






码上爬-第7&8题
靶场地址:
js加密 & js混淆
题七:千山鸟飞绝
打开控制台有无限debugger
找了个油猴插件hook掉: remove-debugger
查看接口调用堆栈的 pagenation.js文件, 已经被混淆
全部复制找个解混淆的网站尝试还原一下
还原后替换原有混淆的js文件
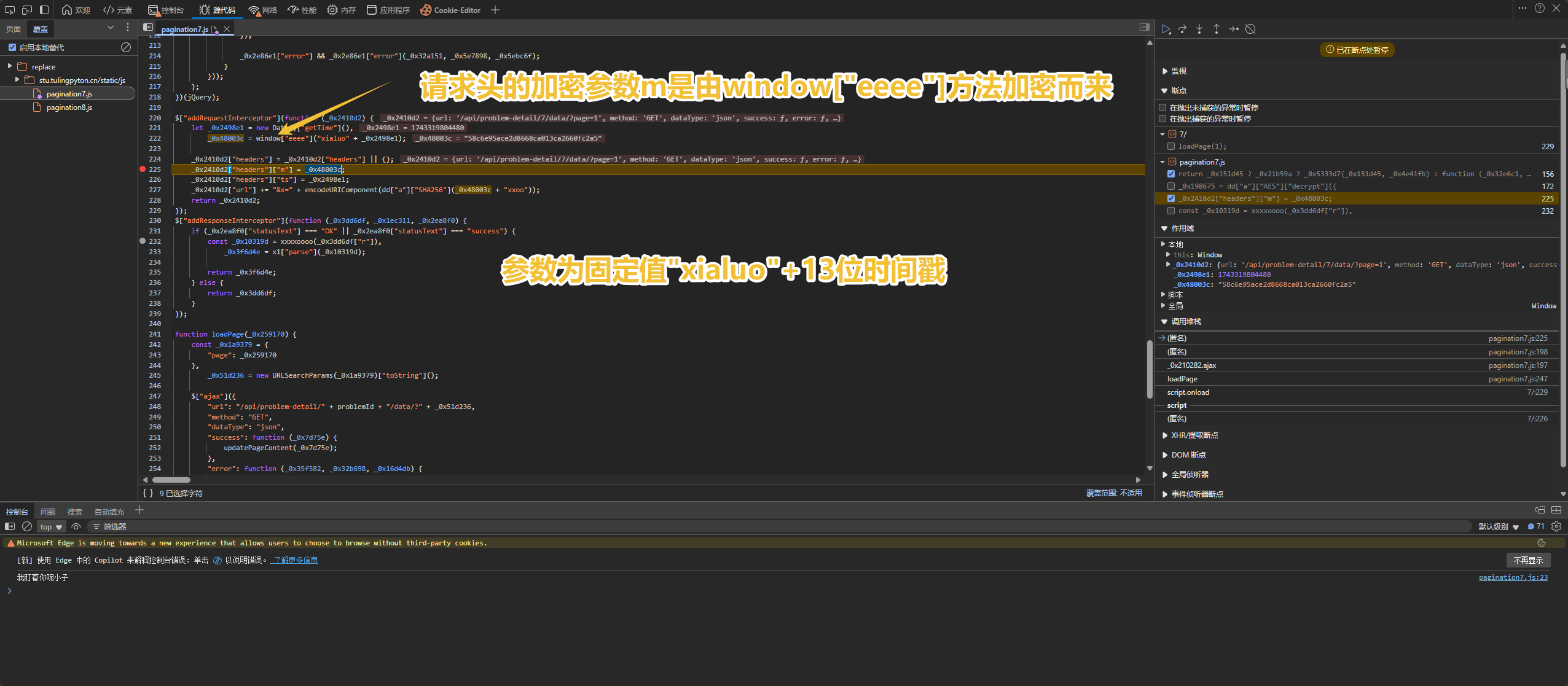
可以看到, param参数的x为请求头的参数m+固定值"xxoo" , 经过SHA256算法得到
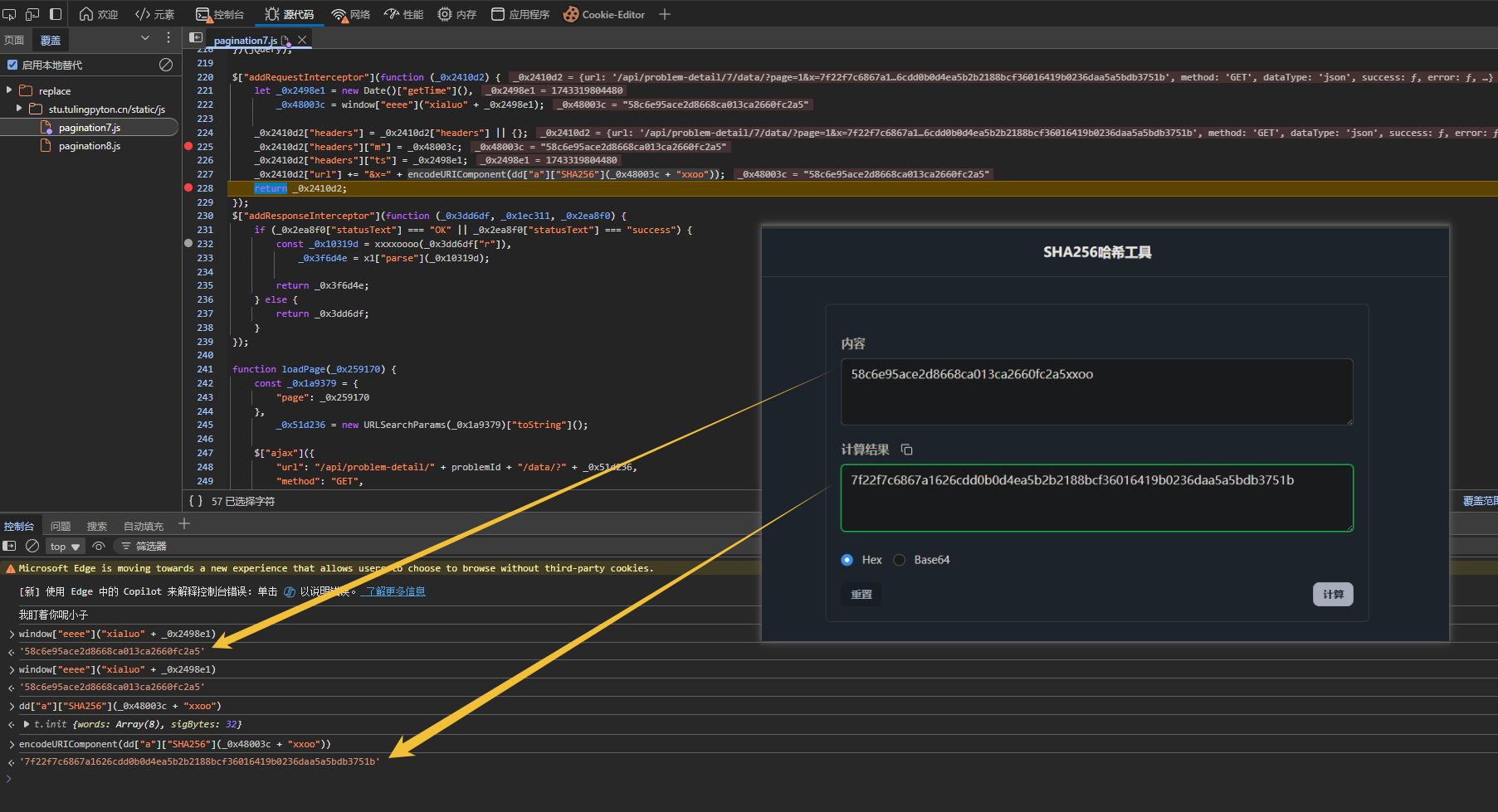
验证SHA256算法: SHA256 - 在线工具
也就是只要确定了方法 window["eeee"] 的算法后, 参数m,x都出来了
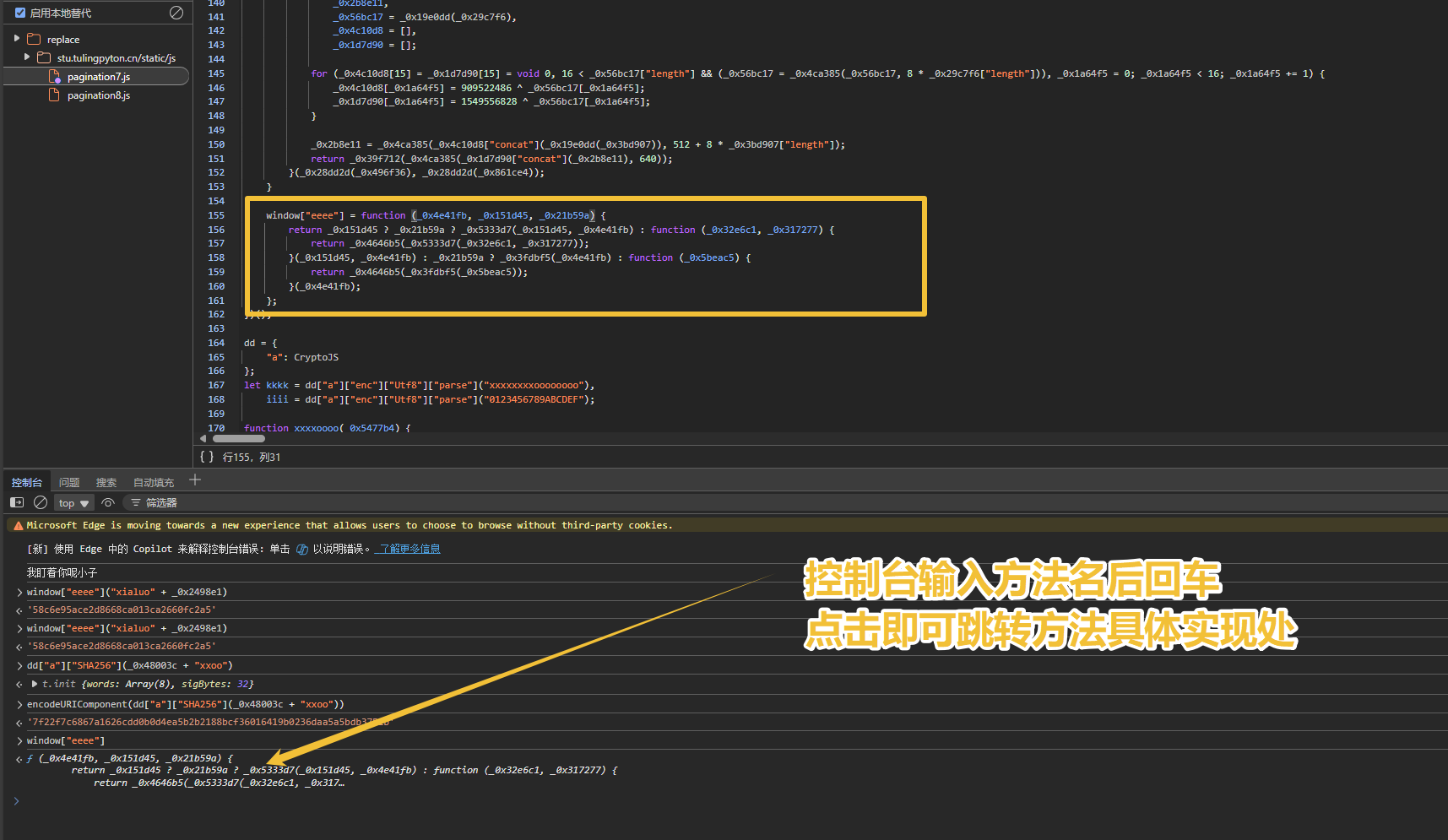
正好看到AES的解密, 猜测应该是响应的解密, 验证一下; 证明确实对的, 这样解密算法也出来了, 就只剩eeee方法的实现了
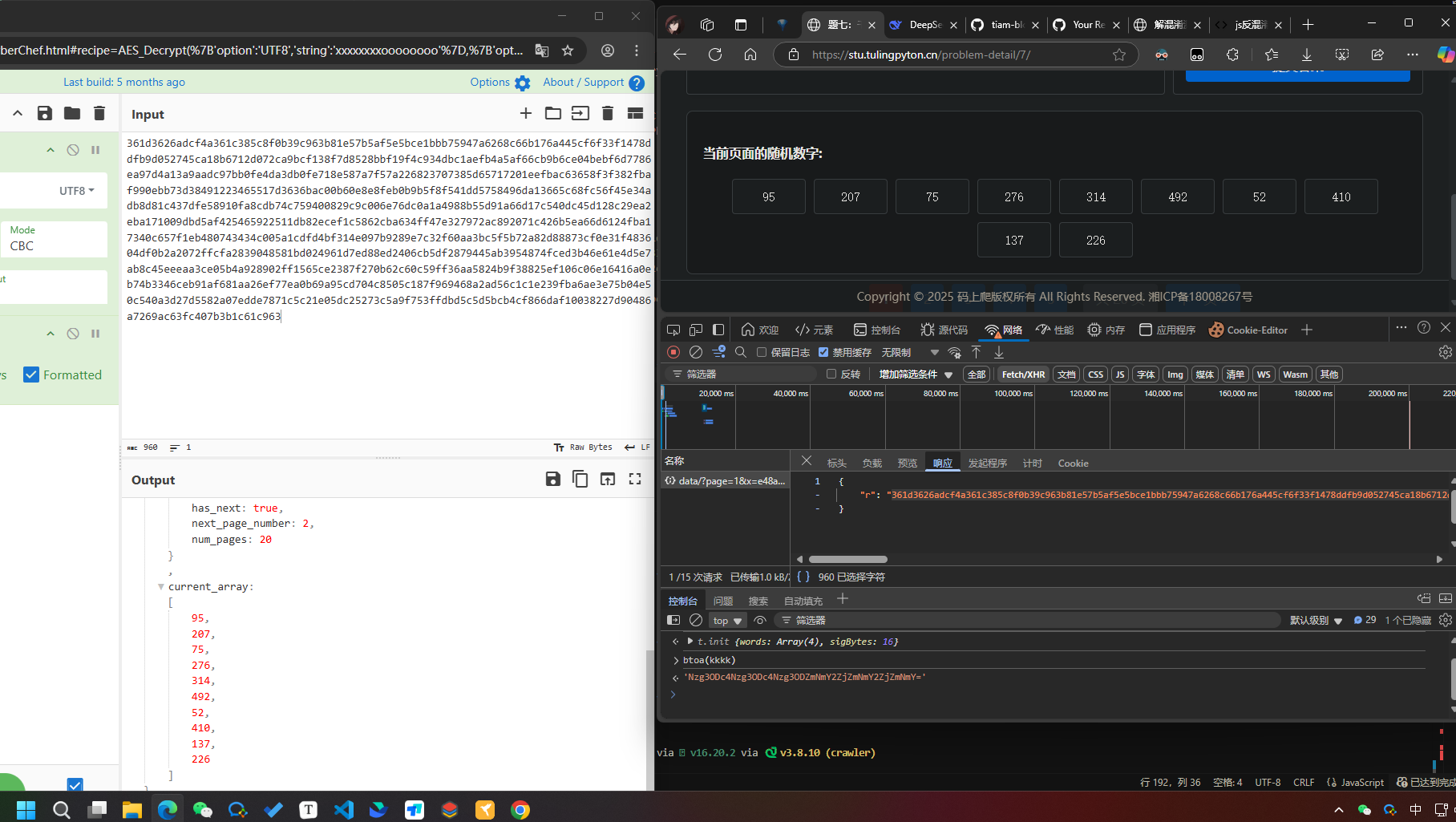
由于eeee方法还调用了很多其他方法和变量, 需要一个一个补; 为了省事, 直接把整个解混淆后的js拿过来修改 尝试直接调用eeee方法
取消 IIFE(Immediately Invoked Function Expression,立即调用函数表达式)的独立作用域, 可以直接在外部调用, 或者在独立作用域内调用
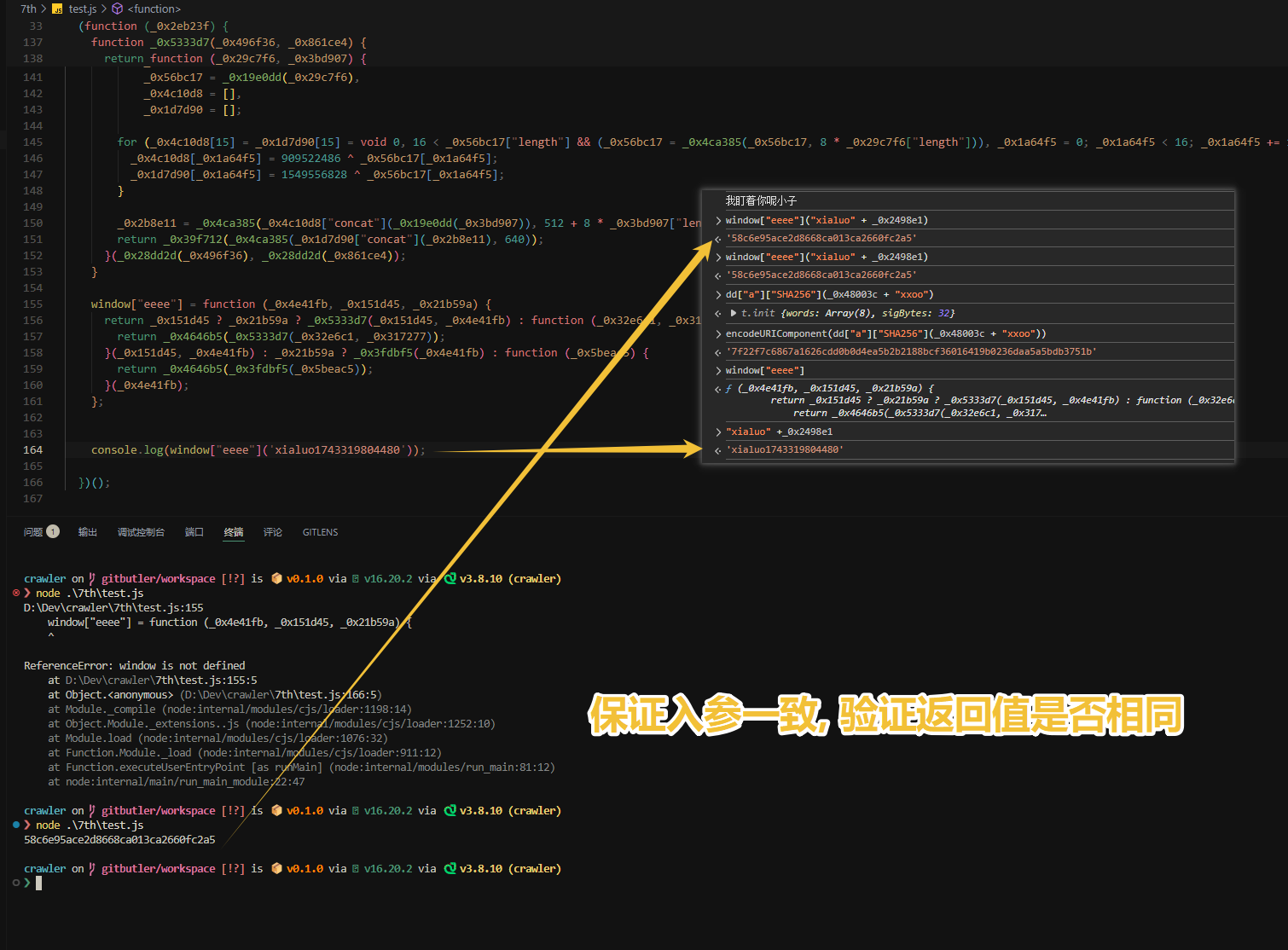
保证入参一致, 验证返回值是否相同; 验证值一致, 就可以直接python调用js方法
