







 本文详细阐述了基础循环神经网络的工作原理,包括Elman神经网络定理,算法实现步骤,优缺点比较,以及在自然语言处理、音乐生成等领域的应用。同时对比了RNN与传统统计模型、LSTM、GRU和Transformer等其他模型的差异。
本文详细阐述了基础循环神经网络的工作原理,包括Elman神经网络定理,算法实现步骤,优缺点比较,以及在自然语言处理、音乐生成等领域的应用。同时对比了RNN与传统统计模型、LSTM、GRU和Transformer等其他模型的差异。
目录
1.引言与背景
在信息爆炸的时代,处理和理解序列数据的能力成为人工智能领域的重要挑战。从自然语言文本、语音信号、时间序列分析到音乐生成,这些复杂的数据形式都具有显著的时序依赖特性,传统浅层模型往往难以捕捉其内在的时间动态性。为此,循环神经网络(Recurrent Neural Network, RNN)应运而生,尤其在处理序列数据任务中展现出强大的建模能力。本文将聚焦于基础循环神经网络(Basic RNN),深入剖析其理论基础、工作原理以及算法实现细节。
2.Elman神经网络定理
基础循环神经网络的理论基石可追溯至Elman神经网络定理。该定理指出,通过引入循环连接结构,RNN能够以递归方式捕获并积累输入序列的历史信息,从而构建一个动态状态表示,该表示随时间演化并反映当前时刻的上下文信息。具体而言,Elman神经网络定理强调了以下关键特性:
-
记忆机制:RNN通过内部隐藏状态(hidden state)存储过去的信息。每一时刻的隐藏状态不仅取决于当前时刻的输入,还与前一时刻的隐藏状态有关,形成一种隐式记忆链,使得网络能够在处理长序列时保留远期历史的影响。
-
参数共享:RNN的权重在时间维度上是共享的,这意味着相同的参数集用于处理序列中的所有时间步。这种设计极大地减少了模型参数量,增强了泛化能力和训练效率,并使网络能以一致的方式处理不同长度的序列。
-
动态计算:对于给定的输入序列,RNN在每个时间步进行一次前向传播,根据当前输入和前一时刻的隐藏状态更新隐藏状态,并据此产生输出。这种动态计算过程允许网络在处理过程中适应输入变化,实时调整其内部状态以适应新的输入特征。
3.算法原理
基础循环神经网络的核心架构包括输入层、隐藏层和输出层,其中隐藏层包含循环连接,形成反馈回路。其工作流程如下:
-
输入层:接收当前时间步的输入向量
x_t,通常对原始数据进行预处理(如词嵌入)以适配网络输入。 -
隐藏层:隐藏状态
h_t是网络的记忆单元,由两部分组成:- 当前输入影响:通过一个权重矩阵
W_xh将输入向量x_t与隐藏层进行线性变换,得到当前输入对隐藏状态的贡献。 - 历史信息继承:通过另一个权重矩阵
W_hh和一个偏置项b_h将前一时刻的隐藏状态h_{t-1}传递至当前时刻,保持时间上的连续性。
综合这两部分影响,隐藏状态
h_t的更新公式为: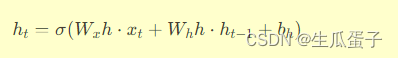
其中,
\sigma表示激活函数(如sigmoid、tanh等),用于引入非线性以增加模型表达能力。 - 当前输入影响:通过一个权重矩阵
-
输出层:基于当前时刻的隐藏状态
h_t,通过权重矩阵W_hy和偏置项b_y生成输出向量y_t,可能进一步经过softmax等操作以得到概率分布或回归值。输出层的计算公式为: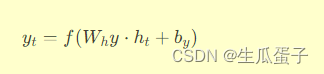
其中,
f表示输出层所需的特定转换函数,如softmax函数、线性激活等。 -
反向传播与训练:由于RNN存在时间上的循环依赖,传统的反向传播算法需要通过BPTT(Backpropagation Through Time)进行扩展。BPTT通过展开网络在时间维度上的计算图,计算梯度并沿时间反向传播,更新模型参数。同时,为应对训练过程中可能出现的梯度消失/爆炸问题,可以采用诸如梯度裁剪、LSTM(Long Short-Term Memory)或GRU(Gated Recurrent Unit)等改进型RNN结构,以及正则化、残差连接等技术。
