









本篇文章是博主强化学习RL领域学习时,用于个人学习、研究或者欣赏使用,并基于博主对相关等领域的一些理解而记录的学习摘录和笔记,若有不当和侵权之处,指出后将会立即改正,还望谅解。文章分类在强化学习专栏:
【强化学习】(14)---《面向角色的多智能体强化学习(ROMA)算法》
面向角色的多智能体强化学习(ROMA)算法
目录
[Python] ROMA伪代码
1. 背景介绍
多智能体强化学习(Multi-Agent Reinforcement Learning, MARL)在许多应用场景中面临巨大挑战,如智能体之间的协作、竞争以及在复杂环境中的策略优化。在多智能体系统中,如何让各个智能体有效协作、合理分工,最大化整体性能是一个核心问题。面向角色的多智能体强化学习(Role-Oriented Multi-Agent Reinforcement Learning, ROMA) 算法正是为了解决这一问题而设计的。
在 ROMA 中,“角色”(Role) 是多智能体协作中的核心概念。智能体被分配不同的角色,每个角色决定智能体在任务中的具体职责和行为模式。通过这种角色导向的方式,ROMA 试图提高多智能体系统中的协作效率,同时使得策略学习更加稳定和高效。
论文:ROMA: Multi-Agent Reinforcement Learning with Emergent Roles
其他多智能体深度强化学习(MADRL)算法见下面博客:
2. ROMA 算法的核心思想
ROMA 的核心思想是为每个智能体分配特定的“角色”,使其根据角色选择行动,并在学习过程中优化角色和策略的选择。通过将智能体的行为分解为角色的表现,ROMA 能够有效减少策略学习的复杂性,特别是在复杂的多智能体协作任务中。
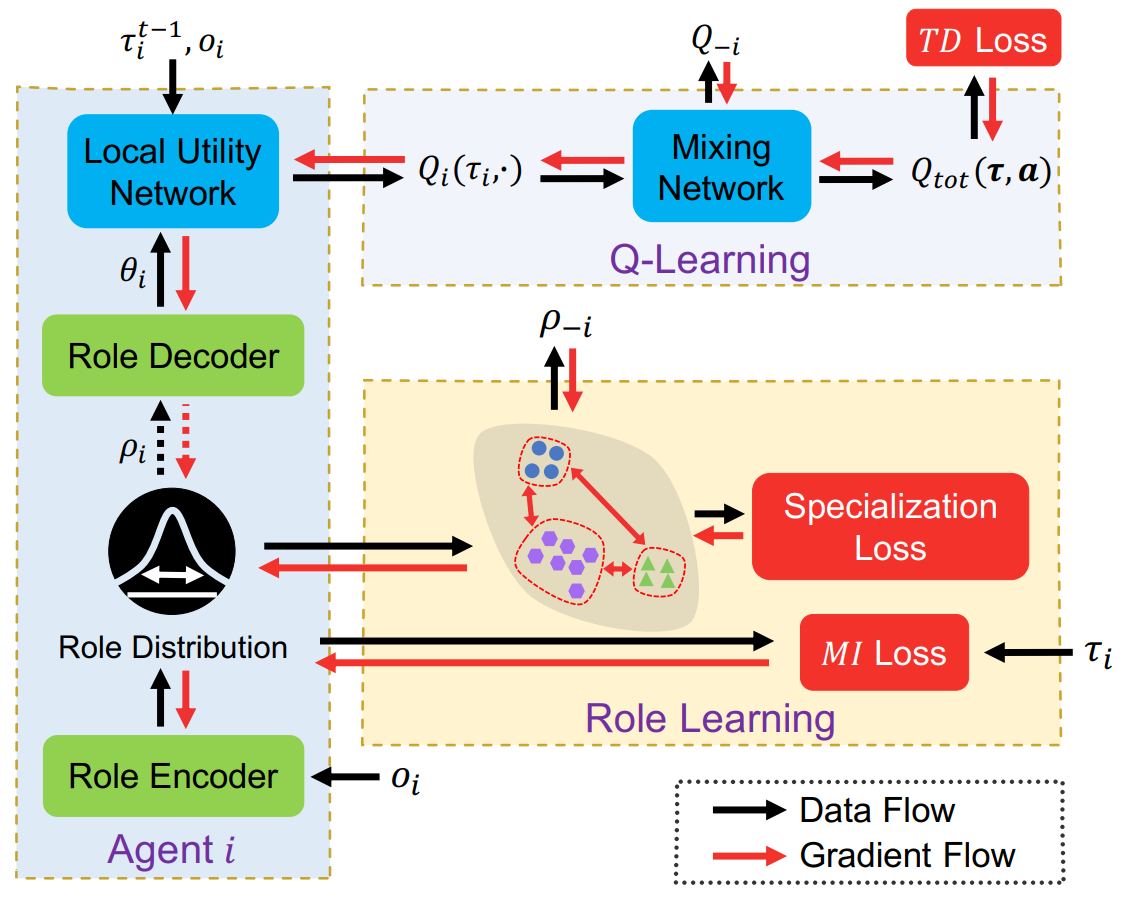
ROMA 的主要思路可以总结为以下几个要点:
-
角色定义与分配:每个智能体根据环境中的信息动态选择自己的角色。不同的角色代表智能体的不同行为模式或职责,例如在足球比赛中,进攻和防守就是不同的角色。
-
角色引导的策略学习:在确定角色之后,智能体会根据其角色选择最优的策略。角色的引入使得策略空间的划分更加合理,减少了学习的复杂性。
-
角色优化与调整:智能体并不是一开始就固定角色的,而是通过训练过程中不断优化自己的角色选择,使得整体系统的表现最大化。
-
协作与通信:ROMA 允许智能体在特定的情况下通过角色来引导协作,并在必要时通过通信共享信息,增强团队的协同能力。
3. ROMA 算法的实现流程
3.1 初始化
- 为每个智能体初始化策略网络
,其中
是该智能体的角色。
- 定义角色的类别数量
,并为每个智能体分配初始的角色,角色可以是动态分配的或者从有限集合中选择。
- 初始化角色选择网络,用于根据环境状态
和其他信息选择最优的角色。
3.2 数据收集
- 在多智能体环境中,智能体根据其当前角色和策略进行交互,记录每个智能体的状态
、角色
。
- 轨迹
被存储用于后续的策略优化。
3.3 角色选择与更新
- 在每次交互中,智能体通过角色选择网络
根据当前的环境状态
。角色选择网络基于当前的状态信息和历史信息,动态调整智能体的角色分配。
3.4 策略更新
- 根据所选角色
- 收集交互数据后,使用基于策略梯度的优化方法更新策略参数
,使得每个角色下的策略得到改进。
- 同时更新角色选择网络
3.5 角色优化
- 在优化过程中,智能体的角色分配并不是固定的,而是动态变化的。通过优化角色选择网络,智能体可以在不同的环境状态下切换不同的角色,最大化系统的整体回报。
4. 关键公式
4.1 角色选择网络
角色选择的概率由角色选择网络控制,给定当前的环境状态
,选择角色
的概率为:
其中,是角色选择网络的参数,通过策略梯度法进行优化。
4.2 策略更新
每个智能体的策略依赖于其所选择的角色,给定角色 和状态
,策略网络选择动作
的概率为:
策略更新的目标是最大化期望的累积回报:
这里通过策略梯度算法(如 A2C 或 PPO)更新每个智能体的策略网络参数。
4.3 角色更新
角色选择网络的更新目标是使得每个智能体在不同的状态下选择最优的角色
,其更新过程通过最大化期望回报来进行:
