







文章目录
- 前言
- 代码实现:
- 1、导入所需模块,并输出torch版本
- 2、导入MNIST的训练集和测试集
- 3、将数据集按批次加载到DataLoader,batch_size 设置为32
- 4、随机展现10张训练集中的图片,并同时显示标签和灰度图
- 5、构建一个线性模型“MNISTModelV0”类
- 6、基于“MNISTModelV0”,以SGD作为优化器,以批次为单位对网络进行训练,每个Epoch打印训练过程,训练结束后将模型在测试集上进行预测和评估
- 7、构建一个非线性模型“MNISTModelV1”类
- 8、基于“MNISTModelV1”对网络进行训练
- 9、构建一个CNN模型“MNISTModelV2”类
- 10、基于“MNISTModelV2”,选择一个合适的优化器
- 11、三个模型比较
- 12、可视化展示“MNISTModelV2”模型的预测效果的 ConfusionMatrix
- 13、保存“MNISTModelV2”,并重新载入模型,进行训练和预测
前言
MNIST数据库(Modified National Institute of Standards and Technology database)是一个大型数据库的手写数字是通常用于训练各种图像处理系统。该数据库还广泛用于机器学习领域的培训和测试。它是通过“重新混合” NIST原始数据集中的样本而创建的。创作者认为,由于NIST的培训数据集来自美国人口普查局员工,而测试数据集则来自美国 高中学生,这不是非常适合于机器学习实验。此外,将来自NIST的黑白图像归一化以适合28x28像素的边界框并进行抗锯齿处理,从而引入了灰度级。
包含60,000个训练图像和10,000个测试图像。训练集的一半和测试集的一半来自NIST的训练数据集,而训练集的另一半和测试集的另一半则来自NIST的测试数据集。数据库的原始创建者保留了一些经过测试的方法的列表。在他们的原始论文中,他们使用支持向量机获得0.8%的错误率。类似于MNIST的扩展数据集EMNIST已于2017年发布,其中包含240,000个训练图像和40,000个手写数字和字符的测试图像。
MNIST手写数字识别模型的主要任务是:输入一张手写数字的图像,然后识别图像中手写的是哪个数字。
该模型的目标明确、任务简单,数据集规范、统一,数据量大小适中,在普通的PC电脑上都能训练和识别,堪称是深度学习领域的“Hello World!”,学习AI的入门必备模型。
代码实现:
1、导入所需模块,并输出torch版本
import torch
from torch import nn
import torchmetrics
import torchvision
from torchvision import datasets
from torchvision.transforms import ToTensor
import matplotlib.pyplot as plt
from torch.utils.data import DataLoader
import mlxtend
import random
import pandas as pd
import numpy as np
from timeit import default_timer as timer
from tqdm.auto import tqdm
from torchmetrics import ConfusionMatrix
from mlxtend.plotting import plot_confusion_matrix
from pathlib import Path
print(f"PyTorch version: {torch.__version__}\ntorchvision version: {torchvision.__version__}")
2、导入MNIST的训练集和测试集
MNIST 数据集 包含上千个手写数字(0 to 9).
包含 10 个数字的灰度图片,用于进行多分类问题研究. 可以从 torchvision.datasets 直接导入该数据集torchvision.datasets.MNIST().
为了载入该数据集,需要为 [torchvision.datasets.MNIST()] 提供一些参数设置:
root: str- 数据下载的路径train: Bool- 获取训练集还是测试集download: Bool- 是否直接下载transform: torchvision.transforms- 对图像数据做那种转换,比如 “ToTensor()” 将图像转为 Tensor.target_transform- 转换标签设置.
train_data = datasets.MNIST(root="data", train=True, download=True, transform=ToTensor(), target_transform=None)
test_data = datasets.MNIST(root="data", train=False, download=True, transform=ToTensor())
# 查看图片形状
image.shape

tensor 的 shape 为 [1, 28, 28] ,代表:
[color_channels=1, height=28, width=28]
其中 color_channels=1 代表图片是一个灰度图.
# 查看各样本数
print('训练集数据:',len(train_data.data))
print('训练集标签:',len(train_data.targets))
print('测试集数据:',len(test_data.data))
print('测试集标签:',len(test_data.targets))
# 查看类别
class_names = train_data.classes
print('标签类别',class_names)