4.算法实现
实现基础循环神经网络涉及以下几个关键步骤:
数据准备:对序列数据进行预处理,如分词、编码、填充/截断至固定长度等,以适应RNN的输入要求。同时,划分训练集、验证集和测试集。
模型定义:定义隐藏层(包括循环连接和激活函数)、输出层(含相应的转换函数),以及损失函数和优化器。以下是一个使用Python和PyTorch框架的基本RNN模型实现示例:
Python
import torch
import torch.nn as nn
class BasicRNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_layers=1, dropout=0.0):
super(BasicRNN, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
# 定义RNN层
self.rnn = nn.RNN(input_size, hidden_size, num_layers, batch_first=True, dropout=dropout)
# 定义输出层
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x, hidden=None):
batch_size = x.size(0)
# RNN前向传播
out, hidden = self.rnn(x, hidden)
# 取最后一个时间步的隐藏状态作为序列的最终表示
out = out[:, -1, :]
# 输出层计算
out = self.fc(out)
return out, hidden
# 示例:创建一个BasicRNN模型,输入维度为100,隐藏层维度为256,输出维度为50
model = BasicRNN(input_size=100, hidden_size=256, output_size=50)
# 初始化隐藏状态(若未指定,则默认为零初始化)
hidden = model.init_hidden(batch_size=32)-
模型训练:
下面是一个简化的训练循环示例:
- 前向传播:将预处理后的输入数据送入模型,计算预测输出和损失。
- 反向传播与参数更新:使用BPTT计算梯度,通过优化器(如Adam、SGD等)更新模型参数。
- 监控与调整:记录训练过程中的损失和验证指标(如准确率),根据需要调整学习率、正则化强度等超参数,或应用早停策略。
-
Python
import torch.optim as optim # 定义损失函数和优化器 criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=0.001) # 训练循环 for epoch in range(num_epochs): for inputs, targets in train_loader: # 前向传播 outputs, _ = model(inputs) loss = criterion(outputs, targets) # 反向传播与参数更新 optimizer.zero_grad() loss.backward() optimizer.step() # 每个epoch结束后评估模型性能并保存最佳模型 with torch.no_grad(): val_loss, val_acc = evaluate_model(model, val_loader) if val_loss < best_val_loss: best_val_loss = val_loss torch.save(model.state_dict(), 'best_model.pth') - 模型评估与应用:在测试集上评估模型性能,可能涉及计算各种评价指标(如准确率、F1分数、困惑度等)。对于实际应用,将训练好的模型部署到相应环境中,如作为服务端接口、嵌入到移动应用或集成到数据分析流水线中。
-
