







本文章是做为记录面经,方便后期自己查阅,取自于牛客网面经。
目录
1.说一说hash类型底层的数据结构
哈希对象有两种编码方案,当同时满足以下条件时,哈希对象采用ziplist编码,否则采用hashtable编码:
-
哈希对象保存的键值对数量小于512个;
-
哈希对象保存的所有键值对中的键和值,其字符串长度都小于64字节。
其中,ziplist编码采用压缩列表作为底层实现,而hashtable编码采用字典作为底层实现。
压缩列表:
压缩列表(ziplist),是Redis为了节约内存而设计的一种线性数据结构,它是由一系列具有特殊编码的连续内存块构成的。一个压缩列表可以包含任意多个节点,每个节点可以保存一个字节数组或一个整数值。
压缩列表的结构如下图所示:

该结构当中的字段含义如下表所示:
| 属性 | 类型 | 长度 | 说明 |
|---|---|---|---|
| zlbytes | uint32_t | 4字节 | 压缩列表占用的内存字节数; |
| zltail | uint32_t | 4字节 | 压缩列表表尾节点距离列表起始地址的偏移量(单位字节); |
| zllen | uint16_t | 2字节 | 压缩列表包含的节点数量,等于UINT16_MAX时,需遍历列表计算真实数量; |
| entryX | 列表节点 | 不固定 | 压缩列表包含的节点,节点的长度由节点所保存的内容决定; |
| zlend | uint8_t | 1字节 | 压缩列表的结尾标识,是一个固定值0xFF; |
其中,压缩列表的节点由以下字段构成:

previous_entry_length(pel)属性以字节为单位,记录当前节点的前一节点的长度,其自身占据1字节或5字节:
-
如果前一节点的长度小于254字节,则“pel”属性的长度为1字节,前一节点的长度就保存在这一个字节内;
-
如果前一节点的长度达到254字节,则“pel”属性的长度为5字节,其中第一个字节被设置为0xFE,之后的四个字节用来保存前一节点的长度;
基于“pel”属性,程序便可以通过指针运算,根据当前节点的起始地址计算出前一节点的起始地址,从而实现从表尾向表头的遍历操作。
content属性负责保存节点的值(字节数组或整数),其类型和长度则由encoding属性决定,它们的关系如下:
| encoding | 长度 | content |
|---|---|---|
