






动漫链接的爬取
在此声明,以下内容纯粹是学习交流所用
首选第一步应该获取网页地址
如下选取的是樱花动漫
分析其网站首页,发现该网站具有搜索功能
随便在里面输入几个数据

点击搜索,查看其跳转到的页面的url
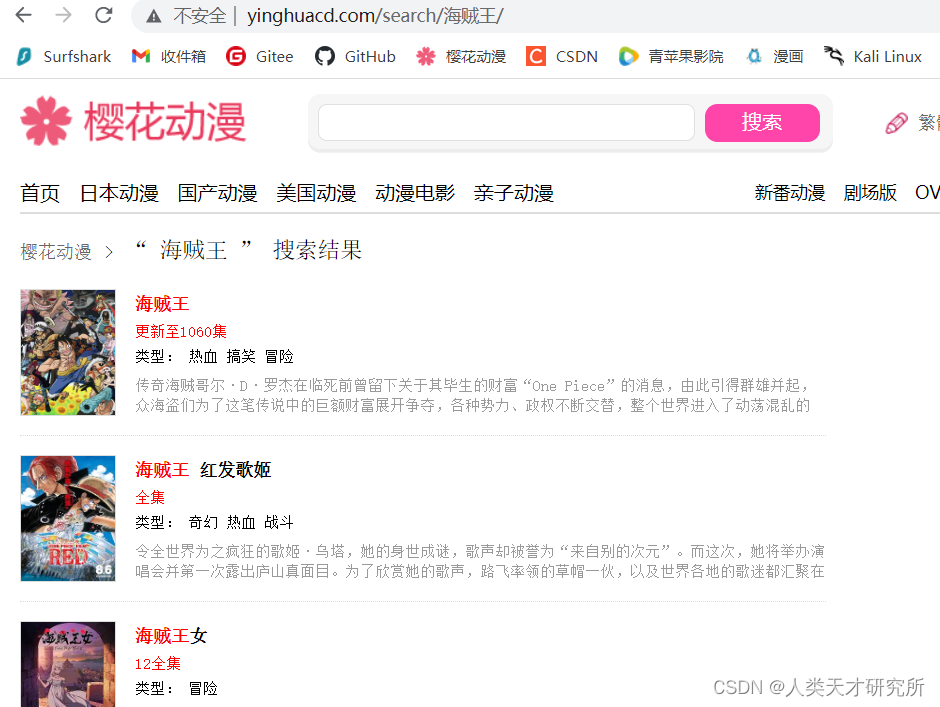
下面是部分 代码。
url = 'http://www.yinghuacd.com/'#网页地址
url = url_+'/search/'+key_word#拼接网页地址
response = get_response(url)
def get_response(url):
response = requests.get(url)#网页请求
response.encoding = 'utf-8'#指定编码
return response
当然,此时返回的是页面的原本数据。
然后分析该页面的结构,找到想要的元素
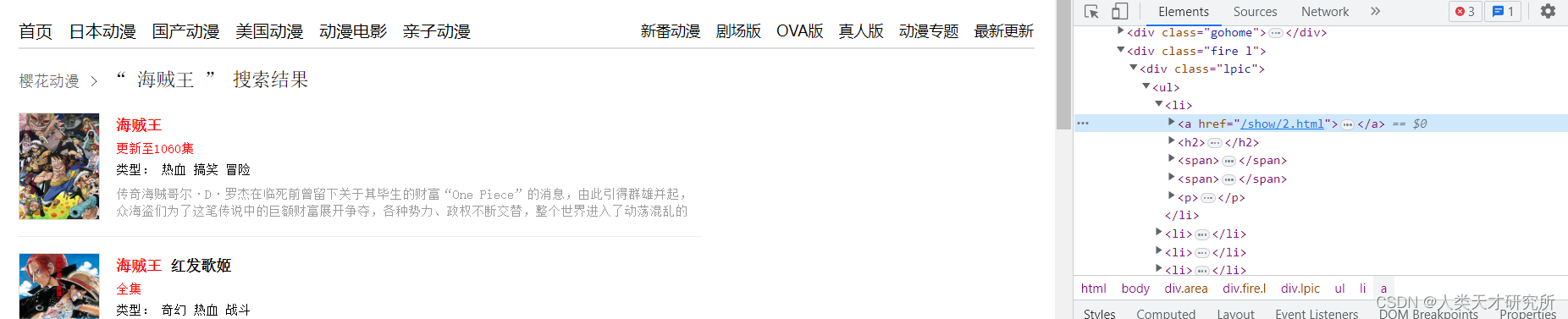
下面是部分代码
soup = BeautifulSoup(response.text,'lxml')#使用BeautifulSoup进行解析
res_list = soup.find('div',attrs={'class':'lpic'}).find_all('ul')[0].find_all('a')
res_map = {}#作为存放结果的字典
for res in res_list:
try:#防止出错,影响程序进行
title = res.find_all('img')[0]['alt']
url = res['href']
res_map[title.strip()] = url
except Exception as e:
pass
通过以上操作,得到想要访问的页面的地址
同样,分析该网页的结构,找到需要的数据
soup = BeautifulSoup(response.text,'lxml')
res_list = soup.find('div',attrs={'class':'movurl'}).find('ul')
res_json = {}
for res in res_list:
url_ = res.find_all('a')[0]['href']
title = res.find_all('a')[0].text
res_json[key_word+title] = url+url_
将最后的结果存入json文件
def writeJson(key_word,res_map):
with open(key_word+'.json','w',encoding='utf8') as f:
json.dump(res_map,f,ensure_ascii=False)
结果如图所示

全部代码如下
import requests
from bs4 import BeautifulSoup
import json
def get_url(url,key_word='海贼王'):
res_map = search(url,key_word=key_word)
res_url = url+res_map[key_word]
response = get_response(res_url)
soup = BeautifulSoup(response.text,'lxml')
res_list = soup.find('div',attrs={'class':'movurl'}).find('ul')
res_json = {}
for res in res_list:
url_ = res.find_all('a')[0]['href']
title = res.find_all('a')[0].text
res_json[key_word+title] = url+url_
return res_json
def get_response(url):
response = requests.get(url)
response.encoding = 'utf-8'
return response
def search(url_,key_word):
url = url_+'/search/'+key_word
response = get_response(url)
soup = BeautifulSoup(response.text,'lxml')
res_list = soup.find('div',attrs={'class':'lpic'}).find_all('ul')[0].find_all('a')
res_map = {}
for res in res_list:
try:
title = res.find_all('img')[0]['alt']
url = res['href']
res_map[title.strip()] = url
except Exception as e:
pass
return res_map
def writeJson(key_word,res_map):
with open(key_word+'.json','w',encoding='utf8') as f:
json.dump(res_map,f,ensure_ascii=False)
def main():
url='http://www.yinghuacd.com/'#网址可能会更换
keyword = '海贼王'
result=get_url(url,key_word=keyword)
writeJson(keyword,result)
if __name__ == '__main__':
main()
有问题的朋友可以直接和我私信交流

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