同样,这个优化过程也可以通过梯度上升法进行。
5. ROMA 的优点与挑战
5.1 优点
- 角色分工明确:通过引入角色概念,ROMA 将智能体的行为空间合理分解,使得每个智能体的策略优化更加高效。
- 协作效率高:角色导向的智能体能够更好地协作,因为每个角色在特定任务中有明确的职责。
- 动态适应性强:智能体可以根据环境的变化动态调整自己的角色,提升系统的灵活性和适应性。
5.2 挑战
- 角色设计复杂:如何合理定义和分配角色是一个重要问题,角色的设计直接影响智能体的协作效率。
- 角色的动态性:虽然动态角色切换可以提高灵活性,但频繁的角色切换可能导致学习过程不稳定,需要精心设计角色选择网络的优化过程。
6. ROMA 的应用场景
ROMA 算法适用于以下场景:
- 多智能体协作任务:如机器人集群的任务分配、无人机协同作业等。
- 复杂博弈环境:如多人战略游戏或竞争性任务中的角色分配和策略优化。
- 复杂模拟环境:如交通控制系统中的多车道控制、多智能体在智能电网中的负载管理等。
7. 总结
ROMA 通过引入角色的概念,将多智能体强化学习中的复杂性问题分解为角色的分配和策略学习两部分,提升了多智能体系统中的协作效率和适应性。通过动态的角色选择与策略优化,ROMA 在多个多智能体强化学习任务中表现出良好的性能,是一种具有前景的算法。
[Python] ROMA伪代码
面向角色的多智能体强化学习(ROMA)算法的详细伪代码,涵盖了角色选择、策略更新、正则化过程等。
# ROMA 伪代码
# 初始化策略网络 π_θi 和角色选择网络 R_φ
initialize policy networks π_θi for each agent i
initialize role selection network R_φ
initialize value function networks V_ϕi for each agent i
initialize role embedding z_i for each agent i
# 定义正则化权重超参数 λ_disc 和 λ_share
λ_disc = role_discrimination_weight # 辨识度正则化权重
λ_share = role_sharing_weight # 角色共享正则化权重
# 定义最大训练迭代次数 max_iterations
for iteration in range(max_iterations):
# 1. 数据收集阶段
for each agent i do:
trajectory_τi = [] # 每个智能体的轨迹
for episode in range(num_episodes):
s = environment.reset() # 初始化环境状态
done = False
while not done:
# a) 角色选择:每个智能体基于当前状态 s 选择角色 z_i
z_i = sample_role(R_φ(s)) # 从角色选择网络中采样角色
# b) 动作选择:根据选择的角色 z_i 和状态 s 选择动作 a_i
a_i = sample_action(π_θi(s, z_i)) # 从策略网络中采样动作
# c) 环境交互:执行动作 a_i,观察环境的反馈
s_next, r_i, done, info = environment.step(a_i)
# d) 记录轨迹:将当前回合的 (s, a_i, z_i, r_i, s_next) 存储到轨迹中
trajectory_τi.append((s, a_i, z_i, r_i, s_next))
# e) 更新状态
s = s_next
# 将该智能体的轨迹 τ_i 保存用于后续优化
store_trajectory(trajectory_τi)
# 2. 策略更新阶段(Policy Update)
for each agent i do:
# a) 计算价值函数:基于存储的轨迹 τ_i 计算回报 G_t 和优势函数 A_t
G_t = compute_returns(trajectory_τi) # 计算每个状态的回报 G_t
A_t = compute_advantage(G_t, V_ϕi(s)) # 计算优势函数 A_t
