






前期准备
基础知识:
- Python语言:Python的基础语法,包括变量、数据类型、控制结构(if语句、for循环、while循环等)、函数等。
- HTML和CSS:了解HTML的基础结构,如何定义标签、属性等,以及CSS选择器的基本使用,因为BeautifulSoup库使用CSS选择器来定位HTML元素。
- 网络基础:了解HTTP请求的基本概念,GET请求、请求头、状态码等。
学习使用的库和工具:
- requests库:学习如何使用requests库发送HTTP请求,获取网页内容。
- BeautifulSoup库:学习BeautifulSoup的基本用法,如何解析HTML,以及如何使用选择器找到所需的元素。
- os模块:了解os模块的基本功能,如检查路径是否存在、创建目录等。
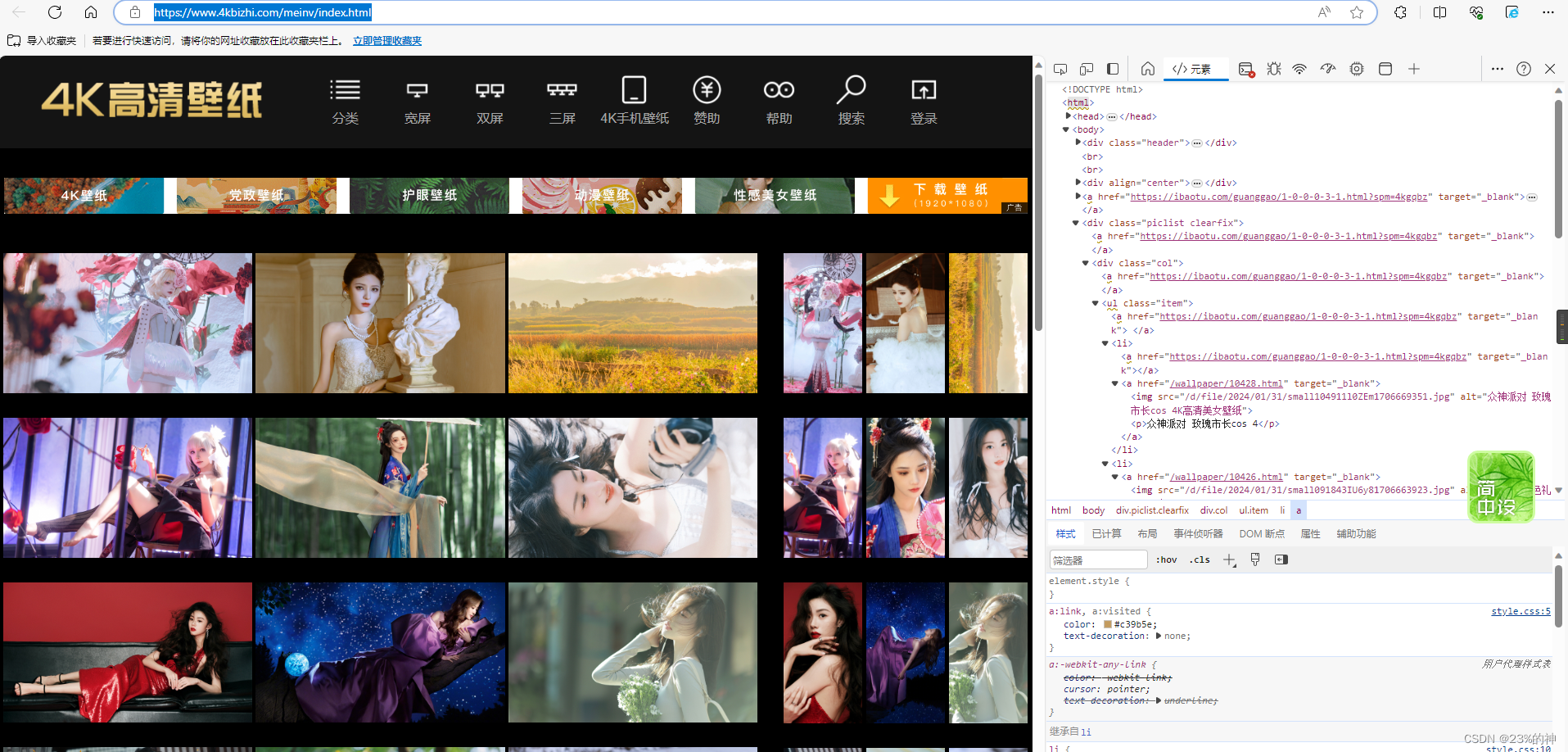
打开要爬取的网页,所有的网页数据理论上看到即能拿到,因为他必然存在,后端通过什么方式提供展示,前端就能反方向通过该路径获取。静态的可以通过get请求直接拿到,动态渲染的需要模拟用户行为来反爬或者等待加载。
这里只展示一下静态的资源拿取流程。
打开f12,找到鼠标点击元素寻找代码部分或者浏览代码部分找到目标元素高亮的地方。
最终确定标签结构的定位。
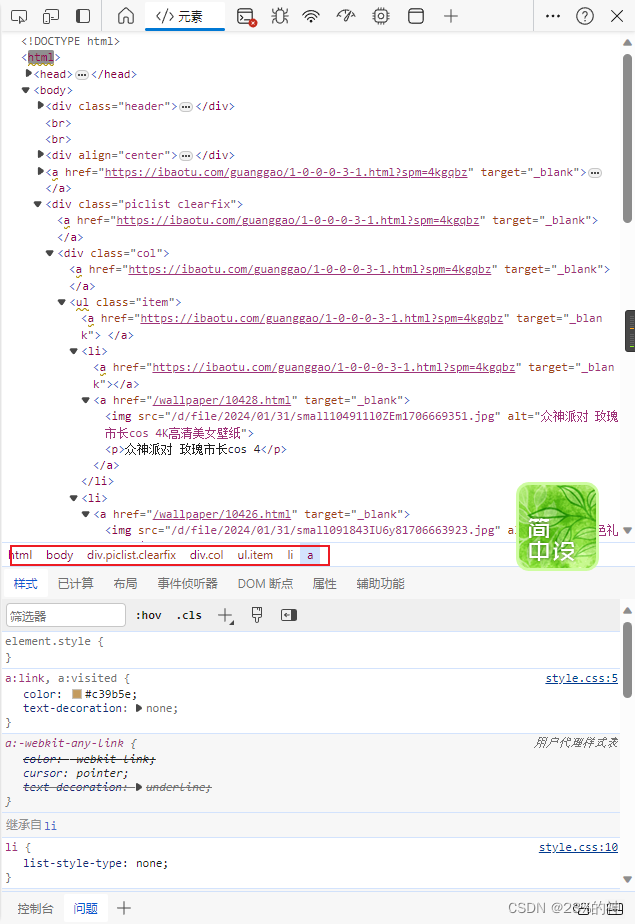
截止到这,资源已经可以拿到了,点击img标签的src即可跳转到图片位置,说明没有问题~
直接上代码!
import os
import requests
from urllib.parse import urljoin
from bs4 import BeautifulSoup
# 设置请求头,模拟真人请求
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Referer': 'https://www.google.com/', # 添加Referer字段,模仿请求来源
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8', # 添加Accept-Language字段,表示接受的语言类型
'Connection': 'keep-alive', # 保持连接,以便于连续发送请求
}
# 获取图片链接
def getImg(url):
# 发送HTTP请求
response = requests.get(url, headers=headers)
# 检查请求是否成功
if response.status_code == 200:
print('网页使用编码:' + response.encoding)
print('\n')
response.encoding = 'gbk' # 手动设置编码为gbk,以防止乱码
# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(response.text, 'html.parser')
