







目录
5.4 增加卷积核大小,第一、二层卷积核大小由3*3增加到5*5
5.5 增加卷积核大小,第一、二层卷积核大小由3*3增加到7*7
1. 代码部分:
import tensorflow as tf
# 处理因python版本不同带来的错误
old_v = tf.logging.get_verbosity()
tf.logging.set_verbosity(tf.logging.ERROR)
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
from tensorflow.examples.tutorials.mnist import input_data
# 属于那个类就为1,不属于就为0,零点几为多,取最高
mnist = input_data.read_data_sets("./mnist/", one_hot=True)
# mnist数据集形状就是28*28*1,None是bitesize
X = tf.placeholder(tf.float32, [None, 28, 28, 1])
# 10个类,用10维向量作为输出,数据集是1*10,这里也得是1*10
Y = tf.placeholder(tf.float32, [None, 10])
# dropout随机删掉一些,解决过拟合
keep_prob = tf.placeholder(tf.float32)
# 模型
# 根据正态分布随机生成向量,四维的tensor,卷积核3*3,一层的,因为输入x是一层的,32个卷积核一起计算,标准差0.01,生成的是个常量,放到tf.Variable里成为变量
W1 = tf.Variable(tf.random_normal([3, 3, 1, 32], stddev=0.01))
# strides在官方定义中是一个一维具有四个元素的张量,其规定前后必须为1,所以我们可以改的是中间两个数,中间两个数分别代表了水平滑动和垂直滑动步长值。
# 在卷积核移动逐渐扫描整体图时候,因为步长的设置问题,可能导致剩下未扫描的空间不足以提供给卷积核的,大小扫描 比如有图大小为5*5,卷积核为2*2,步长为2,
# 卷积核扫描了两次后,剩下一个元素,不够卷积核扫描了,这个时候就在后面补零,补完后满足卷积核的扫描,这种方式就是same。
# 2d上的一个卷积,X是输入,W1是32个卷积核,padding边缘填充
L1 = tf.nn.conv2d(X, W1, strides=[1, 1, 1, 1], padding='SAME')
# 对L1进行relu激活
L1 = tf.nn.relu(L1)
# 进行最大池化,
L1 = tf.nn.max_pool(L1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
# 第二层
W2 = tf.Variable(tf.random_normal([3, 3, 32, 64], stddev=0.01))
L2 = tf.nn.conv2d(L1, W2, strides=[1, 1, 1, 1], padding='SAME')
L2 = tf.nn.relu(L2)
L2 = tf.nn.max_pool(L2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
W3 = tf.Variable(tf.random_normal([7 * 7 * 64, 256], stddev=0.01))
# 改变L2形状,-1就是None,符合其他维形状就行,第一维不要求,任何形状都可以,64是卷积核的个数,经过L2图片形状变成7*7,100*7*7*64的矩阵
L3 = tf.reshape(L2, [-1, 7 * 7 * 64])
# 进行矩阵乘法,变成100*256的矩阵
L3 = tf.matmul(L3, W3)
L3 = tf.nn.relu(L3)
# 把一些参数设为0
L3 = tf.nn.dropout(L3, keep_prob)
# 256*10的矩阵
W4 = tf.Variable(tf.random_normal([256, 10], stddev=0.01))
# 得到预测值
model = tf.matmul(L3, W4)