3、将数据集按批次加载到DataLoader,batch_size 设置为32
通常情况下由于数据量较大,我们会将数据集分成很多个 batchs(mini-batches) 或者叫 chunks,将数据集分成很多小块可以提高计算效率,梯度下降法可以在每个 batchs 上执行而不是在一个 epoch 上执行,每个 batchs 的大小设置是个 hyperparameter,其设置是个调参的问题,32、64、128、256 都是可选的值。
- 此处我们以 32 作为 batch size,并进行随机扰乱,打乱图像的顺序.
BATCH_SIZE = 32
# 将数据集转换成可批处理
train_dataloader = DataLoader(train_data, batch_size=BATCH_SIZE, shuffle=True) # 进行混洗
test_dataloader = DataLoader(test_data,batch_size=BATCH_SIZE,shuffle=False) # 不进行混洗
# 查看转换后的数据集批数
print(f"Dataloaders: {train_dataloader, test_dataloader}")
print(f"Length of train dataloader: {len(train_dataloader)} batches of {BATCH_SIZE}")
print(f"Length of test dataloader: {len(test_dataloader)} batches of {BATCH_SIZE}")

# 查看训练数据加载器中的内容
train_features_batch, train_labels_batch = next(iter(train_dataloader))
train_features_batch.shape, train_labels_batch.shape

4、随机展现10张训练集中的图片,并同时显示标签和灰度图
torch.manual_seed(42)
fig = plt.figure(figsize=(9, 4))
rows, cols = 2, 5
for i in range(1, rows * cols + 1):
random_idx = torch.randint(0, len(train_features_batch), size=[1]).item()
img, label = train_features_batch[random_idx], train_labels_batch[random_idx]
fig.add_subplot(rows,cols,i)
plt.imshow(img.squeeze(), cmap="gray")
plt.title(class_names[label])
plt.axis("Off");

5、构建一个线性模型“MNISTModelV0”类
将要构建的初始模型由 2 个 nn.Linear() 层构成.
与之前的模型构建方式不同,此处处理的是图像数据,因此需要引入一个新的层,用户将上述的图像 tensor 转换为一个向量:nn.Flatten() layer.
nn.Flatten() 层输入一个 shape 为 [color_channels, height, width] 的 tensor, 转换(平展)为 shape 为 [color_channels, height*width] 的 “特征向量”.
nn.Linear() 对这种很长的 “特征向量” 在计算上是非常友好的.
class MNISTModelV0(nn.Module):
def __init__(self, input_shape: int, hidden_units: int, output_shape: int):
super().__init__()
self.layer_stack = nn.Sequential(
nn.Flatten(),
nn.Linear(in_features=input_shape, out_features=hidden_units), # in_features =数据样本中的要素数量(784像素)
nn.Linear(in_features=hidden_units, out_features=output_shape)
)
def forward(self, x):
return self.layer_stack(x)
使用上述定义的模型类初始化一个模型对象,并设置下述参数:
input_shape=784- 这个值其实是将图像平展成为一个 “特征向量” 后,该向量的长度,也就是图像里面像素的个数.(28 * 28 像素 = 784 个像素特征).hidden_units=10- 每一层的神经元个数, 这个数值由程序员决定,但是为了保持网络不要太复杂,此处将该值设置为10.output_shape=len(class_names)- 由于这是一个多分类问题,对数据集中的每个分类,都需要对应有一个输出.
torch.manual_seed(42)
# 需要用输入参数设置模型
model_0 = MNISTModelV0(input_shape=784, hidden_units=10,output_shape=len(class_names))
model_0.to("cpu") # 将模型保存在CPU上