综上所述,基础循环神经网络的实现涵盖了数据预处理、模型定义、训练、评估与应用等多个环节。通过深入理解和熟练掌握这些步骤,研究者和开发者能够有效地利用RNN解决各类序列数据问题,挖掘时序数据中蕴含的丰富信息。
5.优缺点分析
基本循环神经网络(Basic RNN)的优点:
-
处理序列数据:RNN特别适合处理具有时间顺序或依赖关系的序列数据,如文本、语音、视频帧序列等。其内部的循环结构允许网络在处理当前输入的同时,考虑过去的信息,能够捕获序列数据中的时间依赖性。
-
变长输入输出:RNN可以处理任意长度的输入序列,并产生相应长度的输出序列,无需固定数据维度,具有良好的灵活性,适应多种序列建模任务。
-
非线性建模能力:与线性统计模型相比,RNN通过隐藏状态和非线性激活函数(如sigmoid、tanh等)能够捕捉数据中的非线性关系,对于复杂序列模式的建模能力更强。
-
端到端学习:RNN可以作为一个完整的模型,从原始序列数据中直接学习到复杂的映射关系,无需人工设计复杂的特征工程,实现了从输入到输出的端到端训练。
-
参数共享:在处理序列数据时,RNN的循环单元(如隐藏层)在每个时间步使用相同的权重矩阵,这种参数共享机制大大减少了模型参数数量,有利于减少过拟合风险并提高模型的泛化能力。
基本循环神经网络(Basic RNN)的缺点:
-
梯度消失/爆炸问题:在处理长序列时,由于反向传播过程中连乘的Jacobian矩阵可能导致梯度要么快速衰减至接近于零(梯度消失),要么指数级增长(梯度爆炸),使得网络难以学习到远距离的依赖关系。
-
训练困难:RNN的训练通常比前馈神经网络更复杂,需要进行反向传播通过时间(BPTT),这可能导致收敛速度慢,对优化算法和超参数设置要求较高。
-
计算效率:由于RNN的递归特性,其计算通常是序列化的,不能像CNN那样利用高度并行化的硬件(如GPU)进行高效计算,尤其在处理长序列时,训练和推理速度可能相对较慢。
-
长期依赖建模不足:尽管理论上RNN可以捕捉任意长度的依赖,但在实际应用中,随着序列长度增加,RNN往往难以有效利用远期历史信息,对长距离依赖的建模能力有限。
-
缺乏位置敏感性:基础RNN在处理序列数据时,对位置信息的处理相对模糊,没有显式的位置编码,可能在需要明确位置信息的任务中表现不佳。
6.案例应用
基础循环神经网络(Basic RNN)因其对序列数据的强大建模能力,在众多实际应用中展现出显著效果。以下列举几个典型的应用场景:
自然语言处理(NLP)
情感分析:在社交媒体、产品评论等文本数据中,RNN能够捕捉词汇间的语义关系和情感倾向的演变,从而实现对文本情感极性的精准分类。例如,通过对用户评论进行分词、编码后输入RNN模型,模型可依据评论内容的上下文信息判断其整体情感倾向(如积极、消极或中性)。
机器翻译:RNN可以作为序列到序列(seq2seq)模型的基础,其中编码器RNN捕获源语言句子的语义信息,解码器RNN生成目标语言的翻译结果。RNN的循环结构确保了翻译过程中对原文句法和语义连贯性的保持。
语音识别:语音信号是一种典型的时序数据,RNN能有效处理语音帧间的时域依赖,将其转化为文字序列。在声学模型中,RNN常与卷积神经网络(CNN)结合,共同提取和建模语音特征,提升识别精度。
音乐生成:RNN可以学习音乐序列的节奏、和声和旋律模式,生成风格连贯的新曲目。模型接受一系列音符作为输入,学习音乐结构的内在规律,进而创作出新颖且符合人类审美标准的乐曲。
时间序列预测
股票价格预测:金融市场数据具有明显的时序特征,RNN能够捕捉价格波动的周期性和趋势性变化。通过输入历史交易数据(如开盘价、收盘价、成交量等),RNN模型可以对未来股价走势进行预测,为投资者提供决策支持。
电力负荷预测:电力系统中,用电需求随时间呈现出一定的规律性和随机性。RNN模型可以整合历史负荷数据、天气预报、节假日等因素,准确预测未来时段的电力需求,有助于电网调度和规划。
生物医学信号分析
心电图(ECG)异常检测:RNN能够解析ECG信号的时间序列特征,识别出心率失常、心肌梗死等疾病迹象。通过学习正常和异常ECG样本的时序模式,RNN模型可实现对实时监测数据的自动诊断,提高医疗保健的效率和准确性。
