






实验内容
1.Apriori算法的实现
(1)手动生成样本数据集data_set,该数据集包含事物列表,每个事物包含若干项。[[‘11’,’12’,’15’]、[‘12’,’14’]、[’12’,’13’]、[‘11’,’12’,’14’]、[‘11’,’13’]、[’12’,’13’]、[‘11’,’13’]、[‘11’,’12’,’13’,’15’]、[‘11’,’12’,’13’]]
(2)生成频繁相集;
(3)判断候选频繁相集是否满足Apriori算法;
(4)创建产生所有频繁相集;
(5)从产生的频繁相集中生成规则。
实验方案
(1)导入数据集模块
(2)生成候选频繁项集C1
(3)判断频繁K项集是否满足Apriori算法,返回值为布尔类型
(4)通过在L(k-1)中执行self-joining策略创建一个包含所有频繁候选k相集的集合ck
(5)通过ck执行pruning策略生成Lk项集
(6)从所产生的频繁项集中生成规则
实验代码
def load_data_set():
"""
加载一个样本数据集(来自数据挖掘:概念和技术,第3版)
返回:
数据集:事务列表。每个事务都包含若干项。
"""
data_set = [['l1', 'l2', 'l5'], ['l2', 'l4'], ['l2', 'l3'],
['l1', 'l2', 'l4'], ['l1', 'l3'], ['l2', 'l3'],
['l1', 'l3'], ['l1', 'l2', 'l3', 'l5'], ['l1', 'l2', 'l3']]
return data_set
def create_C1(data_set):
"""
通过扫描数据集创建频繁候选1-itemset C1。
参数:
data_set:事务列表。每个事务都包含若干项。
返回:
C1:包含所有频繁候选1-项目集的集合
"""
C1 = set()
for t in data_set:
for item in t:
item_set = frozenset([item])
C1.add(item_set)
return C1
def is_apriori(Ck_item, Lksub1):
"""
判断频繁候选k-项集是否满足Apriori性质。
参数:
Ck_item: Ck中的一个频繁候选k-itemset,它包含所有的频繁项
k-itemsets候选人。
Lksub1: Lk-1,一个包含所有频繁候选(k-1)项集的集合。
返回:
真:满足Apriori性质。
错误:不满足Apriori性质。
"""
for item in Ck_item:
sub_Ck = Ck_item - frozenset([item])
if sub_Ck not in Lksub1:
return False
return True
def create_Ck(Lksub1, k):
"""
创建Ck,一个包含所有频繁候选k-itemset的集合
通过Lk-1自己的连接操作。
参数:
Lksub1: Lk-1,一个包含所有频繁候选(k-1)项集的集合。
k:频繁项目集的项目号。
返回:
Ck:包含所有频繁候选k-itemset的集合。
"""
Ck = set()
len_Lksub1 = len(Lksub1)
list_Lksub1 = list(Lksub1)
for i in range(len_Lksub1):
for j in range(1, len_Lksub1):
l1 = list(list_Lksub1[i])
l2 = list(list_Lksub1[j])
l1.sort()
l2.sort()
if l1[0:k-2] == l2[0:k-2]:
Ck_item = list_Lksub1[i] | list_Lksub1[j]
# pruning
if is_apriori(Ck_item, Lksub1):
Ck.add(Ck_item)
return Ck
def generate_Lk_by_Ck(data_set, Ck, min_support, support_data):
"""
通过从Ck执行删除策略来生成Lk。
参数:
data_set:事务列表。每个事务都包含若干项。
Ck:包含所有频繁候选k-itemset的集合。
min_support:最小支持度。
support_data:一个字典。关键字为“frequent itemset”,取值为“support”。
返回:
Lk:包含所有频繁k-itemset的集合。
"""
Lk = set()
item_count = {}
for t in data_set:
for item in Ck:
if item.issubset(t):
if item not in item_count:
item_count[item] = 1
else:
item_count[item] += 1
t_num = float(len(data_set))
for item in item_count:
if (item_count[item] / t_num) >= min_support:
Lk.add(item)
support_data[item] = item_count[item] / t_num
return Lk
def generate_L(data_set, k, min_support):
"""
生成所有频繁项集。
参数:
data_set:事务列表。每个事务都包含若干项。
k:所有频繁项目集的最大项目数量。
min_support:最小支持度。
返回:
L: Lk的名单。
support_data:一个字典。关键字为“frequent itemset”,取值为“support”。
"""
support_data = {}
C1 = create_C1(data_set)
L1 = generate_Lk_by_Ck(data_set, C1, min_support, support_data)
Lksub1 = L1.copy()
L = []
L.append(Lksub1)
for i in range(2, k+1):
Ci = create_Ck(Lksub1, i)
Li = generate_Lk_by_Ck(data_set, Ci, min_support, support_data)
Lksub1 = Li.copy()
L.append(Lksub1)
return L, support_data
def generate_big_rules(L, support_data, min_conf):
"""
从频繁项目集生成强规则。
参数:
L: Lk的名单。
support_data:一本字典。关键字为“frequent itemset”,取值为“support”。
min_conf:最小的置信度。
返回:
big_rule_list:包含所有大规则的列表。每个大规则都表示为一个3元组。
"""
big_rule_list = []
sub_set_list = []
for i in range(0, len(L)):
for freq_set in L[i]:
for sub_set in sub_set_list:
if sub_set.issubset(freq_set):
conf = support_data[freq_set] / support_data[freq_set - sub_set]
big_rule = (freq_set - sub_set, sub_set, conf)
if conf >= min_conf and big_rule not in big_rule_list:
big_rule_list.append(big_rule)
sub_set_list.append(freq_set)
return big_rule_list
if __name__ == "__main__":
"""
Test
"""
data_set = load_data_set()
L, support_data = generate_L(data_set, k=3, min_support=0.2)
big_rules_list = generate_big_rules(L, support_data, min_conf=0.7)
for Lk in L:
print ("="*50)
print ("frequent ") + str(len(list(Lk)[0])) + ("-itemsets\t\tsupport")
print ("="*50)
for freq_set in Lk:
print(freq_set, support_data[freq_set])
print()
print ("Big Rules")
for item in big_rules_list:
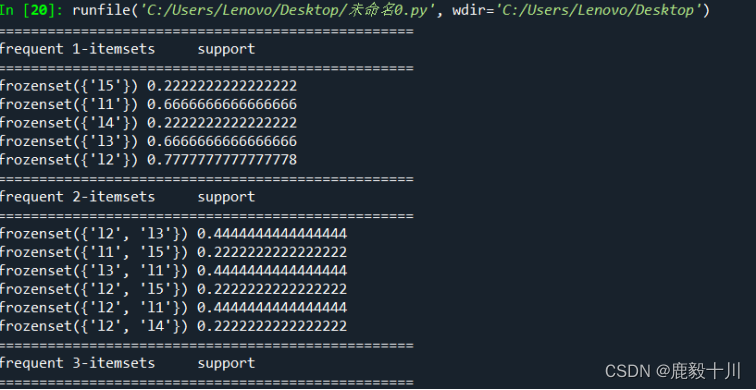
print(item[0], "=>", item[1], "conf: ", item[2])运行结果

















 1662
1662











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