6、基于“MNISTModelV0”,以SGD作为优化器,以批次为单位对网络进行训练,每个Epoch打印训练过程,训练结束后将模型在测试集上进行预测和评估
# accuracy 准确性指标
torchmetrics.functional.accuracy
# 设置损失函数和优化器
cost = nn.CrossEntropyLoss() # 这在某些地方也被称为“准则”/“成本函数”
optimizer = torch.optim.SGD(params=model_0.parameters(), lr=0.1)
6.1 创建一个计算时间检测函数
上述模型将基于 CPU 和 GPU 运行,为了比较两种运行方式的性能差异,此处定义一个函数用于显示计算时间,该函数通过导入 timeit.default_timer() function 函数作为辅助.
from timeit import default_timer as timer
"""该函数用于打印起始时间差.
Args:
start (float): 开始计算时间 (preferred in timeit format).
end (float): 结束计算时间.
device ([type], optional): 计算设备.
Returns:
float: 计算时间差.
"""
def print_train_time(start: float, end: float, device: torch.device = None):
total_time = end - start
print(f"Train time on {device}: {total_time:.3f} seconds")
return total_time
6.2 基于 batches 数据训练模型
# 设置种子并启动计时器
torch.manual_seed(42)
train_time_start_on_cpu = timer()
# 设置epochs数(为了加快训练时间,我们将保持较小的epochs数)
epochs = 3
# 创建训练和测试循环
for epoch in tqdm(range(epochs)):
print(f"Epoch: {epoch}\n-------")
### Training
train_loss = 0
# 添加一个循环来循环训练批次
for batch, (X, y) in enumerate(train_dataloader):
model_0.train()
# 1. 前向传播
y_pred = model_0(X)
# 2. 计算损耗(每批)
loss = cost(y_pred, y)
train_loss += loss # 累计每个epochs的损失
# 3. 优化零梯度
optimizer.zero_grad()
# 4. 反向传播
loss.backward()
# 5. 优化步骤
optimizer.step()
# 打印出已经看过的样品数量
if batch % 400 == 0:
print(f"Looked at {batch * len(X)}/{len(train_dataloader.dataset)} samples")
# 每个epoch每批的平均损失
train_loss /= len(train_dataloader)
### Testing
# 设置累积损耗和精度的变量
test_loss, test_acc = 0, 0
model_0.eval()
with torch.inference_mode():
for X, y in test_dataloader:
# 1. 前向传播
test_pred = model_0(X)
# 2. 计算损失(累计)
test_loss += cost(test_pred, y) # 累计每个epochs的损失
# 3. 计算精度
test_acc += torchmetrics.functional.accuracy(y,test_pred.argmax(dim=1),task="multiclass",num_classes=10)
# 测试指标的计算需要在torch.inference_mode()中进行
# 将总测试损失除以测试数据加载器的长度(每批)
test_loss /= len(test_dataloader)
# 总准确度除以测试数据加载器的长度(每批)
test_acc /= len(test_dataloader)
print(f"\nTrain loss: {train_loss:.5f} | Test loss: {test_loss:.5f}, Test acc: {test_acc:.2f}%\n")
# 计算训练时间
train_time_end_on_cpu = timer()
total_train_time_model_0 = print_train_time(start=train_time_start_on_cpu, end=train_time_end_on_cpu,
device=str(next(model_0.parameters()).device))

6.3 基于 Model0 进行预测
"""
定义一个函数,接收一个 torch.nn.Modul对象、一个 torch.utils.data.DataLoader 对象、一个损失函数对象作为参数,返回一个数据字典,其中包含预测的结果.
参数:
model (torch.nn.Module): 一种可以在 torch.utils.data.DataLoader 对象上进行训练的模型.
data_loader (torch.utils.data.DataLoader): 目标数据集对象.
loss_fn (torch.nn.Module): 损失函数.
accuracy_fn: 模型测量函数.
返回值:
(dict): 预测结果.
"""
torch.manual_seed(42)
def eval_model(model: torch.nn.Module,
data_loader: torch.utils.data.DataLoader,
loss_fn: torch.nn.Module,
accuracy_fn):
loss, acc = 0, 0
model.eval()
with torch.inference_mode():
for X, y in data_loader:
# 使用模型进行预测
y_pred = model(X)
# 累计每批的损失和准确度值
loss += cost(y_pred, y)
acc += torchmetrics.functional.accuracy(y,y_pred.argmax(dim=1),task="multiclass",num_classes=10)
# 损耗和acc,找出每批的平均损耗/acc
loss /= len(data_loader)
acc /= len(data_loader)
return {"model_name": model.__class__.__name__,
"model_loss": loss.item(),
"model_acc": acc}
# 计算测试数据集上的模型0结果
model_0_results = eval_model(model=model_0, data_loader=test_dataloader,
loss_fn=cost, accuracy_fn=torchmetrics.functional.accuracy
)
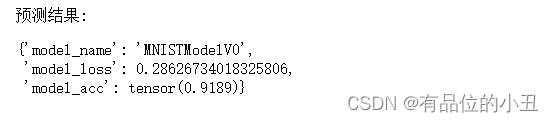
print('预测结果:')
model_0_results
设置对应的 device 标记.:
device = "cuda" if torch.cuda.is_available() else "cpu"
7、构建一个非线性模型“MNISTModelV1”类
为了得到非直线拟合的效果,我们再每个线性全连接层中加入一个 nn.ReLU() 层,构建一个非线性模型 MNISTModelV1
# 创建具有非线性和线性层的模型
class MNISTModelV1(nn.Module):
def __init__(self, input_shape: int, hidden_units: int, output_shape: int):
super().__init__()
self.layer_stack = nn.Sequential(
nn.Flatten(), # 将输入展平为单一向量
nn.Linear(in_features=input_shape, out_features=hidden_units),
nn.ReLU(),
nn.Linear(in_features=hidden_units, out_features=output_shape),
nn.ReLU()
)
def forward(self, x: torch.Tensor):
return self.layer_stack(x)
用上述名初始化实例的时候,我们仍然设置 input_shape=784 (784 等于图像的特征大小), hidden_units=10 (保持与 Model0 一致) , output_shape=len(class_names) (每一种分类对应一个输出).
注: 上述实例化设定基本上与 Model0 保持一致,是为了更好的比对不同模型的效果.
torch.manual_seed(42)
model_1 = MNISTModelV1(input_shape=784, # 输入特征的数量
hidden_units=10,
output_shape=len(class_names) # 所需的输出类别数
).to(device) # 将模型发送到GPU(如果可用)
next(model_1.parameters()).device # 检查模型设备

