







目录
Generative Adversarial Network(生成对抗网络)
Generative Adversarial Network(生成对抗网络)
Basic Idea of GAN
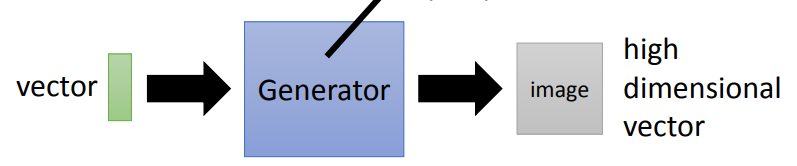
- Generation(生成器)
Generation是一个neural network,它的输入是一个vector,它的输出是一个更高维的vector,以图片生成为例,输出就是一张图片,其中每个维度的值代表生成图片的某种特征。
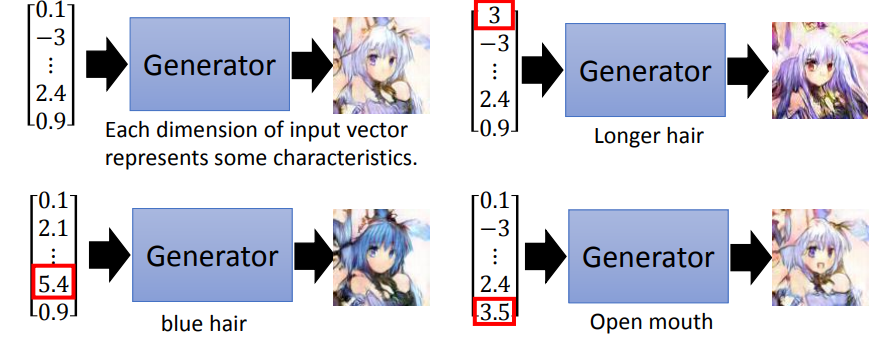
- Discriminator(判别器)
Discriminator也是一个neural network,它的输入是一张图片,输出是一个scalar,scalar的数值越大说明这张图片越像真实的图片。

- Generation和Discriminator两者的关系
举了鸟和蝴蝶例子说明Generation和Discriminator之间的关系是相互对抗,相互提高。然后提出两个问题:
- Generator为什么不自己学,还需要Discriminator来指导。
- Discriminator为什么不自己直接做。
- Algorithm(算法说明)
首先要随机初始化generator 、discriminator的参数;
然后在每一个training iteration要做两件事:
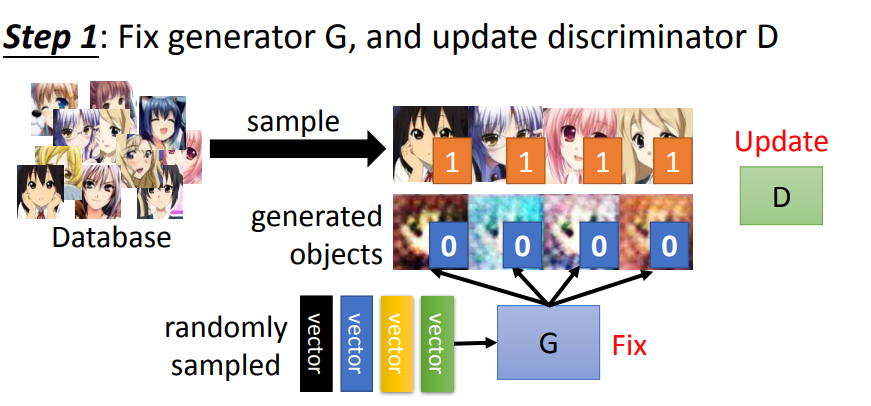
1. 固定generator的参数,然后只训练discriminator。
将generator生成的图片与从database sample出来的图片放入discriminator中训练,如果是generator生成的图片就给低分,从database sample出来的图片就给高分。
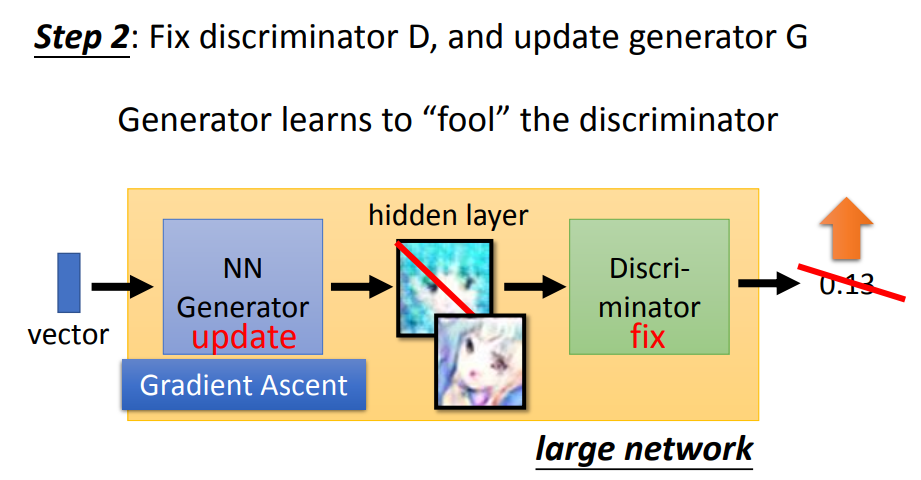
2. 固定discriminator的参数,然后只训练generator。
把generator生成的图片当做discriminator的输入,训练目标是让输出越大越好。
具体算法如下:
训练D(固定G):
- 首先从database中抽取m个样本。
- 从一个分布中抽取m个vector z。
- 将z输入generator,生成m张图片
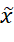 。
。 - 计算损失,最大化损失。
训练G(固定D):
- 随机产生m个噪声,通过generator得到图片G(z);
- 然后经过discriminator得到D(G(z)),更改G中的参数,使得它的得分越高越好。

