






Object Detection in 20 Years: A Survey 目标检测综述
文章地址:Object Detection in 20 Years: A Survey
本文仅作为论文的阅读笔记,文中内容为自己阅读论文的理解,如有错误烦请指正。
abstract
文章回顾了近25年来(1990s~2019)目标检测算法的发展进步,包括了再历史上具有里程碑意义的检测器、数据集、评估指标以及最近的SOTA模型。同时,回顾了目标检测的各种应用,如行人检测、人脸检测等,并深入分析这些任务的挑战性以及它们再近年来取得的进步。
1. Introduction
目标检测是其它的视觉任务如实例分割、目标追踪的基础,近年来得益于深度学习的迅猛发展,目标检测也取得了极大的进步使其成为研究的热点,与之相关的出版物数量连年增加(如图1所示)。

这篇文章与其它目标检测综述相比有以下优点:
1.对技术发展的全面回顾
2.对关键技术和最新技术的深入探索
3.对检测加速技术的全面分析
2. Object Detection in 20 Years
这20年里目标检测的发展可以分为两段时期:2014年以前的传统目标检测时期以及2014年以后的基于深度学习的目标检测时期。

2.1 传统目标检测
1.Viola Jones Detectors
该算法首次实现了没有限制条件的实时人脸检测。算法采用传统的滑动窗口的方法来检测人脸,为了提高检测速度算法引入了三个重要技术:(1) Integral image (2) Feature selection (3)Detection cascades
2.HOG Detector
HOG(Histogram of Oriented Gradients)是对当时尺度不变特征变换和形状上下文的重要改进,其广泛应用于各种不同类别的检测当中。
3.Deformable Part-based Model (DPM)
DPM作为传统方法的巅峰,赢得了VOC-07、08、09挑战赛的冠军。DPM是HOG的延申,在2008年被P. Felzenszwalb提出。
2.2 基于CNN的两阶段检测
2010到2012年这段时间里,传统的人工提取特征的目标检测方法的性能难以得到提升,2014年R. Girshick等人提出the Regions with CNN features (RCNN)率先打破了僵局,从此目标检测以前所未有的速度快速发展。
RCNN
算法流程比较清晰,首先选择性地搜索一组候选区域(proposals),然后将候选区域放到CNN模型中提取特征,最后通过线性SVM分类器预测候选区域是否存在物体及其类别。
虽然RCNN取得了很大的进步,但其缺点也很明显:计算冗余。RCNN会产生大量的候选区域(一张照片2000个),而这些候选区域有很多是重叠的,这就导致CNN模型需要进行大量计算,使得该算法检测速度很慢。
SPPNet
SPPNet(Spatial Pyramid Pooling Networks)的主要贡献在于提出了空间金字塔池化层(Spatial Pyramid Pooling layer),使得模型可以输入任意尺寸的图片并输出固定长度的特征。由于SPPNet可以利用一张完整的图像一次性得到特征图避免了重复计算,使得其在保持了检测性能的情况下速度相比于RCNN快了20倍。