8、基于“MNISTModelV1”对网络进行训练
该模型优化器将采用RMSprop,加权考虑历史梯度和当前梯度,历史梯度系数是 α \alpha α ,当前梯度系数是 ( 1 − α ) (1-\alpha) (1−α)
E t = α ∗ E t − 1 + ( 1 − α ) ∗ g t 2 p t = p t − 1 − lr ∗ g t E t + e p s E_{t}=\alpha * E_{t-1}+(1-\alpha) * g_{t}^{2} p_{t}=p_{t-1}-\operatorname{lr} * \frac{g_{t}}{\sqrt{E_{t}+e p s}} Et=α∗Et−1+(1−α)∗gt2pt=pt−1−lr∗Et+epsgt
RMSprop(params, lr=0.01, alpha=0.99, eps=1e-08, weight_decay=0, momentum=0, centered=False)
accuracy_fn=torchmetrics.functional.accuracy
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.RMSprop(params=model_1.parameters(), lr=1e-3)
训练循环和测试循环在训练过程中会高频的调用,我们通过封装一个 train_step() 函数,接收一个 DataLoader 、一个损失函数和一个优化器作为参数。并基于同样的思路封装一个 test_step() 函数用于执行测试循环。
下述代码中.to(device) 的作用是将特征 (X) 和目标特征 (y) 适配到物理设备中.
def train_step(model: torch.nn.Module,
data_loader: torch.utils.data.DataLoader,
loss_fn: torch.nn.Module,
optimizer: torch.optim.Optimizer,
accuracy_fn,
device: torch.device = device):
train_loss, train_acc = 0, 0
for batch, (X, y) in enumerate(data_loader):
# 向GPU发送数据
X, y = X.to(device), y.to(device)
# 1. 前向传播
y_pred = model(X)
# 2. 计算损失
loss = loss_fn(y_pred, y)
train_loss += loss
train_acc += accuracy_fn(y,y_pred.argmax(dim=1),task="multiclass",num_classes=10) # Go from logits -> pred labels
# 3. 优化零梯度
optimizer.zero_grad()
# 4. 反向传播
loss.backward()
# 5. 优化步骤
optimizer.step()
# 计算每个时期的损失和准确性,并打印出发生了什么
train_loss /= len(data_loader)
train_acc /= len(data_loader)
print(f"Train loss: {train_loss:.5f} | Train accuracy: {train_acc:.2f}%")
def test_step(data_loader: torch.utils.data.DataLoader,
model: torch.nn.Module,
loss_fn: torch.nn.Module,
accuracy_fn,
device: torch.device = device):
test_loss, test_acc = 0, 0
model.eval() # 将模型置于评估模式
# 打开推理上下文管理器
with torch.inference_mode():
for X, y in data_loader:
# 向GPU发送数据
X, y = X.to(device), y.to(device)
# 1. 前向传播
test_pred = model(X)
# 2. 计算损失和精确度
test_loss += loss_fn(test_pred, y)
test_acc += accuracy_fn(y,test_pred.argmax(dim=1),task="multiclass",num_classes=10)
# 调整指标并打印出来
test_loss /= len(data_loader)
test_acc /= len(data_loader)
print(f"Test loss: {test_loss:.5f} | Test accuracy: {test_acc:.2f}%\n")
将上述封装好的每个训练步骤应用于每一个 epoch.
注: 下述代码在每个训练步骤后执行了一个测试步骤,实际上测试步骤的执行频率是可调节的,可以根据具体的情况而定.
下述代码在 GPU 上执行,通过执行计时器可以看到具体的执行时间。
torch.manual_seed(42)
# 测量时间
train_time_start_on_gpu = timer()
epochs = 3
for epoch in tqdm(range(epochs)):
print(f"Epoch: {epoch}\n---------")
train_step(data_loader=train_dataloader,
model=model_1,
loss_fn=loss_fn,
optimizer=optimizer,
accuracy_fn=accuracy_fn
)
test_step(data_loader=test_dataloader,
model=model_1,
loss_fn=loss_fn,
accuracy_fn=accuracy_fn
)
train_time_end_on_gpu = timer()
total_train_time_model_1 = print_train_time(start=train_time_start_on_gpu,
end=train_time_end_on_gpu,
device=device)