GAN as structured learning
结构化学习的输入和输出多种多样,可以是序列(sequence)到序列,序列到矩阵(matrix),矩阵到图(graph),图到树(tree)等。例如,机器翻译、语音识别、聊天机器人、文本转图像等。GAN也是结构化学习的一种。
- Structured Learning面临的挑战
- One-shot/Zero-shot Learning:比如在分类任务中,有些类别没有数据或者有很少的数据。
- 机器需要创造新的东西。如果把每个可能的输出都视为一个“class”,由于输出空间很大,大多数“class”都没有训练数据,也,这就导致了机器必须在testing时创造新的东西。
- 机器需要有规划的概念,要有大局观。因为输出组件具有依赖性,所以应全局考虑它们。
- Structured Learning Approach
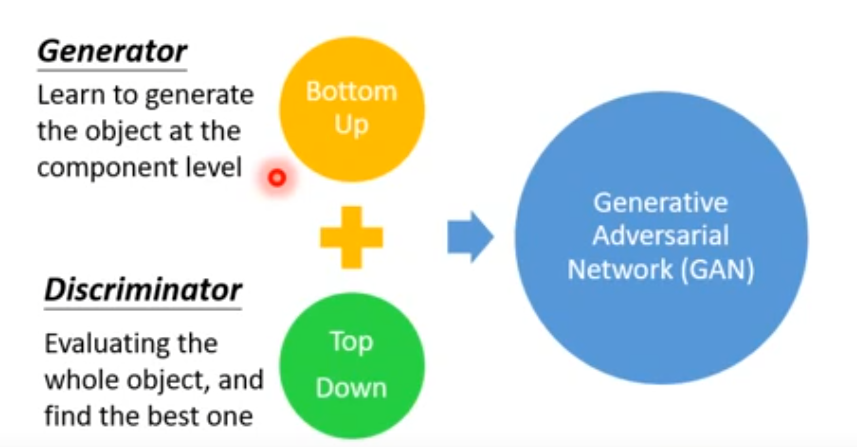
传统的structured learning主要有两种做法:Bottom up 和 Top down。
Bottom up:机器逐个产生object的component。
Top down:从整体来评价产生的component的好坏。
Generator可以视为是一个Bottom Up的方法,discriminator可以视为是一个Top Down的方法,把这两个方法结合起来就是GAN。
Can Generator learn by itself
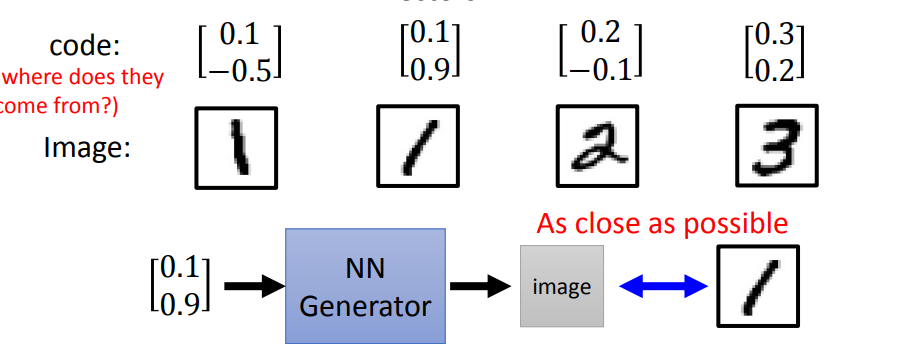
可以用监督学习的方法来对generator进行训练,但是还会存在一个问题:表示图片的code从哪里来。如果随机产生,训练起来可能非常困难。因为如果两种图片很像,它们输入vector差异很大的话,就很难去训练。
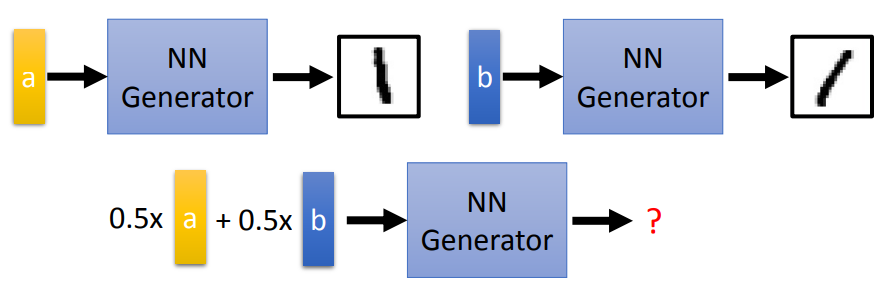
可以通过训练一个encoder,得到相应的code。但是存在的问题就是:Vector a 输出结果是向左的1,vector b 输出结果是向右的1。若把a、b平均作为输入,则输出不一定是数字,可以使用VAE来解决这个问题。
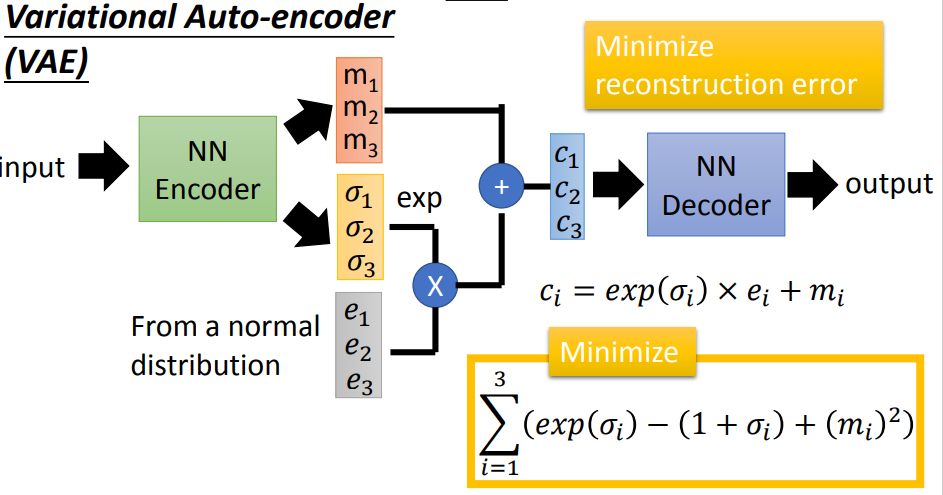
- VAE (Variational Auto-Encoder,变分编码器)
VAE不仅产生一个code还会产生每一个维度的方差;然后将方差和正态分布中抽取的噪声进行相乘,之后加上code上去,就相当于加上noise的code。
- VAE的缺陷
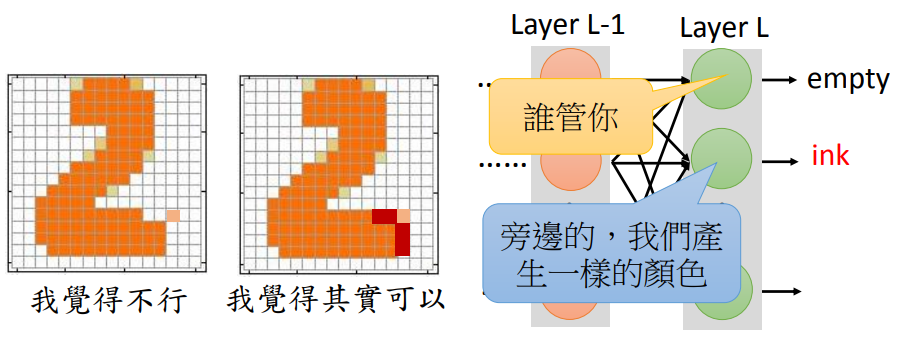
在生成图片时,不是单纯的让生成结果与真实结果越接近越好,还要保证整幅图片符合现实规律。