# 损失函数
# 预测值是model,标签是Y,batch_size*10
# 求均值
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=model, labels=Y))
# 优化器,学习率0.001,目标是把cost最小化
optimizer = tf.train.AdamOptimizer(0.001).minimize(cost)
# 初始化所有变量
init = tf.global_variables_initializer()
# 定义一个session
sess = tf.Session()
sess.run(init)
batch_size = 100
total_batch = int(mnist.train.num_examples / batch_size)
# epoch一轮,整个数据集输入
for epoch in range(15):
total_cost = 0
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
# reshape
batch_xs = batch_xs.reshape(-1, 28, 28, 1)
# 放了两个节点进去
_, cost_val = sess.run([optimizer, cost], feed_dict={X: batch_xs, Y: batch_ys, keep_prob: 0.7})
total_cost += cost_val
print('Epoch:', '%04d' % (epoch + 1),
'Avg. cost =', '{:.3f}'.format(total_cost / total_batch))
# 判断是否相等,相等为1
is_correct = tf.equal(tf.argmax(model, 1), tf.argmax(Y, 1))
# 算准确度,cast类型转换,算精确度
accuracy = tf.reduce_mean(tf.cast(is_correct, tf.float32))
print('accuracy:', sess.run(accuracy, feed_dict={X: mnist.test.images.reshape(-1, 28, 28, 1),
Y: mnist.test.labels, keep_prob: 1}))
2. 原理:
首先输入minst数据集,mnist数据集形状是28*28*1。
第二步进行数据规则化,彩色图像的输入通常先要分解为R(红)G(绿)B(蓝)三个通道,其中每个值介于0~255之间。
然后进行卷积运算(Convolution),前面讲到,由于普通的神经网络对于输入与隐层采用全连接的方式进行特征提取,在处理图像时,稍微大一些的图将会导致计算量巨大而变得十分缓慢。卷积运算正是为了解决这一问题,每个隐含单元只能连接输入单元的一部分,我们可以理解为是一种特征的提取方法。期中卷积运算的基础概念有:深度(depth)、步长(stride)、补零(zero-padding)、卷积核(convolution kernel)。
深度(depth):深度指的是图的深度与它控制输出单元的深度,也表示为连接同一块区域的神经元个数。
步幅(stride):用来描述卷积核移动的步长。
补零(zero-padding):通过对图片边缘补零来填充图片边缘,从而控制输出单元的空间大小。
卷积核(convolution kernel):在输出图像中每一个像素是输入图像中一个小区域中像素的加权平均的权值函数。卷积核可以有多个,卷积核参数可以通过误差反向传播来进行训练。
第四步进行激活操作,CNN卷积神经网络在卷积后需要经过激活过程,当前通常使用的激活函数是Relu函数。Relu函数的主要特点在之前的章节已经讲过。从函数的图像上来看,单侧抑制,相对宽阔的兴奋边界,具有稀疏激活性的特点。
在卷积层后面紧接着是一个ReLU层,主要定义了name,type,bottom,top,其属于非线性激活函数的一种,同类型的函数还有sigmoid函数,tanh函数,softplus函数等等。对于ReLU函数,其公式即为个ReLU(x)=max(0, x),而sigmoid函数为sigmoid(x)= 1/(1+e^-x),而Softplus(x)=log(1+e^x)。