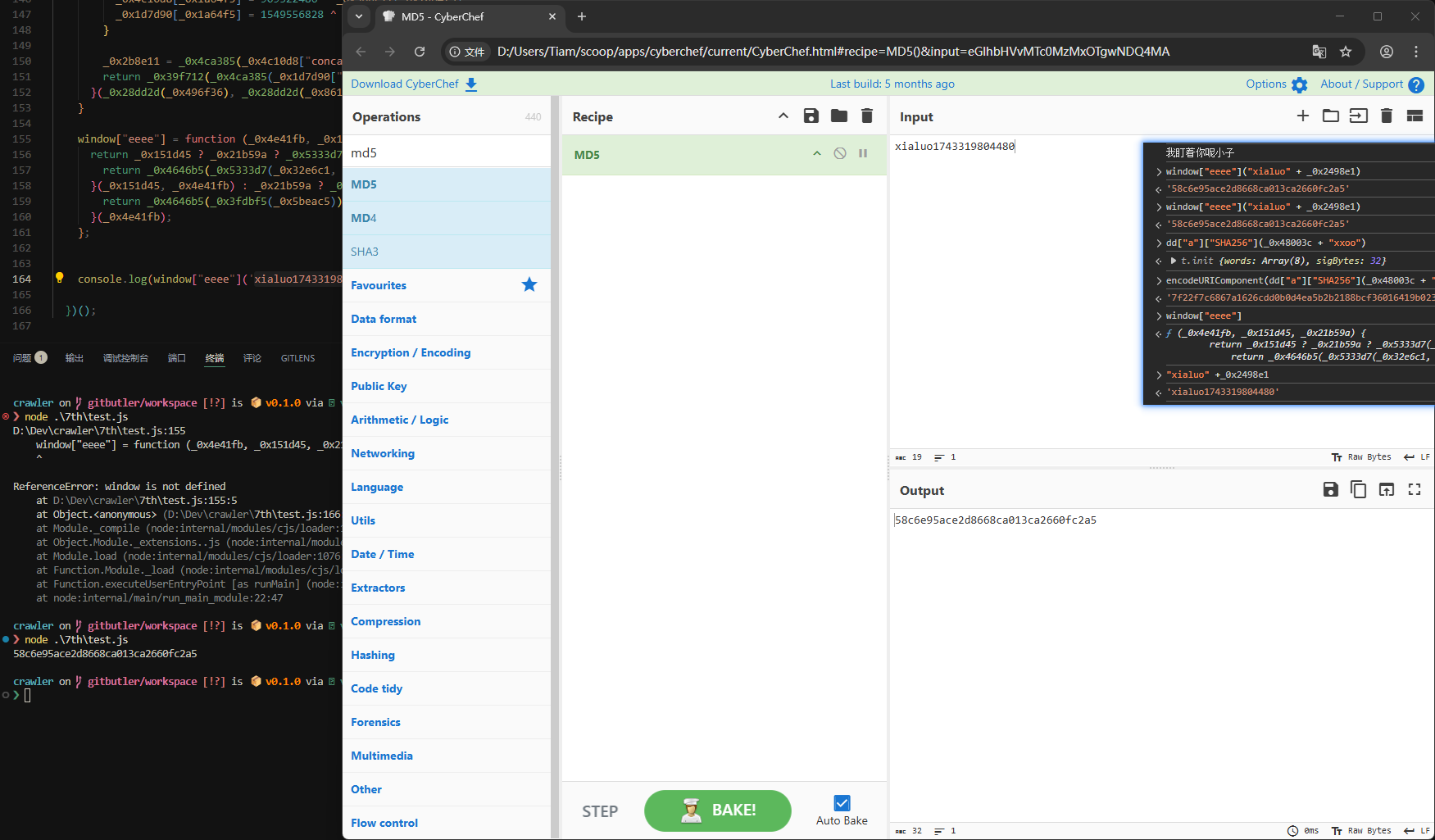
还有给AI js代码, 让其使用python实现, Ai会知道eeee方法其实就是个MD5, 验证一下
至此, 所有加解密算法已经出来了, 调个接口试试
使用的加密库: Examples — PyCryptodome 3.230b0 documentation
pip install pycryptodomex
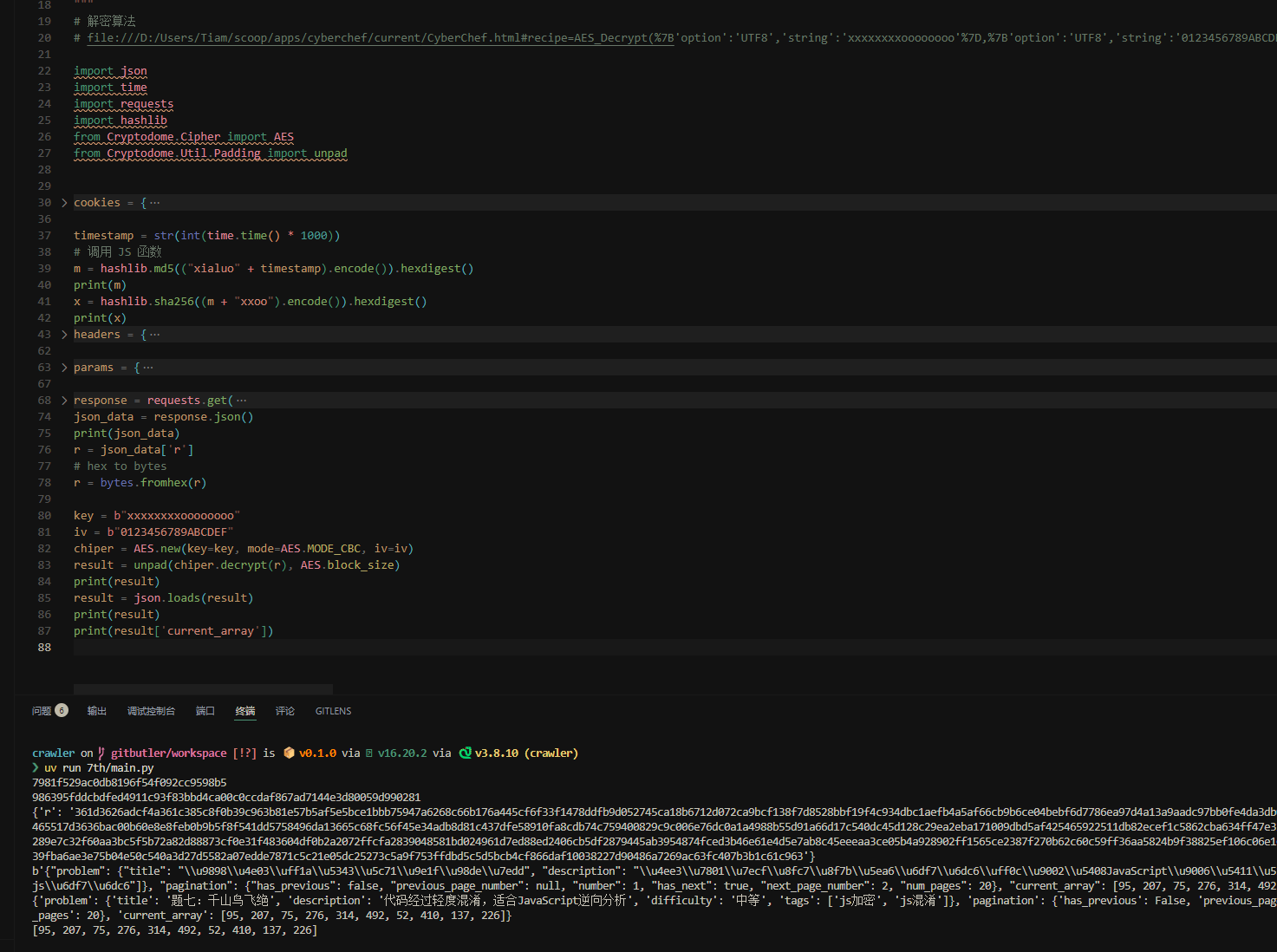
最后做个翻页请求20次接口累加数组即可得到答案, 就不做了, 贴个代码
import json
import time
import requests
import hashlib
from Cryptodome.Cipher import AES
from Cryptodome.Util.Padding import unpad
cookies = {
"sessionid": "66cxjeayq4hhd6e0bedtqze62lluxzhe",
"Hm_lvt_b5d072258d61ab3cd6a9d485aac7f183": "1743067108,1743124399",
"HMACCOUNT": "64ECCFF2BFC433A1",
"Hm_lpvt_b5d072258d61ab3cd6a9d485aac7f183": "1743155397",
}
timestamp = str(int(time.time() * 1000))