假设Layer L-1的值是给定的,则Layer L每一个dimension的输出都是独立的,无法相互影响。因此只有在L后面在加几个隐藏层,才可以调整第L层的神经元输出。也就是说,VAE要想获得GAN的效果,它的网络要比GAN要深才行。
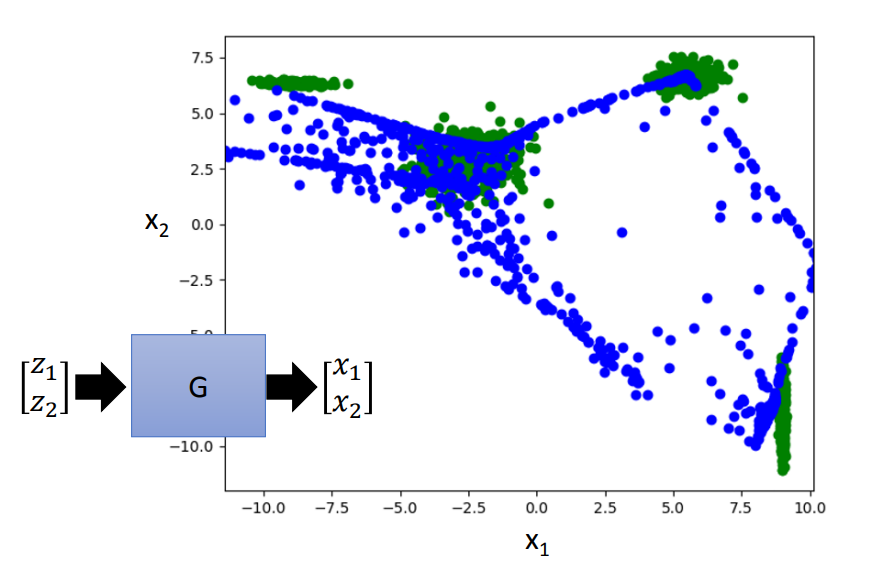
下图中绿色是目标,蓝色是VAE学习的结果。VAE在做一些离散的目标效果不好。
Can Discriminator generate
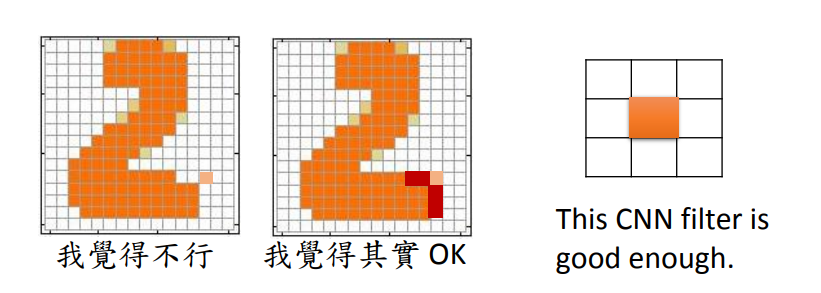
Discriminator就是给定一个输入,输出一个分数。对discriminator来说,要考虑component和component之间的联系就比较容易。比如有一个滤波器,它会去检索有没有独立的像素点,有的话就是低分。
假如有一个discriminator,它能够鉴别图片的好坏,就可以用这个discriminator去生成图片。穷举所有的输入x,比较discriminator给出的分数,找到分数最高的就是discriminator的生成结果。
- 训练discriminator
- 首先给定一些正样本,随机产生一些负样本。
- 在每一个iteration里面,训练出discriminator能够鉴别正负样本。
- 然后用训练出来的discriminator生成图片当做负样本。
- 开始迭代。