SPPNet主要有两个缺点:1. 模型的训练仍然需要多个步骤 2.模型只微调了全连接层而忽视了前面的层。
Fast RCNN
2015年R. Girshick提出了Fast RCNN,使得我们可以在相同网络配置下同时训练检测器和边界框回归器,算法相比于RCNN快了超过200倍。但还是不够快,检测速度还是被候选区域限制了。
Faster RCNN
同样在2015年S. Ren等人提出了Faster RCNN,得益于RPN(Region Proposal Network)的接近于零成本的区域建议,该算法是首个实现端到端并接近于实时检测的深度学习检测器。
Feature Pyramid Networks(FPN)
2017年T.-Y. Lin等人提出了FPN网络,之前的检测网络都是用深层的网络层进行检测,然而深层特征虽适合分类但对于定位却没什么帮助,而FPN网络为解决这个问题开发出了带有横向连接的自顶向下的结构使得检测器可以利用多尺度特征进行检测,使检测性能取得了很大进步,FPN也成了往后很多模型的基础结构。
2.3基于CNN的但阶段目标检测
You Only Look Once (YOLO)
2015年R. Joseph等人提出了YOLO模型,这是深度学习时代的首个单阶段目标检测模型,只用一个网络实现对整张图象的检测,使得检测速度得到极大提升实现了实时目标检测。网络将图像分为很多个区域,然后同时对各个区域的边界框和类别概率值进行预测。
YOLO虽然快,但在定位精度上比二阶段的模型要差,特别是对小目标来说。因此,YOLO后续的改进版本对这个问题更加重视。
Single Shot MultiBox Detector (SSD)
W. Liu等人提出了SSD模型,该模型提出了多参考(multi-reference)和多分辨率(multi-resolution)技术使得模型在速度和精度上都得到了进步。SSD与之前模型最大的不同在于SSD对不同尺度的目标会在不同的网络层进行检测,而其它模型都是在网络顶层进行的检测。
RetinaNet
T.-Y. Lin等人认为单阶段模型在精度上不如二阶段模型的主要原因是图像前景和背景的类别不均衡,为此他们提出了“focal loss”损失函数,使模型在训练过程中更关注于那些“hard”和分类错误的样本。
2.4 目标检测数据集
Pascal VOC
Pascal VOC有多个任务,如图像分类、目标检测、实例分割等,其中VOC07和VOC12主要用于目标检测任务,其中VOC包含五千张训练图像VOC12包含一万张。
ILSVRC
The ImageNet Large Scale Visual Recognition Challenge (ILSVRC)这个比赛用到的就是ImageNet数据集,该数据集有200个类别五十多万张图片。
MS-COCO
COCO数据集是当今(2019年及之前)最有挑战性的目标检测数据集。该数据集有80个类别,虽然类别数量少于ImageNet ,单单张图像有更多的实例和更多的小物体,难度更大。以MS-COCO-17为例,该版本的数据集包含了16万张图片以及近90万个实例。
Open Images
