








今天偶然刷到这个网站,刚接触这个东西,试着玩了下,以下内容仅供参考
第一题
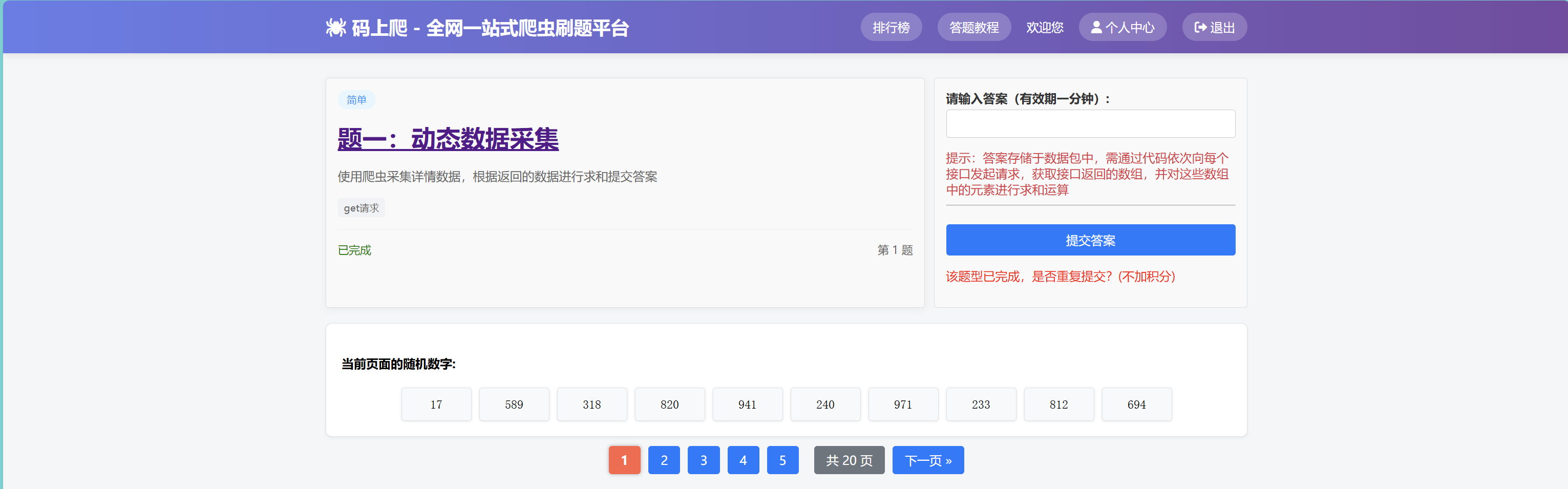
第一题可以说没有做任何校验,只需要你带上自己的用户session信息即可
参考代码:
import requests
def request_page(sessionid: str, page: int):
"""
请求对应页码信息
:param sessionid: 用户session信息
:param page: 页码
:return: 结果列表
"""
page_url = "https://stu.tulingpyton.cn/api/problem-detail/1/data/"
headers = {
# 标识登录用户
"cookie": f"sessionid={sessionid}"
}
querystring = {"page": f"{page}"}
return requests.get(page_url, headers=headers, params=querystring).json()['current_array']
if __name__ == '__main__':
user_session = 'xxxxxxxxxx'
number = 0
for i in range(1, 21):
number += sum(request_page(user_session, i))
print(number)
第二题
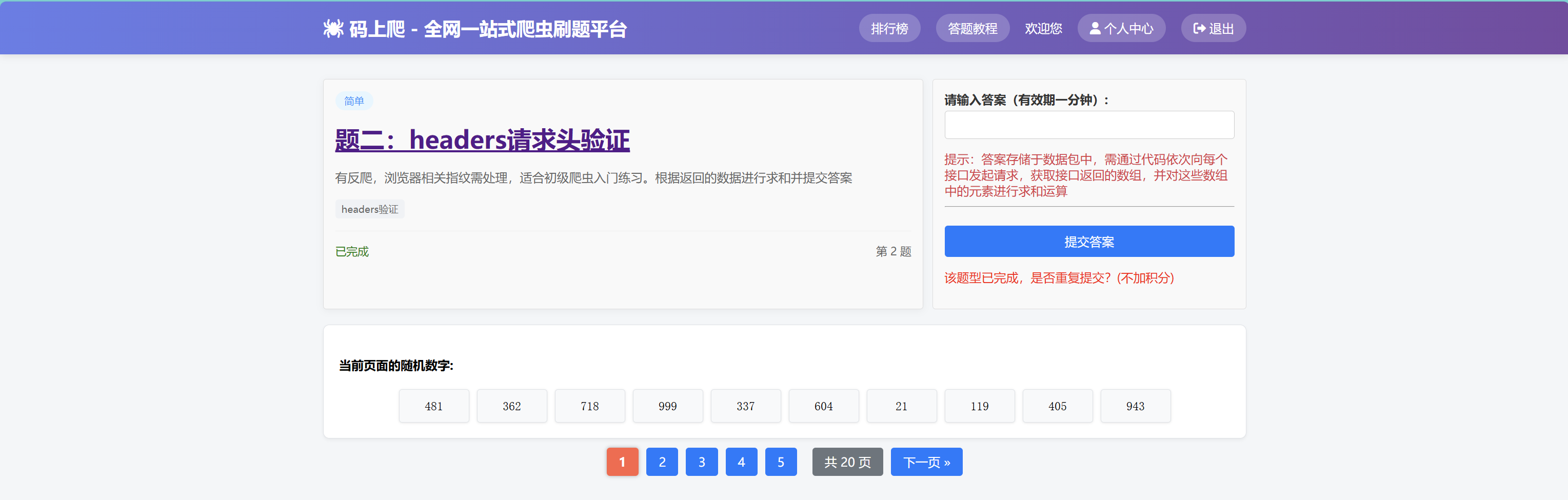
第二题相较第一题就多了一个referer的校验
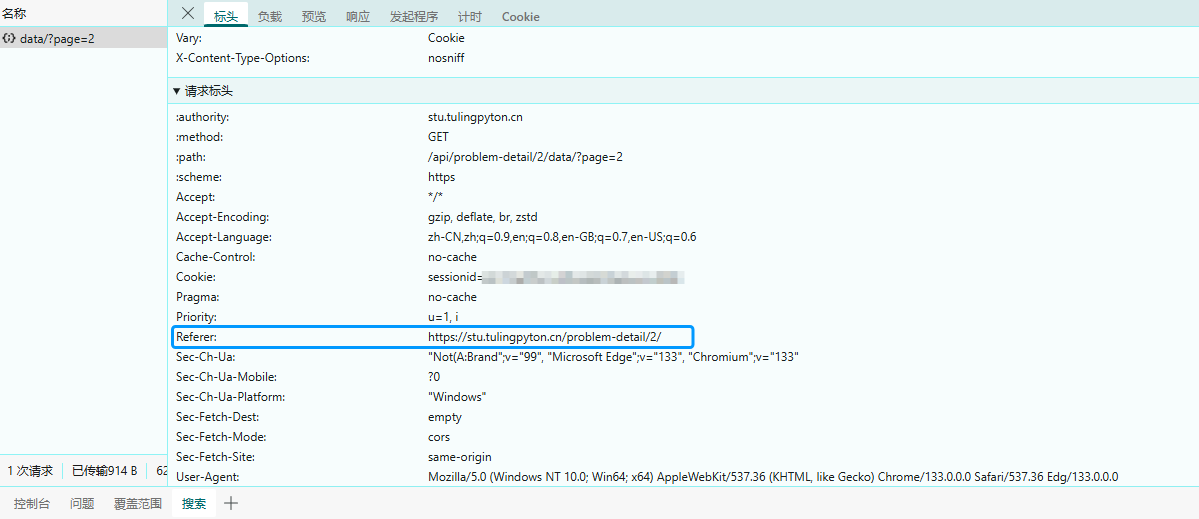
参考代码:
import requests