下述代码进行模型训练同时进行模型评估:
torch.manual_seed(42)
# 注意:由于“eval_model()”没有使用与设备无关的代码,这将导致错误
model_1_results = eval_model(model=model_1,
data_loader=test_dataloader,
loss_fn=loss_fn,
accuracy_fn=accuracy_fn)
print("预测结果:")
model_1_results
此时 eval_model() 返回类似下述错误:
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu! (when checking argument for argument mat1 in method wrapper_addmm)
解决这个问题需要将一个 device 参数传给 eval_model() 函数,使得经过一定的设置,可以让所有的计算都保持在同一的物理设备上。基于上述的概念,对函数做了一定的改造:
# 将值移动到设备
"""在给定的数据集上评估模型的能力.
参数:
model (torch.nn.Module): Torch 模型对象.
data_loader (torch.utils.data.DataLoader): 目标数据集.
loss_fn (torch.nn.Module): 损失函数.
accuracy_fn: 用于比较预测结果和实际标签的自定义评估函数.
device (str, optional): 木桥物理设备.
Returns:
(dict): 预测结果.
"""
torch.manual_seed(42)
def eval_model(model: torch.nn.Module,
data_loader: torch.utils.data.DataLoader,
loss_fn: torch.nn.Module,
accuracy_fn,
device: torch.device = device):
loss, acc = 0, 0
model.eval()
with torch.inference_mode():
for X, y in data_loader:
# 向目标设备发送数据
X, y = X.to(device), y.to(device)
y_pred = model(X)
loss += loss_fn(y_pred, y)
acc += accuracy_fn(y, y_pred.argmax(dim=1),task="multiclass",num_classes=10)
# 规模损失和精确度
loss /= len(data_loader)
acc /= len(data_loader)
return {"model_name": model.__class__.__name__, # 仅在使用类创建模型时有效
"model_loss": loss.item(),
"model_acc": acc}
# 使用与设备无关的代码计算模型1结果
model_1_results = eval_model(model=model_1, data_loader=test_dataloader,
loss_fn=loss_fn, accuracy_fn=accuracy_fn,
device=device
)
model_1_results
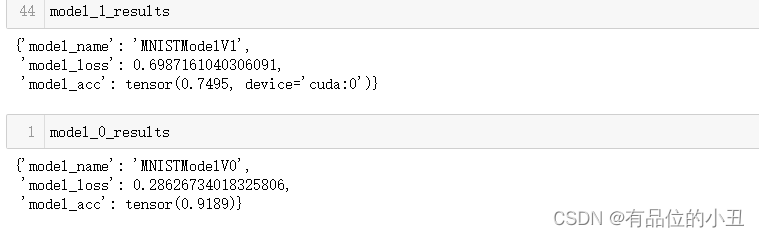
从上数结果可见,非线性模型比线性模型的效果更差一些。
核心的原因主要是因为产生的过拟合现象,模型对训练数据的拟合过好,导致泛化能力变弱。
9、构建一个CNN模型“MNISTModelV2”类
# 创建一个卷积神经网络
class MNISTModelV2(nn.Module):
def __init__(self, input_shape: int, hidden_units: int, output_shape: int):
super().__init__()
self.block_1 = nn.Sequential(
nn.Conv2d(in_channels=input_shape,
out_channels=hidden_units,
kernel_size=3,
stride=1,
padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=hidden_units,
out_channels=hidden_units,
kernel_size=3,
stride=1,
padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2,
stride=2) # 默认步幅值与内核大小相同
)
self.block_2 = nn.Sequential(
nn.Conv2d(hidden_units, hidden_units, 3, padding=1),
nn.ReLU(),
nn.Conv2d(hidden_units, hidden_units, 3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.classifier = nn.Sequential(
nn.Flatten(),
# in_features形状来源是因为我们网络的每一层都在压缩和改变我们输入数据的形状
nn.Linear(in_features=hidden_units*7*7,
out_features=output_shape)
)
def forward(self, x: torch.Tensor):
x = self.block_1(x)
x = self.block_2(x)
x = self.classifier(x)
return x
torch.manual_seed(42)
model_2 = MNISTModelV2(input_shape=1,
hidden_units=10,
output_shape=len(class_names)).to(device)
model_2