Open Images Detection (OID) 挑战赛共有两个任务:(1)标准目标检测。(2)视觉关系检测,检测特定关系中的成对对象。比赛中用到的Open Images数据集规模是空前的,包含191万张图片和1544万个标注框共600个物体类别。
其它检测任务的数据集





2.5 目标检测评价指标
在早期,通常用漏检率和每窗口误检率 "miss rate vs. false positives per-window (FPPW)"作为评价指标,但FPPW无法在所有情况下正确反映模型在整张图片的表现,后来(2009年后)人们改用每图片误检率“false positives perimage(FPPI)”作为指标。
近年来最常用的指标是"Average Precision (AP)"指标,AP指标定义为在不同召回率下的平均精度,每次通常只评估一个类别。为了比较所有类别的表现,通常使用mAP(mean AP)——各类别的平均AP做为最后评估指标。
为了检测模型的定位表现,又引入了交并比“Intersection over Union (IoU)”。IoU就是预测框和标签框的交集与并集的比例,比如,若IoU大于0.5则预测框检测成功否则失败。这样IoU和mAP相结合就能较全面地评估一个模型的表现了。
2.6 目标检测技术的发展
2.6.1 早期的黑暗知识
一些早期的研究者将目标检测定义为测量物体成分、形状和轮廓之间的相似性,包括距离变换、形状上下文和边缘变换等,但检测效果不佳,基于机器学习的方法开始繁荣发展。基于机器学习的方法经历了几个时期,包括外观统计模型(1998年之前)、小波特征表示(1998-2005)和基于梯度的表示(2005-2012)。
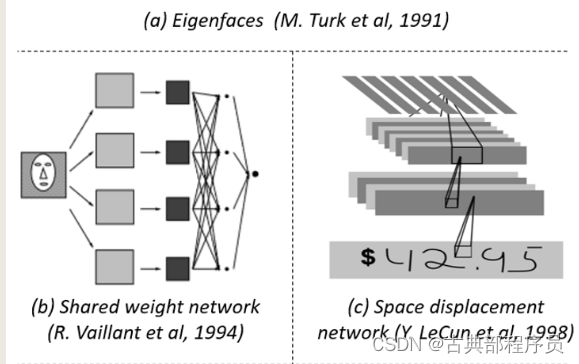
现在主流的基于CNN的方法其实在90年代就已经出现了,虽然当时的CNN模型层数很少,但对当时的算力而言仍然是一个大问题。为减少计算量,Y. LeCun等人提出了共享权重复制神经网络和空间位移网络(如图3所示),这可以认为是20年后出现的全卷积网络的雏形。
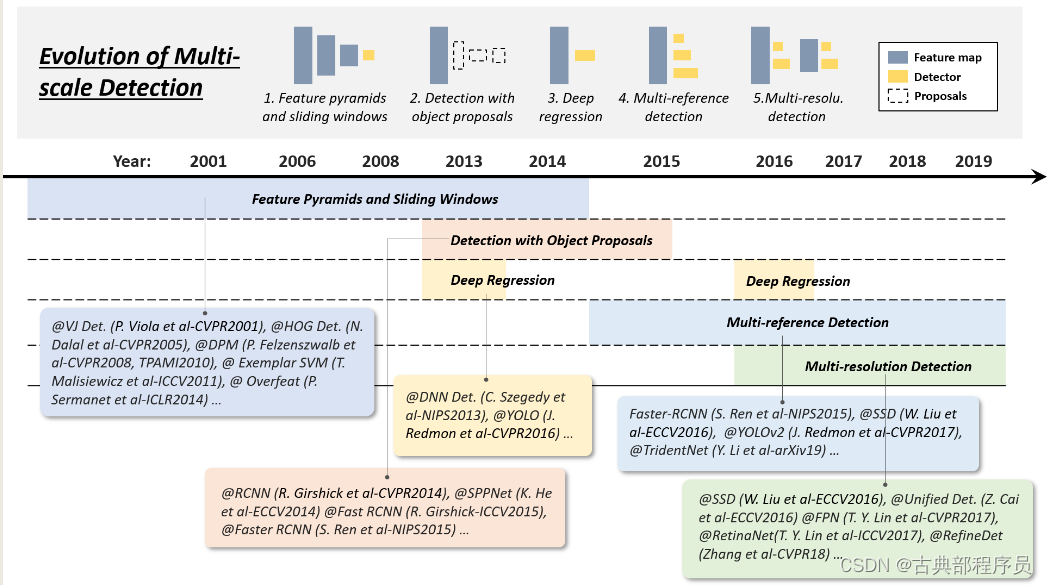
2.6.2 多尺度检测的发展
对不同大小和不同长宽比的物体的检测一直是目标检测领域的一个主要挑战之一,20年来多尺度检测经历了以下几个时期:
(1)特征金字塔和滑动窗(2014年以前)
(2)目标建议检测(2010-2015年)
(3)深度回归(2013-2016年)
(4)多参考检测(2015年以后)
(5)多分辨率检测(2016年以后)
2.6.4 边界框回归的技术发展
边界框回归指的是在初始候选区域或锚框的基础上进一步细化预测框的位置,该技术经历了以下几个时期:
(1)无边界框回归(2008年以前)
(2)从边界框到边界框(2008-2013)
(3)从特征到边界框(2013年以后)
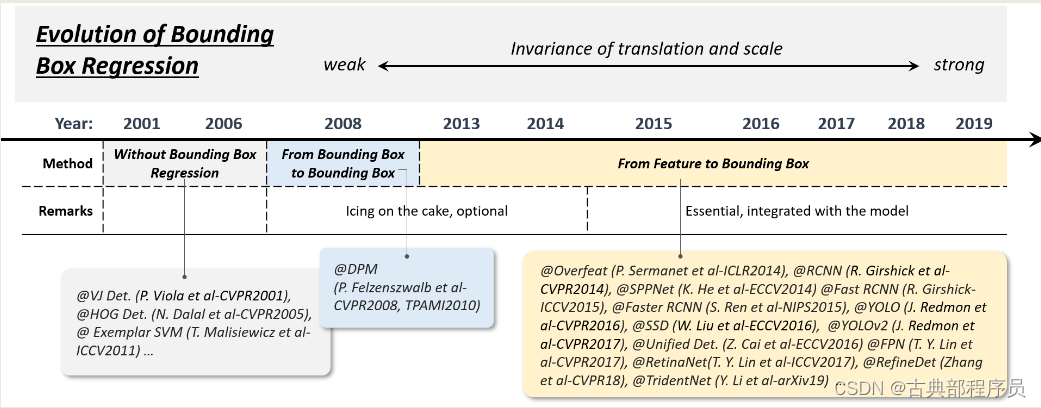
(1)无边界框回归
这段时期的很多研究者并不进行边界框回归,而是直接将滑窗当作边界框,这就导致了如果想得到更高精度的边界框就需要提高滑窗的密集度。
(2)从边界框到边界框
边界框回归最早由DPM算法引入,但此时边界框回归只是一个可选择的后处理1模块。后来R. Girshick等人介绍了一种更复杂的基于对象完全配置假设的边界框预测方法,并将该过程公式化为线性最小二乘回归问题,检测取得了显著的提高。
