







摘要
Fast R-CNN是针对R-CNN缺点改进的目标检测模型。Fast R-CNN先计算整个图片的特征图,并没有针对每个候选区域计算特征图,避免了来自同一张图片的候选区域计算特征图导致的重复计算问题。为了解决这个重复计算问题,Fast R-CNN提出了RoI池化层,它首先会根据原图形状与特征图形状得出候选区域在特征图上的位置,接着对候选区域的特征图在每个颜色通道上进行网格划分,然后对网格中每个单元进行单元形状的最大池化,最后得到池化后固定形状的特征图,便于全连接层提取特征向量。同时RoI层也解决了多尺度的候选区域为了得到同样大小特征向量需要进行缩放的问题,加速了训练和预测的过程。此外,Fast R-CNN通过多任务损失将分类任务和边界框修正任务联合起来训练,使得R-CNN原来多阶段的流程变为单阶段的流程,同样也加速了训练和预测的过程。尽管Fast R-CNN解决一部分导致R-CNN训练和预测耗时长的问题,但是候选区域生成耗时长的问题还是没有解决。
Abstract
Fast R-CNN is an improved object detection model aimed at addressing the shortcomings of R-CNN. Fast R-CNN first computes the feature map of the entire image, rather than calculating the feature map for each candidate region, thereby avoiding the redundant computation caused by generating feature maps for multiple candidate regions from the same image. To address this redundancy issue, Fast R-CNN introduces the RoI pooling layer, which first determines the location of each candidate region on the feature map based on the original image shape and feature map shape. It then divides the candidate region’s feature map into a grid for each color channel, performs max pooling on each unit of the grid, and finally obtains a pooled feature map with a fixed shape that can be passed to the fully connected layers to extract feature vectors. At the same time, the RoI pooling layer also solves the problem of rescaling multi-scale candidate regions to obtain the same-sized feature vectors, accelerating both the training and inference processes. Furthermore, Fast R-CNN combines the classification task and bounding box regression task into a single joint loss function, transforming the multi-stage pipeline of R-CNN into a single-stage pipeline, which further speeds up training and inference. Despite solving some of the issues that caused long training and inference times in R-CNN, the problem of slow candidate region generation has not been addressed.
1. 引言
尽管R-CNN在目标检测上达到了极好的准确率,但它同样具有非常显著的缺点:
1. 训练过程是一个多阶段的流程:(1) 在候选区域上使用分类损失对卷积神经网络进行微调;(2) 用提取出的特征向量来训练支持向量机;(3) 训练边界框回归。
2. 训练在时间和空间上的代价极其昂贵:在训练支持向量机和边界框时,每个图片产生的候选区域都要提取出一个特征向量并存储在磁盘上。
3. 目标检测很慢:在测试时,每个图片的候选区域提取特征向量的过程耗时严重。
Fast R-CNN是R-CNN的改进模型,同时进一步提高了速度和准确率。
2. 框架
下图是Fast R-CNN的框架。生成每张图片中候选区域的算法仍然是选择性搜索。每张图片和这张图片上的所有候选区域作为Fast R-CNN的输入;图片通过VGG16前17层后产生了整张图片的特征图;所有候选区域和这张特征图经过RoI池化层和两层全连接层后得到每个候选区域的特征向量;这些特征向量会进入两个不同的全连接层,一个最终经过softmax得到特征向量属于每个类别的可能性,另一个最终经过边界框回归器得到每个除背景外类别的边界框偏移量。
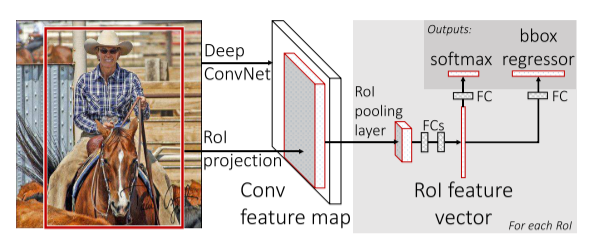
2.1 RoI池化层
RoI池化层使用的是最大池化,并且和最大池化一样在每个颜色通道上单独计算。假设整个图片的形状为
[
H
1
,
W
1
,
C
2
]
[H_1, W_1, C_2]
[H1,W1,C2],图片经过VGG16前17层后得到的特征图形状为
[
H
2
,
W
2
,
C
1
]
[H_2, W_2, C_1]
[H2,W2,C1],一个候选区域的四元组为
[
x
1
,
y
1
,
x
2
,
y
2
]
[x_1, y_1, x_2, y_2]
[x1,y1,x2,y2]。第一步首先要计算这个候选区域在特征图上的位置:
x
1
′
=
x
1
W
2
W
1
x
2
′
=
x
2
W
2
W
1
y
1
′
=
y
1
H
2
H
1
y
2
′
=
y
2
H
2
H
1
.
