







Pandas的基本使用和实际案例
- Pandas的基本语法
- Series对象创建
- DataFram对象的创建
- Pandas的index
- 浏览数据 head() tail()
- df.info() 查看数据的类型和数学信息
- df.shape 看数据表有多少行,多少列
- df.describe() 掌握数值的分布情况:均值 最值 方差
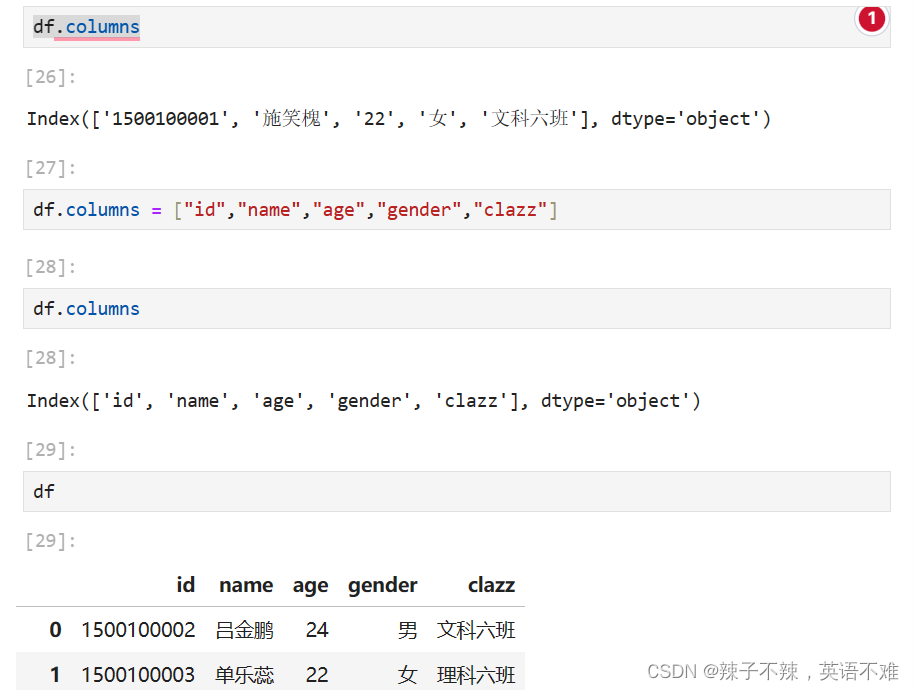
- df.columns =['xxx','xxx'] 修改变量列(表头)
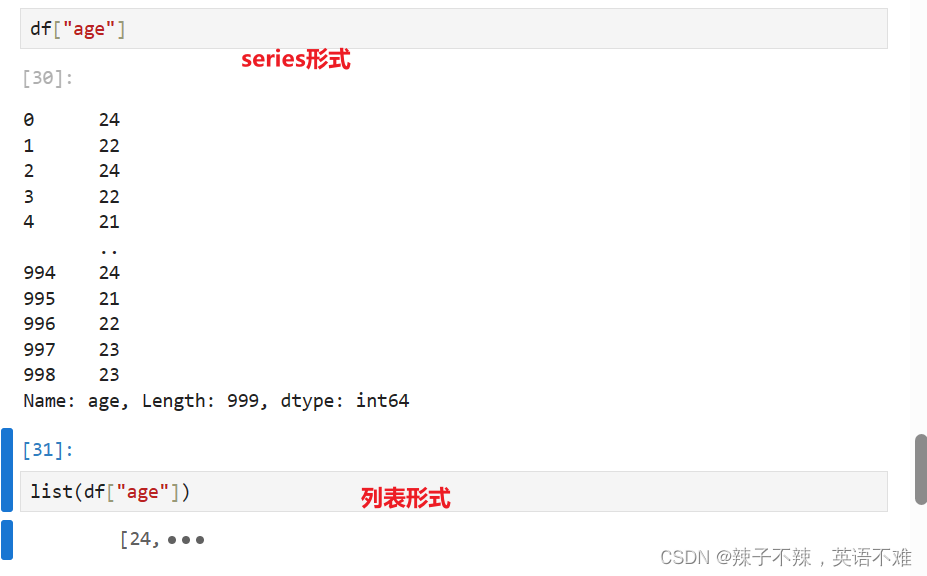
- 筛选变量列 df["age"]
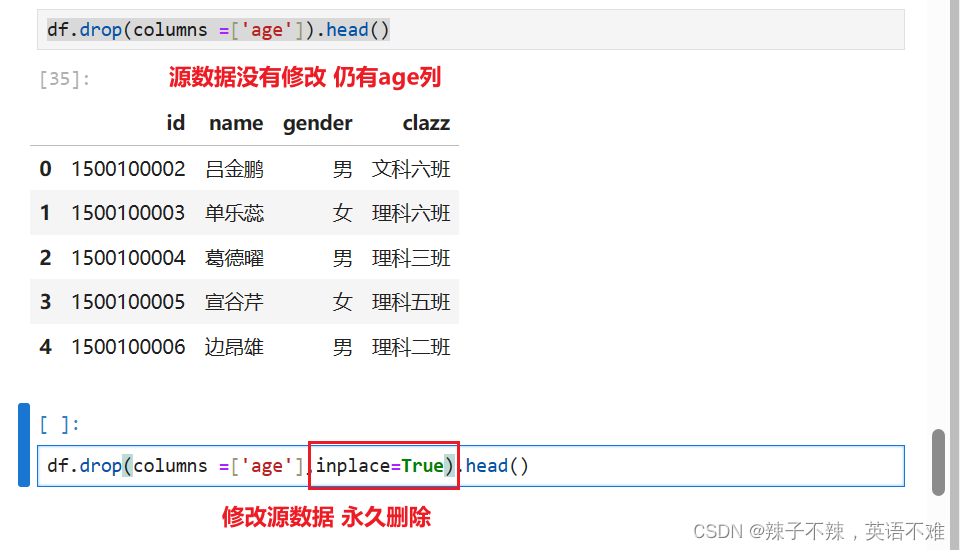