(3)从特征到边界框
Faster RCNN出现后边界框回归不再作为单独的后处理模型,而是整合到检测器中以端到端的方式进行训练。此时,已经能够用CNN得到的特征直接预测边界框了。
2.6.5 Technical Evolution of Context Priming
上下文信息对我们理解语义是否重要,对于目标检测而言也很重要。上下文信息用于目标检测也有它的发展过程:
(1)局部上下文信息
局部上下文信息是指被检测对象周围区域的视觉信息。局部上下文有助于提高目标检测性能,不管是在以前还是现在的深度学习时代。
(2)全局上下文信息
全局上下文信息可以为模型提供附加的信息,使模型能够更好地对物体进行检测。
(3)上下文信息交互(Context interactive)
上下文交互是指通过视觉元素的交互来传递的信息,例如约束和依赖关系。图像中的物体之间很多是有联系的,如果能利用这些信息将有助于提高检测性能。
2.6.6 非极大值抑制(NMS)技术发展
进行目标检测时通常会产生许多重叠的预测框,而非极大值抑制就是用来选择合适的预测框而将其它多余框滤除的方法。非极大值抑制主要有三种方法:
(1)贪婪选择(Greedy selection)
这种方法首先在重叠预测框中选取检测得分最高的预测框,而根据预定义的重叠阈值(例如,0.5)删除其相邻框,迭代重复这个步骤。这种方法是最常用的方法。
(2)边界框聚合(bounding box aggregation)
顾名思义,其思想是将多个重叠的边界框组合或聚类成一个最终检测。
(3)Learning to NMS
这组方法的主要思想是将NMS视为一个过滤器,用于重新对所有原始检测进行评分,并以端到端方式将NMS作为网络的一部分进行训练。
2.6.7 Technical Evolution of Hard Negative Mining(HNM )
该技术旨在解决背景和物体之间的样本不平衡问题。
(1)Bootstrap
Bootstrap指的是从一小部分背景样本开始训练,然后迭代地增加新的错误分类背景的一组技术。
(2)HNM in deep learning based detectors
在深度学习时代由于算力的发展Bootstrap技术一度被抛弃(2014-2016),Faster RCNN和YOLO尝试通过平衡正负样本间的权重来缓解样本不平衡问题,但后来研究者发现仅通过权重无法解决这个问题,在2016年以后Bootstrap技术又重获新生。
3. SPEED-UP OF DETECTION
如何加快目标检测的速度一直是一个难题,20年来针对这个问题发展出了三个层次的加速技术:
(1)“speed up of detection pipeline”
(2)“speed up of detection engine”
(3)“speed up of numerical computation”
这三个层次的技术又包含了许多具体的方法,如图6所示。

3.1 特征图共享计算
基于滑动窗口的方法的计算冗余通常是因为位置和尺度,前者是由相邻窗口之间的重叠引起的,而后者是由相邻尺度之间的特征相关性引起的。
3.1.1 空间计算冗余与加速