| 00 xxxxxx | 1字节 | 最大长度为26 -1的字节数组; |
| 01 xxxxxx bbbbbbbb | 2字节 | 最大长度为214-1的字节数组; |
| 10 __ bbbbbbbb ... ... ... | 5字节 | 最大长度为232-1的字节数组; |
| 11 000000 | 1字节 | int16_t类型的整数; |
| 11 010000 | 1字节 | int32_t类型的整数; |
| 11 100000 | 1字节 | int64_t类型的整数; |
| 11 110000 | 1字节 | 24位有符号整数; |
| 11 111110 | 1字节 | 8位有符号整数; |
| 11 11xxxx | 1字节 | 没有content属性,xxxx直接存[0,12]范围的整数值; |
字典:
字典(dict)又称为散列表,是一种用来存储键值对的数据结构。C语言没有内置这种数据结构,所以Redis构建了自己的字典实现。
Redis字典的实现主要涉及三个结构体:字典、哈希表、哈希表节点。其中,每个哈希表节点保存一个键值对,每个哈希表由多个哈希表节点构成,而字典则是对哈希表的进一步封装。这三个结构体的关系如下图所示:
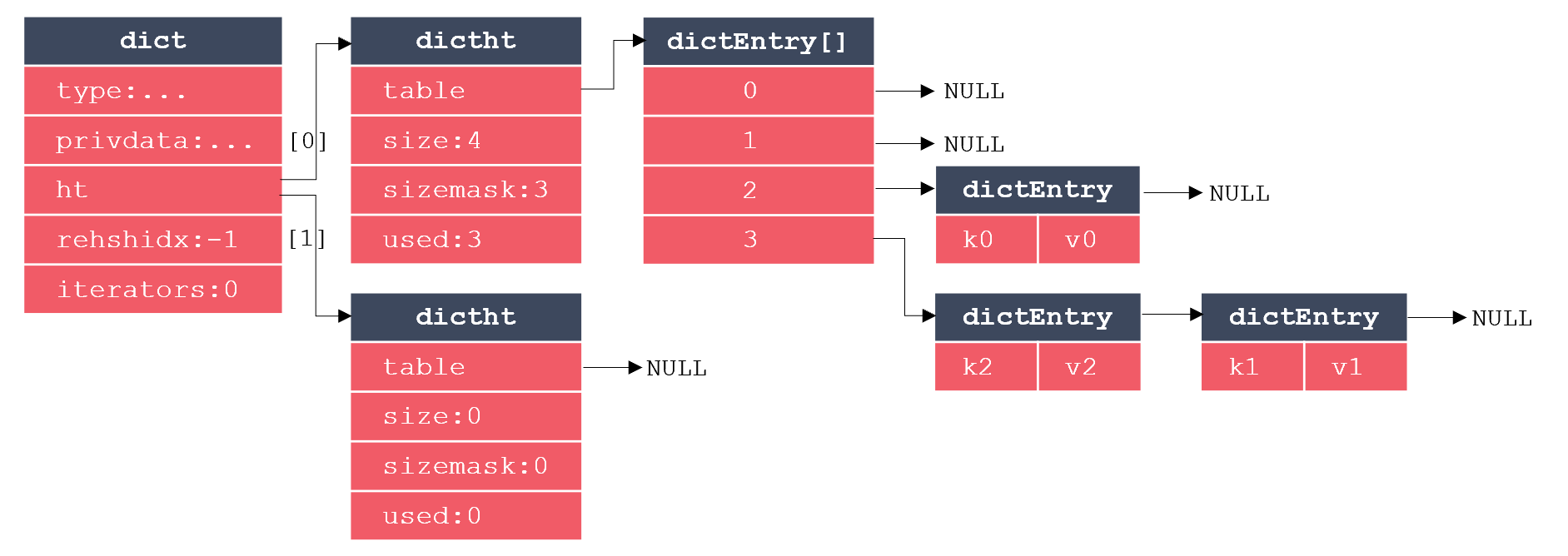
其中,dict代表字典,dictht代表哈希表,dictEntry代表哈希表节点。可以看出,dictEntry是一个数组,这很好理解,因为一个哈希表里要包含多个哈希表节点。而dict里包含2个dictht,多出的哈希表用于REHASH。当哈希表保存的键值对数量过多或过少时,需要对哈希表的大小进行扩展或收缩操作,在Redis中,扩展和收缩哈希表是通过REHASH实现的,执行REHASH的大致步骤如下:
-
为字典的ht[1]哈希表分配内存空间
如果执行的是扩展操作,则ht[1]的大小为第1个大于等于ht[0].used*2的2n。如果执行的是收缩操作,则ht[1]的大小为第1个大于等于ht[0].used的2n。
-
将存储在ht[0]中的数据迁移到ht[1]上
重新计算键的哈希值和索引值,然后将键值对放置到ht[1]哈希表的指定位置上。
-
将字典的ht[1]哈希表晋升为默认哈希表
迁移完成后,清空ht[0],再交换ht[0]和ht[1]的值,为下一次REHASH做准备。
当满足以下任何一个条件时,程序会自动开始对哈希表执行扩展操作:
-
