







一、实验内容:
Part A Uthread: switching between threads
-
实现思路:
根据实验要求,我们可以知道应该是要在三处进行代码的添加,分别是
user/uthread.c的thread_create()和thread_schedule()以及user/uthread_switch.S中的thread_switch。在阅读了xv6 book后,得到了这样一个提示,就是内核的swtch做了上下文切换的工作,这与我们需要实现的线程切换十分相似。上下文通过结构体struct context的形式来保存寄存器的内容。对于线程的切换,我们同样需要寄存器的保存与恢复,故我们应先声明一个struct context,并在struct thread中添加一个context项。对于
thread_schedule()的添加内容,就是要调用thread_switch,但参数需要思考一下填什么,参考内核的sched函数,所以应该分别填入t和next_thread的context。填入时,注意指针的使用,同时函数参数的类型要保持一致。对于
thread_switch的添加内容,模仿swtch.S进行寄存器的保存和读取即可。对于
thread_create()的添加内容,参考allocproc,它对context的ra和rp进行了赋值。我们知道,ra是存的是PC的值,sp存的是栈顶的地址。具体到thread_create(),就是要把func函数指针(地址)赋给ra;由于栈是由高到低增长,故栈顶是stack数组最后一位的地址。 -
具体实现
user.h中声明context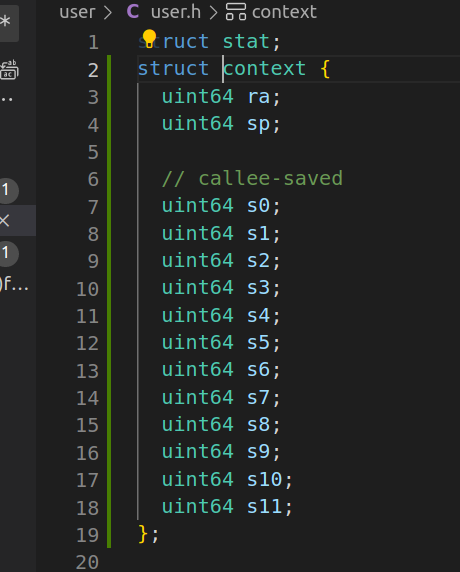
thread中添加context项,并将thread_switch的参数类型改为struct context *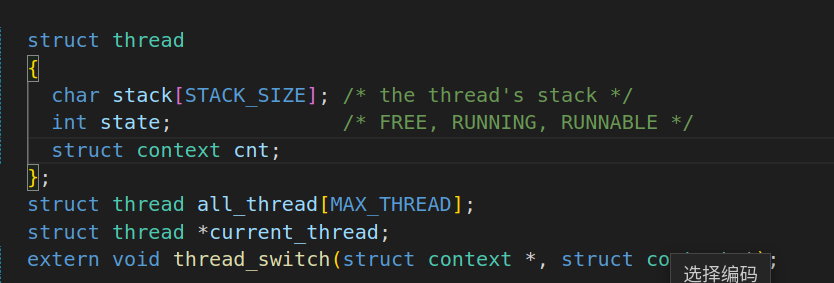
在
user/uthread_switch.S中的thread_switch进行寄存器的保存与恢复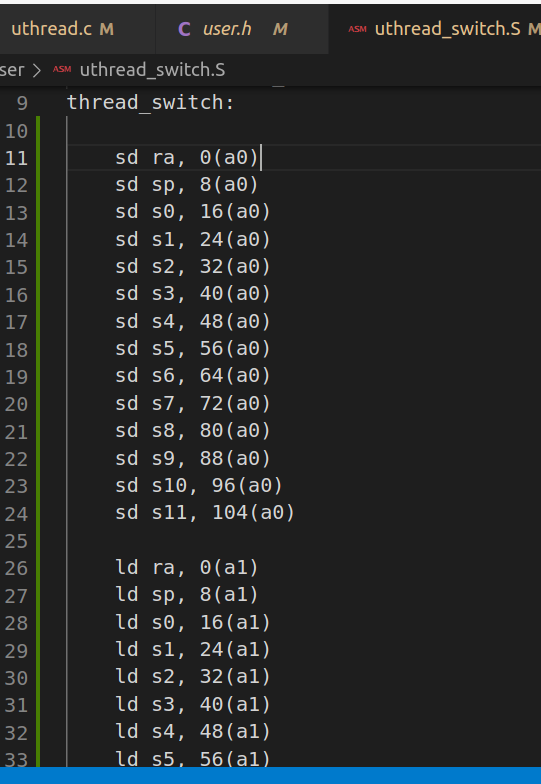
