







目录
1. 引言与背景
生成对抗网络(GANs)作为无监督机器学习领域的一种强大工具,尤其在生成高度逼真、接近真实世界分布的合成数据方面取得了显著成果。然而,GANs常常面临训练不稳定性与模式崩溃问题,制约了其性能与实际应用。为解决这些问题,Mao等人于2017年提出了最小二乘生成对抗网络(LSGAN),用最小二乘损失函数替代了原有的二元交叉熵损失。本文将对LSGAN进行全面探讨,涵盖其理论基础、算法原理、实现细节、优缺点分析、实际应用案例、与其他算法的对比,以及未来展望。
2. LSGAN定理
LSGAN建立在GAN基本原理之上,即两个神经网络——生成器(G)与判别器(D)通过一种极小极大博弈相互作用。但LSGAN对目标函数进行了改造,采用了最小二乘损失而非二元交叉熵。LSGAN背后的中心定理是将GAN目标转化为一个最小二乘优化问题:
定理: 给定真实数据分布与生成器分布
,LSGAN旨在最小化两者之间的皮尔逊χ²散度:
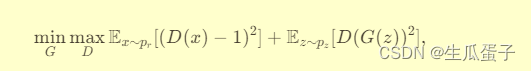
其中x代表真实样本,z表示从先验分布抽取的噪声向量,而G(z)生成伪造样本。判别器D被训练以对真实数据预测接近1的值,对生成数据预测接近0的值;生成器G则力求生成能欺骗判别器使其预测接近1的样本。
3. 算法原理
LSGAN的主要改动在于对生成器和判别器采用不同的损失函数:
- 判别器损失(D-loss):LSGAN不再使用二元交叉熵,而是采用最小二乘损失来惩罚判别器预测与期望目标(对真实数据为1,对生成数据为0)之间的平方差。
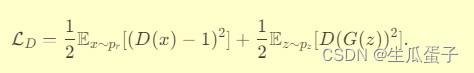
- 生成器损失(G-loss):生成器损失同样源于最小二乘损失,旨在最小化判别器对生成样本预测与目标值1之间的平方差。
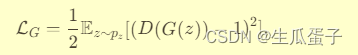
这一损失函数的改变导致了更平滑的优化景观,缓解了梯度消失问题,促进了更稳定的训练动态。
4. 算法实现
实现一个LSGAN需遵循以下步骤:
-
网络架构:定义生成器与判别器网络的架构,通常在图像生成任务中使用卷积或反卷积层。
-
训练循环:
- 抽样一批真实数据x和噪声向量z。
- 通过反向传播与优化器(如Adam)更新判别器,以最小化
。
- 冻结判别器参数,通过相同优化器更新生成器,以最小化
。
- 重复步骤1-2直至多轮迭代达到收敛。
-
后处理(可选):对生成器网络进行微调或应用额外技术(如特征匹配、谱归一化)以进一步提升生成样本质量。
要实现最小二乘生成对抗网络(LSGAN)算法,可以使用Python编程语言结合深度学习库如PyTorch。以下是一个简化的LSGAN实现示例,包括必要的代码段和相应的讲解:
Python
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# 定义生成器和判别器网络结构
class Generator(nn.Module):
def __init__(self, latent_dim, output_dim):
super(Generator, self).__init__()
# 这里仅给出一个简单的示例结构,实际应用中可能需要更复杂的架构
self.model = nn.Sequential(
nn.Linear(latent_dim, 256),
nn.ReLU(),
nn.Linear(256, 128),
nn.ReLU(),
nn.Linear(128, output_dim),
nn.Tanh() # 输出限制在[-1, 1]区间
)
def forward(self, z):
return self.model(z)
class Discriminator(nn.Module):
def __init__(self, input_dim):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(input_dim, 128),
nn.LeakyReLU(0.2),
nn.Linear(128, 256),
nn.LeakyReLU(0.2),
nn.Linear(256, 1),
nn.Sigmoid() # 输出概率值
)
def forward(self, x):
return self.model(x)
# 设置实验参数
latent_dim = 100
input_dim = 784 # MNIST图像尺寸为28x28,展平后为784
batch_size = 64
num_epochs = 100
learning_rate = 0.0002
# 数据预处理与加载
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
# 实例化生成器和判别器
generator = Generator(latent_dim, output_dim=input_dim)
discriminator = Discriminator(input_dim)
# 定义优化器
g_optimizer = optim.Adam(generator.parameters(), lr=learning_rate)
d_optimizer = optim.Adam(discriminator.parameters(), lr=learning_rate)
# 训练循环
for epoch in range(num_epochs):
for real_images, _ in dataloader:
real_images = real_images.view(-1, input_dim).to(device) # 将数据送入GPU(如有)
# 更新判别器
d_optimizer.zero_grad()
real_labels = torch.ones(batch_size, 1).to(device) # 真实数据标签为1
fake_labels = torch.zeros(batch_size, 1).to(device) # 生成数据标签为0
real_scores = discriminator(real_images)
real_loss = nn.MSELoss()(real_scores, real_labels) # 使用最小二乘损失