服务器目前没有执行bgsave或bgrewriteof命令,并且哈希表的负载因子大于等于1;
-
服务器目前正在执行bgsave或bgrewriteof命令,并且哈希表的负载因子大于等于5。
为了避免REHASH对服务器性能造成影响,REHASH操作不是一次性地完成的,而是分多次、渐进式地完成的。渐进式REHASH的详细过程如下:
-
为ht[1]分配空间,让字典同时持有ht[0]和ht[1]两个哈希表;
-
在字典中的索引计数器rehashidx设置为0,表示REHASH操作正式开始;
-
在REHASH期间,每次对字典执行添加、删除、修改、查找操作时,程序除了执行指定的操作外,还会顺带将ht[0]中位于rehashidx上的所有键值对迁移到ht[1]中,再将rehashidx的值加1;
-
随着字典不断被访问,最终在某个时刻,ht[0]上的所有键值对都被迁移到ht[1]上,此时程序将rehashidx属性值设置为-1,标识REHASH操作完成。
REHSH期间,字典同时持有两个哈希表,此时的访问将按照如下原则处理:
-
新添加的键值对,一律被保存到ht[1]中;
-
删除、修改、查找等其他操作,会在两个哈希表上进行,即程序先尝试去ht[0]中访问要操作的数据,若不存在则到ht[1]中访问,再对访问到的数据做相应的处理。
2.介绍一下zset类型底层的数据结构
有序集合对象有2种编码方案,当同时满足以下条件时,集合对象采用ziplist编码,否则采用skiplist编码:
-
有序集合保存的元素数量不超过128个;
-
有序集合保存的所有元素的成员长度都小于64字节。
其中,ziplist编码的有序集合采用压缩列表作为底层实现,skiplist编码的有序集合采用zset结构作为底层实现。
其中,zset是一个复合结构,它的内部采用字典和跳跃表来实现,其源码如下。其中,dict保存了从成员到分支的映射关系,zsl则按分值由小到大保存了所有的集合元素。这样,当按照成员来访问有序集合时可以直接从dict中取值,当按照分值的范围访问有序集合时可以直接从zsl中取值,采用了空间换时间的策略以提高访问效率。
typedef struct zset { dict *dict; // 字典,保存了从成员到分值的映射关系; zskiplist *zsl; // 跳跃表,按分值由小到大保存所有集合元素; } zset;综上,zset对象的底层数据结构包括:压缩列表、字典、跳跃表。