10、基于“MNISTModelV2”,选择一个合适的优化器
在比较SGD、RMSprop、Adagrad、Adam四类优化器使用的结果后,此处选用Adam作为模型MNISTModelV2的优化器
实现了自适应学习率有优化器, Adam 是 Momentum 和 RMSprop 的结合。主要超参数有
β
1
\beta_{1}
β1,
β
2
\beta_{2}
β2,eps。 公式如下:
m
t
=
β
1
∗
m
t
−
1
+
(
1
−
β
1
)
∗
g
t
v
t
=
β
2
∗
v
t
−
1
+
(
1
−
β
2
)
∗
g
t
2
m
^
t
=
m
t
1
−
β
t
1
v
^
t
=
v
t
1
−
β
t
2
p
t
=
p
t
−
lr
∗
m
^
t
v
^
t
+
ϵ
m_{t}=\beta_{1} * m_{t-1}+\left(1-\beta_{1}\right) * g_{t} v_{t}=\beta_{2} * v_{t-1}+\left(1-\beta_{2}\right) * g_{t}^{2} \hat{m} t=\frac{m_{t}}{1-\beta^{t} 1} \hat{v} t \\ =\frac{v_{t}}{1-\beta^{t} 2} p_{t}=p_{t}-\operatorname{lr} * \frac{\hat{m} t}{\sqrt{\hat{v} t+\epsilon}}
mt=β1∗mt−1+(1−β1)∗gtvt=β2∗vt−1+(1−β2)∗gt2m^t=1−βt1mtv^t=1−βt2vtpt=pt−lr∗v^t+ϵm^t
- 其中,mt、vt分别是对梯度的一阶矩估计和二阶矩估计,可以看作对期望 E [ g t ] E[gt] E[gt]、 E [ g t 2 ] E[g_t^2] E[gt2] 的近似; m ^ t \hat{m}t m^t , v ^ t \hat{v}t v^t 是校正,这样可以近似为对期望的无偏估计
# 设置损失和优化器
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(params=model_2.parameters(),lr=1e-3)
torch.manual_seed(42)
# 测量时间
train_time_start_model_2 = timer()
# 训练和测试模型
epochs = 3
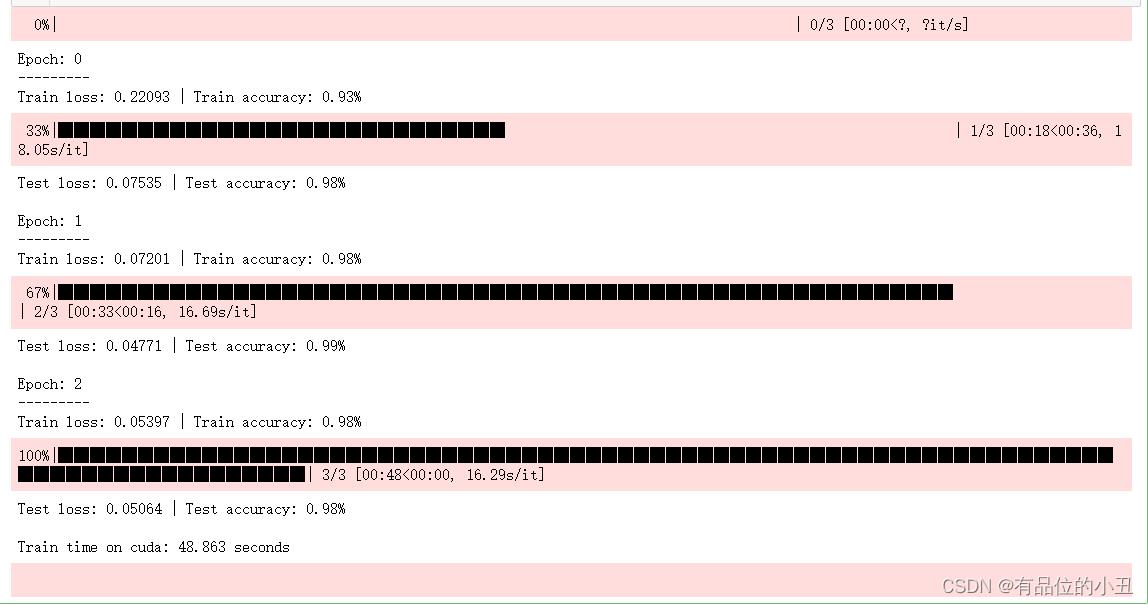
for epoch in tqdm(range(epochs)):
print(f"Epoch: {epoch}\n---------")
train_step(data_loader=train_dataloader,
model=model_2,
loss_fn=loss_fn,
optimizer=optimizer,
accuracy_fn=accuracy_fn,
device=device
)
test_step(data_loader=test_dataloader,
model=model_2,
loss_fn=loss_fn,
accuracy_fn=accuracy_fn,
device=device
)
train_time_end_model_2 = timer()
total_train_time_model_2 = print_train_time(start=train_time_start_model_2,
end=train_time_end_model_2,
device=device)
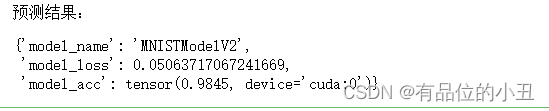
下述代码对模型进行评估:
model_2_results = eval_model(
model=model_2,
data_loader=test_dataloader,
loss_fn=loss_fn,
accuracy_fn=accuracy_fn
)
print('预测结果:')
model_2_results
11、三个模型比较
目前为止,一共创建了三个模型.
model_0- 拥有两个线性nn.Linear()layers 的线性模型.model_1- 在两个nn.Linear()层之间加入一个nn.ReLU()层之后的非线性模型.model_2- 卷积神经网络模型,基于 TinyVGG 架构.
compare_results = pd.DataFrame([model_0_results, model_1_results, model_2_results])
compare_results