# 调用 JS 函数
m = hashlib.md5(("xialuo" + timestamp).encode()).hexdigest()
print(m)
x = hashlib.sha256((m + "xxoo").encode()).hexdigest()
print(x)
headers = {
"accept": "application/json, text/javascript, */*; q=0.01",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"cache-control": "no-cache",
"m": m,
"pragma": "no-cache",
"priority": "u=1, i",
"referer": "https://stu.tulingpyton.cn/problem-detail/7/",
"sec-ch-ua": '"Chromium";v="134", "Not:A-Brand";v="24", "Microsoft Edge";v="134"',
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": '"Windows"',
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-origin",
"ts": timestamp,
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36 Edg/134.0.0.0",
"x-requested-with": "XMLHttpRequest",
# 'cookie': 'sessionid=66cxjeayq4hhd6e0bedtqze62lluxzhe; Hm_lvt_b5d072258d61ab3cd6a9d485aac7f183=1743067108,1743124399; HMACCOUNT=64ECCFF2BFC433A1; Hm_lpvt_b5d072258d61ab3cd6a9d485aac7f183=1743155397',
}
params = {
"page": "1",
"x": x,
}
response = requests.get(
"https://stu.tulingpyton.cn/api/problem-detail/7/data/",
params=params,
cookies=cookies,
headers=headers,
)
json_data = response.json()
print(json_data)
r = json_data['r']
# hex to bytes
r = bytes.fromhex(r)
key = b"xxxxxxxxoooooooo"
iv = b"0123456789ABCDEF"
chiper = AES.new(key=key, mode=AES.MODE_CBC, iv=iv)
result = unpad(chiper.decrypt(r), AES.block_size)
print(result)
result = json.loads(result)
print(result)
print(result['current_array'])
题八:迷踪步
依旧还是解混淆替换, 然后跟栈断点 定位加密位置