既然分别计算每个滑窗的特征会导致计算冗余,那么自然而然的,最容易想到的方法就是先将整张图片的特征图计算出来,然后再进行滑窗。
3.1.1 规模计算冗余与加速
减少尺度计算冗余,最成功的方法是直接对特征进行缩放,而不是对图像进行缩放,这种方法首次应用于VJ检测器。另外构建“检测器金字塔”也是一种方法,既不改变特征图尺寸而是用多个检测器进行不同尺度物体的检测。
3.2 分类器加速
传统的VJ、DPM等算法一般用计算量较小的线性分类器,但非线性分类器,如SVM这类方法通常有更好地检测精度但计算量大。
SVM这类核方法的计算量随着数据增大而增大,而常用的加速方法是“模型近似”(model approximation)。Reduced Set Vectors就是一个用于SVM的近似方法,该方法旨在用少量的合成向量来获得等价的决策边界(decision boundary)。另一种加速SVM的方法是将其决策边界近似为分段线性形式,从而实现恒定的推理时间。也可以用稀疏编码方法加速核方法。
3.3 级联检测(Cascaded Detection)
它采用了一种由粗到精的检测理念:用简单的计算过滤掉大多数简单的背景窗口,然后用复杂的窗口处理那些更困难的窗口。VJ检测器就是级联检测的代表,而近年来级联检测也用于基于深度学习的检测器,特别是在“大场景中的小目标检测”领域。
3.4 网络剪枝与量化
剪枝指的是剪掉网络中不重要的结构或权重,而量化指的是减少激活或权重的编码长度(code-length)。
网络剪枝
剪枝最早可以追溯到上世纪八十年代,当时Y. LeCun等人使用二阶导数来近似损失函数从而去掉一些不重要的权重。根据这一思路,近些年的剪枝方法通常采取训练和剪枝不断迭代的流程,即在训练过程中不断去除一些不重要的参权重。但只是简单去掉权重可能导致卷积滤波器中出现一些稀疏的连通性模式,因此不能直接用于压缩CNN模型,一个简单的解决方法就是直接去掉一整个滤波器而不仅仅是权重。
网络量化
最近的网络量化工作主要聚焦于如何将网络二值化,也就是把网络的激活或权重量化为二元变量(0或1)。这样就将浮点运算转化为了‘与’、‘或’、‘非’这样的逻辑运算,大大提高了运算速度并减少所需的存储。
网络蒸馏(Network Distillation)
网络蒸馏是一种将大网络(“teacher net”)的知识压缩到小网络(“学student net”)中的通用框架。一种思路是用teacher net来指导轻量级的student net 以便于student net能用于快速检测。另一种方法是对候选区域进行变换,使student net和teacher net之间的特征距离最小。这种方法使检测模型的速度提高了2倍,同时达到了相当的精度。
3.5 轻量级网络设计
与其在现有网络上进行改进加速,不如直接设计一个新的轻量网络。研究者们在近些年来已经提出了多种轻量级网络的设计方法。
3.5.1 分解卷积(Factorizing Convolutions)
分解卷积的思路就是将大的卷积分解为小的卷积,比如一个5x5的卷积核可以用两个3x3的卷积核替代,两者卷积后的感受野不变而两个3x3卷积核的计算量要小于一个5x5卷积核(25>9+9)。
3.5.2 群卷积
群卷积的目的是通过将特征通道分成许多不同的组,然后在每一组上独立进行卷积来减少卷积层中的参数数量,如图7所示。如果我们将特征通道平均分成m组,在不改变其他配置的情况下,理论上卷积的计算复杂度将降低到原来的1/m。