# 将训练时间添加到结果比较中,并将model_acc转换为float类型数值
compare_results["training_time"] = [total_train_time_model_0,
total_train_time_model_1,
total_train_time_model_2]
compare_results[u'model_acc'] = compare_results[u'model_acc'].apply(lambda x: float(x)*100)
compare_results
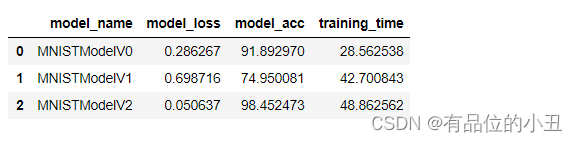
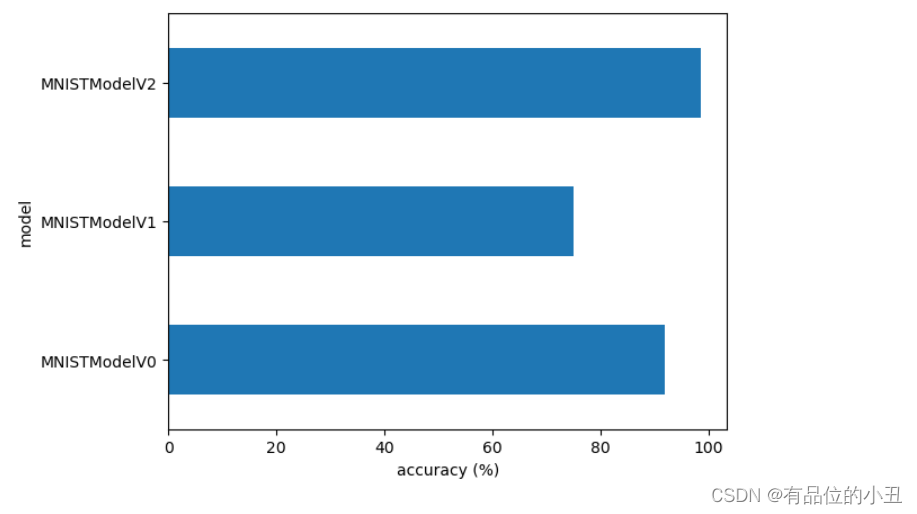
从上述结果可见 CNN (MNISTModelV2) 模型表现最好(更小的 loss, 更高的 accuracy),但是训练时间却更长(准确度和训练时间存在一定的矛盾).
线性模型(MNISTModelV0) 比非线性模型 model_1 (MNISTModelV1) 表现更好些,但是训练时间也短一些 (MNISTModelV1 基于GPU,但由于数据量少,启用gpu初始化等操作反而时间更长).
# 结果可视化
compare_results.set_index("model_name")["model_acc"].plot(kind="barh")
plt.xlabel("accuracy (%)")
plt.ylabel("model");
12、可视化展示“MNISTModelV2”模型的预测效果的 ConfusionMatrix
混淆矩阵是众多用于测量分类模型的评估方法中可视化效果比较好的一种,它能否展现模型的预测结果与实际结果的混淆程度.
构建混淆矩阵的步骤:
- 基于模型进行预测 (混淆矩阵的主要作用是将预测值与实际值进行比较).
- 用
torch.ConfusionMatrix构建混淆矩阵. - 用
mlxtend.plotting.plot_confusion_matrix()函数绘制混淆矩阵.
# 1. 使用训练好的模型进行预测
y_preds = []
model_2.eval()
with torch.inference_mode():
for X, y in tqdm(test_dataloader, desc="Making predictions"):
# 向目标设备发送数据和目标
X, y = X.to(device), y.to(device)
# 前向传播
y_logit = model_2(X)
# 从逻辑->预测概率->预测标签转换预测
y_pred = torch.softmax(y_logit.squeeze(), dim=0).argmax(dim=1)
# 将预测放在CPU上进行评估
y_preds.append(y_pred.cpu())
# 将预测列表连接成一个张量
y_pred_tensor = torch.cat(y_preds)
接下来执行上述描述中的两个步骤:
- 用
torch.ConfusionMatrix构建混淆矩阵. - 用
mlxtend.plotting.plot_confusion_matrix()函数绘制混淆矩阵.
首先,我们需要确保我们已经安装了“torchmetrics”和“mlxtend ”(这两个库将帮助我们制作和可视化一个混淆矩阵)。
注: 需要确保
torchmetrics和mlxtend这两个库已经安装了.mlxtend的版本应高于 0.19.0.
首先,需要创建一个 torchmetrics.ConfusionMatrix 实例并传参 num_classes,表示一共有多少个目标类别: num_classes=len(class_names).
其次,创建在 torchmetrics.ConfusionMatrix 实例上进行预测结果(preds=y_pred_tensor) 和实际目标(target=test_data.targets) 之间的比较.
最后,使用 mlxtend.plotting 模块里的 plot_confusion_matrix() 函数绘制混淆矩阵 .
# 2. 设置混淆矩阵实例并将预测与目标进行比较
confmat = ConfusionMatrix(num_classes=len(class_names),task="multiclass")
confmat_tensor = confmat(preds=y_pred_tensor,
target=test_data.targets)
# 3. 绘制混淆矩阵
fig, ax = plot_confusion_matrix(
conf_mat=confmat_tensor.numpy(),
class_names=class_names, # 将行和列标签转换成类名
figsize=(10, 7)
);