然后进行池化(Pooling)操作,池化层主要用于压缩数据和参数量, 减小过拟合。简而言之,如果输入是图像的话,那么池化层的最主要作用就是压缩图像。我们在这里选择的池化策略是Max Pooling(最大池化),即选择每个小窗口
最后进行全连接(Fully-connected layer)操作,全连接层一般出现最后几步,在卷积神经网络中起到“分类器”的作用。如果说卷积层、池化层和激活函数层等操作是将原始数据映射到隐层特征空间的话,全连接层则起到将学到的“分布式特征表示”映射到样本标记空间的作用。全连接过程是对矩阵的展开过程,也可以理解为输出矩阵与一个1*1的卷积核进行卷积运算,最后展开为一个1*n的向量。在卷积神经网络中,全连接层一般使用Softmax函数来进行分类。Softmax函数适用于数据分类,用于保证每个分类概率总和为1。

为了更好地提取特征,可以用多层重复操作,这里我们也是采用了这种方式,使用了两层卷积层和池化层,每一层都是对上一层特征的提取。但这并不意味着层数越多越好,要和训练集匹配以避免过拟合。
3. 模型:
输入的数据集的格式为28*28*1,有10个类。dropout后进入第一层。
首先根据正态分布随机生成一个标准差为0.01的3*3*1*32的tensor,即用32个3*3的一层的卷积核进行2d卷积操作,其中水平滑动和垂直滑动步长值均为1,然后进行ReLU激活和最大池化。
然后对上一层进行特征提取,再卷积、ReLU、最大池化。
得到一个7*7的图片,再对其进行reshape,然后进行矩阵乘法后ReLU激活,dropout后得到一个100*256的矩阵。
W4进行矩阵乘法后得到预测值。
cost损失函数,预测值是model,标签是Y,形状都是batchsize*10,损失后求均值。
optimizer优化器学习率0.01,目标是把损失函数最小化。
初始化变量,把batchsize设置为100。
4. 运行结果:
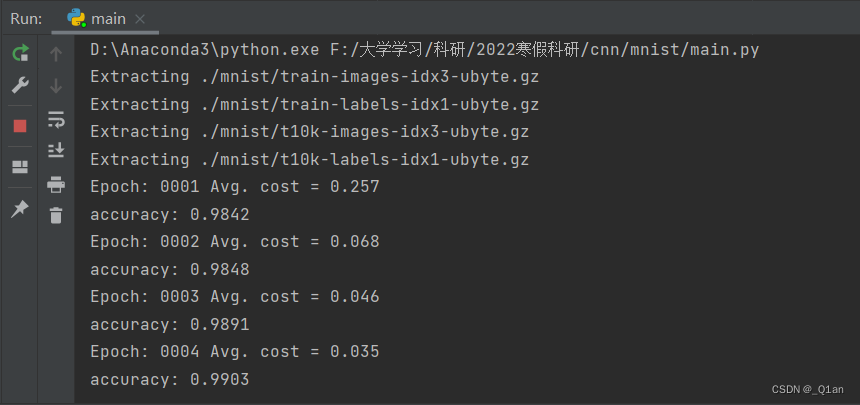
运行一遍太慢了,这里给出前四个epoch的结果
5. 更改模型
初始模型为:
W1 = tf.Variable(tf.random_normal([3, 3, 1, 32], stddev=0.01))
W2 = tf.Variable(tf.random_normal([3, 3, 32, 64], stddev=0.01))
W3 = tf.Variable(tf.random_normal([7 * 7 * 64, 256], stddev=0.01))
5.1 减少一半卷积核数量
更改后:
将32个卷积核改为16个:
W1 = tf.Variable(tf.random_normal([3, 3, 1, 16], stddev=0.01))
将64个卷积核改为32个:
W2 = tf.Variable(tf.random_normal([3, 3, 16, 32], stddev=0.01))
将256个卷积核改为128个:
W3 = tf.Variable(tf.random_normal([7 * 7 * 32, 128], stddev=0.01))
5.2 减少3/4卷积核数量
更改后:
将32个卷积核改为8个:
W1 = tf.Variable(tf.random_normal([3, 3, 1, 8], stddev=0.01))
将64个卷积核改为16个:
W2 = tf.Variable(tf.random_normal([3, 3, 8, 16], stddev=0.01))
将256个卷积核改为64个:
W3 = tf.Variable(tf.random_normal([7 * 7 * 32, 64], stddev=0.01))
5.3 增加卷积核数量,第二层由32增加为40
更改后:
W2 = tf.Variable(tf.random_normal([3, 3, 32, 40], stddev=0.01))
5.4 增加卷积核大小,第一、二层卷积核大小由3*3增加到5*5
更改后:
将卷积核大小由3*3改为5*5:
W1 = tf.Variable(tf.random_normal([5, 5, 1, 16], stddev=0.01))
将卷积核大小由3*3改为5*5:
W2 = tf.Variable(tf.random_normal([5, 5, 16, 32], stddev=0.01))
