







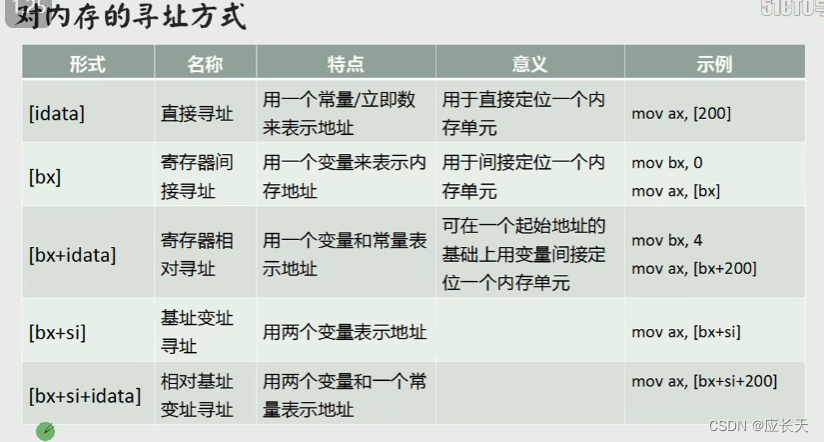
内存寻址方式 \blue{\huge{内存寻址方式}} 内存寻址方式
处理字符问题
在汇编程序中使用’…‘的方式指明数据是以字符串形式给出的。编译强将把它们转化为对应的
A
S
C
I
I
ASCII
ASCII码。
示例:
\color{olive}{示例:}
示例:
assume cs : code , ds : data
data segment
db 'unIX' //在数据段中,db开头,使用' '包括的内容被表示为字符串
db 'foRX'
data ends
code segment
start : mov al,'a'
mov bl,'b'
mov ax,4c00h
int 21h
code ends
end start
💥💥💥💥 字符串存储的时候存储的就是 A S C I I 码值!!! \color{blue}{字符串存储的时候存储的就是ASCII码值!!!} 字符串存储的时候存储的就是ASCII码值!!!
字母的大小写
\color{purple}{\huge{字母的大小写}}
字母的大小写
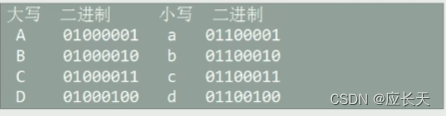
💥💥💥💥💥由图可知,大写与小写
A
S
C
I
I
ASCII
ASCII码值之间就只相差了
20
H
\red{20H}
20H。
大写
+
20
H
=
对应小写
大写 + 20H = 对应小写
大写+20H=对应小写
小写
−
20
H
=
对应大写
小写 - 20H = 对应大写
小写−20H=对应大写
示例:
\color{olive}{\huge{示例:}}
示例:
大小写转换问题
\red{大小写转换问题}
大小写转换问题