\begin{aligned} x_1'=\frac{x_1W_2}{W_1}\quad x_2'=\frac{x_2W_2}{W_1}\quad y_1'=\frac{y_1H_2}{H_1}\quad y_2'=\frac{y_2H_2}{H_1}. \end{aligned}
x1′=W1x1W2x2′=W1x2W2y1′=H1y1H2y2′=H1y2H2.
假设RoI池化层输出的形状为
[
h
1
,
w
1
,
C
2
]
[h_1, w_1, C_2]
[h1,w1,C2],则RoI池化层会根据上面计算得到的四元组取出候选区域的特征图(候选区域特征图的形状为
[
h
2
,
w
2
,
C
2
]
[h_2, w_2, C_2]
[h2,w2,C2]);然后在每个颜色通道上划分出一个形状为
h
1
×
w
1
h_1\times w_1
h1×w1的网格,网格中每个单元的形状为
[
h
2
h
1
,
w
2
w
1
]
\displaystyle[\frac{h_2}{h_1}, \frac{w_2}{w_1}]
[h1h2,w1w2];最后对网格中每个单元使用与单元形状一致的最大池化,每个单元在池化后都变成了一个值,因此RoI池化后输出的形状为
[
h
1
,
w
1
,
C
2
]
[h_1, w_1, C_2]
[h1,w1,C2]。
下图给出了单个颜色通道上RoI池化的一个例子。输入特征图在单通道上的形状为
[
8
,
16
]
[8, 16]
[8,16],RoI池化的输出形状为
[
4
,
4
]
[4, 4]
[4,4],网格中每个单元的形状为
[
2
,
4
]
[2, 4]
[2,4]。每个单元经过
2
×
4
2\times4
2×4的最大池化后得到一个值,比如下图左上角的单元经过最大池化得到7,如此便能在经过RoI池化后得到指定形状的特征图。在单元形状无法除尽的情况下,RoI池化会使用填充来解决问题。

2.2 网络结构
下表给出了VGG16模型的结构。
| 编号 | 类型 | 卷积核/池化核/全连接神经元个数 | 激活函数 |
|---|---|---|---|
| C1 | 卷积层 | 64个 3 × 3 卷积核 3\times3卷积核 3×3卷积核,步长和填充都为1 | ReLU |
| C2 | 卷积层 | 64个 3 × 3 3\times3 3×3卷积核,步长和填充都为1 | ReLU |
| S3 | 池化层 | 2 × 2 2\times2 2×2最大池化,步长为2 | - |
| C4 | 卷积层 | 128个 3 × 3 3\times3 3×3卷积核,步长和填充都为1 | ReLU |
| C5 | 卷积层 | 128个 3 × 3 3\times3 3×3卷积核,步长和填充都为1 | ReLU |
| S6 | 池化层 | 2 × 2 2\times2 2×2最大池化,步长为2 | - |
| C7 | 卷积层 | 256个 3 × 3 3\times3 3×3卷积核,步长和填充都为1 | ReLU |
| C8 | 卷积层 | 256个 3 × 3 3\times3 3×3卷积核,步长和填充都为1 | ReLU |
| C9 | 卷积层 | 256个 3 × 3 3\times3 3×3卷积核,步长和填充都为1 | ReLU |
| S10 | 池化层 | 2 × 2 2\times2 2×2最大池化,步长为2 | - |
| C11 | 卷积层 | 512个 3 × 3 3\times3 3×3卷积核,步长和填充都为1 | ReLU |
| C12 | 卷积层 | 512个 3 × 3 3\times3 3×3卷积核,步长和填充都为1 | ReLU |
| C13 | 卷积层 | 512个 3 × 3 3\times3 3×3卷积核,步长和填充都为1 | ReLU |
| S14 | 池化层 | 2 × 2 2\times2 2×2最大池化,步长为2 | |
| C15 | 卷积层 | 512个 3 × 3 3\times3 3×3卷积核,步长和填充都为1 | ReLU |
| C16 | 卷积层 | 512个 3 × 3 3\times3 3×3卷积核,步长和填充都为1 | ReLU |
| C17 | 卷积层 | 512个 3 × 3 3\times3 3×3卷积核,步长和填充都为1 | ReLU |
| S18 | 池化层 | 2 × 2 2\times2 2×2最大池化,步长为2 | - |
| F19 | 全连接层 | 4096个全连接神经元 | ReLU |
| F20 | 全连接层 | 4096个全连接神经元 | ReLU |