5.5 增加卷积核大小,第一、二层卷积核大小由3*3增加到7*7
更改后:
将卷积核大小由3*3改为7*7:
W1 = tf.Variable(tf.random_normal([7, 7, 1, 16], stddev=0.01))
将卷积核大小由3*3改为7*7:
W2 = tf.Variable(tf.random_normal([7, 7, 16, 32], stddev=0.01))
6. 结果及分析
6.1 初始模型
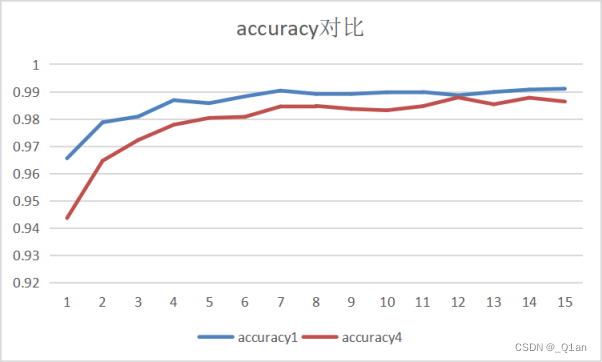
这里对初始模型进行三次学习训练:
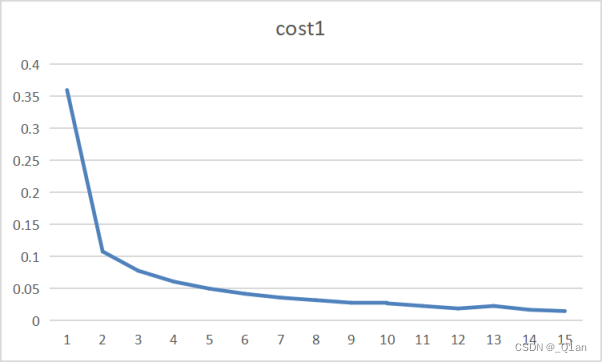
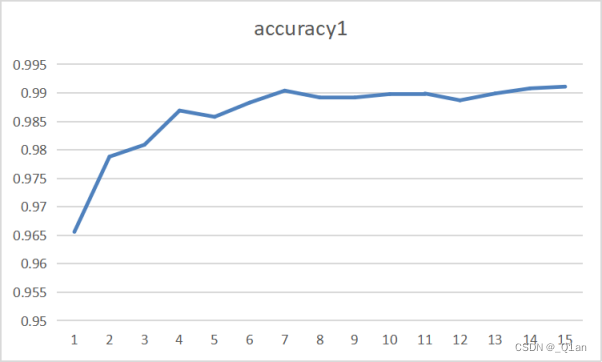
| 第一次 | epoch1 | cost1 | accuracy1 |
| 1 | 0.36 | 0.9656 | |
| 2 | 0.108 | 0.9788 | |
| 3 | 0.078 | 0.9809 | |
| 4 | 0.061 | 0.9869 | |
| 5 | 0.05 | 0.9858 | |
| 6 | 0.042 | 0.9883 | |
| 7 | 0.036 | 0.9904 | |
| 8 | 0.032 | 0.9892 | |
| 9 | 0.028 | 0.9892 | |
| 10 | 0.027 | 0.9898 | |
| 11 | 0.023 | 0.9899 | |
| 12 | 0.019 | 0.9887 | |
| 13 | 0.023 | 0.9899 | |
| 14 | 0.017 | 0.9908 | |
| 15 | 0.015 | 0.9911 |
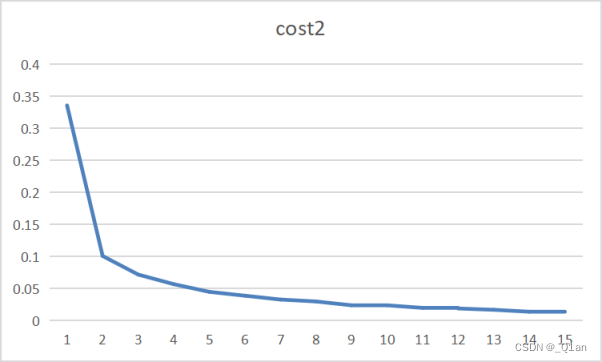
| 第二次 | epoch2 | cost2 | accuracy2 |
| 1 | 0.336 | 0.9686 | |
| 2 | 0.101 | 0.9791 | |
| 3 | 0.072 | 0.9839 | |
| 4 | 0.057 | 0.9871 | |
| 5 | 0.045 | 0.9869 | |
| 6 | 0.039 | 0.9881 | |
| 7 | 0.033 | 0.989 | |
| 8 | 0.03 | 0.989 | |
| 9 | 0.024 | 0.9895 | |
| 10 | 0.024 | 0.9898 | |
| 11 | 0.02 | 0.9895 | |
| 12 | 0.019 | 0.991 | |
| 13 | 0.017 | 0.9903 | |
| 14 | 0.014 | 0.9899 | |
| 15 | 0.015 | 0.9907 |
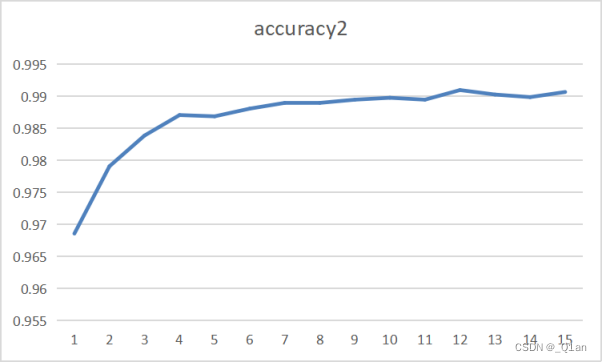
| 第三次 | epoch3 | cost3 | accuracy3 |
| 1 | 0.33 | 0.9716 | |
| 2 | 0.104 | 0.9812 | |
| 3 | 0.073 | 0.9846 | |
| 4 | 0.058 | 0.9854 | |
| 5 | 0.048 | 0.9859 | |
| 6 | 0.041 | 0.9874 | |
| 7 | 0.036 | 0.985 | |
| 8 | 0.031 | 0.9873 | |
| 9 | 0.028 | 0.9897 | |
| 10 | 0.023 | 0.9889 | |
| 11 | 0.02 | 0.989 | |
| 12 | 0.021 | 0.9902 | |
| 13 | 0.017 | 0.9911 | |
| 14 | 0.017 | 0.9903 | |
| 15 | 0.014 | 0.988 |
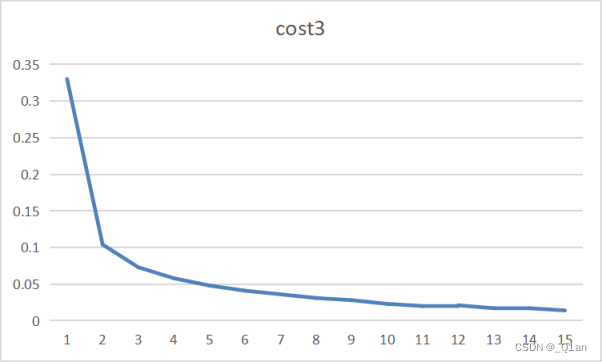
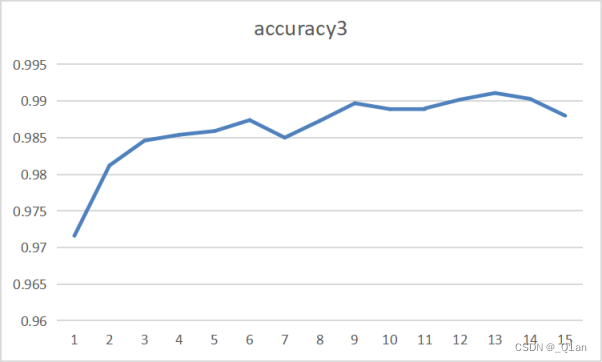
发现训练结果的accuracy可以达到0.99。
观察结果发现了一些问题,cost和accuracy在大多情况都在递增,但有时也出现了减少的情况。出现这种情况的原因猜测:
① 正常现象,数值很小,在误差范围之内