利用上面的结论:
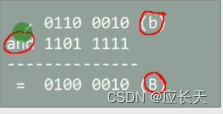
- 对于第一个字符串,小写→大写,其余不变情况,可以将原数据与
11011111
11011111
11011111做
a
n
d
(
与
)
\red{and}(与)
and(与)运算。
1
1
1位进行
a
n
d
and
and运算,原数据不变还是保留。
0
0
0只存在在第
6
6
6位,刚好将小写第
6
6
6位的
1
1
1转换为
0
0
0,而其余位置数据不变,这就完成了小写→大写。
C o d e : \blue{Code:} Code:
mov bx,0
mov cx,5 //第一个字符串的长度是5
s: mov al,[bx] //将每个字符取出来放到al中
and al,11011111b
mov [bx],al //操作完毕之后放回[bx]中
inc bx //bx自增移动到下一个位置
loop s
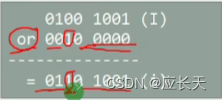
- 对于第二个字符串,大写→小写,可以将原数据与
00100000
00100000
00100000做
o
r
(
或
)
\red{or}(或)
or(或)进行运算。
0
0
0位进行
o
r
or
or运算,保留原来数据的情况。
1
1
1位只存在在第
6
6
6位,刚好大写第
6
6
6位是
0
0
0,进行
o
r
or
or后变为
1
1
1,完成了大写→小写。
C o d e : \blue{Code:} Code:
mov bx,5
mov cx,11 //第二个字符串长度为11
s0: mov al,[bx]
or al,00100000b
mov [bx],al
inc bx
loop s0
总代码: \blue{\huge{总代码:}} 总代码:
assume cs : codesg , ds : datasg
datasg segment
db 'BaSic'
db 'iNfOrMaTion'
datasg ends
codesg segment
start: mov ax , datasg
mov ds , ax
mov bx , 0
mov cs , 5
s : mov al , [bx]
and al , 11011111b
mov [bx] , al
inc bx
loop s
mov bx , 5
mov cs , 11
s0 : mov al , [bx]
or al , 00100000b
mov [bx] , al
inc bx
loop s0
mov ax , 4c00h
int 21h
codesg ends
end start
[ b x + i d a t a ] [bx + idata] [bx+idata]方式寻址
[
b
x
+
i
d
a
t
a
]
[bx + idata]
[bx+idata]就是表示的是一个内存单元,这个内存单元基于相应的段地址。在
b
x
bx
bx初始地址的基础之上偏移了
200
200
200字节的位置。
💥💥💥💥
[
b
x
+
i
d
a
t
a
]
:
[bx + idata]:
[bx+idata]:就可以理解成为
C
C
C中的数组下标访问。
示例:
\color{red}{示例:}
示例:

K
e
y
:
\color{red}{Key:}
Key:当然可以像上面一样一个一个字符串进行处理,但是仔细一看,两个字符串的长度相等,并且存储的时候字符串就是按照地址顺序进行存储的,换句话说
是可以通过
[
b
x
+
i
d
a
t
a
]
这种寻址方式使得两个字符串的处理同时进行的。
\color{blue}{是可以通过[bx + idata]这种寻址方式使得两个字符串的处理同时进行的。}
是可以通过[bx+idata]这种寻址方式使得两个字符串的处理同时进行的。
完整代码: \color{purple}{完整代码:} 完整代码:
assume cs : codesg , ds : datasg
datasg segment
db 'BaSic' //数据段中定义两个字符串
db 'MinIX'
datasg ends
codesg segment
start: mov ax , datasg //段地址初始化
mov ds, ax
mov bx , 0
mov cx , 5
s: mov al , [bx] //处理第一个字符串
and al , 11011111b //小转大
mov [bx] , al
mov ax , [bx + 5] //[bx+5] 访问第二个字符串相应的位置
or al , 00100000b //大转小
mov [bx + 5] , al
inc bx
loop s
mov ax , 4c00h
int 21h
codesg ends
end start
S I SI SI和 D I DI DI寄存器
S I SI SI和 D I DI DI又称为 变址寄存器 \red{变址寄存器} 变址寄存器,故经常 执行与地址有关的操作。 \red{执行与地址有关的操作。} 执行与地址有关的操作。
b
x
:
\blue{bx:}
bx:通用寄存器,在计算存储器地址的时候,常作为基地址寄存器使用。
s
i
:
\blue{si:}
si:
S
o
u
r
c
e
I
n
d
e
x
SourceIndex
SourceIndex,源变址寄存器。
d
i
:
\blue{di:}
di:
D
e
s
t
i
n
a
t
i
o
n
I
n
d
e
x
DestinationIndex
DestinationIndex,目标变址寄存器。
💥💥💥💥 s i 、 d i si、di si、di与 b x bx bx的唯一区别就是 b x bx bx可以看作两个 8 8 8位寄存器的合成,可以分别使用 b l bl bl和 b h bh bh,但是 s i 、 d i si、di si、di只能看作是一个 16 16 16位的寄存器。
✔️✔️✔️✔️ s i 、 d i 、 b x si、di、bx si、di、bx用法 完全一致 \red{完全一致} 完全一致!!!
示例:
\color{olive}{\huge{示例:}}
示例:

K
e
y
:
\red{Key:}
Key:使用
d
i
di
di和
s
i
si
si寄存器,
d
s
:
s
i
ds:si
ds:si指向要复制的原始字符串,
d
s
:
d
i
ds:di
ds:di指向目的空间,使用循环同时移动复制即可。
C o d e : \color{purple}{Code:} Code:
assume cs : codesg , ds : datasg
datasg segment
db 'welcome to masm!'
db '..............................' //预设定存储空间存放复制的字符串
datasg ends
codesg segment
start: mov ax , datasg //初始化段寄存器
mov ds , ax
mov si , 0 //si初始化为0,从字符串第一个字符开始访问
mov di , 16 //第一个开始复制的位置
mov cx , 8
s: mov ax , [si] //从si表示地址中提出字符存放到ax中
mov [di] , ax //再将ax中字符串存放到di对应地址中
add si , 2 //同时移动两个寄存器
add di , 2
loop s
mov ax , 4c00h
int 21h
codesg ends
end start
[ b x + s i ] [bx + si] [bx+si]和 [ b x + d i ] [bx + di] [bx+di]方式寻址
[
b
x
+
s
i
]
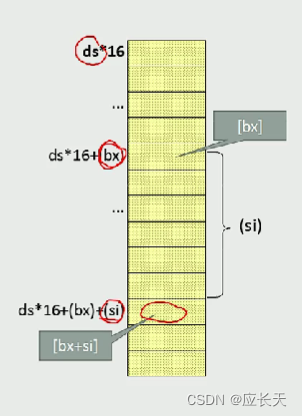
[bx + si]
[bx+si]表示的就是一个内存单元,这个内存单元的偏移地址是
[
b
x
+
s
i
]
[bx + si]
[bx+si],基地址是
d
s
ds
ds。
b
x
bx
bx:基址
s
i
si
si:变址
示例:
\color{olive}{\huge{示例:}}
示例:
mov ax , 2000H
mov ds , ax
mov bx , 1000H
mov si , 0
mov ax , [bx + si]
inc si
mov cx , [bx + si]
inc si
mov di,si
mov ax , [bx + di]
💥💥💥
[
b
x
+
s
i
+
i
d
a
t
a
]
[bx + si + idata]
[bx+si+idata]寻址方式
[
b
x
+
s
i
+
i
d
a
t
a
]
=
[
基址
+
变址
+
立即数
]
[bx + si + idata] = [基址 + 变址 + 立即数]
[bx+si+idata]=[基址+变址+立即数]
💥💥💥💥
使用方法与上面的使用方式可以说是完全一致
\red{使用方法与上面的使用方式可以说是完全一致}
使用方法与上面的使用方式可以说是完全一致
对内存寻址方式的总结 \blue{对内存寻址方式的总结} 对内存寻址方式的总结
灵活使用不同的寻址方式: \purple{\huge{灵活使用不同的寻址方式:}} 灵活使用不同的寻址方式:
示例
1
:
\color{olive}{\huge{示例1:}}
示例1:
[
b
x
+
i
d
a
t
a
]
方式
\orange{[bx+ idata]方式}
[bx+idata]方式

K
e
y
:
\red{Key:}
Key:
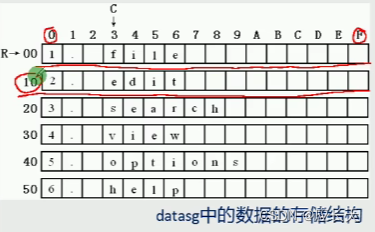
观察字符串的格式,和每次都将
首字母
\red{首字母}
首字母转换为大写,可以使用一个立即数常量锁定每一列的位置,然后使用
d
x
dx
dx寄存器来表示每一行,通过
a
d
d
d
x
,
16
\red{add \space dx ,16}
add dx,16来跳转到下一行。

