







原文链接:
| 2022 | CVPR 2022 | MAT: Mask-Aware Transformer for Large Hole Image Inpainting [pdf] [code] |
本文创新点:
- 开发了一种新颖的修复框架 MAT,是第一个能够直接处理高分辨率图像的基于 transformer 的修复系统。
- 提出了一种新的多头自注意力 (MSA) 变体,称为多头上下文注意力 (MCA),只使用有效的token来计算注意力。
- 设计了一个风格操作模块,使模型能够通过调节卷积的权重来提供不同的预测结果。
网络结构
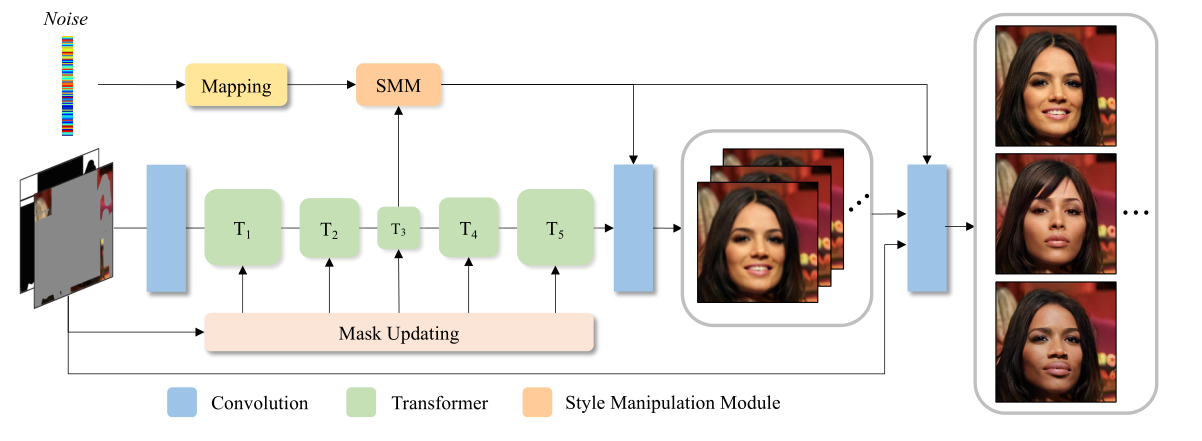 网络分为粗修复与细修复两个阶段。粗修复主要由一个卷积头,五个transformer模块和一个卷积尾构成;细修复采用一个 Conv-U-Net 来细化高频细节。
网络分为粗修复与细修复两个阶段。粗修复主要由一个卷积头,五个transformer模块和一个卷积尾构成;细修复采用一个 Conv-U-Net 来细化高频细节。
Convolutional Head
卷积头主要由四个卷积层构成,将3*512*512的图像转换成180*64*64的特征图,用来提取token。
Transformer Body
本文对transformer模块进行了改进,一是删除了层归一化,二是将残差连接改成了全连接层。
删除层归一化的原因:在大面积区域缺失的情况下,大部分的token是无效的,而层归一化会放大这些无效的token,从而导致训练不稳定;
删除残差连接的原因:残差连接鼓励模型学习高频内容,然而在刚开始大多数的token是无效的,在训练过程中没有适当的低频基础,很难直接学习高频细节,如果使用残差连接就会使优化变得困难。
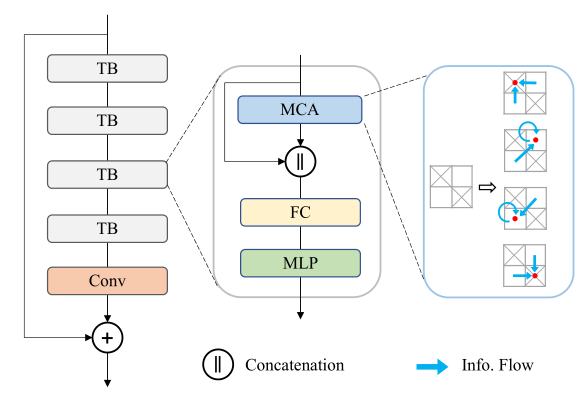
Multi-Head Contextual Attention
注意力模块利用移位窗口和动态掩码,只使用有效的token进行加权求和,
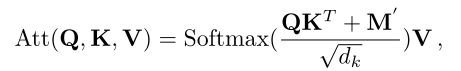
其中,![]() 表达式如下:
表达式如下:
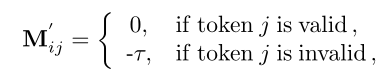
其中,![]() 为100。通过加上掩码
为100。通过加上掩码![]() ,无效的token经过softmax后的权重几乎等于0。每次计算注意力后,将w*w大小的窗口的位置移动 (⌊
,无效的token经过softmax后的权重几乎等于0。每次计算注意力后,将w*w大小的窗口的位置移动 (⌊ ![]() ⌋, ⌊
⌋, ⌊ ![]() ⌋) 个位置,从而实现信息交互。
⌋) 个位置,从而实现信息交互。
Mask Updating Strategy
更新规则:只要当前窗口有一个token是有效的,经过注意力后,该窗口中的所有token都会更新为有效的。如果一个窗口中的所有token都是无效的,经过注意力后,它们仍然无效。
Style Manipulation Module
它通过在带有额外噪声输入的重建过程中改变卷积层的权重归一化来操纵输出。为了增强噪声输入的表示能力,我们强制图像条件风格![]() 从图像特征X 和噪声无条件风格
从图像特征X 和噪声无条件风格![]() 中学习,
中学习,
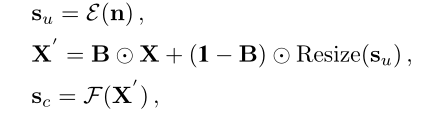
其中,B为随机二值掩码(值为1的概率为p,为0的概率为1− p),ε和F都为映射函数,最终的风格是融合两种风格得到的
![]()
其中,A为映射函数,则卷积的权重W更新为
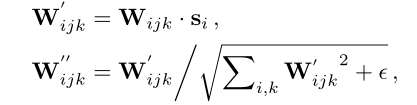
其中,i,j,k分别为输入通道,输出通道,卷积核的大小,ε为很小的常数。
损失函数
Adversarial Loss
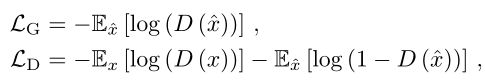
Perceptual Loss.
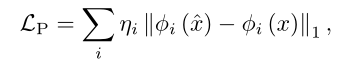
Overall Loss
![]()
















 1132
1132











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