从可视化和概率的角度来看一下整个过程。蓝色的是discriminator生成图片的分布,绿色的是真实图片分布。训练discriminator给绿色的高分,蓝色的低分。然后寻找discriminator除了真实图片之外,得分最大高的地方把它变成负样反复迭代,最终正样本和负样本就会重合在一起。
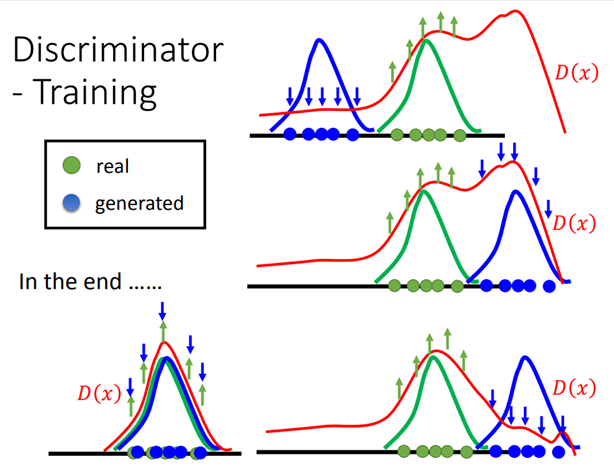
- Generator v.s. Discriminator
generator:很容易生成图片,但是它不考虑component之间的联系。只学到了目标的表象,没有学到精神。
Discriminator:能够考虑大局,但是很难生成图片。
- Generator + Discriminator
Generator就是取代了这个argmax的过程。GAN的优点如下:
从discriminator来看,利用generator去生成样本,去求解argmax问题,更加有效。
从generator来看,虽然在生成图片过程中的像素之间依然没有联系,但是它的图片好坏是由有大局观的discriminator来判断的。从而能够学到有大局观的generator。
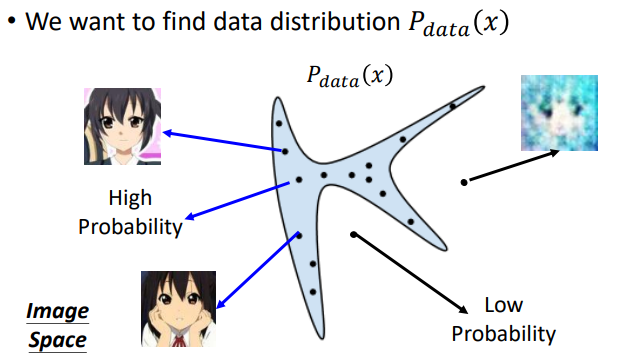
Theory behind GAN
假如要生成一些人脸图,实际上就是想要找到一个分布,从这个分布内sample出来的图片像是人脸,分布之外生成的就不像人脸。而GAN要做的就是找到这个distribution。
在GAN之前用的是Maximum Likelihood Estimation。
- Maximum Likelihood Estimation(最大似然估计)
最大似然估计的思想是,假设数据的分布是 ![]() ,定义一个分布为
,定义一个分布为![]() ,求得一组参数θ,使得
,求得一组参数θ,使得![]() 与
与![]() 越接近越好。具体步骤如下:
越接近越好。具体步骤如下:
- 从
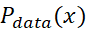 中sample出一些样本;
中sample出一些样本; - 对于sample出来的样本,可以计算出它们的likelihood;
- 计算总分likelihood L,并找到一组参数
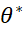 使得L最大。
使得L最大。