- 删除变量列 df.drop(columns =['age']).head()
- 添加变量列
- df.dtypes :査看各列的数据类型
- 修改某一列数据的数据类型 df.column.astype ('str')
- ==将索引全部还原为变量 df.reset_index ()==
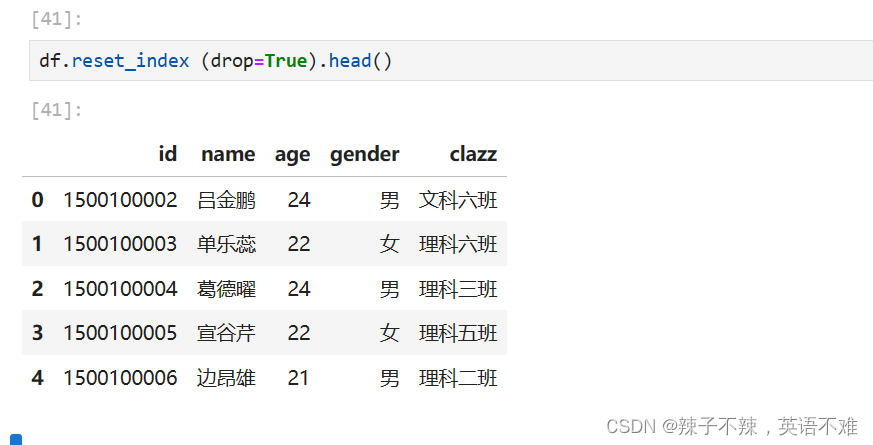
- ==删除 index 列 df.reset_index (drop=True)==
- 索引和切片
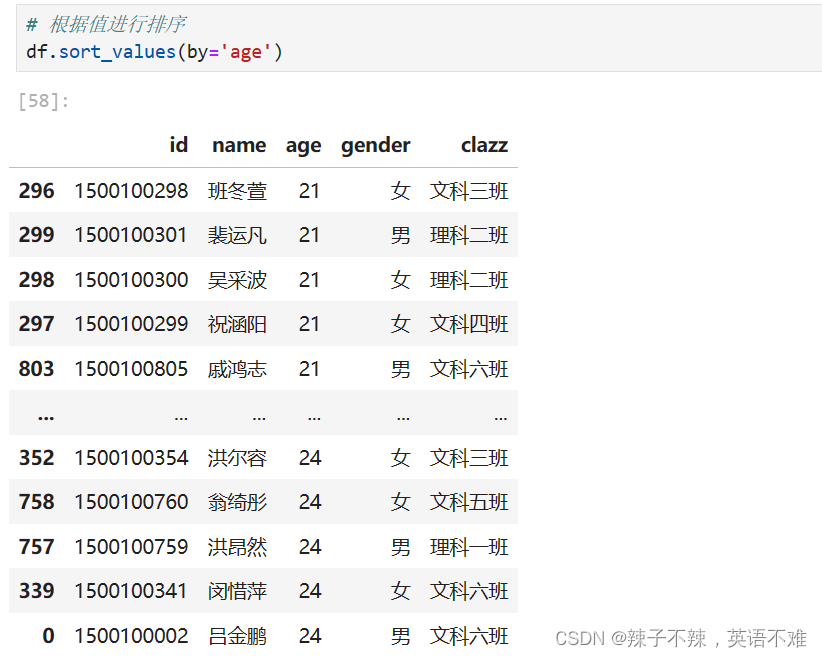
- 用变量值排序sort()
- pd导入文件
- pd导出文件
Pandas的基本语法
Series对象创建
import pandas as pd
data=pd.Series([4,3,5,6,1])
data