# 找到所有符合条件的元素,这里选择器'.item li a img'表示选择类名为)item的元素下的li元素中的a元素内的img元素
items = soup.select('.item li a img')
# 创建一个列表用来接住所有的图片链接
imgurls = []
# 检查是否找到了任何元素
if len(items) != 0:
# 处理每个元素
for item in items:
# 获取图片链接
img_url = item['src']
# 将相对地址补全为绝对地址
imgAddress = urljoin('https://www.4kbizhi.com/', img_url)
# 把拿到的链接添加到列表中
imgurls.append(imgAddress)
# 打印结果
print(imgAddress)
return imgurls
else:
print('没有找到任何图片链接。')
else:
print('请求失败,状态码:', response.status_code)
# 下载图片
def downloadImg(img_url, save_dir, img_name):
# 发送HTTP请求获取图片数据
response = requests.get(img_url)
# 检查请求是否成功
if response.status_code == 200:
# 检查目录是否存在,不存在则创建
if not os.path.exists(save_dir):
os.makedirs(save_dir)
# 拼接图片的完整保存路径
img_path = os.path.join(save_dir, img_name)
# 以二进制写模式打开文件,并将图片数据写入文件
with open(img_path, 'wb') as f:
f.write(response.content)
# 打印成功消息
print(f'{img_name} 下载成功,保存在 {img_path}')
else:
# 打印失败消息和状态码
print(f'下载失败,状态码:{response.status_code}')
# 主函数
def main():
# 输入网页链接和保存路径
url = 'https://www.4kbizhi.com/meinv/index.html'
savePath = 'E://图片\Spider\\2024.1.31'
# 获取图片链接列表
Imgurls = getImg(url)
print(Imgurls)
# 遍历链接列表并下载图片
for i, img_url in enumerate(Imgurls, 1):
img_name = f'无敌{i}号.jpg' # 根据需要修改图片名称
# 下载每张图片
downloadImg(img_url, savePath, img_name)
# 启动主函数
if __name__ == "__main__":
main()
- 用到的库先安装

