length[];
memset(Image$$RW_IRAM1$$ZI$$Base[], 0, Image$$RW_IRAM1$$ZI$$Length);6.5.4 具体代码
1. memset
void mymemset(void * dest, unsigned int val, unsigned int len)
{
unsigned char *pcDest = (unsigned char *)dest;
while(len--)
{
*pcDest = val;
pcDest++;
}
}2. 汇编文件
PRESERVE8
THUMB
AREA RESET, DATA, READONLY
_Vectors DCD 0;
DCD Reset_Handler
AREA |.text|, CODE, READONLY
Reset_Handler PROC
IMPORT main
IMPORT mymemcpy
IMPORT mymemset
IMPORT |Image$$RW_IRAM1$$Base| ;链接地址(目标地址)
IMPORT |Image$$RW_IRAM1$$Length| ;长度
IMPORT |Load$$RW_IRAM1$$Base| ;加载地址(源地址)
IMPORT |Image$$RW_IRAM1$$ZI$$Base| ;BSS段地址
IMPORT |Image$$RW_IRAM1$$ZI$$Length| ;BSS段长度
LDR SP, =0x20000000+0x100
LDR R0, =|Image$$RW_IRAM1$$Base|
LDR R1, =|Load$$RW_IRAM1$$Base|
LDR R2, =|Image$$RW_IRAM1$$Length|
BL mymemcpy
LDR R0, =|Image$$RW_IRAM1$$ZI$$Base| ;BSS段地址
MOV R1, #0
LDR R2, =|Image$$RW_IRAM1$$ZI$$Length| ;BSS长度
BL mymemset
BL main
ENDP
END
3. 运行结果
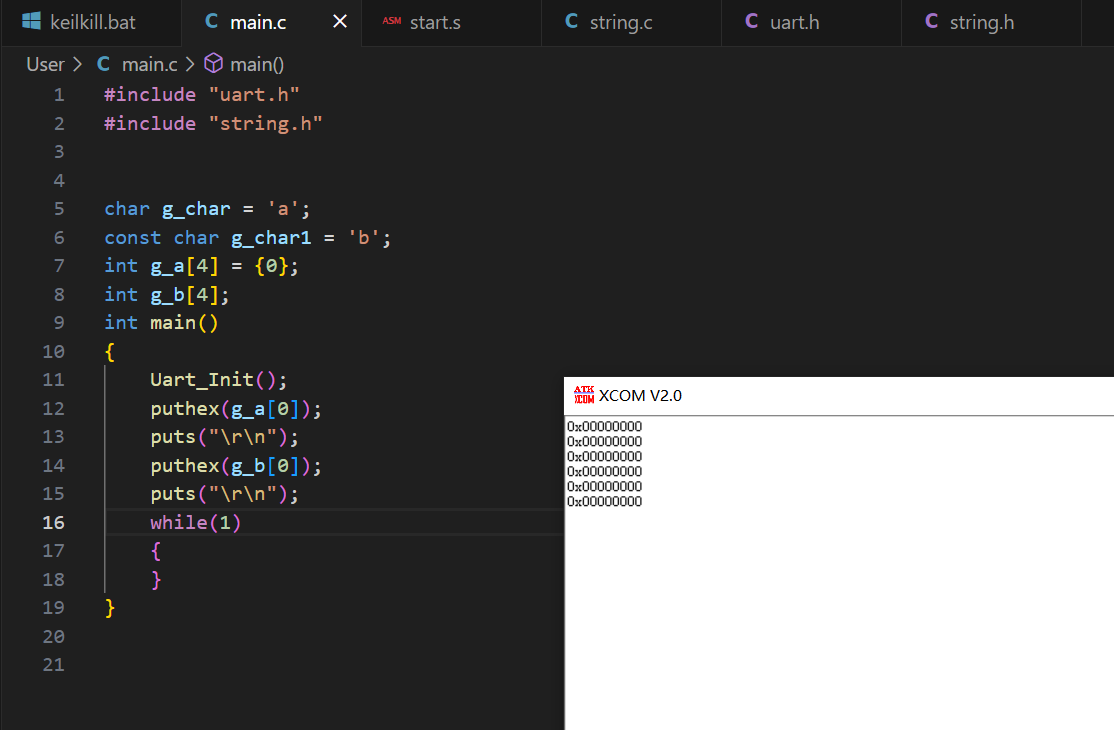
6.6 重定位代码
6.6.1 什么时候需要代码重定位
之前散列文件中的代码段的 加载地址=链接地址,因此无需重定位,但是想让程序执行得更快,需要把代码段复制到内存(RAM)里,下面修改散列文件:
; *************************************************************
; *** Scatter-Loading Description File generated by uVision ***
; *************************************************************