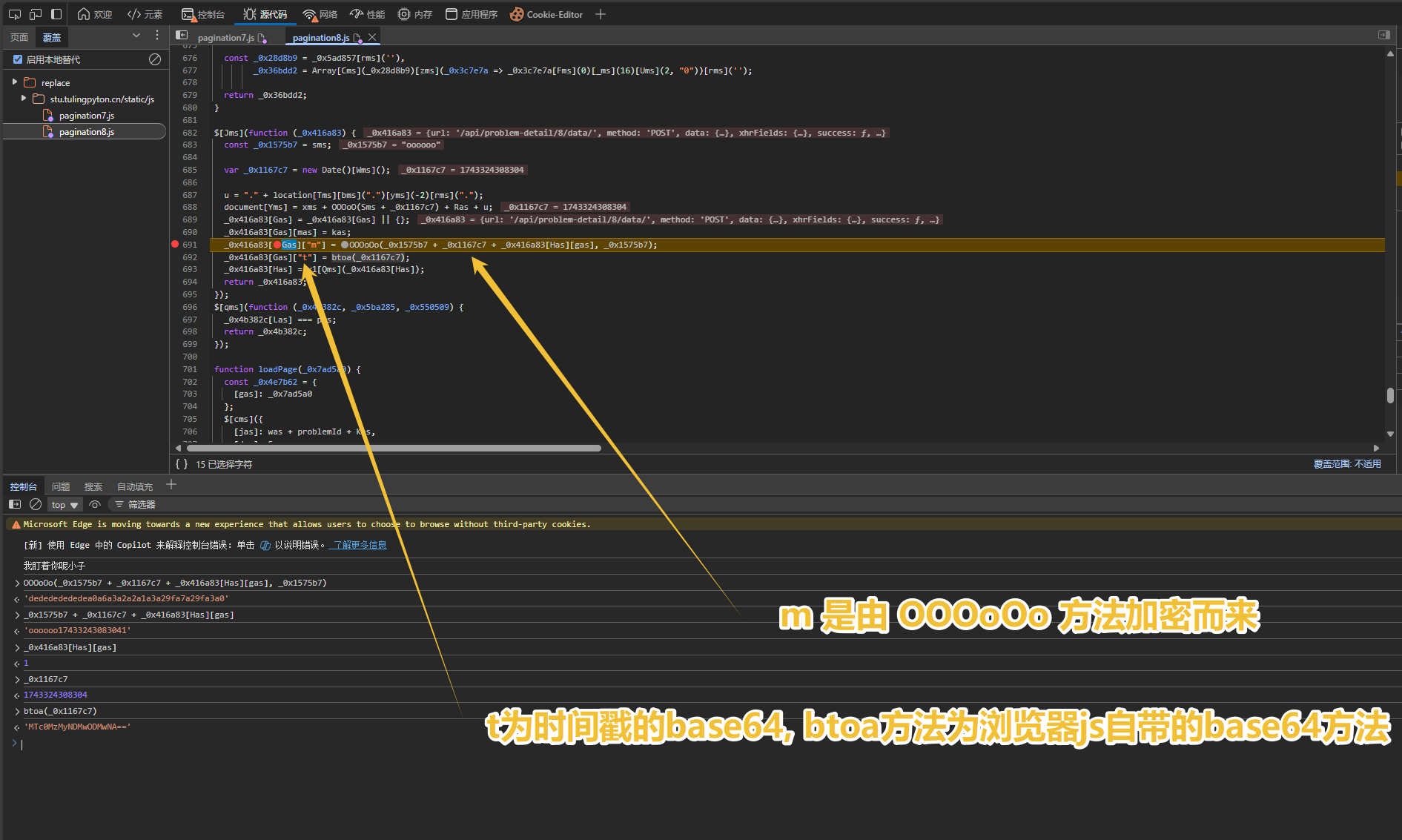
尝试分析加密方法OOOoOo, 先分析参数, 经过几次请求断点, 基本确定"ooooo"为固定值, 只有一个时间戳变量, 但是加密逻辑实在有点难看懂, 丢给AI试试
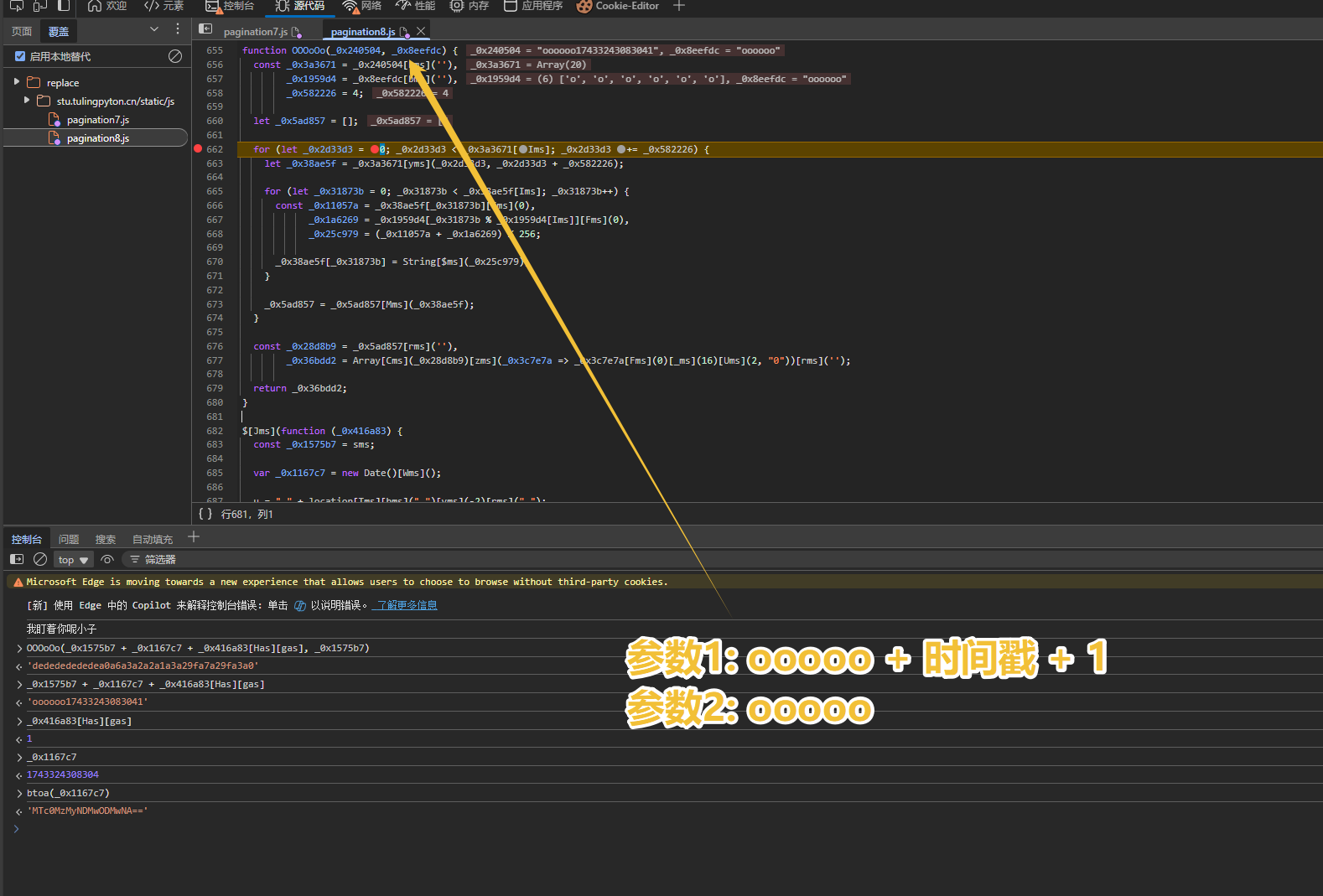
拿Ai生成的方法测试返回值是否一致, 没想到还真出来了; 甚至优化后, 加密逻辑可简化至两行代码,
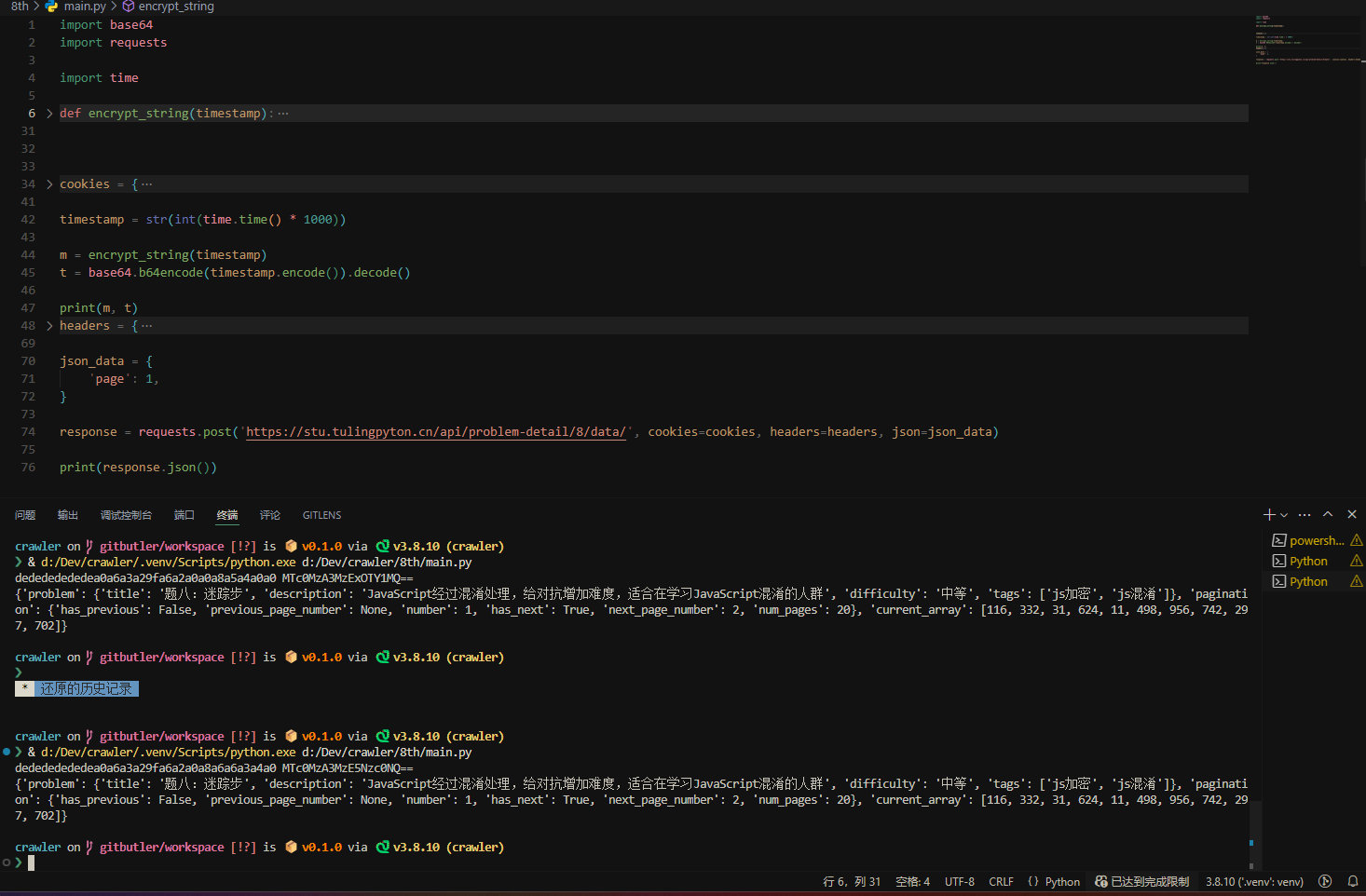
贴个代码; 以学习为目的的话, 还是应该尝试慢慢扣代码还原逻辑, 而不是丢给AI🫡
import base64
import requests
import time
def encrypt_string(timestamp):
key_string = "oooooo"
input_string = key_string + timestamp + "1"
input_chars = list(input_string)
key_chars = list(key_string)
result = []
# Process input in chunks of 4 characters
for i in range(0, len(input_chars), 4):
chunk = input_chars[i:i+4]
# XOR each character in the chunk with corresponding key character
for j in range(len(chunk)):