② accuracy下降/cost上升:可能出现了overfitting过拟合的情况(accuracy 是模型在数据集上基于给定 label 得到的评估结果,cost是预先设定的损失函数计算得到的损失值)
③ 为什么cost下降accuracy上升:模型调整过拟合问题,代价是cost上升
④ 我电脑问题
6.2 减少卷积核数量
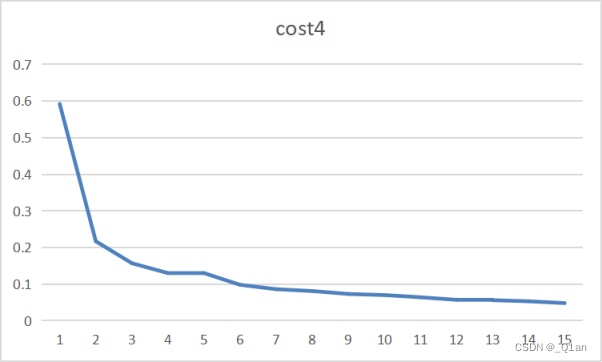
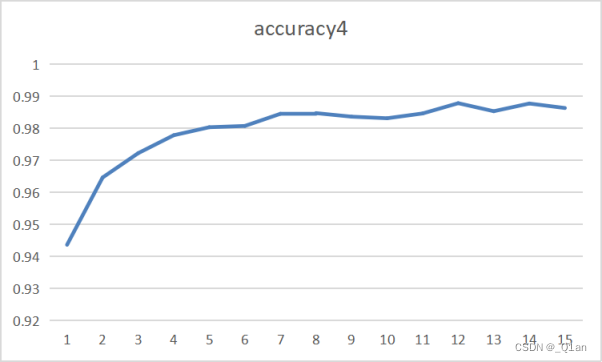
| 减少一半 | epoch4 | cost4 | accuracy4 |
| 1 | 0.592 | 0.9437 | |
| 2 | 0.217 | 0.9647 | |
| 3 | 0.157 | 0.9723 | |
| 4 | 0.13 | 0.9779 | |
| 5 | 0.13 | 0.9804 | |
| 6 | 0.098 | 0.9808 | |
| 7 | 0.086 | 0.9846 | |
| 8 | 0.081 | 0.9848 | |
| 9 | 0.073 | 0.9837 | |
| 10 | 0.07 | 0.9832 | |
| 11 | 0.064 | 0.9847 | |
| 12 | 0.057 | 0.9879 | |
| 13 | 0.056 | 0.9854 | |
| 14 | 0.053 | 0.9878 | |
| 15 | 0.048 | 0.9864 |
| 对比 | epoch1 | cost1 | accuracy1 | epoch4 | cost4 | accuracy4 |
| 1 | 0.36 | 0.9656 | 1 | 0.592 | 0.9437 | |
| 2 | 0.108 | 0.9788 | 2 | 0.217 | 0.9647 | |
| 3 | 0.078 | 0.9809 | 3 | 0.157 | 0.9723 | |
| 4 | 0.061 | 0.9869 | 4 | 0.13 | 0.9779 | |
| 5 | 0.05 | 0.9858 | 5 | 0.13 | 0.9804 | |
| 6 | 0.042 | 0.9883 | 6 | 0.098 | 0.9808 | |
| 7 | 0.036 | 0.9904 | 7 | 0.086 | 0.9846 | |
| 8 | 0.032 | 0.9892 | 8 | 0.081 | 0.9848 | |
| 9 | 0.028 | 0.9892 | 9 | 0.073 | 0.9837 | |
| 10 | 0.027 | 0.9898 | 10 | 0.07 | 0.9832 | |
| 11 | 0.023 | 0.9899 | 11 | 0.064 | 0.9847 | |
| 12 | 0.019 | 0.9887 | 12 | 0.057 | 0.9879 | |
| 13 | 0.023 | 0.9899 | 13 | 0.056 | 0.9854 | |
| 14 | 0.017 | 0.9908 | 14 | 0.053 | 0.9878 | |
| 15 | 0.015 | 0.9911 | 15 | 0.048 | 0.9864 |
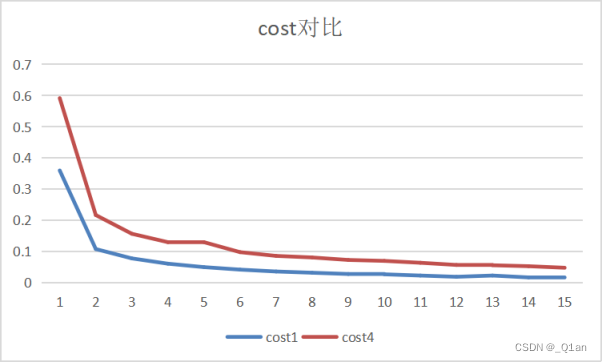
此处把每层的卷积核都减少了一半,即第一层由32减少到16,第二层由32层减少到16层,第三层由64层减少到32层,第四层由256层减少到64层。
可以明显发现,卷积核数量少时,cost和明显更高,accuracy要明显更低。
当我增加卷积核数量时,系统报错memory error,带不动程序,这里发现增加卷积核数量会对系统性能有更高的要求,同时也会增加模型精确度。
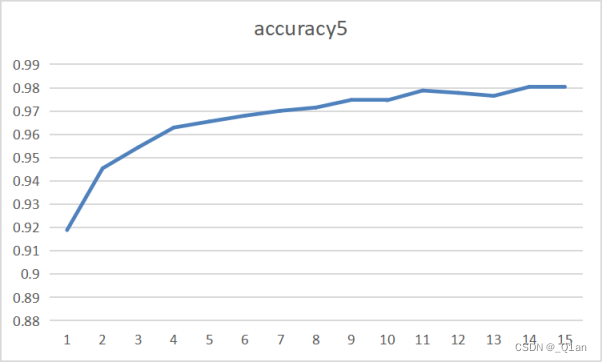
| 减少 | epoch5 | cost5 | accuracy5 |
| 1 | 0.807 | 0.9189 | |
| 2 | 0.37 | 0.9454 | |
| 3 | 0.296 | 0.9544 | |
| 4 | 0.25 | 0.9629 | |
| 5 | 0.223 | 0.9655 | |
| 6 | 0.203 | 0.968 | |
| 7 | 0.186 | 0.9701 | |
| 8 | 0.174 | 0.9715 | |