3.5.3 深度可分离卷积(Depth-wise Separable Convolution)
深度可分离卷积是最近流行的一种构建轻量级网络的技术,下面通过一个例子介绍一下这种方法。深度可分离卷积的每个卷积核只对应输入特征图的一个通道,而特征图的每个通道仅由一个卷积核进行卷积,比如输入5x5x3的特征图,那么会有3个卷积核(大小为3x3)分别对应输入的三个通道,然后三个通道分别与对应的卷积核卷积生成三个特征图,具体如图8所示。

但这样只能生成与输入通道数相同的特征图,所以还需要下一步操作。如果我们希望卷积后得到的是4通道的特征图,则可设置4个1x1的卷积核,而上一步得到的特征图有三个通道,那么相应的每个1x1大小的卷积核也需要有3个通道,然后将上一步得到的特征图分别与四个卷积核卷积便可得到最终的结果,具体如图9所示。

参考自知乎:深度可分离卷积
3.5.4 神经网络架构搜索(Neural Architecture Search,NAS)
最近,人们对通过NAS自动设计网络架构了浓厚的兴趣,这样即使我们没有丰富的知识和经验也能设计网络。NAS已经应用于图像分类、目标检测和图像分割等任务中,在轻量级网络设计中也表现可期,在设计网络时同时考虑到了精度和计算复杂度。
4. 目标检测的最新进展
4.1 Detection with Better Engines
这里的engine其实就是指的骨干网络,模型检测性能的好坏非常依赖于提取到的特征。下面点单介绍一下深度学习时代的一些重要的CNN模型。
(1)AlexNet
AlexNet是一个八层深度网络,是第一个在计算机视觉领域开启深度学习革命的CNN模型。
(2)VGG
VGG模型将深度延申到了16-19层,并将5x5或7x7的大卷积核替换为了3x3的小卷机核,在ImageNet数据集上实现了当时的SOTA性能。
(3)GoogLeNet
GoogLeNet是谷歌在2014年提出的模型,其主要的贡献在于提出了分解卷积核批量归一化,增加了模型的深度和宽度(达到22层)。
(4)ResNet
Deep Residual Networks (ResNet),由K. He等人在2015年提出,是一种新型的卷积网络架构,比以前使用的更深(高达152层)。ResNet在2015年赢得了多个计算机视觉竞赛,包括ImageNet检测、ImageNet定位、COCO检测和COCO分割。
(5)DenseNet
DenseNet由G. Huang和Z. Liu等人于2017年提出。ResNet表明CNN中的short cut连接能提高模型的深度和准确度,根据这一思路作者提出了一个稠密连接的模块,前面的每一层都会和后面的层进行连接。
(6)SENet
SENet的主要贡献是集成了全局池化和洗牌(shuffling)来学习特征图的通道重要性。SENet 在 ILSVRC 2017 分类竞赛中获得了第一名。
4.2 Detection with Better Features
图像特征是目标检测的关键,如何获取更好的图像特征一直是研究者努力的方向,近年来的研究可以分为两个方向:(1)特征融合、(2)学习具有大感受野的高分辨率特征
特征融合为何重要?