指定前面的index序列
data=pd.Series([5,4,6,3,1],index=['one','two','three','four','five'])
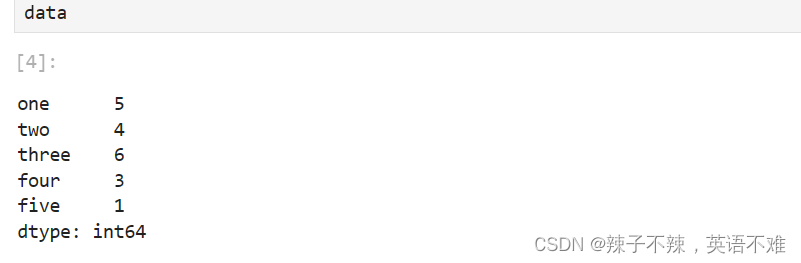
使用list 列表指定index
data=pd.Series([4,3,2,1],index=list('abcd'))

DataFram对象的创建
population_dict={'beijing':3000,'shanghai':1200,'guangzhou':1800}
area_dict={'beijing':300,'shanghai':180,'guangzhou':200}
import pandas as pd
population_series=pd.Series(population_dict)
area_series=pd.Series(area_dict)
citys=pd.DataFrame({'area':area_series,'population':population_series})

1 citys.index 前面的北京上海。。。
2 citys.values (300,3000 ),(180,1200)按行取值
3 citys.columns 【area ,population】
可以用list(city.index) 等等来取出你想要的值放在列表中
Pandas的index
Pandas中的Index,其实是不可变的一维数组
ind=pd.Index([3,4,5,6,7])
#根据下标获取值
ind[3]
#切片获取值
ind[::2]
#有ndim shap dtype size属性
#但不能进行修改
#ind[3]=20

浏览数据 head() tail()
#浏览前几条记录
df.head()
df.head(10)
#浏览最后几条记录
df.tail()
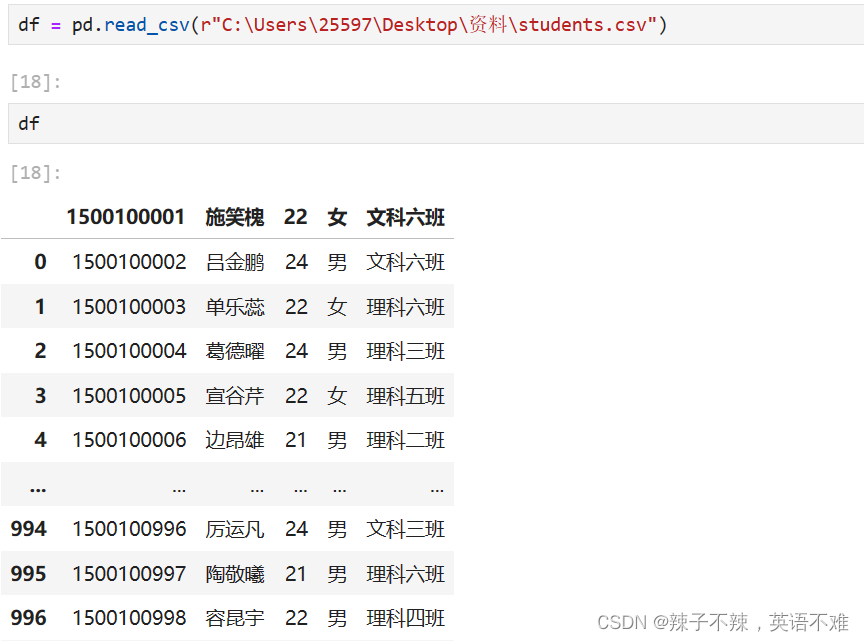