C o d e : \color{blue}{Code:} Code:
assume cs : codesg , ds : datasg
datasg segment
db '1. file'
db '2. edit'
db '3. search'
db '4. view'
db '5. options'
db '6. help'
datasg ends
codesg segment
start: mov ax , datasg //初始化寄存器
mov ds , ax
mov bx , 0 //bx寄存器存储基址
mov cx , 6
s : mov al , [bx + 3] //3这个立即数卡好访问的列
and al , 11011111b
mov [bx + 3] , al
add bx , 16
loop s
mov ax , 4c00h
int 21h
codesg ends
end start
示例
2
:
\color{olive}{\huge{示例2:}}
示例2:
[
b
x
+
s
i
]
方式
\orange{[bx+si]方式}
[bx+si]方式

K
e
y
:
\color{red}{Key:}
Key:

要将所有字符串的字母都进行小写→大写,很明显需要
b
x
bx
bx来控制行的访问,还需要一个可变量来访问列,就可以使用
s
i
si
si来进行访问,换句话说需要
一个
b
x
和
s
i
和双重循环
\color{purple}{一个bx和si和双重循环}
一个bx和si和双重循环。
直观算法是这样的:

💥💥💥💥但是有一个问题,尽管使用的是双层循环,但是双层循环都是使用
L
o
o
p
Loop
Loop指令进行实现的,
也就是说两个循环共用一个
c
s
寄存器!!!
\color{purple}{也就是说两个循环共用一个cs寄存器!!!}
也就是说两个循环共用一个cs寄存器!!!
💥💥💥💥上图算法如果直接写成代码,在内层循环之中 c x cx cx寄存器中的值就已经是 0 0 0,之后到外层循环结尾判断,就根本不会执行外层循环!!!!
💥💥💥💥 所以关键在于如何保存下来外层循环时, c x 中的值 \red{所以关键在于如何保存下来外层循环时,cx中的值} 所以关键在于如何保存下来外层循环时,cx中的值
可以使用寄存器 d x dx dx存储外层 c x cx cx的值,但是寄存器资源过于稀缺,并且有可能 d x dx dx已经被占用了,这个方法不太可取。 ❌ \huge{❌} ❌
也可以将外层 c x cx cx的值存储在一个存储空间里面,但是这样有可能存储的那个存储空间本身存储着很重要的数据,可能导致非常大的隐患。 ❌ \huge{❌} ❌
放在特定的存储空间里面没有错误,关键是存储空间的选择, 可以放在栈空间之中。栈空间可以让系统进行分配,能够有效防止非法访问的问题出现 \color{purple}{可以放在栈空间之中。栈空间可以让系统进行分配,能够有效防止非法访问的问题出现} 可以放在栈空间之中。栈空间可以让系统进行分配,能够有效防止非法访问的问题出现。 √ \red{\huge{√}} √
C o d e : \blue{Code:} Code:
assume cs : codesg , ds : datasg
datasg segment
db 'ibm '
db 'dec '
db 'dos '
db 'vax '
datasg ends
stacksg segment
dw 0,0,0,0,0,0,0,0 //预先设定好栈空间
stacksg ends
codesg segment
start : mov ax , stacksg //栈段初始化
mov ss , ax
mov sp , 16
mov ax , datasg //代码段初始化
mov ds , ax
mov bx , 0
mov cx , 4
s0: push cx //将进入外层循环时cx的值入栈保存
mov si , 0
mov cx , 3 //cx置入内层循环的次数,恢复cx
s: mov al , [bx + si]
and al , 11011111b
mov [bx + si] , al
inc si
loop s
add bx , 16 //内层循环完毕之后转向下一个字符串
pop cx //取出之前保存的外层cx的值
loop s0
mov ax , 4c00h
int 21h
codesg ends
end start















 2188
2188











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