不变性和等变性是图像特征表示的两个特性,在分类任务中更依赖于图像特征的不变性,而在定位任务中则希望图像特征有更好的等变性,目标检测既要分类也要定位,因此不变性和等变性都十分重要。然而,深层网络特征通常不变性更强而等变性弱,浅层特征则相反,因此,将浅层特征和深层特征融合对于提升模型性能十分重要。
4.2.1 特征融合
(1)Processing flow
这类特征融合方法可以细分为两种:自底向上的方法和自顶向下的方法,具体如图10所示。

图中(a)为自底向上进行特征融合,(b)为自顶向下的特征融合。
(2)逐元素操作(Element-wise operation)
这类融合方法可细分为三种:1.逐元素求和 2.逐元素积 3.拼接(concatenation),如图11所示。
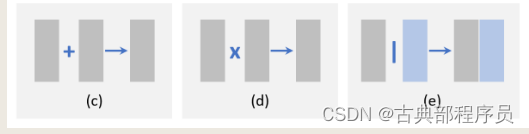
顾名思义,逐元素求和就是两个特征图对应元素分别求和得到一个新特征图,逐元素积同理。逐元素积的一个优点就是可以抑制或强调某一区域的特征。
4.2.2 学习具有大感受野的高分辨率特征
大的感受野可以更好地检测大物体,但感受野大了以后特征图的分辨率就会降低,导致小目标的检测能力下降,如何在保证大感受野的情况下还能有较高的分辨率呢?一种较为实用的方法是使用空洞卷积(dilated/atrous convolution)。空洞卷积其实可以当作普通卷积来计算,只不过卷积核中间填充了0,具体如图12所示。
空洞卷积提高了每一特征的感受野,同时如果合理地设置填充的话还能保持特征图的分辨率,由于篇幅有限详细的信息可以参考以下链接进行学习。在连续使用空洞卷积时扩张率的设置最好是1、2、3这样而不是2、2、2,后者会导致gridding effect(具体见B站链接)。
知乎——空洞卷积
4.3 滑动窗口之外
早期常用的检测方法是滑动窗口,目前已经发展出了许多新的检测方法。
4.3.1 Detection as sub-region search
最近的一种方法是将检测视为一个路径规划过程,从初始网格开始,最终收敛到所需的地面真值框。另一种方法是将检测视为迭代更新过程,以细化预测边界框的角。
4.3.2 Detection as key points localization
由于图像中的任何对象都可以由其地面实况框的左上角和右下角唯一确定,因此,检测任务可以等效地框定为成对关键点定位问题。
4.4 定位的改进
目前有两类提高定位准确度的方法:(1)边界框细化 (2)设计新的损失函数
4.4.1 边界框细化
在实际的检测中一些物体的尺寸可能会出乎我们的意料,通过预先设置的锚框可能难以捕获到物体,这就没法得到精确的位置信息了。因此,引入了“迭代边界框优化”,通过迭代地将检测结果输入到边界框回归器中,直到预测收敛到正确的位置和大小。但一些学者认为该方法并不能保证多次使用边界框回归器后定位效果不会变差。
4.4.2 设计新的损失函数
现在一般将物体的定位问题看作是坐标回归问题,但这种做法存在两个问题。首先,定位的损失函数与真正的定位评估并不对应,即使损失很低但也不能保证预测框和标签框的IoU就大。另外,由于缺少定位的置信度,当存在多个预测框的时候可能会导致非极大值抑制的失败。
设计新的损失函数可以缓解上述问题,最直观的方法就是将IoU作为损失函数。此外,一些研究者也尝试在概率推理框架下改进定位,与以往直接预测框坐标的方法不同,该方法预测了边界框位置的概率分布。
4.5 Learning with Segmentation
最近的研究表明,可以通过语义分割学习来改进目标检测,原因有如下几点:
(1)分割任务能够很好地获取物体的边界信息,这对物体的分类和定位都有帮助。
(2)天空、水、草地等背景元素构成了图像的上下文信息,整合语义分割的上下文信息有助于目标检测,比如飞行器通常会出现在天空而不是在水里。
方法大概有两种:
(1)Learning with enriched features
将分割网络作为一个额外的特征提取器整合到检测框架中,但这就增加了计算量。
(2)Learning with multi-task loss functions