- MLE=Minimize KL Divergence
最大似然估计就相当于最小化的KL散度。
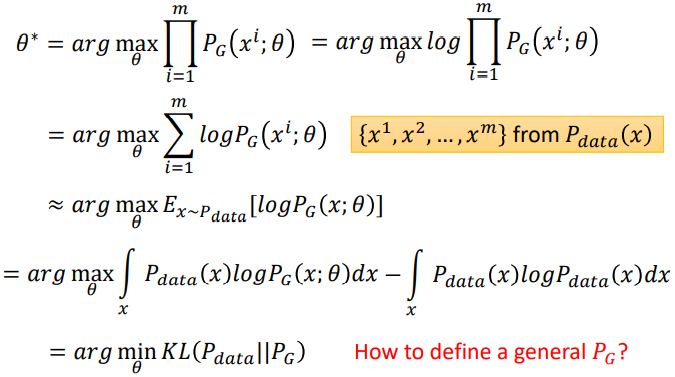
如果使用最大似然估计,采用高斯混合模型定义PG![]() ,生成的图片会非常模糊,现在使用generator产生PG
,生成的图片会非常模糊,现在使用generator产生PG![]() 。优化的目标就是使PG
。优化的目标就是使PG![]() 和Pdata
和Pdata![]() 越接近越好,即使得G*
越接近越好,即使得G*![]() 越小越好,但是不知道PG
越小越好,但是不知道PG![]() 和Pdata
和Pdata![]() 的公式。
的公式。
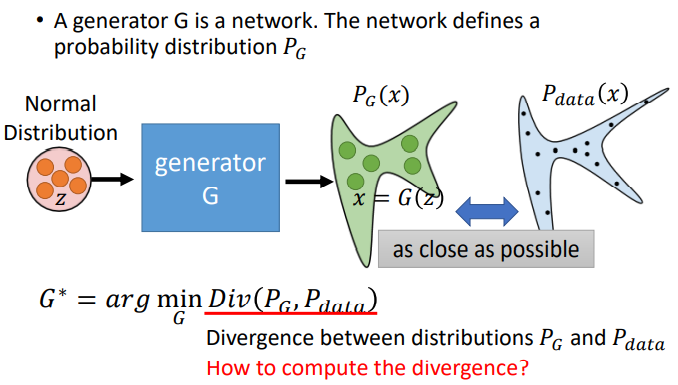
虽然不知道PG![]() 和Pdata
和Pdata![]() 的公式,但是可以从这两个分布中做sample。可以用Discriminator来衡量PG
的公式,但是可以从这两个分布中做sample。可以用Discriminator来衡量PG![]() 和Pdata
和Pdata![]() 的Divergence。训练出来的maxV(G,D)
的Divergence。训练出来的maxV(G,D)![]() 就相当于JS divergence。
就相当于JS divergence。
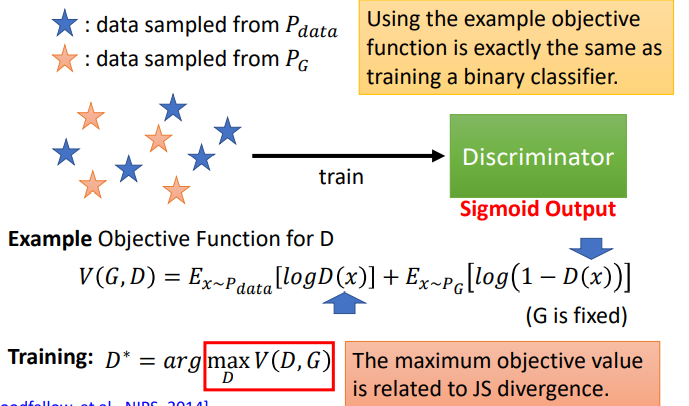
- 证明过程
要求V(G,D)的最大值,就是求![]() 的最大值。
的最大值。

因为![]() 和
和![]() 都是固定的,所以设为常数,然后通过求导求出最大值。
都是固定的,所以设为常数,然后通过求导求出最大值。

将求出的D* 回带入V(G,D),然后化简。
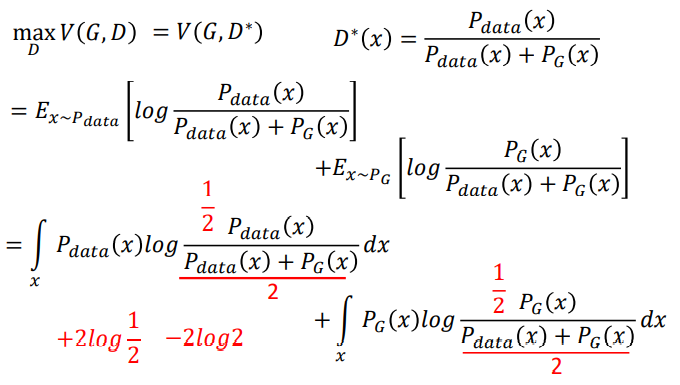
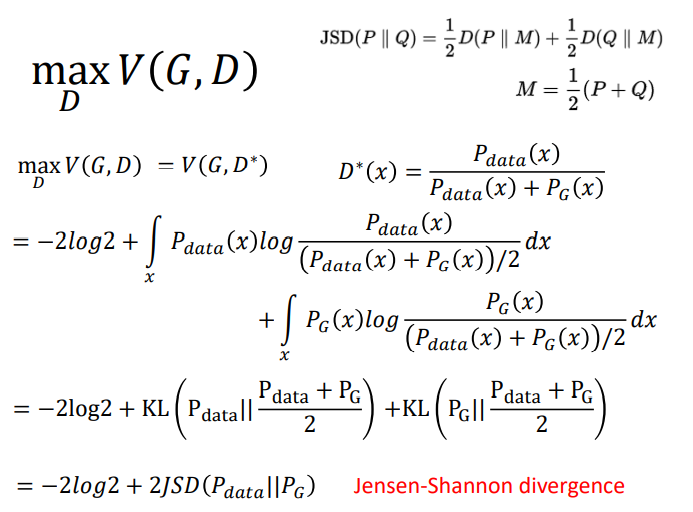
Generator 的训练目标就是,找到一个G* 去最小化![]() 和
和![]() 之间的差异,即
之间的差异,即![]() ,由于不知道
,由于不知道![]() 和
和![]() 的具体公式,所以无法直接计算divergence。于是通过一个discriminator来计算两个分布之间的差异,
的具体公式,所以无法直接计算divergence。于是通过一个discriminator来计算两个分布之间的差异,![]() 。所以最终优化目标为
。所以最终优化目标为![]() 。
。