df.info() 查看数据的类型和数学信息
df.shape 看数据表有多少行,多少列

df.describe() 掌握数值的分布情况:均值 最值 方差
掌握数值的分布情况,即均值是多少,最值是多少,方差及分位数
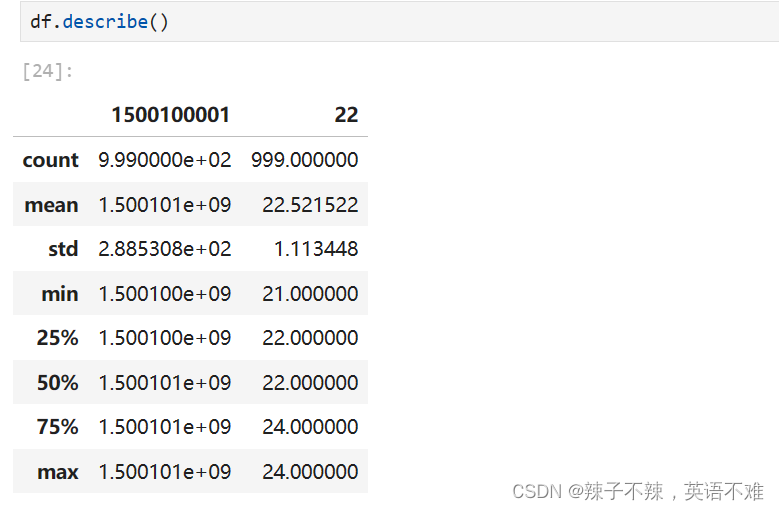
只会计算int类型的列的结果
df.columns =[‘xxx’,‘xxx’] 修改变量列(表头)
筛选变量列 df[“age”]
删除变量列 df.drop(columns =[‘age’]).head()
添加变量列
几种方法都可以
df[cloumn] = pd.Series([val,val2,val3],index=[c1,c2,c3])
df["xxx"]=[a,b,c,d,e,f,...]
df[cloumn] = df[c2]+df[c3]
df.dtypes :査看各列的数据类型

修改某一列数据的数据类型 df.column.astype (‘str’)

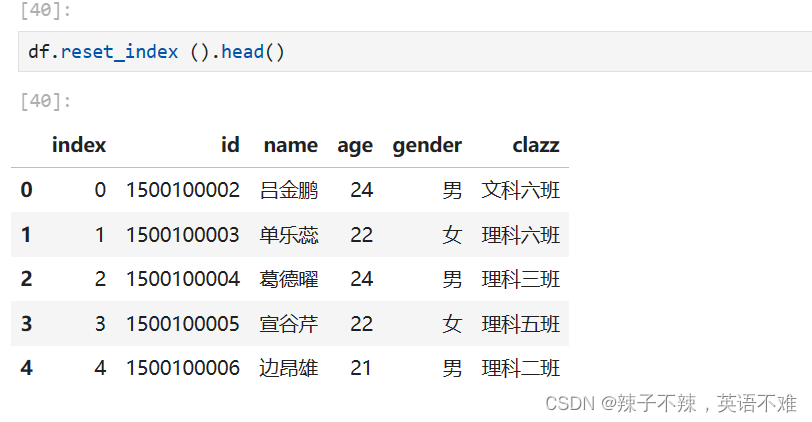
将索引全部还原为变量 df.reset_index ()
删除 index 列 df.reset_index (drop=True)
索引和切片
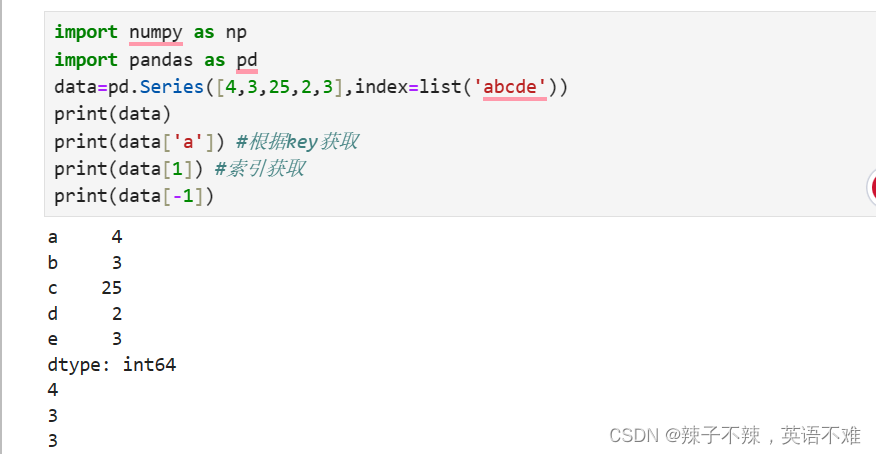
Series的索引和切片
索引
切片
import numpy as np
import pandas as pd
data=pd.Series([4,3,25,2,3],index=list('abcde'))
print(data)
print(data['a':'d'])
print(data[2:4]) #索引切片
print(data[-3:-1])
print(data[data>3])