LR_IROM1 0x08000000 0x00010000 { ; load region size_region
ER_IROM1 0x20000000{ ; load address = execution address
*.o (RESET, +First)
.ANY (+RO)
}
RW_IRAM1 +0 { ; RW data
.ANY (+RW +ZI)
}
}
- 可执行域
ER_IROM1- 加载地址为0x08000000,可执行地址为0x20000000,两者不相等
- 板子上电后,从0x08000000处开始运行,需要尽快把代码段复制到0x20000000
- 可执行域
RW_IRAM1- 加载地址:紧跟着ER_IROM1的加载地址
- 可执行地址:紧跟着ER_IROM1的可执行地址
- 需要尽快把数据段复制到可执行地址处
6.6.2 不进行重定位会发生什么
1). 程序跑飞
指令从0x08000000位置开始存储(加载地址),但是实际运行地址(链接地址)是从0x20000000处开始的,但此空间并没有放入指令,所以此时程序不能正常执行,分析反汇编文件:
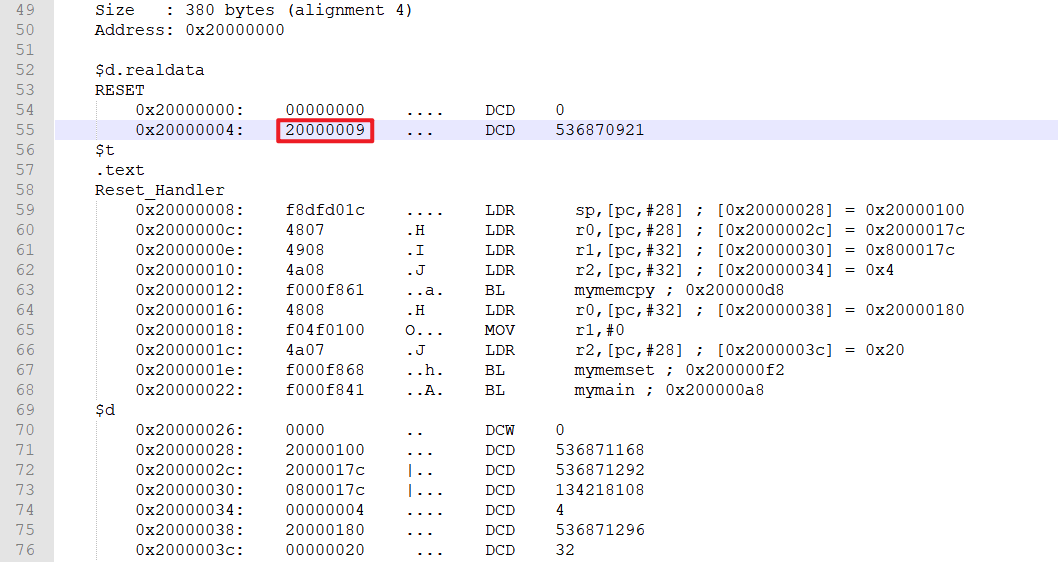
注意:图中第一列是编译器生成的链接地址,实际上,我们没有进行代码的重定位之前,这些代码都是储存在 FLASH 上的,暂时可以忽略这里的链接地址。
执行流程:
- 程序上电复位,从 RESET 取出 0 作为栈的大小(我们后面单独设置了 SP ),随后将 0x2000 0009 取出,将 PC 寄存器的值设置为 0x2000 0008 (因为最后一位为1的话将执行 THUMB 指令集)
- 程序执行到 0x2000 0008 的位置时,由于我们还没有进行代码重定位,所以 0x2000 0008 上储存的并不是我们想执行的程序,所以程序跑飞。
2). 程序竟然正常运行
我们来修改一下启动文件:
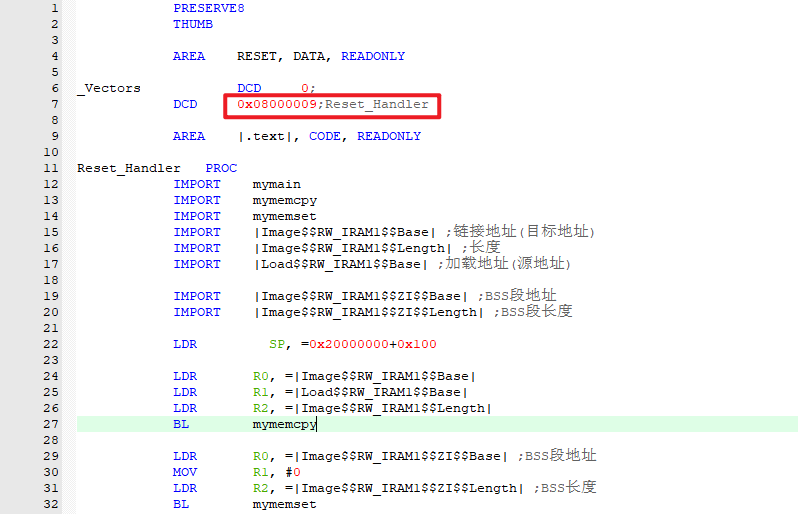
将 Reset_Handler 修改为 0x8000 0009 程序即可正常运行
为什么呢?我们来分析一下反汇编文件:
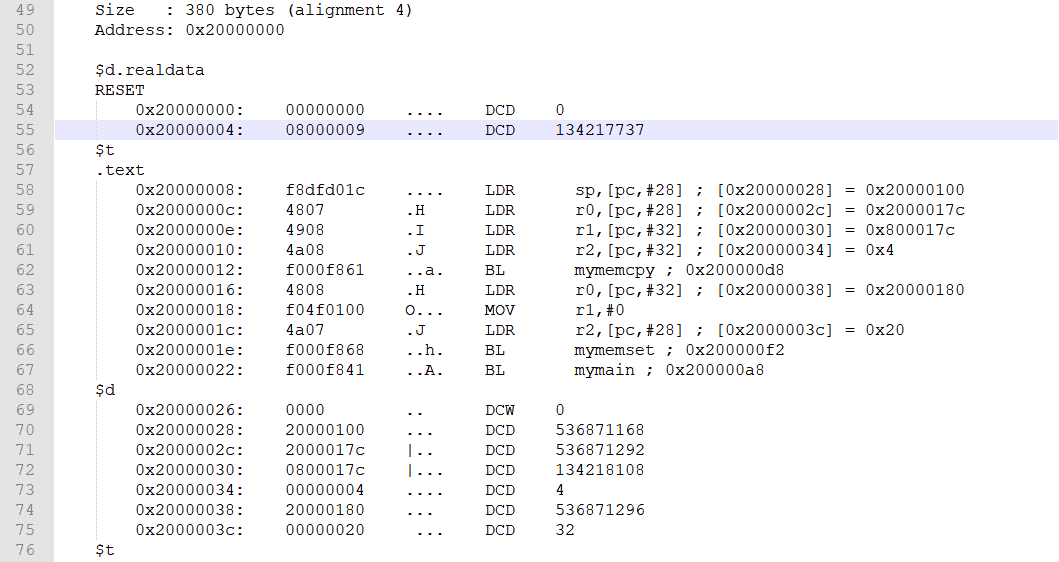
我们未进行重定位的时候,.text段实际上还是存在 FLASH 的:
从 Reset_Handler 开始执行时,pc = 0x08000008 + 4(因为ARM指令流水线机制),然后从pc+ 28 = 0x08000028取指执行(链接地址 0x20000028也是相对pc偏移计算出来的),后面每条指令都是相对 PC 偏移运行的,即依然是在 FLASH 中取指的。
3). 如果不使用位置无关码呢
- 在汇编中,我们可以这样使用 mymain 的链接地址:
LDR pc, =my_main
; 调用函数时,用到main函数的链接地址,如果代码段没有重定位,则跳转失败- 在 C 语言中,我们可以使用函数指针:
void (*funcptr)(const char *s);
funcptr = puts;
funcptr("hello, test function ptr");当程序运行到函数指针处时,指针指向的函数运行时的地址(链接地址)是存放在RAM 中的,程序会以绝对跳转的方式到该空间取指,但并没有存入指令,程序跑飞。
6.6.3 重定位代码段编程实现
语法以及方法和上述 重定位可读可写数据段 类似,不再赘述。
具体代码实现:
PRESERVE8
THUMB
AREA RESET, DATA, READONLY
_Vectors DCD 0;
DCD 0x08000009;Reset_Handler
AREA |.text|, CODE, READONLY
Reset_Handler PROC
IMPORT mymain
IMPORT mymemcpy
IMPORT mymemset
IMPORT |Image$$ER_IROM1$$Base| ;代码段链接地址(目标地址)
IMPORT |Image$$ER_IROM1$$Length| ;代码段长度
IMPORT |Load$$ER_IROM1$$Base| ;代码段加载地址(源地址)
IMPORT |Image$$RW_IRAM1$$Base| ;链接地址(目标地址)
IMPORT |Image$$RW_IRAM1$$Length| ;长度
IMPORT |Load$$RW_IRAM1$$Base| ;加载地址(源地址)
IMPORT |Image$$RW_IRAM1$$ZI$$Base| ;BSS段地址
IMPORT |Image$$RW_IRAM1$$ZI$$Length| ;BSS段长度
LDR SP, =0x20000000+0x5000
LDR R0, =|Image$$ER_IROM1$$Base|
LDR R1, =|Load$$ER_IROM1$$Base|
LDR R2, =|Image$$ER_IROM1$$Length|
BL mymemcpy
LDR R0, =|Image$$RW_IRAM1$$Base|
LDR R1, =|Load$$RW_IRAM1$$Base|
LDR R2, =|Image$$RW_IRAM1$$Length|
BL mymemcpy
LDR R0, =|Image$$RW_IRAM1$$ZI$$Base| ;BSS段地址
MOV R1, #0
LDR R2, =|Image$$RW_IRAM1$$ZI$$Length| ;BSS长度
BL mymemset
BL mymain
ENDP
END
注意:几个写代码遇到的坑:
- 栈的大小一定要设置得存的下 代码段
- RESET 第二个 一定要写成 0x0800 0009 ,不然程序复位后会直接跳到 0x2000 0008 执行,导致跑飞

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