首先训练D,多训练几次直至收敛;之后训练G:其中第一项是与生成器无关的,由于G不能训练太多,否则会导致D无法evaluate JS,所以update一次就好。

- In practice
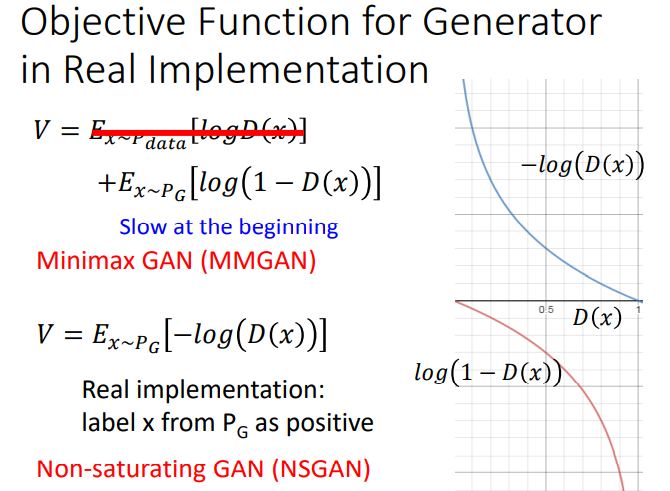
理论上V是要取期望值,但是实际上是不可能的,只能用样本的均值进行估计。

论文原文在实作的时候把![]() 换成
换成![]() ,蓝色曲线刚开始的值很大,适合做梯度下降。其实后来实验证明两种结果都差不多。
,蓝色曲线刚开始的值很大,适合做梯度下降。其实后来实验证明两种结果都差不多。
Conditional GAN
- Text-to-Image
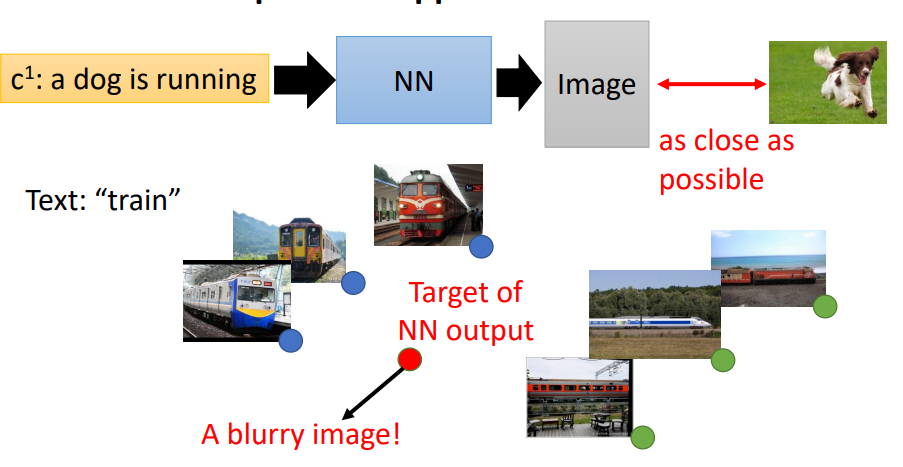
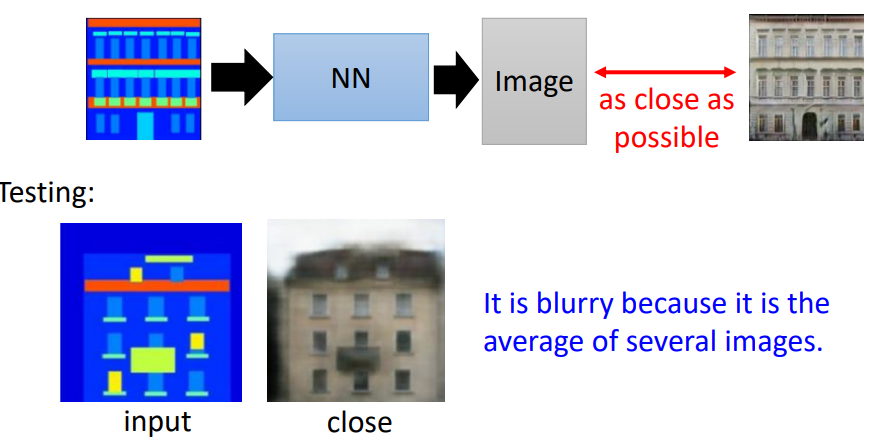
对于根据文字生成图像的问题,传统的做法就是训练一个NN,然后输入一段文字,输出对应一个图片,输出图片与目标图片越接近越好。存在的问题就是,比如火车对应的图片有很多张,如果用传统的NN来训练,模型会产生多张图像的平均,结果就会很模糊。
- Conditional GAN
Conditional GAN与普通GAN的区别在于输入加入了一个额外的condition,并且在训练的时候使得输出的结果拟合这个 condition。
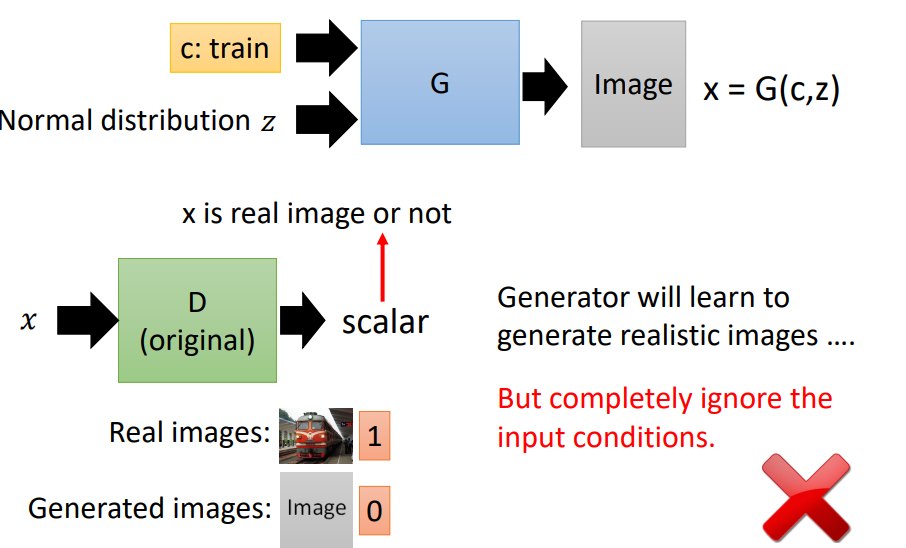
此时的discriminator的输入是generator的输出和conditional vector,此时discriminator有两个任务:
- 判断图片质量的好坏(图片是否是真实图片)。
- 图片是否和输入条件匹配。