压缩列表:
压缩列表(ziplist),是Redis为了节约内存而设计的一种线性数据结构,它是由一系列具有特殊编码的连续内存块构成的。一个压缩列表可以包含任意多个节点,每个节点可以保存一个字节数组或一个整数值。
压缩列表的结构如下图所示:

该结构当中的字段含义如下表所示:
| 属性 | 类型 | 长度 | 说明 |
|---|---|---|---|
| zlbytes | uint32_t | 4字节 | 压缩列表占用的内存字节数; |
| zltail | uint32_t | 4字节 | 压缩列表表尾节点距离列表起始地址的偏移量(单位字节); |
| zllen | uint16_t | 2字节 | 压缩列表包含的节点数量,等于UINT16_MAX时,需遍历列表计算真实数量; |
| entryX | 列表节点 | 不固定 | 压缩列表包含的节点,节点的长度由节点所保存的内容决定; |
| zlend | uint8_t | 1字节 | 压缩列表的结尾标识,是一个固定值0xFF; |
其中,压缩列表的节点由以下字段构成:

previous_entry_length(pel)属性以字节为单位,记录当前节点的前一节点的长度,其自身占据1字节或5字节:
-
如果前一节点的长度小于254字节,则“pel”属性的长度为1字节,前一节点的长度就保存在这一个字节内;
-
如果前一节点的长度达到254字节,则“pel”属性的长度为5字节,其中第一个字节被设置为0xFE,之后的四个字节用来保存前一节点的长度;
基于“pel”属性,程序便可以通过指针运算,根据当前节点的起始地址计算出前一节点的起始地址,从而实现从表尾向表头的遍历操作。
content属性负责保存节点的值(字节数组或整数),其类型和长度则由encoding属性决定,它们的关系如下:
| encoding | 长度 | content |
|---|---|---|
| 00 xxxxxx | 1字节 | 最大长度为26 -1的字节数组; |
| 01 xxxxxx bbbbbbbb | 2字节 | 最大长度为214-1的字节数组; |
| 10 __ bbbbbbbb ... ... ... | 5字节 | 最大长度为232-1的字节数组; |
| 11 000000 | 1字节 | int16_t类型的整数; |
| 11 010000 | 1字节 | int32_t类型的整数; |