# b) 策略网络更新:基于优势函数 A_t 和策略梯度法(如 PPO)更新策略网络 π_θi
update_policy(π_θi, A_t, trajectory_τi)
# c) 价值网络更新:通过最小化均方误差(MSE)来更新每个智能体的价值网络 V_ϕi
update_value_network(V_ϕi, G_t, trajectory_τi)
# 3. 角色选择网络更新(Role Selection Network Update)
for each agent i do:
# a) 基于策略梯度法(如 PPO)更新角色选择网络 R_φ,使其能够优化角色选择
update_role_network(R_φ, A_t, trajectory_τi)
# 4. 角色正则化(Role Regularization)
# a) 角色辨识度正则化:鼓励不同的角色 z_i 之间有较大差异,增强角色的可辨识度
for each agent i, j (i ≠ j) do:
D_KL = compute_kl_divergence(R_φ(s_i), R_φ(s_j)) # 计算 KL 散度,衡量角色分布差异
role_discrimination_loss = λ_disc * D_KL
apply_gradient_descent(R_φ, role_discrimination_loss) # 应用梯度下降更新角色选择网络
# b) 角色共享正则化:鼓励拥有相似角色的智能体共享策略网络,减少策略差异
for each agent i, j (if z_i ≈ z_j) do:
policy_difference = compute_policy_difference(π_θi, π_θj) # 计算策略网络的差异
role_sharing_loss = λ_share * policy_difference
apply_gradient_descent(π_θi, role_sharing_loss) # 应用梯度下降更新策略网络
# 5. 重复训练过程
# 重复以上步骤,直到达到预设的训练迭代次数或满足其他终止条件
MADRL面向角色的多智能体强化学习(ROMA)算法项目代码:
[Notice] 注意事项
伪代码详细说明
1. 初始化
- 策略网络
:每个智能体有独立的策略网络,用于根据状态和角色选择动作。
- 角色选择网络
:根据环境状态
- 角色嵌入
:代表每个智能体当前的角色,可以是从角色选择网络中动态选择的角色向量。
- 正则化超参数:用于控制正则化损失的强度,角色辨识度正则化和角色共享正则化分别通过超参数
和
控制。
2. 数据收集
- 角色选择:每个智能体基于当前状态通过角色选择网络
- 动作选择:每个智能体根据所选角色
中选择最优动作
- 轨迹存储:在每一轮交互后,存储所有智能体的轨迹数据,包括状态、动作、角色和奖励等。
3. 策略更新
- 优势函数计算:利用存储的轨迹数据计算每个状态的优势函数
,用于指导策略更新。
- 策略优化:使用基于策略梯度的优化方法(如 PPO)更新每个智能体的策略网络,使其在不同角色下的策略更优。
4. 角色正则化
- 角色辨识度正则化:鼓励不同角色的智能体角色具有可区分性,使用 KL 散度作为损失函数来计算角色选择网络中角色分布之间的差异,增加智能体角色的独特性。
- 角色共享正则化:鼓励具有相似角色的智能体共享策略,通过最小化策略差异来促进策略共享,从而加速学习过程。
5. 角色共享与辨识度
- 角色辨识度损失:通过 KL 散度计算两个智能体的角色选择分布差异:
- 角色共享损失:通过最小化两个策略网络在相同角色下的差异来鼓励策略共享:
文章若有不当和不正确之处,还望理解与指出。由于部分文字、图片等来源于互联网,无法核实真实出处,如涉及相关争议,请联系博主删除。如有错误、疑问和侵权,欢迎评论留言联系作者,或者关注VX公众号:Rain21321,联系作者。


















 1167
1167

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