- Algorithm
训练D(固定G):
- 首先从database中抽取m个样本,每个样本都是一对条件和图片。
- 从一个分布中抽取m个vector z;然后每个vector都加上条件,表示为(c,z)。
- 将(c,z)输入generator,生成m张图片x
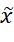 (条件+图片)。
(条件+图片)。 - 从database中随机选取m个真实图片 x
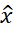 。
。 - 计算损失,最大化损失。
训练G(固定D):
- 随机产生m个噪声,随机从database中抽取m个条件;
- 通过generator得到G(C,Z),然后经过discriminator得到D(G(C,Z)),更改G中的参数,使得它的得分越高越好。

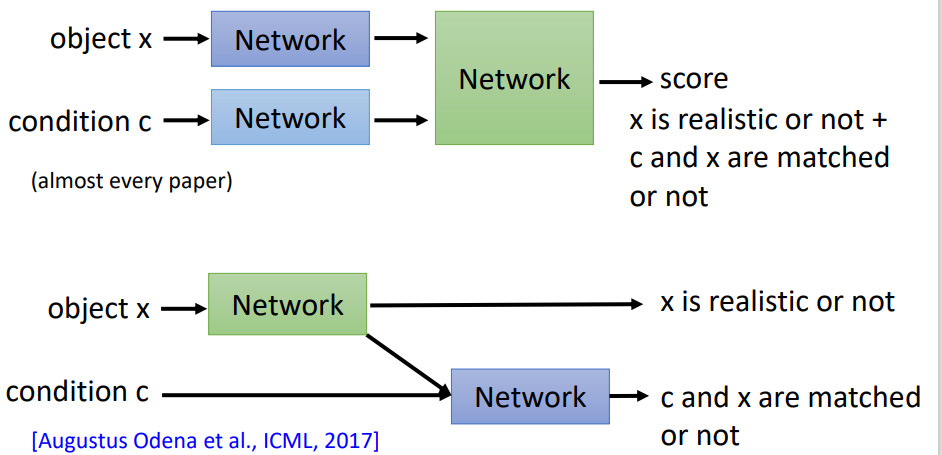
具体设计条件GAN判别器,有两种方式:
- 图片x经过一个网络变成一个code,条件经过一个网络也变成一个code;把这两种code组合在一输入到网络里面,输出一个分数。
- 首先让图片经过一个网络,输出一个分数(用于判断图片是否真实),同时这个网络也输出一个code,这个code和条件结合起来输入到另外一个网络里,也输出一个分数(图片和文字是否匹配)。