| 11 100000 | 1字节 | int64_t类型的整数; |
| 11 110000 | 1字节 | 24位有符号整数; |
| 11 111110 | 1字节 | 8位有符号整数; |
| 11 11xxxx | 1字节 | 没有content属性,xxxx直接存[0,12]范围的整数值; |
字典:
字典(dict)又称为散列表,是一种用来存储键值对的数据结构。C语言没有内置这种数据结构,所以Redis构建了自己的字典实现。
Redis字典的实现主要涉及三个结构体:字典、哈希表、哈希表节点。其中,每个哈希表节点保存一个键值对,每个哈希表由多个哈希表节点构成,而字典则是对哈希表的进一步封装。这三个结构体的关系如下图所示:
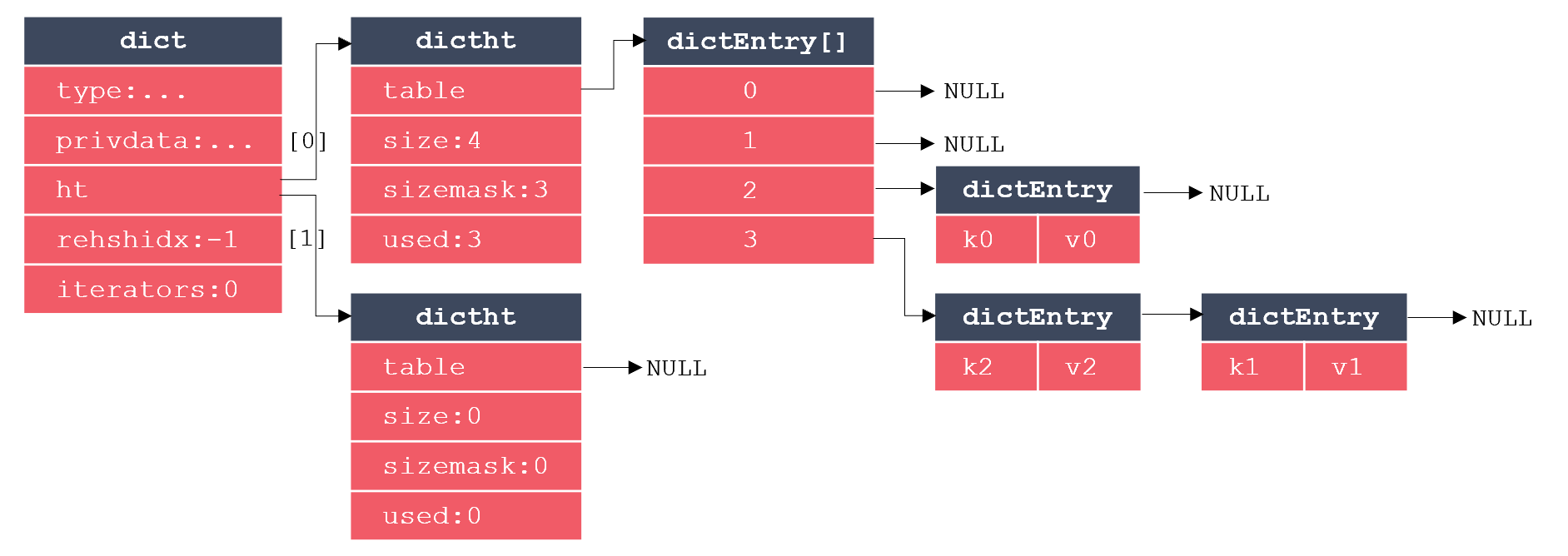
其中,dict代表字典,dictht代表哈希表,dictEntry代表哈希表节点。可以看出,dictEntry是一个数组,这很好理解,因为一个哈希表里要包含多个哈希表节点。而dict里包含2个dictht,多出的哈希表用于REHASH。当哈希表保存的键值对数量过多或过少时,需要对哈希表的大小进行扩展或收缩操作,在Redis中,扩展和收缩哈希表是通过REHASH实现的,执行REHASH的大致步骤如下:
-
为字典的ht[1]哈希表分配内存空间
如果执行的是扩展操作,则ht[1]的大小为第1个大于等于ht[0].used*2的2n。如果执行的是收缩操作,则ht[1]的大小为第1个大于等于ht[0].used的2n。
-
将存储在ht[0]中的数据迁移到ht[1]上
重新计算键的哈希值和索引值,然后将键值对放置到ht[1]哈希表的指定位置上。
-
将字典的ht[1]哈希表晋升为默认哈希表
迁移完成后,清空ht[0],再交换ht[0]和ht[1]的值,为下一次REHASH做准备。
当满足以下任何一个条件时,程序会自动开始对哈希表执行扩展操作:
-
服务器目前没有执行bgsave或bgrewriteof命令,并且哈希表的负载因子大于等于1;
-
服务器目前正在执行bgsave或bgrewriteof命令,并且哈希表的负载因子大于等于5。
为了避免REHASH对服务器性能造成影响,REHASH操作不是一次性地完成的,而是分多次、渐进式地完成的。渐进式REHASH的详细过程如下:
-
为ht[1]分配空间,让字典同时持有ht[0]和ht[1]两个哈希表;
-