| 9 | 0.162 | 0.9748 | |
| 10 | 0.151 | 0.9746 | |
| 11 | 0.145 | 0.9788 | |
| 12 | 0.135 | 0.9778 | |
| 13 | 0.129 | 0.9765 | |
| 14 | 0.121 | 0.9804 | |
| 15 | 0.118 | 0.9807 |

| 对比 | epoch1 | cost1 | accuracy1 | enpoch4 | cost4 |
| 1 | 0.36 | 0.9656 | 1 | 0.592 | |
| 2 | 0.108 | 0.9788 | 2 | 0.217 | |
| 3 | 0.078 | 0.9809 | 3 | 0.157 | |
| 4 | 0.061 | 0.9869 | 4 | 0.13 | |
| 5 | 0.05 | 0.9858 | 5 | 0.13 | |
| 6 | 0.042 | 0.9883 | 6 | 0.098 | |
| 7 | 0.036 | 0.9904 | 7 | 0.086 | |
| 8 | 0.032 | 0.9892 | 8 | 0.081 | |
| 9 | 0.028 | 0.9892 | 9 | 0.073 | |
| 10 | 0.027 | 0.9898 | 10 | 0.07 | |
| 11 | 0.023 | 0.9899 | 11 | 0.064 | |
| 12 | 0.019 | 0.9887 | 12 | 0.057 | |
| 13 | 0.023 | 0.9899 | 13 | 0.056 | |
| 14 | 0.017 | 0.9908 | 14 | 0.053 | |
| 15 | 0.015 | 0.9911 | 15 | 0.048 | |
| accuracy4 | epoch5 | cost5 | accuracy5 | ||
| 0.9437 | 1 | 0.807 | 0.9189 | ||
| 0.9647 | 2 | 0.37 | 0.9454 | ||
| 0.9723 | 3 | 0.296 | 0.9544 | ||
| 0.9779 | 4 | 0.25 | 0.9629 | ||
| 0.9804 | 5 | 0.223 | 0.9655 | ||
| 0.9808 | 6 | 0.203 | 0.968 | ||
| 0.9846 | 7 | 0.186 | 0.9701 | ||
| 0.9848 | 8 | 0.174 | 0.9715 | ||
| 0.9837 | 9 | 0.162 | 0.9748 | ||
| 0.9832 | 10 | 0.151 | 0.9746 | ||
| 0.9847 | 11 | 0.145 | 0.9788 | ||
| 0.9879 | 12 | 0.135 | 0.9778 | ||
| 0.9854 | 13 | 0.129 | 0.9765 | ||
| 0.9878 | 14 | 0.121 | 0.9804 | ||
| 0.9864 | 15 | 0.118 | 0.9807 | ||
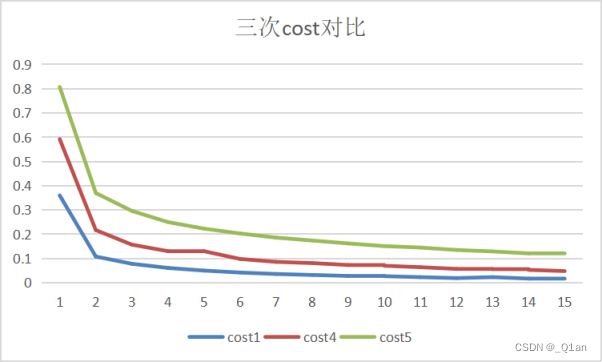
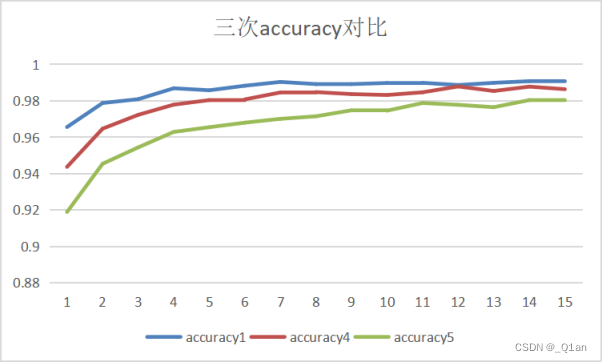
第三次卷积核数量要更少
发现第一次enpoch的cost明显更高,然后在optimizer的作用下降低
运行速度显著增快
6.3 增加卷积核数量,第二层由32增加为40
| 增加 | epoch6 | cost6 | accuracy6 |
| 1 | 0.327 | 0.9725 | |
| 2 | 0.103 | 0.9788 | |
| 3 | 0.076 | 0.9842 | |
| 4 | 0.059 | 0.9878 | |
| 5 | 0.048 | 0.9882 | |
| 6 | 0.041 | 0.9884 | |
| 7 | 0.035 | 0.9888 | |
| 8 | 0.029 | 0.9887 | |
| 9 | 0.027 | 0.9893 | |
| 10 | 0.022 | 0.9904 | |
| 11 | 0.022 | 0.9913 | |
| 12 | 0.019 | 0.9909 | |
| 13 | 0.018 | 0.9902 | |