input_char_code = ord(chunk[j])
key_char_code = ord(key_chars[j % len(key_chars)])
encrypted_code = (input_char_code + key_char_code) % 256
chunk[j] = chr(encrypted_code)
result.extend(chunk)
# Convert to hexadecimal representation
encrypted_string = ''.join(result)
hex_string = ''.join(f"{ord(char):02x}" for char in encrypted_string)
return hex_string
def encrypt_string1(timestamp):
input_str = "oooooo" + timestamp + "1"
return ''.join(f"{(ord(c) + 111) % 256:02x}" for c in input_str)
cookies = {
'Hm_lvt_b5d072258d61ab3cd6a9d485aac7f183': '1743067108',
'HMACCOUNT': '64ECCFF2BFC433A1',
'sessionid': '66cxjeayq4hhd6e0bedtqze62lluxzhe',
'Hm_lpvt_b5d072258d61ab3cd6a9d485aac7f183': '1743072264',
's': '51b351b351b351b370b0d03050b010d07150b07130',
}
timestamp = str(int(time.time() * 1000))
m = encrypt_string1(timestamp)
t = base64.b64encode(timestamp.encode()).decode()
print(m, t)
headers = {
'accept': '*/*',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'cache-control': 'no-cache',
'content-type': 'application/json',
'm': m,
'origin': 'https://stu.tulingpyton.cn',
'pragma': 'no-cache',
'priority': 'u=1, i',
'referer': 'https://stu.tulingpyton.cn/problem-detail/8/',
'sec-ch-ua': '"Chromium";v="134", "Not:A-Brand";v="24", "Microsoft Edge";v="134"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
't': t,
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36 Edg/134.0.0.0',
'x-requested-with': 'XMLHttpRequest',
# 'cookie': 'Hm_lvt_b5d072258d61ab3cd6a9d485aac7f183=1743067108; HMACCOUNT=64ECCFF2BFC433A1; sessionid=66cxjeayq4hhd6e0bedtqze62lluxzhe; Hm_lpvt_b5d072258d61ab3cd6a9d485aac7f183=1743072264; s=51b351b351b351b370b0d03050b010d07150b07130',
}
json_data = {
'page': 1,
}
response = requests.post('https://stu.tulingpyton.cn/api/problem-detail/8/data/', cookies=cookies, headers=headers, json=json_data)
print(response.json())
51b351b351b351b370b0d03050b010d07150b07130’,
}
json_data = {
‘page’: 1,
}
response = requests.post(‘https://stu.tulingpyton.cn/api/problem-detail/8/data/’, cookies=cookies, headers=headers, json=json_data)
print(response.json())


















 55万+
55万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