| F21 | 全连接层 | 1000个全连接神经元 | \Softmax |
Fast R-CNN把第18层最大池化层替换为RoI池化层,并且通过把最后一层全连接层替换为两个平行的子层,一个层计算K个类别和背景的softmax概率值,另一层计算K个类别的边界框偏移量。此外,还需要调整模型的输入,使其接收两个输入:图片和该图片上候选区域。
2.3 训练细节
2.3.1 训练采样
对于每个候选区域,如果它与真实区域的交并比大于等于0.5,则它的标签为真实区域对应的类(类编号从1开始)和真实区域对应的四元组;如果它与真实区域的交并比大于等于0.1且小于0.5,则它的标签为背景,类编号为0。
在训练过程,使用的数据增强是水平翻转,假设候选区域和真实区域四元组的格式为
[
x
m
i
n
,
y
m
i
n
,
x
m
a
x
,
y
m
a
x
]
[x_{min}, y_{min}, x_{max}, y_{max}]
[xmin,ymin,xmax,ymax],图像的宽度为
w
i
d
t
h
width
width,则水平翻转后的四元组为:
x
m
i
n
′
=
w
i
d
t
h
−
x
m
a
x
y
m
i
n
′
=
y
m
i
n
x
m
a
x
′
=
w
i
d
t
h
−
x
m
i
n
y
m
a
x
′
=
y
m
a
x
.
x_{min}'=width-x_{max}\quad y_{min}'=y_{min}\quad x_{max}'=width-x_{min}\quad y_{max}'=y_{max}.
xmin′=width−xmaxymin′=yminxmax′=width−xminymax′=ymax.
使用ImageNet上预训练的VGG16模型,并对它进行上一小节中的修改后再进行微调。微调时批量大小为128,随机选择两个图片,从每个图片上采集64个符合本小节一开始要求的候选区域。
2.3.2 多任务损失
Fast R-CNN有两个平行的输出子层,一个输出每个候选区域属于K+1类的概率分布
p
p
p,另一个输出边界框偏移量
t
u
t^u
tu,因此需要使用多任务损失来联合训练分类和边界框回归,损失函数为:
L
(
p
,
u
,
t
u
,
v
)
=
L
c
l
s
(
p
,
u
)
+
λ
I
(
u
≥
1
)
L
l
o
c
(
t
u
,
v
)
.
L(p, u, t^u, v)=L_{cls}(p, u)+\lambda I(u\ge1)L_{loc}(t^u, v).
L(p,u,tu,v)=Lcls(p,u)+λI(u≥1)Lloc(tu,v).
其中
u
u
u是候选区域属于的真实类别,
v
v
v是真实区域的四元组,
I
(
u
≥
1
)
I(u\ge1)
I(u≥1)是指示函数即
I
(
u
≥
1
)
=
{
1
,
u
≥
1
0
,
其他
I(u\ge1)=\left\{\begin{aligned}&1,\quad u\ge1\\&0,\quad 其他\end{aligned}\right.
I(u≥1)={1,u≥10,其他(当
u
=
0
u=0
u=0时候选区域为背景,不需要进行定位),
λ
\lambda
λ设置为1。
分类损失为
L
c
l
s
(
p
,
u
)
=
−
l
o
g
p
u
L_{cls}(p, u)=-logp_u
Lcls(p,u)=−logpu。假设候选区域的四元组为
[
x
1
,
y
1
,
x
2
,
y
2
]
[x_1, y_1, x_2, y_2]
[x1,y1,x2,y2],真实区域的四元组为
[
x
3
,
y
3
,
x
4
,
y
4
]
[x_3, y_3, x_4, y_4]
[x3,y3,x4,y4],定位损失为
L
l
o
c
(
t
u
,
v
)
=
∑
i
∈
{
x
,
y
,
w
,
h
}
s
m
o
o
t
h
L
1
(
t
i
u
−
v
i
)
L_{loc}(t^u, v)=\sum_{i\in \{x, y, w, h\}}smooth_{L_1}(t_i^u-v_i)
Lloc(tu,v)=∑i∈{x,y,w,h}smoothL1(tiu−vi),其中
s
m
o
o
t
h
L
1
(
x
)
=
{
0.5
x
2
,
i
f
∣
x
∣
<
1
∣
x
∣
−
0.5
,
其他
smooth_{L_1}(x)=\left\{\begin{aligned}0.5x^2\quad,&if |x|\lt1\\|x|-0.5,&其他\end{aligned}\right.