| 14 | 0.016 | 0.9898 | |
| 15 | 0.015 | 0.9884 |


这里将第二层的卷积核数量从32改为40,没有用2的整数次幂,再多就运行不起了
发现运行速度明显变慢
| 对比 | epoch1 | cost1 | accuracy1 | epoch6 | cost6 | accuracy6 |
| 1 | 0.36 | 0.9656 | 1 | 0.327 | 0.9725 | |
| 2 | 0.108 | 0.9788 | 2 | 0.103 | 0.9788 | |
| 3 | 0.078 | 0.9809 | 3 | 0.076 | 0.9842 | |
| 4 | 0.061 | 0.9869 | 4 | 0.059 | 0.9878 | |
| 5 | 0.05 | 0.9858 | 5 | 0.048 | 0.9882 | |
| 6 | 0.042 | 0.9883 | 6 | 0.041 | 0.9884 | |
| 7 | 0.036 | 0.9904 | 7 | 0.035 | 0.9888 | |
| 8 | 0.032 | 0.9892 | 8 | 0.029 | 0.9887 | |
| 9 | 0.028 | 0.9892 | 9 | 0.027 | 0.9893 | |
| 10 | 0.027 | 0.9898 | 10 | 0.022 | 0.9904 | |
| 11 | 0.023 | 0.9899 | 11 | 0.022 | 0.9913 | |
| 12 | 0.019 | 0.9887 | 12 | 0.019 | 0.9909 | |
| 13 | 0.023 | 0.9899 | 13 | 0.018 | 0.9902 | |
| 14 | 0.017 | 0.9908 | 14 | 0.016 | 0.9898 | |
| 15 | 0.015 | 0.9911 | 15 | 0.015 | 0.9903 |
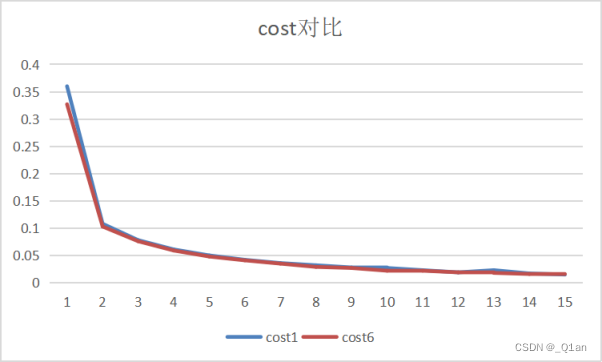

还是可以发现卷积核数量增加后cost减少、accuracy增加
6.4 增大卷积核大小
这里把第一、二层卷积核的大小从3*3改为5*5
| 增加 | epoch7 | cost7 | accuracy7 |
| 1 | 0.281 | 0.9746 | |
| 2 | 0.076 | 0.9837 | |
| 3 | 0.054 | 0.9882 | |
| 4 | 0.04 | 0.989 | |
| 5 | 0.032 | 0.99 | |
| 6 | 0.027 | 0.9921 | |
| 7 | 0.023 | 0.9922 | |
| 8 | 0.019 | 0.9907 | |
| 9 | 0.017 | 0.9895 | |
| 10 | 0.014 | 0.9923 | |
| 11 | 0.013 | 0.9918 | |
| 12 | 0.013 | 0.9903 | |
| 13 | 0.01 | 0.9932 | |
| 14 | 0.009 | 0.9926 | |
| 15 | 0.008 | 0.9931 |
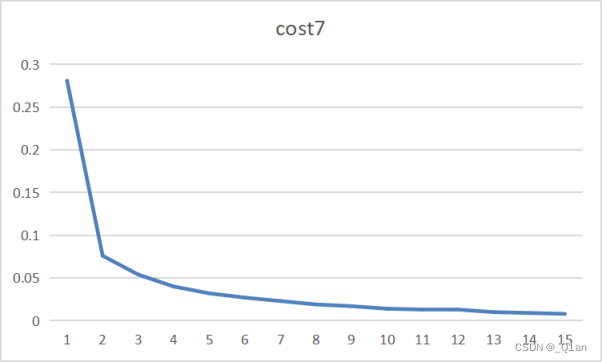
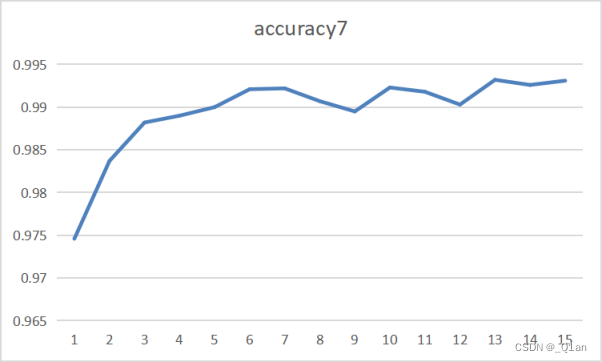
这里把第一、二层卷积核的大小从3*3改为7*7
| 增加 | epoch8 | cost8 | accuracy8 |
| 1 | 0.265 | 0.9819 | |
| 2 | 0.07 | 0.9857 | |
| 3 | 0.05 | 0.9872 | |
| 4 | 0.038 | 0.9905 | |
| 5 | 0.032 | 0.9912 | |
| 6 | 0.025 | 0.9909 | |
| 7 | 0.022 | 0.9915 | |
| 8 | 0.018 | 0.9904 | |
| 9 | 0.015 | 0.9921 | |
| 10 | 0.014 | 0.9912 | |
| 11 | 0.014 | 0.9921 | |
| 12 | 0.01 | 0.9923 | |
| 13 | 0.009 | 0.9927 | |
| 14 | 0.008 | 0.9933 | |