- 即使是静态资源拿取也尽量定义好请求头,不然机器看你都呆呆的

- 两个方法,一个获取所有图片链接,一个使用获取到的链接把图片下载到本地
- 流程是先用request库将网页拿回来,是个字符串(刚看到文章说request库的coder失业了。。离谱)。

- 带有标签的树结构的字符串拿到了,使用beautifulSoup库定位元素(解析)
 这里直接从item开始而没用到从body级别一级一级下来,是beautifulSoup提供的方法。具体看一下文档,还有findall,selectone等方法,都很好用。
这里直接从item开始而没用到从body级别一级一级下来,是beautifulSoup提供的方法。具体看一下文档,还有findall,selectone等方法,都很好用。 - 拿到的图片或者其他资源地址一般都是相对地址,网页中点进去看一下前面拼接的部分是什么就好了。
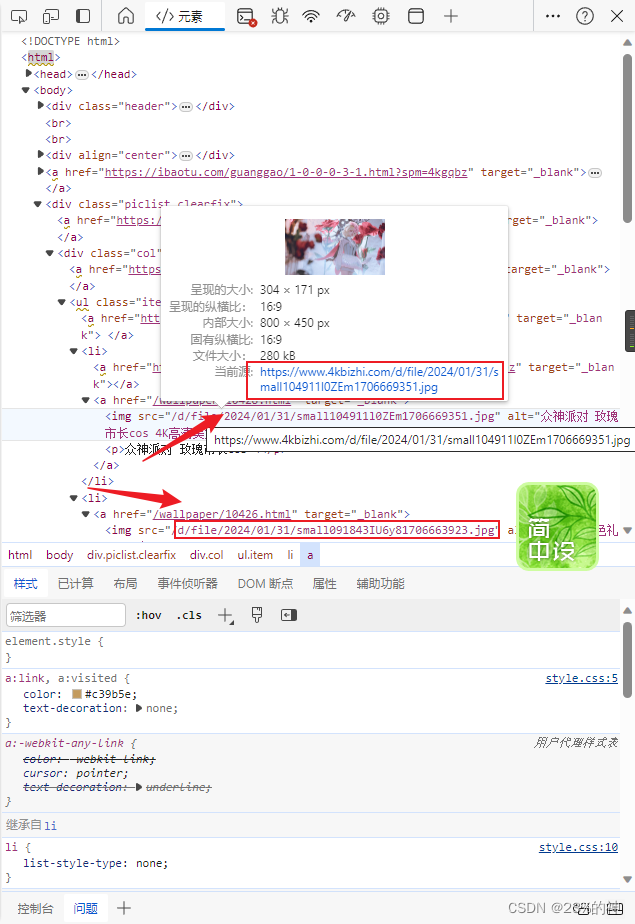
- IO操作创建文件夹保存进去就ok了。pythonIO比java简单的多~
- 本篇仅供学习,也只简单的拿取了一页图片,可以试着模拟翻页递归获取所有资源。















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