def request_page(sessionid: str, page: int):
"""
请求对应页码信息
:param sessionid: 用户session信息
:param page: 页码
:return: 结果列表
"""
page_url = "https://stu.tulingpyton.cn/api/problem-detail/2/data/"
headers = {
# 标识登录用户
"cookie": f"sessionid={sessionid}",
# 题目2,额外增加
"referer": "https://stu.tulingpyton.cn/problem-detail/2/"
}
querystring = {"page": f"{page}"}
return requests.get(page_url, headers=headers, params=querystring).json()['current_array']
if __name__ == '__main__':
user_session = 'xxxxxxxxxx'
number = 0
for i in range(1, 21):
number += sum(request_page(user_session, i))
print(number)
第三题
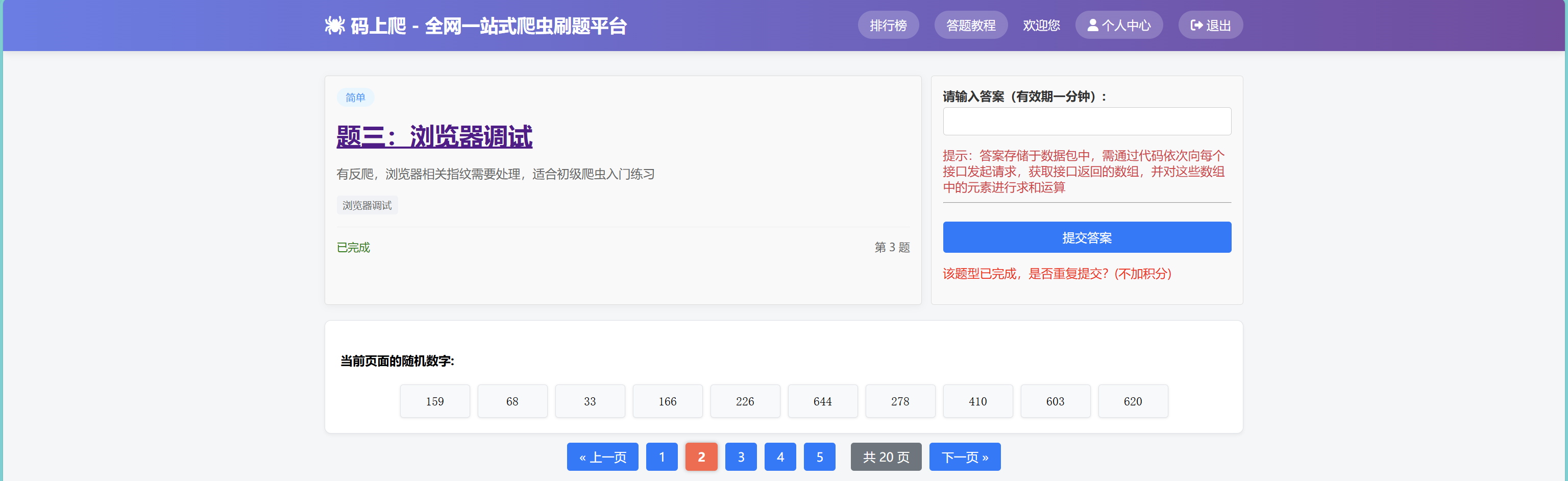
方法1 - 猜测
通过第二题的代码进行猜测,调整url就能直接使用
参考代码:
import requests
def request_page(sessionid: str, page: int):
"""
请求对应页码信息
:param sessionid: 用户session信息
:param page: 页码