| 15 | 0.006 | 0.9928 |
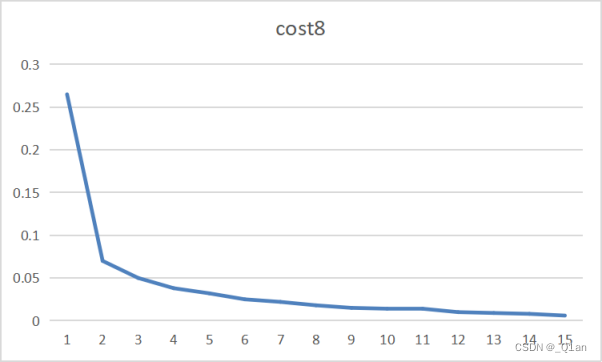
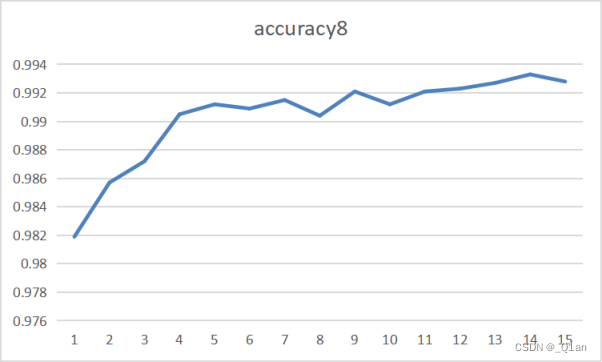
| 对比 | epoch1 | cost1 | accuracy1 | epoch7 | cost7 | accuracy7 |
| 1 | 0.36 | 0.9656 | 1 | 0.281 | 0.9746 | |
| 2 | 0.108 | 0.9788 | 2 | 0.076 | 0.9837 | |
| 3 | 0.078 | 0.9809 | 3 | 0.054 | 0.9882 | |
| 4 | 0.061 | 0.9869 | 4 | 0.04 | 0.989 | |
| 5 | 0.05 | 0.9858 | 5 | 0.032 | 0.99 | |
| 6 | 0.042 | 0.9883 | 6 | 0.027 | 0.9921 | |
| 7 | 0.036 | 0.9904 | 7 | 0.023 | 0.9922 | |
| 8 | 0.032 | 0.9892 | 8 | 0.019 | 0.9907 | |
| 9 | 0.028 | 0.9892 | 9 | 0.017 | 0.9895 | |
| 10 | 0.027 | 0.9898 | 10 | 0.014 | 0.9923 | |
| 11 | 0.023 | 0.9899 | 11 | 0.013 | 0.9918 | |
| 12 | 0.019 | 0.9887 | 12 | 0.013 | 0.9903 | |
| 13 | 0.023 | 0.9899 | 13 | 0.01 | 0.9932 | |
| 14 | 0.017 | 0.9908 | 14 | 0.009 | 0.9926 | |
| 15 | 0.015 | 0.9911 | 15 | 0.008 | 0.9931 | |
| epoch8 | cost8 | accuracy8 | ||||
| 1 | 0.265 | 0.9819 | ||||
| 2 | 0.07 | 0.9857 | ||||
| 3 | 0.05 | 0.9872 | ||||
| 4 | 0.038 | 0.9905 | ||||
| 5 | 0.032 | 0.9912 | ||||
| 6 | 0.025 | 0.9909 | ||||
| 7 | 0.022 | 0.9915 | ||||
| 8 | 0.018 | 0.9904 | ||||
| 9 | 0.015 | 0.9921 | ||||
| 10 | 0.014 | 0.9912 | ||||
| 11 | 0.014 | 0.9921 | ||||
| 12 | 0.01 | 0.9923 | ||||
| 13 | 0.009 | 0.9927 | ||||
| 14 | 0.008 | 0.9933 | ||||
| 15 | 0.006 | 0.9928 | ||||
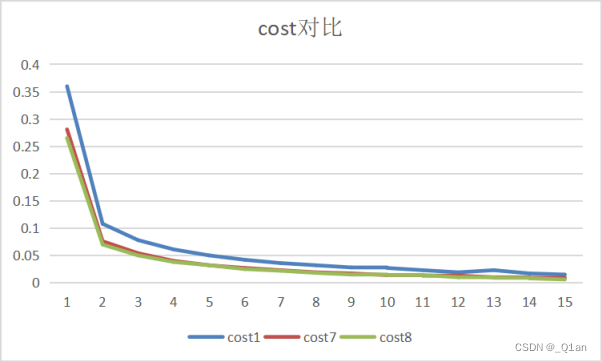
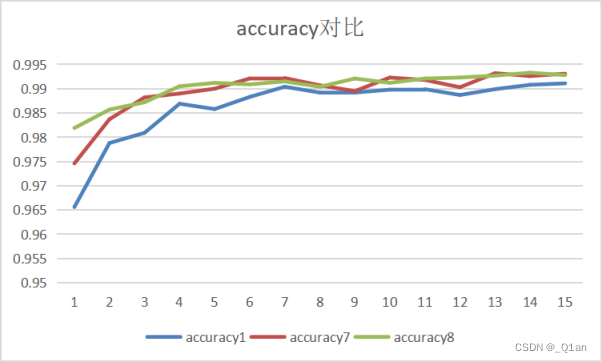
发现其它条件相同的情况下,卷积核越大,运行时间越长、cost越低、accuracy越高。
7. 思考与反思
在本次的模型训练中,我发现了以下问题,并给出了自己的解释。
① 为什么刚开始的两三个epoch的cost下降得很快?
② 为什么最后几个epoch的accuracy出现上下浮动的现象?
我猜想的答案:
① 遍历一次训练集即做一次梯度下降,找到了较为合适的损失函数的变量值。
② 损失算法有一个局部最优解,用算法去逼近这个最优解时,总会出现在最优解附近不断徘徊的情况。
在完成最后presentation后,周老师给了我一些建议,我也注意到了本次实验的一些不足:
① 没有处理更改卷积层的个数的情况。
② 有时到第15个epoch的时候,模型还没有到最优解,系统就停止训练了。
③ 科研中,模型一般只关注最后的训练结束的accuracy,不把太多精力关注在训练过程的数据上















 1436
1436











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