该方法是在原始检测框架之上引入一个额外的分割分支,并使用多任务损失函数(分割损失+检测损失)训练该模型。在推理阶段可以将分割去掉提高检测速度,但在训练阶段需要有像素级别的图像标注。后来一些研究人员遵循了“弱监督学习”的思想,不在像素标注的图像上训练而只用标注了边界框的数据进行训练。
4.6 Robust Detection of Rotation and Scale Changes
物体旋转和尺度变换对目标检测来说是一个挑战,针对这一问题发展出了许多方法。
4.6.1 Rotation Robust Detection
传统的解决物体旋转的方法有两种:一、数据增强,将训练数据进行各个方向的旋转,增强模型对旋转物体的检测能力。二、训练多个检测器来检测不同方向的物体。近年来又提出了一些新的方法。
(1)Rotation invariant loss functions
最近的一些研究在原始的损失函数上引入了约束,使得旋转物体的特征不变。
(2)旋转校准(Rotation calibration)
另一种改进旋转不变性检测的方法是对候选物体进行几何变换。这对多阶段检测器特别有帮助,前一阶段的相关性将有利于随后的检测。这一思想的代表是空间转换网络(STN)。STN现在已经用于旋转文本检测和旋转人脸检测。
(3)Rotation RoI Pooling
在两阶段检测器中,特征池化的目的是首先将任意位置和大小的目标候选区域均匀地划分为一组网格,然后将网格特征连接起来,从而提取出固定长度的特征表示。由于网格划分是在直角坐标系下进行的,其特征对旋转变换不具有不变性。最近的改进是在极坐标下对网格进行网格划分,使特征对旋转变化具有鲁棒性。
4.6.2 Scale Robust Detection
最近在训练和检测阶段都对尺度鲁棒检测进行了改进。
(1)尺度自适应训练(Scale adaptive training)
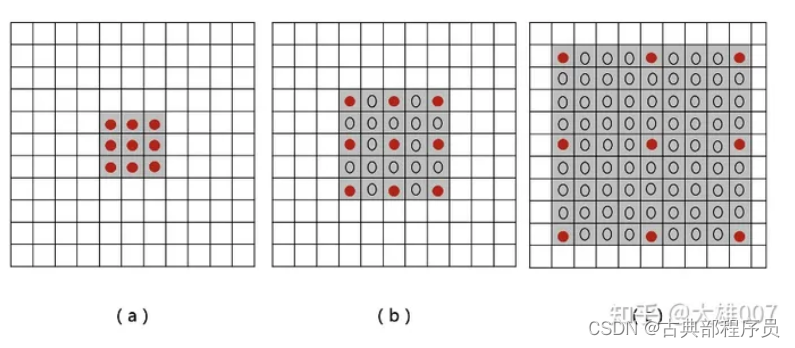
现在的大多数检测器会将输入图片重新缩放到固定的尺度并反向传播所有尺度物体的损失,但由于物体的尺度不同,这种做法会导致“尺度不平衡”。最近的一个方法是图像金字塔的尺度归一化(SNIP),该方法在训练和预测阶段都会构建图像金字塔,并且只会反向传播一些指定尺度的损失,如图13所示。
(2)尺度自适应检测(Scale adaptive detection)
现在的检测方法通常会设置固定大小的锚框,但这有一个缺点就是对于一些没预料到的尺度可能没法很好地检测。为了提高小目标检测能力,一些算法使用了自适应放大技术来将小目标放大,从而利于检测。最近的另一个改进是学习预测图像中物体的比例分布,然后根据分布自适应地重新缩放图像。
4.7 从零开始训练(Training from Scratch)
我们通常会在ImageNet等数据集上进行预训练,在此基础上针对特定任务对模型进行微调。这种做法可能会对模型的训练速度有帮助,但并不一定能提高准确率。
4.8 对抗训练(Adversarial Training)
生成对抗网络(GAN)由A. Goodfellow等人在2014年提出,近年来得到了广泛关注。经典的GAN由生成器网络和鉴别器网络组成,通常,生成器学习从潜在空间映射到感兴趣的特定数据分布,而鉴别器旨在区分真实数据分布的实例和生成器生成的实例。GAN常用于图像生成、图像风格的迁移等任务,最近也被应用于目标检测中,特别是小目标和遮挡目标的检测任务中。
4.9 弱监督目标检测(Weakly Supervised Object Detection)
通常我们要训练一个目标检测模型的话需要有提前标注好的数据集,而人工标注数据集不仅费时费力费钱,而且效率还低,而通过弱监督来进行训练可以在一定程度上解决这个问题。
5 应用
目标检测主要有以下几个方面都应用:
(1)行人检测
(2)人脸检测
(3)文本检测
(4)交通标志和交通灯检测
(5)遥感目标检测

















 284
284

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