:return: 结果列表
"""
page_url = "https://stu.tulingpyton.cn/api/problem-detail/3/data/"
headers = {
# 标识登录用户
"cookie": f"sessionid={sessionid}",
# 题目2,额外增加
"referer": "https://stu.tulingpyton.cn/problem-detail/2/"
}
querystring = {"page": f"{page}"}
return requests.get(page_url, headers=headers, params=querystring).json()['current_array']
if __name__ == '__main__':
user_session = 'xxxxxxxxxx'
number = 0
for i in range(1, 21):
number += sum(request_page(user_session, i))
print(number)
方法2 - 替换覆盖
进入调试后不刷新页面 或 在进入前打开调试窗口并取消停靠
在源代码标签里搜索 debugger

发现只找到了一个,打开此文件,复制loadPage整个函数,在对应文件上右键点击替代内容
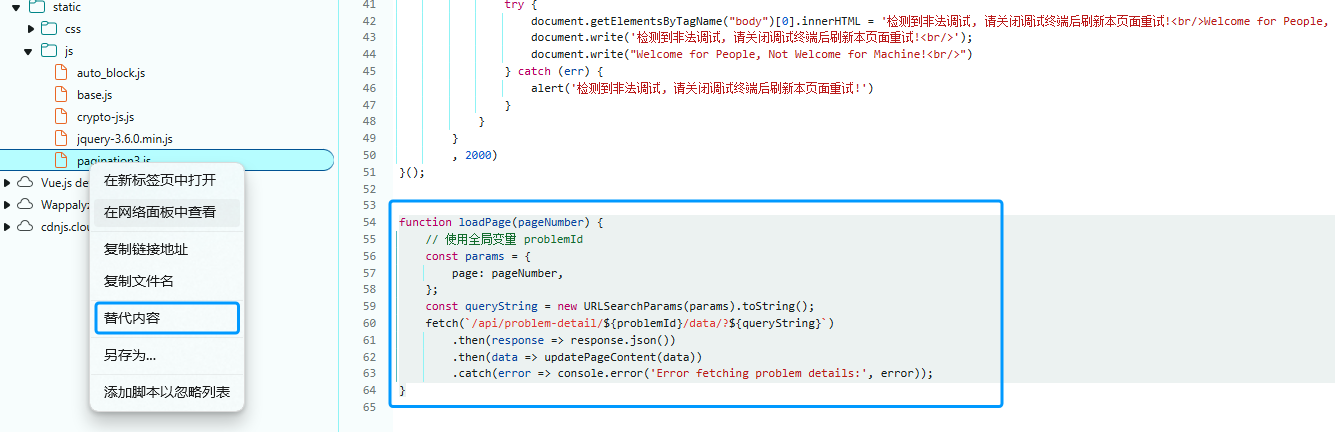
然后全选粘贴【或者删除上面内容也行】,按Ctrl+S保存,然后就可以正常刷新页面了
代码方法1 已经写了,就不再写了,就是翻页的地址的题号发生了变化

















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