基因序列分析:RNN可用于分析DNA或蛋白质序列,预测基因功能、识别转录因子结合位点或进行序列比对。模型通过学习碱基或氨基酸间的上下文关系,揭示生物分子的结构和功能特性。
7.对比与其他算法
与传统统计模型对比:
相较于ARIMA、自回归模型等传统统计方法,RNN具有更强的非线性表达能力和大规模数据学习能力,能更好地捕捉复杂序列数据中的非线性关系和长期依赖。然而,传统统计模型如ARIMA在处理线性关系和短期平稳时间序列时,由于其参数化的简洁性和解释性强,仍具有优势。ARIMA模型通过自回归(AR)、差分(I)和移动平均(MA)组件来刻画时间序列的线性趋势、季节性以及随机波动,并且在模型建立过程中往往需要较少的计算资源。相比之下,RNN虽然更适用于处理非线性关系和非平稳序列,但其训练过程通常更为复杂,可能需要更多的计算资源和更长的训练时间。
与深度学习中的其他序列模型对比:
与LSTM和GRU对比: 长短期记忆网络(LSTM)和门控循环单元(GRU)是RNN的变种,它们在设计上针对RNN的梯度消失/爆炸问题进行了改进,更擅长捕捉长时间跨度的依赖关系。LSTM通过引入输入门、遗忘门和输出门,精确控制信息的存储、更新和输出;GRU则通过更新门和重置门简化了LSTM的结构,同样能够有效地避免梯度问题并保留长期记忆。因此,尽管基础RNN在处理较短序列或对计算资源有限制的场景下仍有一定适用性,但在涉及复杂、长期依赖关系的任务中,LSTM和GRU通常表现更优。
与Transformer对比: Transformer模型摒弃了RNN的循环结构,采用自注意力机制直接对整个序列进行全局建模,这使得Transformer能够在理论上并行处理序列数据,极大地提升了训练效率。Transformer在处理长序列时,尤其是对于跨越长距离的依赖关系,表现出超越RNN家族模型的能力。此外,Transformer在诸如自然语言处理(NLP)领域的多项任务中取得了突破性成果,如机器翻译、问答系统等。尽管基础RNN在某些轻量级应用或资源受限环境中仍有一定的价值,但面对大规模、高复杂度的序列数据任务,Transformer已成为首选模型。
与卷积神经网络(CNN)对比: CNN在处理如图像、音频等具有局部结构和固定模式的数据时表现出色,通过卷积层和池化层能够自动提取特征并进行空间或时间上的降维。尽管CNN也能应用于一维时间序列分析(如通过一维卷积),但它通常更适合于处理具有明确局部特征和较强空间/时间局部相关性的数据,而对长程依赖的建模不如RNN系列模型直接和灵活。在处理文本、语音等序列数据时,RNN通常能提供更好的性能,尤其是在理解上下文和保持时序信息方面。
8.结论与展望
基础循环神经网络(Basic RNN)作为一种经典的时间序列建模工具,其对序列数据的内在联系和动态演化有着独特的建模能力。尽管在处理非线性关系、长期依赖以及大规模数据方面优于传统统计模型,但在面对更复杂的序列建模任务,特别是当数据包含长距离依赖或需要高效并行处理时,RNN的局限性逐渐显现,这时其变种如LSTM、GRU,乃至Transformer等新型模型更具优势。
展望未来,研究将继续探索如何进一步优化RNN及其变种的结构和训练方法,以提高其处理长程依赖和大规模数据的效率。同时,结合领域知识和先验信息构建混合模型,将RNN与其他模型(如统计模型、CNN、Transformer等)进行深度融合,有望在特定应用场景中实现更高精度和更高效的序列建模。随着计算硬件的发展和算法创新,诸如轻量级RNN架构、自适应学习率调整、二阶优化方法等技术将进一步提升RNN模型的实用性和泛化能力。此外,研究如何将RNN更好地融入边缘计算、物联网(IoT)等资源受限环境,以及如何利用RNN进行可解释性建模,将是未来研究的重要方向。总的来说,尽管面临竞争激烈的序列建模领域,基础RNN及其衍生模型仍将在诸多应用中发挥不可或缺的作用,并持续推动人工智能技术的发展。

















 1466
1466

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