thread_create()和thread_schedule()的代码添加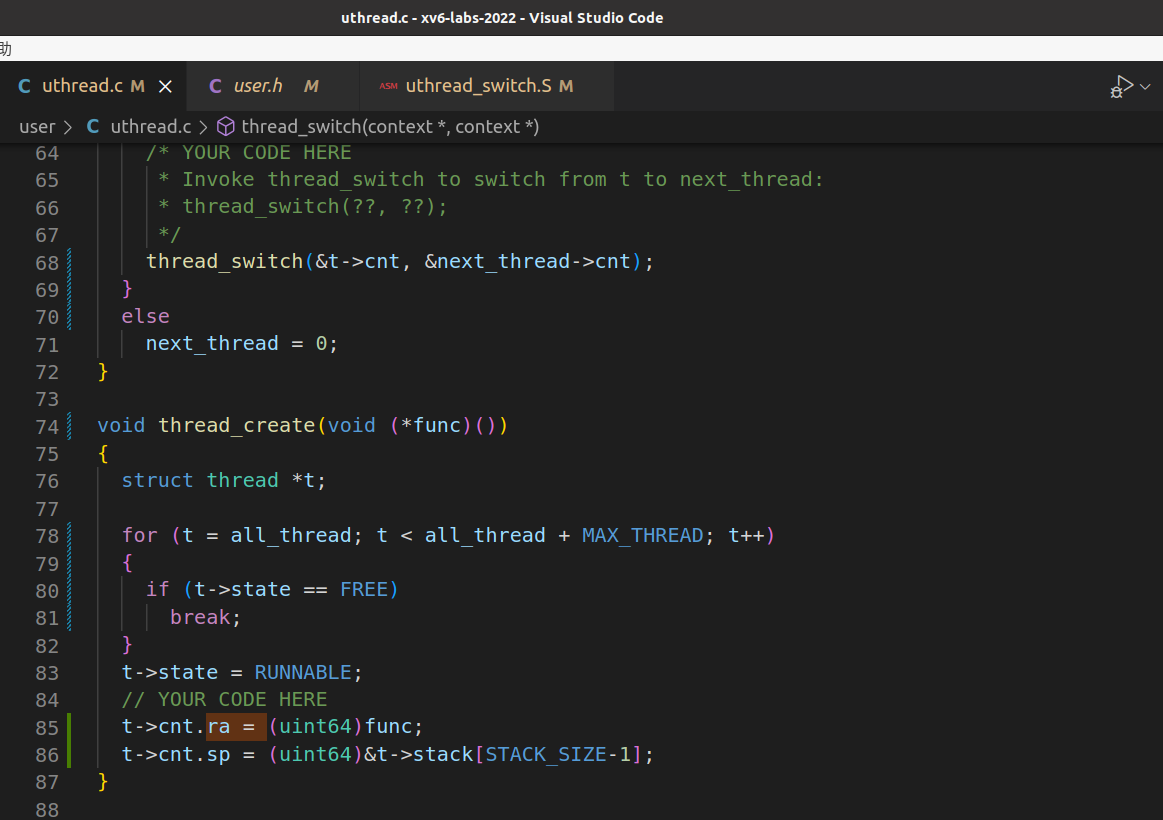
测试:
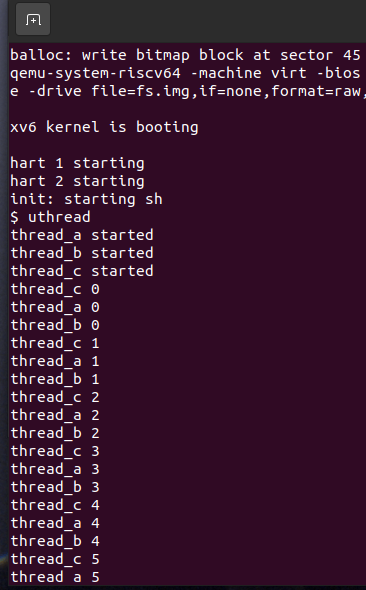
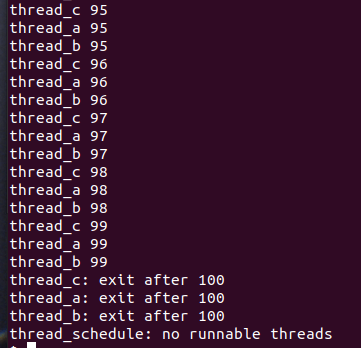
Part B Using threads
-
测试单线程
$ make ph $ ./ph 1输出结果:
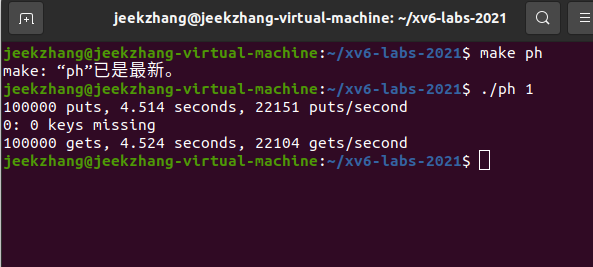
-
测试双线程
$ make ph $ ./ph 2输出结果:
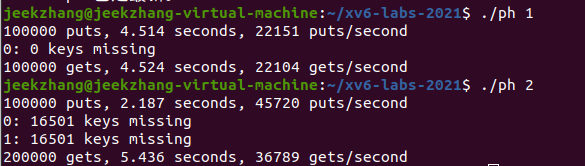
put()添加key到哈希表中,get()从哈希表中获取key,结果说明有大量的key本应在put()时被放到哈希表中却未能正确放入。
-
解决missing问题
既然是多线程导致的put()问题,应该是在线程切换中导致某些key未能正确添加,故可以在put时加入lock的机制来防止这一情况的发生。
pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER;//初始化锁 ... static void put(int key, int value) { pthread_mutex_lock(&lock);//上锁 int i = key % NBUCKET; // is the key already present? struct entry *e = 0; for (e = table[i]; e != 0; e = e->next) { if (e->key == key) break; } if(e){ // update the existing key. e->value = value; } else { // the new is new. insert(key, value, &table[i], table[i]); } pthread_mutex_unlock(&lock);//开锁 } ...再进行测试
./ph 2: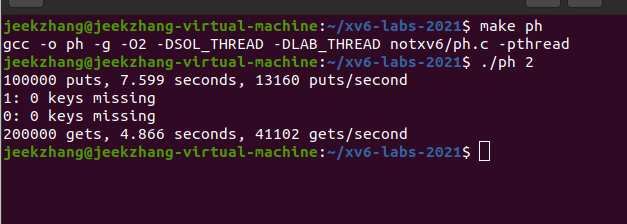