smoothL1(x)={0.5x2,∣x∣−0.5,if∣x∣<1其他,
t
x
=
x
3
−
x
1
x
2
−
x
1
\displaystyle t_x=\frac{x_3-x_1}{x_2-x_1}
tx=x2−x1x3−x1,
t
y
=
y
3
−
y
1
y
2
−
y
1
\displaystyle t_y=\frac{y_3-y_1}{y_2-y_1}
ty=y2−y1y3−y1,
t
w
=
l
o
g
(
x
4
−
x
3
x
2
−
x
1
)
\displaystyle t_w=log(\frac{x_4-x_3}{x_2-x_1})
tw=log(x2−x1x4−x3),
t
h
=
l
o
g
(
y
4
−
y
3
y
2
−
y
1
)
\displaystyle t_h=log(\frac{y_4-y_3}{y_2-y_1})
th=log(y2−y1y4−y3)。在计算定位损失前,需要对真实区域进行归一化,使其均值为0,方差为1,目的是为了使训练更稳定。
3. 创新与不足
3.1 创新
R-CNN根据生成的候选区域先提取特征向量,再根据特征向量训练支持向量来分类,最后用边界框回归修正候选区域,这是一个多阶段的流程;而Fast R-CNN把分类任务和边界框修正任务结合到一起,使其成为了一个单阶段的流程,加速了训练和预测的过程。
R-CNN使用微调后的AlexNet提取每个候选区域的特征向量,有多少候选区域就要进行多少次提取操作,即使某些候选区域来自同一张图片,这过程进行了多次重复计算;而Fast R-CNN针对每张图片计算它的特征图,然后通过RoI池化层和之后两层全连接层计算该图片上所有候选区域的特征向量,减少了重复计算的次数,加速了训练和预测的过程。
R-CNN在微调AlexNet时需要对每张图片进行缩放,同时在提取每个候选区域的特征向量时仍需要对候选区域框住的部分图片进行缩放,使得整个目标检测流程极其繁琐;而Fast R-CNN不需要对图片和候选区域框住的部分图片进行缩放,这一切都要归功于RoI池化层,RoI池化层使得不管什么形状的输入图片和候选区域框住的部分图片在经过处理后都能变成固定形状的特征图,省去了不少对图片进行缩放的操作,提高了训练和预测的速度。
3.2 不足
尽管Fast R-CNN解决了一部分导致R-CNN训练和预测过程耗时长的问题,但是由于它仍然采用选择性搜索来生成图片候选区域,每张图片都需要先生成候选区域,才能将图片和一系列候选区域四元组作为Fast R-CNN模型的输入,因此候选区域生成耗时长的问题还是没有解决。后续的模型Faster R-CNN提出的区域提案网络,能与检测网络共享图片的卷积特征,使候选区域生成耗时长的问题得到进一步的解决。
参考
Ross Girshick. Fast R-CNN.
总结
Fast R-CNN实现目标检测的工作流程:首先使用选择性搜索算法生成一张图片的候选区域;接着把图片和候选区域作为Fast R-CNN的输入,经过VGG16前17层后得到图片的特征图;然后图片的特征图和候选区域一起送入RoI池化层得到每个候选区域固定形状的特征图;接下来每个候选区域的特征图经过两层全连接层后提取出4096维的特征向量;最后候选区域的特征向量和类别标签被送入到一个进行分类任务的子层,得到K+1个类别的概率分布;如果候选区域的标签不是背景,候选区域的特征向量和真实区域的四元组被送入到一个进行边界框修正任务的子层,得到边界框修后的偏移量。Fast R-CNN是一个单阶段的流程,利用RoI池化层和两个任务的联合训练加速了训练和预测的过程,但是仍然没有解决候选区域生成耗时长的问题。

















 20万+
20万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