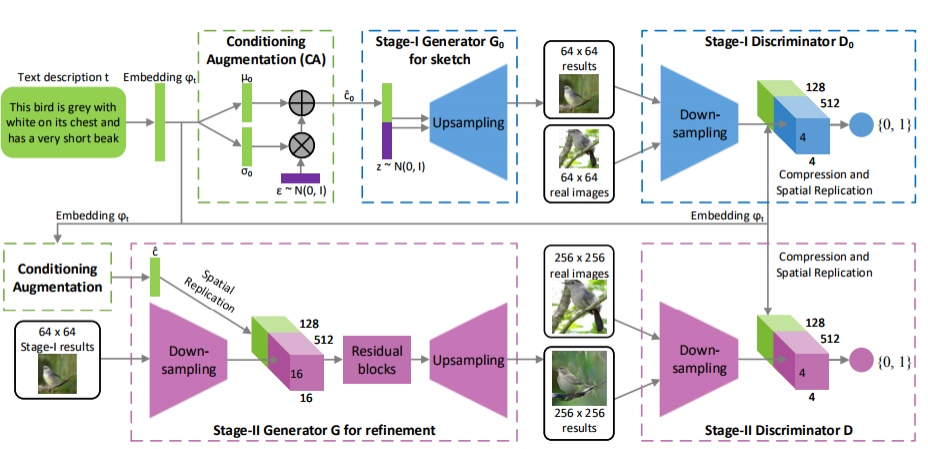
- Stack GAN(叠加生成对抗网络)
第一个网络生成小的图片,第二个网络生成大的图片。
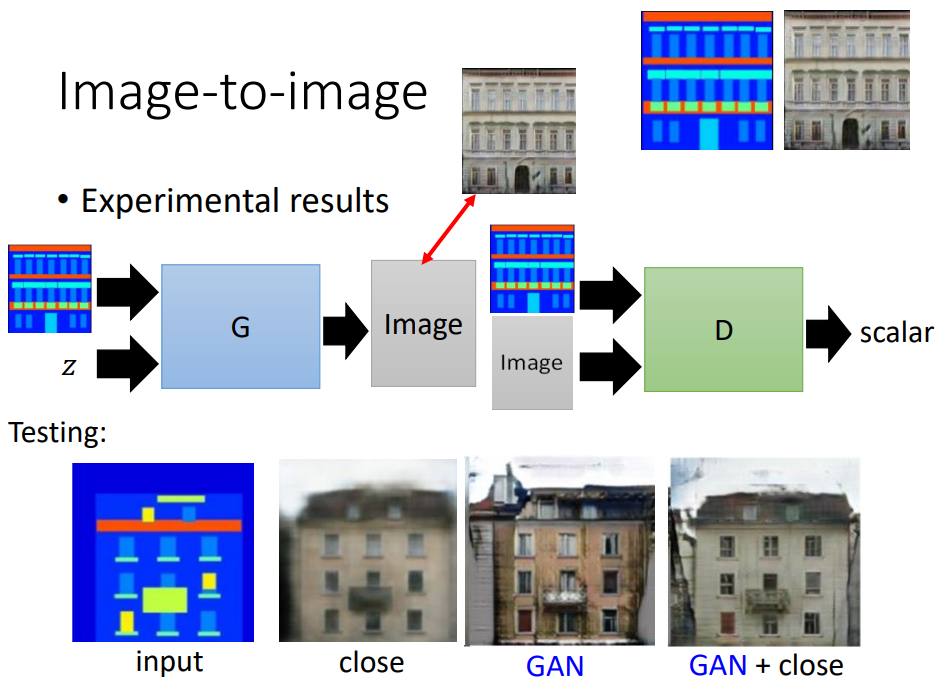
- Image-to-image
传统做法存在的问题就是产生的图片很模糊,是因为它是许多张图片的平均。
Conditional GAN的做法就是,generator的输入一张图片和noise z,输出一张图片,discriminator会输入产生的image和input,输出一个scalar。通过算法的迭代,生成下面第三张图片,看起来很清晰,但和真实的图片还是有差异。所以提出了GAN+close,对generator生成的image加上限制,使得生成的image与真实对象越接近越好,得到第四张图片。
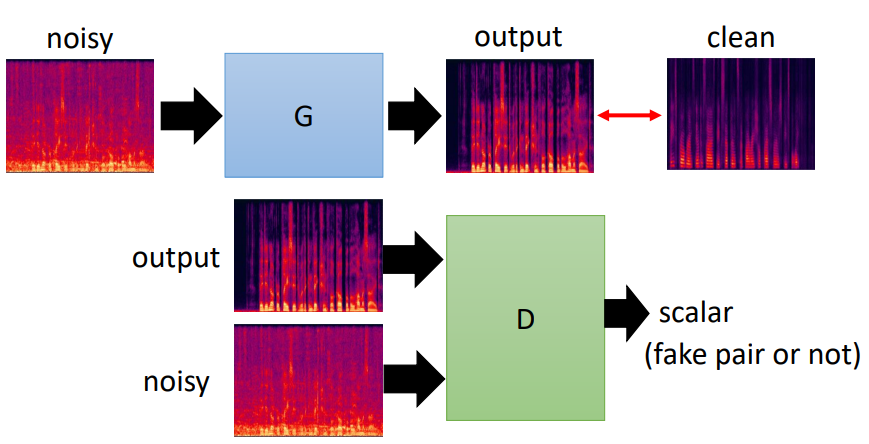
- Speech Enhancement(语音增强)
这里和image-to-image原理类似,都是把G的输入和输出作为D的输入。
Video Generation能够根据影片的前几帧产生后几帧。conditional 为之前几帧的图片。















 1087
1087











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