noise = torch.randn(batch_size, latent_dim).to(device)
fake_images = generator(noise)
fake_scores = discriminator(fake_images)
fake_loss = nn.MSELoss()(fake_scores, fake_labels)
d_loss = real_loss + fake_loss
d_loss.backward()
d_optimizer.step()
# 更新生成器
g_optimizer.zero_grad()
fake_labels.fill_(1) # 对生成器而言,希望判别器输出为1
fake_scores = discriminator(fake_images.detach()) # 防止反向传播到判别器
g_loss = nn.MSELoss()(fake_scores, fake_labels)
g_loss.backward()
g_optimizer.step()
# 打印训练进度
if (epoch+1) % 10 == 0:
print(f"Epoch [{epoch+1}/{num_epochs}], D Loss: {d_loss.item():.4f}, G Loss: {g_loss.item():.4f}")
# 保存模型权重
torch.save(generator.state_dict(), 'lsrgan_generator.pth')
torch.save(discriminator.state_dict(), 'lsrgan_discriminator.pth')代码讲解:
-
定义生成器和判别器网络结构:使用
nn.Module基类创建生成器(Generator)和判别器(Discriminator)类。这里仅给出了一个简化的线性层堆叠示例,实际应用中可能需要使用卷积神经网络(CNN)。生成器最后使用Tanh激活函数确保输出在[-1, 1]范围内,判别器使用Sigmoid输出概率值。 -
设置实验参数:指定隐变量维度、输入维度、批次大小、训练轮数、学习率等参数。
-
数据预处理与加载:使用MNIST数据集作为示例,对其进行预处理(转为张量、标准化)并创建数据加载器。
-
实例化生成器和判别器:根据设定的网络结构创建生成器和判别器对象,并为它们分别指定Adam优化器。
-
训练循环:
-
每个epoch内,遍历数据加载器中的每个批次。
-
更新判别器:
- 清空判别器的梯度。
- 为真实数据和生成数据分别计算标签(1和0)。
- 使用最小二乘损失(
nn.MSELoss())计算真实数据得分与真实标签、生成数据得分与生成标签之间的损失。 - 反向传播损失并更新判别器参数。
-
更新生成器:
- 清空生成器的梯度。
- 生成新的假图像,并计算其在判别器上的得分,但此时需使用
.detach()防止梯度回传至判别器。 - 使用最小二乘损失计算生成图像得分与期望标签(全为1)之间的损失。
- 反向传播损失并更新生成器参数。
-
定期打印训练进度。
-
-
保存模型权重:训练完成后,保存生成器和判别器的权重以供后续使用。
以上代码实现了LSGAN的基本训练流程。在实际应用中,可能还需要添加更多的超参数调整、模型评估、可视化等环节。
5. 优缺点分析
优点:
- 稳定训练:相比于原始GAN,LSGAN展现出更好的训练稳定性,降低了模式崩溃与梯度消失的可能性。
- 良好的梯度流:最小二乘损失即使在判别器高度自信时仍提供有意义的梯度,有助于生成器的学习过程。
- 视觉质量:LSGAN生成的样本往往比基于二元交叉熵的同类模型具有更少瑕疵,视觉效果更佳。
缺点:
- 收敛速度:尽管LSGAN提供了更稳定的训练,但可能比其他GAN变体收敛得慢,需要更多训练迭代才能达到相似效果。
- 对超参数敏感:LSGAN的性能可能对学习率、优化器设置、架构细节等超参数的选择非常敏感,需要精心调整。
6. 实际应用案例
LSGAN已在多个领域得到成功应用:
- 图像合成:生成高质量的人脸、物体、场景图像,通常在视觉保真度与多样性上优于原始GAN。
- 图像到图像转换:在条件信息引导下将图像从一个域转换到另一个域(如草图转照片、黑白转彩色),利用条件信息指导生成过程。
- 视频生成:生成连贯的视频序列,展示了LSGAN在建模时序依赖性和生成动态内容方面的潜力。
7. 与其他算法对比
原始GAN vs. LSGAN:
- 损失函数:原始GAN使用二元交叉熵损失,而LSGAN采用最小二乘损失,导致LSGAN在训练稳定性和视觉质量上有所提升。
- 收敛行为:原始GAN可能出现模式崩溃或梯度消失,而LSGAN趋向于有更平稳的收敛过程,但可能收敛速度较慢。
Wasserstein GANs(WGANs)vs. LSGANs:
- 损失函数:WGANs利用Wasserstein距离体现Earth Mover's Distance(EMD),而LSGANs依赖于Pearson χ²散度。两者均旨在提供更有意义的梯度并缓解训练不稳定现象。
- 梯度惩罚:WGANs常包含梯度惩罚项以强制满足Lipschitz连续性,这在LSGANs中并不需要。
- 性能:WGANs和LSGANs都能生成高质量样本,WGANs有时表现出更快的收敛速度和更好的模式覆盖。
8. 结论与展望
最小二乘生成对抗网络是GAN研究的重要进展,解决了与训练稳定性和模式崩溃相关的关键问题。其采用最小二乘损失函数导致了更平滑的优化景观、更好的梯度流,以及在各类应用中生成样本的视觉质量提升。虽然LSGAN仍面临对超参数敏感、可能收敛较慢等问题,但持续的研究正不断对其进行完善和扩展。
LSGAN的未来发展方向可能包括:
- 与先进训练技术融合:将LSGAN与渐进增长、谱归一化、自注意力机制等最新进展结合,进一步提升性能与稳定性。
- 应用于新领域:探索LSGAN在新兴领域(如三维形状生成、音频合成、分子设计)的潜力。
- 理论发展:深入阐述LSGAN的数学基础,可能揭示GAN优化景观的新见解,并指导设计出更稳健、高效的生成模型。

















 1106
1106

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