loc 与 iloc
data=pd.Series([5,3,2,5,9],index=[1,2,3,4,5])
print(data)
print(data.loc[1]) # 取序列1对应的数
print(data.iloc[1]) # 取值的第二个

DataFrame的索引和切片
索引
#获取一列
df[col]
#获取多列
df[[col1 , col2]]

import numpy as np
import pandas as pd
data=pd.DataFrame(np.arange(12).reshape(3,4),
index=list('abc'),columns=list('ABCD'))
print(data)
#获取行为'b'的行
print(data.loc['b'])
#使用iloc获取,行为'b'的行,行号为1
print(data.iloc[1])


df.isin(values) 返回结果为相应的位置是否匹配给出的 values
1 df.col.isin([1,3,5])
2 df[ df.col.isin([1,3,5])]
3 df[ df.col.isin(['val1','val2'])]
4 df[ df.index.isin(['val1','val2'])]
query()选择满足条件的值
df.query("col>10 and col<90 and col1=val")
用变量值排序sort()
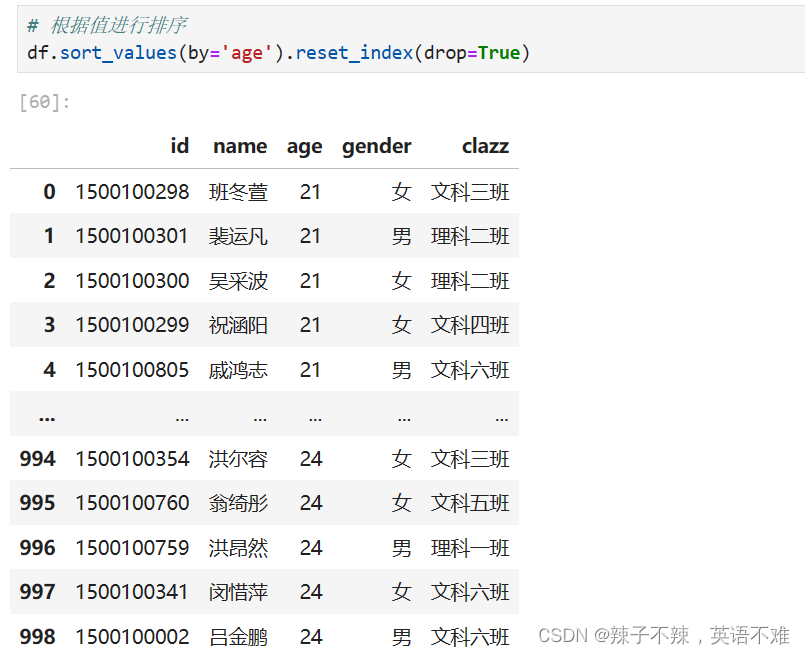
这里就可以使用reset_index
pd导入文件
使用Pandas模块操作Excel时候,需要安装openpyxl
import pandas as pd
pd.read_excel('stu_data.xlsx')
# 指定哪个sheet名字
pd.read_excel('stu_data.xlsx',sheet_name='Target')
pd.read_excel('stu_data.xlsx',sheet_name=0)
# 导入csv文件
pd.read_csv('stu_data.csv',encoding='gbk')
pd.read_table('test_data.txt',encoding='utf-8',sep='\t')
# 读数据时建立一个索引
df = pd.read_csv ("filename",index_col="column”)
这些都是读入文件的方法 但是都需要使用变量来进行接收 都是DataFram的格式
pd导出文件
# 不需要index 就是datafram形式直接保存 不带前面的index索引
df2.to_excel('temp.xlsx', index = False,sheet_name = data)
df2.to_csv('temp.csv', index = False,sheet_name = data)
















 1815
1815











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