尝试
grade测试:make grade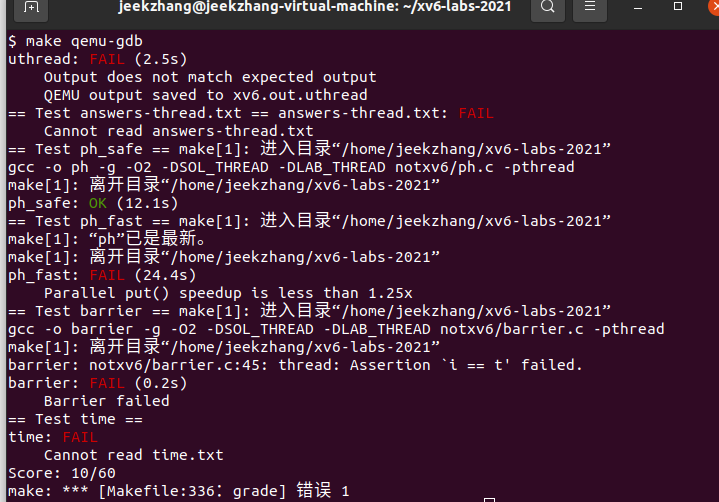
显示
ph_safe可以通过,但ph_fast不行,故需要进行改进来提高性能 -
lock改进
正如实验网站所说的,并不是所有的情况都需要上锁,或者说,不是所有的put()都应该上一把锁,只需要将可能冲突的情况用一把锁锁住即可。
恰好这里的哈希函数求了一个i值,我们可以根据不同的i值来上不同的锁
... pthread_mutex_t lock[NBUCKET]; static void put(int key, int value) { int i = key % NBUCKET; pthread_mutex_lock(&lock[i]);//上锁 // is the key already present? struct entry *e = 0; for (e = table[i]; e != 0; e = e->next) { if (e->key == key) break; } if(e){ // update the existing key. e->value = value; } else { // the new is new. insert(key, value, &table[i], table[i]); } pthread_mutex_unlock(&lock[i]);//开锁 } int main(int argc, char *argv[]) { ... for(int j=0;j<NBUCKET;j++) pthread_mutex_init(&lock[j],NULL); ... }进行测试
./ph 2: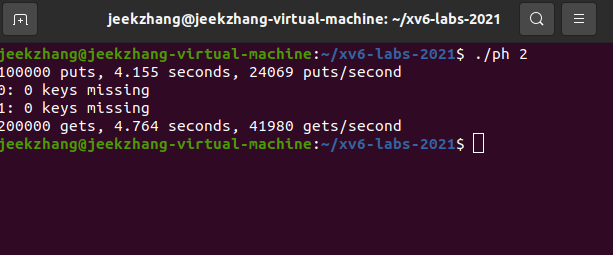
进行grade测试:
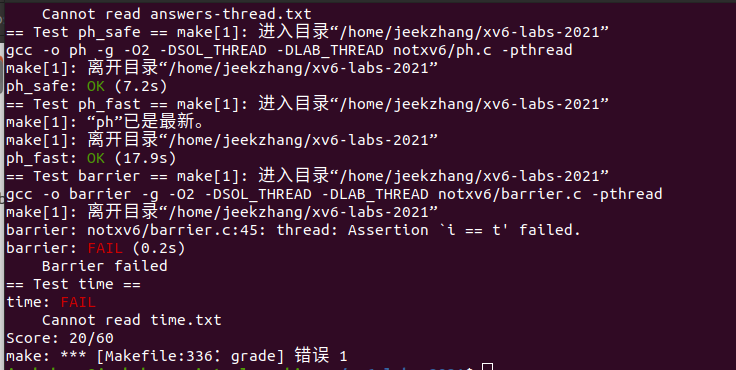
Part C Barrier
-
实现思路:
根据代码提示,只需要在barrier函数中添加内容即可。首先,因为涉及到全局变量的改变,barrier应该上一个锁,分别在前后进行lock和unlock。然后bstate.nthread++,接下来判断该值是否达到了阈值,不是则进行睡眠等待;是则要开启新的一轮,bstate.nthread置零,bstate.round++,并唤醒睡眠的线程。