在字典中的索引计数器rehashidx设置为0,表示REHASH操作正式开始;
-
在REHASH期间,每次对字典执行添加、删除、修改、查找操作时,程序除了执行指定的操作外,还会顺带将ht[0]中位于rehashidx上的所有键值对迁移到ht[1]中,再将rehashidx的值加1;
-
随着字典不断被访问,最终在某个时刻,ht[0]上的所有键值对都被迁移到ht[1]上,此时程序将rehashidx属性值设置为-1,标识REHASH操作完成。
REHSH期间,字典同时持有两个哈希表,此时的访问将按照如下原则处理:
-
新添加的键值对,一律被保存到ht[1]中;
-
删除、修改、查找等其他操作,会在两个哈希表上进行,即程序先尝试去ht[0]中访问要操作的数据,若不存在则到ht[1]中访问,再对访问到的数据做相应的处理。
跳跃表:
跳跃表的查找复杂度为平均O(logN),最坏O(N),效率堪比红黑树,却远比红黑树实现简单。跳跃表是在链表的基础上,通过增加索引来提高查找效率的。
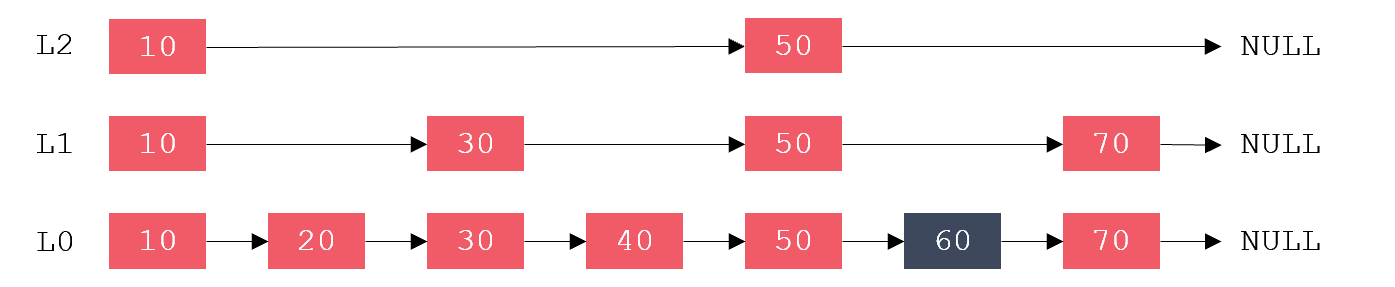
有序链表插入、删除的复杂度为O(1),而查找的复杂度为O(N)。例:若要查找值为60的元素,需要从第1个元素依次向后比较,共需比较6次才行,如下图:

跳跃表是从有序链表中选取部分节点,组成一个新链表,并以此作为原始链表的一级索引。再从一级索引中选取部分节点,组成一个新链表,并以此作为原始链表的二级索引。以此类推,可以有多级索引,如下图:
跳跃表在查找时,优先从高层开始查找,若next节点值大于目标值,或next指针指向NULL,则从当前节点下降一层继续向后查找,这样便可以提高查找的效率了。
跳跃表的实现主要涉及2个结构体:zskiplist、zskiplistNode,它们的关系如下图所示:
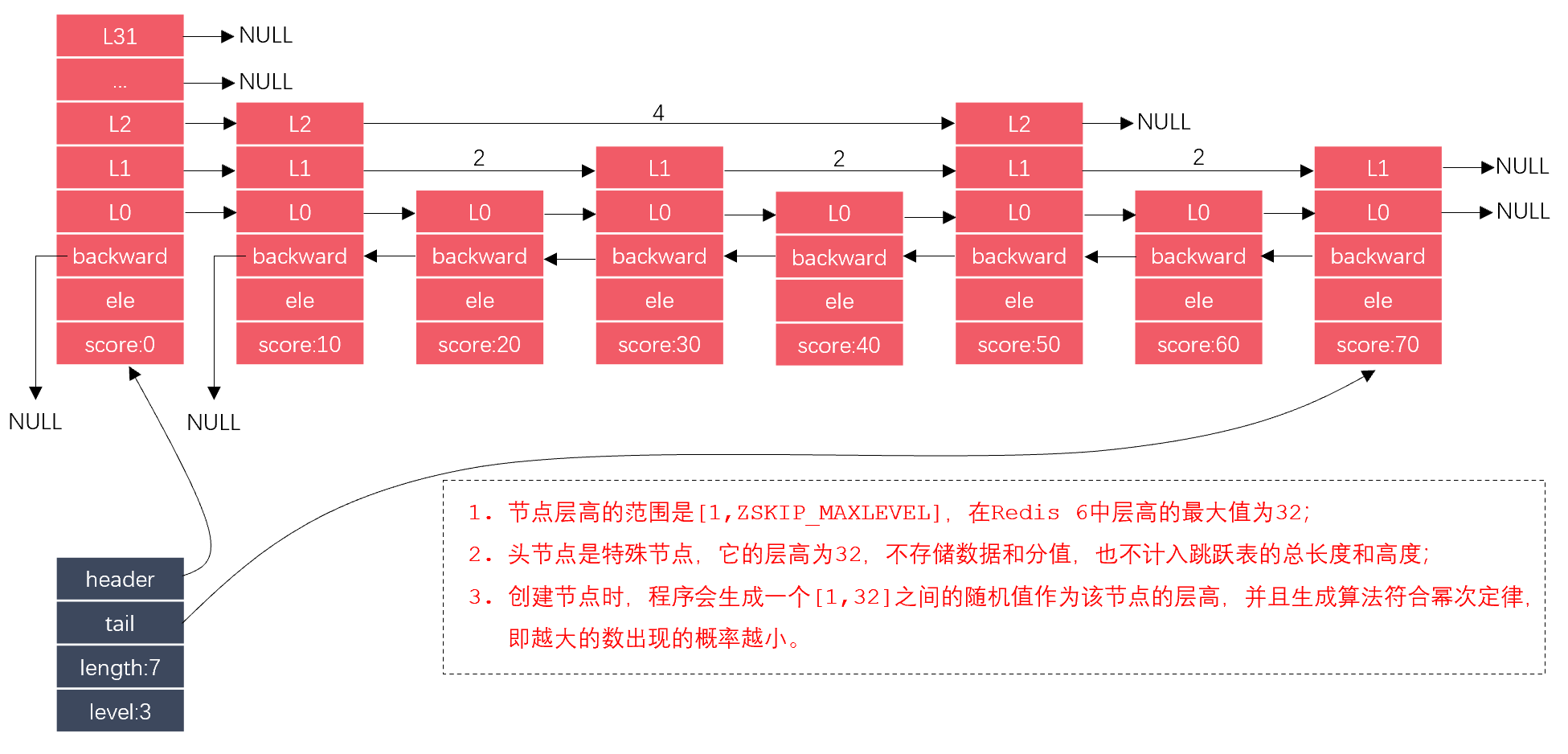
其中,蓝色的表格代表zskiplist,红色的表格代表zskiplistNode。zskiplist有指向头尾节点的指针,以及列表的长度,列表中最高的层级。zskiplistNode的头节点是空的,它不存储任何真实的数据,它拥有最高的层级,但这个层级不记录在zskiplist之内。















 675
675











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