混淆矩阵的横坐标是预测值,纵坐标是实际值,横纵坐标交汇处的值代表,预测的值是横坐标的标签,而实际值是纵坐标的标签这种情况发生的次数.
混淆矩阵能够从全局的角度进行预测情况展示和比较,比单纯计算某种测量数值要直观很多.
如果混淆矩阵之后对角线上的数字,说明模型的预测是完美的,从上图可见 MNISTModelV2 模型的预测效果还是不错的.
13、保存“MNISTModelV2”,并重新载入模型,进行训练和预测
torch.save- 保存一个 PyTorch 完整模型或者模型的state_dict()为一个 PyTorch Object.torch.load- 载入一个预先保存的 PyTorch Objecttorch.nn.Module.load_state_dict()- 把一个预先保存的state_dict()对象导入一个模型实例.
# 创建模型目录(如果尚不存在),请参阅:https://docs.python.org/3/library/pathlib.html#pathlib.Path.mkdir
MODEL_PATH = Path("models")
MODEL_PATH.mkdir(parents=True, # 如果需要,创建父目录
exist_ok=True # 如果模型目录已经存在,不要出错
)
# 创建模型保存路径
MODEL_NAME = "MNISTModelV2_model_2.pth"
MODEL_SAVE_PATH = MODEL_PATH / MODEL_NAME
#保存模型状态字典
print(f"Saving model to: {MODEL_SAVE_PATH}")
torch.save(obj=model_2.state_dict(), # 仅保存state_dict()仅保存学习到的参数
f=MODEL_SAVE_PATH)

现在已经成功的将一个 state_dict() 对象保存到文件中,之后可以使用 torch.load() 先从磁盘上把文件读入为一个对象,然后用 load_state_dict() 将这个对象加载到模型中.
#创建MNISTModelV2的新实例(与我们保存的state_dict()是同一个类)
#注意:如果此处的形状与保存的版本不同,加载模型将会出错
loaded_model_2 = MNISTModelV2(input_shape=1, hidden_units=10, output_shape=10)
# 载入保存的state_dict()
loaded_model_2.load_state_dict(torch.load(f=MODEL_SAVE_PATH))
# 将模型发送到GPU
loaded_model_2 = loaded_model_2.to(device)
接下来即可正常的使用这个从磁盘载入的模型.
# 评估加载的模型
torch.manual_seed(42)
loaded_model_2_results = eval_model(
model=loaded_model_2,
data_loader=test_dataloader,
loss_fn=loss_fn,
accuracy_fn=accuracy_fn
)
loaded_model_2_results

这个载入的模型预测的效果和之前一直在内存运行的模型的预测结果 model_2_results 是一样的:
model_2_results

也可以直接使用 torch.isclose() 对两个 tensor 进行比较,通过 atol (absolute tolerance) 以及 rtol (relative tolerance) 参数传入相似度阈值.
如果两个 tensor 非常接近则 torch.isclose() 函数将返回一个真值
# 检查结果是否彼此接近(如果它们非常远,可能会有错误)
torch.isclose(torch.tensor(model_2_results["model_loss"]),
torch.tensor(loaded_model_2_results["model_loss"]),
atol=1e-08, # 绝对误差
rtol=0.0001) # 相对误差


















 1332
1332











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