-
具体实现:
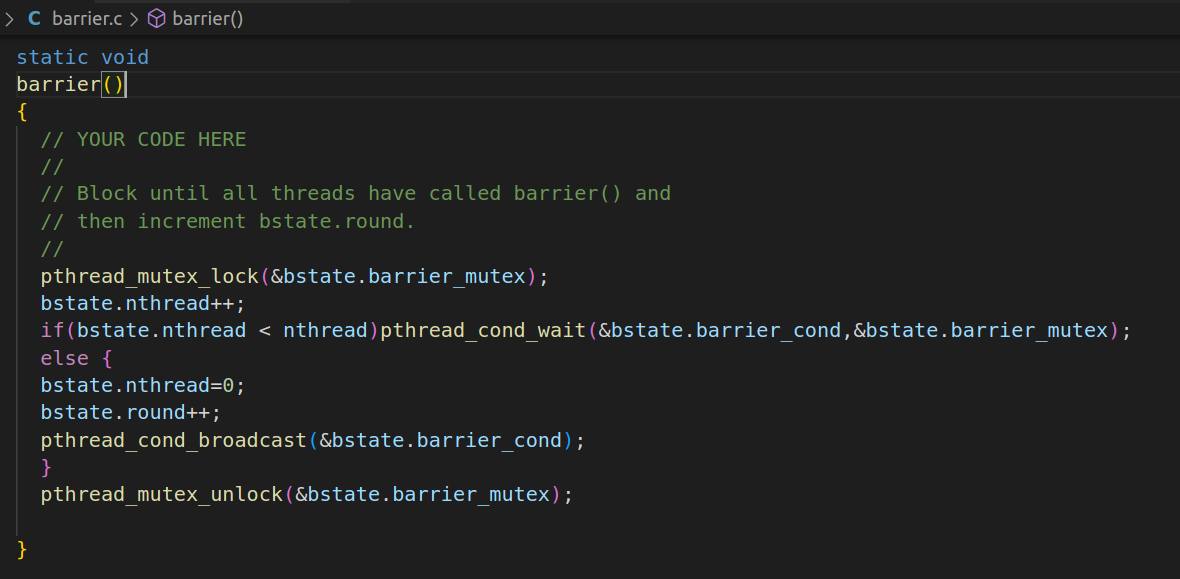
测试:

二、问题回答&实验分析:
Part A:
-
为什么
thread_switch只需要保存/恢复callee-save registers?在swtch.S中
callee-save registers的注明应该有点问题,ra和sp应该也是属于的,也就是说context的全部内容应该都是callee-save registers。callee-save,顾名思义,就是callee保存的寄存器,具体到这里就是thread_switch(),但该函数需要保存旧的、读取新的且未在其他地方保存寄存器内容,故需要对其保存/恢复。与之相对的是caller保存的寄存器(callee-save registers),后者是由调用程序自行负责保存和恢复,都会被保存在线程的堆栈上,故不需要额外的保存和恢复。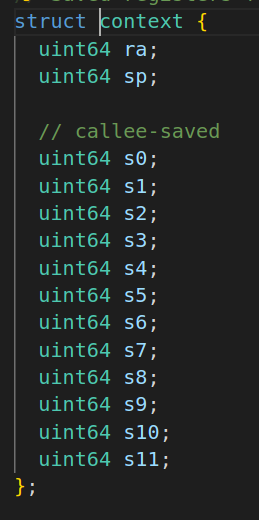

Part B:
-
为什么两个线程会丢失 keys,但是一个线程不会?确定一种两个线程的执行序列,可以使得 key 丢失。
我们先来看看put的机制:先获取当前key的hash值i,然后以此为头,查找表中是否已经有key,若是则更换;否则就要进行insert。
insert操作将key插在来最初查找开始表头的前面。
那么问题就来了,假如当key的next已经指向原head了,这时发生了线程切换,因为head还没来得及更换,新的key又指向了head,再把head替换为key,则原来的key就被丢弃了,这便导致了miss。
-
可以使用哈希值i,来上不同的锁lock[i]的原因:
相同的i值,说明会有相同的表头,会出现上述的情况,自然应该用一个锁
但不同的i值,表头不同,即使出现上述情况,也不会导致key的丢失
-
为什么不直接锁insert()?
既然问题是出在insert(),为什么不可以直接锁insert(),最开始我也是这样做的,但后面想到了这样一种情况:
如果我当前的put遍历到一半发生了切换,新线程是key与原来一样且都未添加,则此线程会将key添加到表头。再次切换后,原线程因为已经遍历过表头了,它会认为key还未添加,故又会把key加到表头,造成key的重复添加。
-
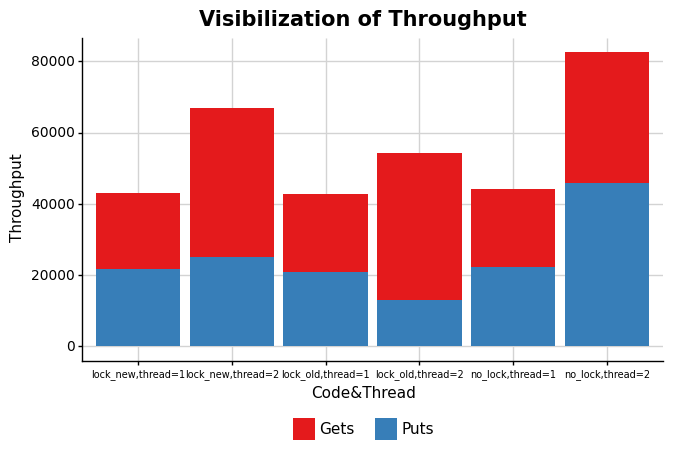
各情况下吞吐率图
Theads Code Puts(/s) Gets(/s) 1 no_lock 22151 22104 2 no_lock 45720 36789 1 lock_old 20854 22028 2 lock_old 13160 41102 1 lock_new 21641 21340 2 lock_new 24980 41980
三、问题解决:
【问题】在Part C最开始实现时,我并没有在到达阈值时将bstate.nthread直接置0,而是在退出时bstate.nthread–,这便不能过。

【分析】这正是Hits的问题所提到的,考虑这样的情况:如果达到阈值后,这一轮的线程还未退出,即bstate.nthread还没开始–。这时有一个新的线程来了,bstate.nthread此时>=nthread,会把bstate.round++,但这不是新的一轮完了。故会导致错误。
【解决】所以要让bstate.nthread和bstate.round同时发生变化,前者回到初值0,后者+1。
四、实验总结:
-
这次实验的代码因为有部分内容已经在之前的作业中做了,工作量有所减轻,但重新看这次,会对以前有些地方的实现有了一些新的理解。
-
相比于书上和课上直接给到的知识,实操起来真的会有更大收获。比如课上以count为例讲临界区,因为是直接就告诉你是怎么回事了,只需要去理解这个过程就可以了,但实验中具体的代码就需要自己去寻找出错的条件,对lock的机制掌握自然也就更深入了。
-
另外,这学期学的“计算机可视化”没想到在这里吞吐量的绘图发挥了用处,也算是某种意义上的学科交叉了。
五、实验参考及git地址:














 420
420











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









