







基础
-
机密性
-
完整性
-
可用性:保证经过授权的客户能及时准确的不间断访问数据。依赖于完整性和机密性
-
漏洞利用:一个与安全相关的软件缺陷实现预期之外的行为
- flag:设计层面
- bug:实现层面
-
软件包括:
- 操作系统
- 数据库系统
- 业务相关的管理信息系统
- 通信协议
-
OS访问控制策略:
- 不同用户、不同端口、不同目录之间设置无法相互访问
-
防火墙和入侵检测(IDS)
- 观察、阻止、过滤程序交换的消息
- 防火墙可以组织来自特定主机或者特定TCP端口的所有流量
- IDS过滤一直漏洞利用模式的数据包
-
防火墙粗粒度
-
IDS细粒度(语法过滤器,过于细粒度会影响性能(Dos)
-
心脏出血:
- 精心设计的数据包会导致Open SSL读取并返回有漏洞的服务器内存的部分内容,存在缓冲区过读的问题
- 黑盒安全技术不足以对抗心脏出血,根源在错误代码,可以分组分块在组装起来攻击
-
软件不安全的原因:
- 软件开发者:测试不到位、没有科学生产
- 软件工程:软件复杂性、需求的变动
-
渗透测试:打补丁、在系统发布之前广泛测试是一个好办法
-
操作系统:计算机中的系统软件,是一些程序模块的集合。他们能以尽量有效、合理的方式组织和管理计算机的软硬件资源,使用户能够灵活、方便地使用计算机,使整个计算机系统高效率运行
- 资源管理者
- 向用户提供各种服务:提供了方便易用的系统调用;进程创建、执行和文件目录的操作、I\O设备的使用、各类统计信息
- 对硬件机器的扩展:操作系统在应用程序和硬件之间建立了一个等价的扩展机器、对硬件抽象,提高可移植性
-
多任务切片:为每个程序提供CPU时间的切片
-
内核:处理底层硬件资源的管理:IO、键盘、内存的输入输出
-
进程:当前指定的程序的实例,最初存在永久存储器中,为了执行必须将程序加载到RAM中,并将其唯一表示为进程,同一程序的多个副本可以作为不同的进程运行
-
进程ID:给定进程的PID可以将CPU时间、内存使用情况、用户ID程序名称等关联起来
-
文件系统:分区或磁盘上所有文件的逻辑集合(目录);驱动器有一组构成树的嵌套文件夹组成
-
文件权限:操作系统检查文件全新啊,由文件权限矩阵显示允许谁对文件执行操作
- 组权限:某些组ID可以执行的操作
- 全局权限(默认访问)
- Read\Write\Xexecute
-
对于正在运行的进程,他被组织成不同的端,并将地址空间的不同部分分开
-
程序内存结构:

- 虚拟内存:由操作系统提供的,将多个物理存储碎片整合为一个连续的虚拟地址空间
linux
-
支持多用户多任务:各个用户和文件之间相互不影响
-
一切都是文件
-
su:超级用户root;只能获得root执行权限,不能获得环境变量
-
su - :以root用户身份登录;切换到root并获得root的环境变量执行及权限
-
sudo:使用超级管理员身份执行某操作,比su更安全
-
PATH在/etc/profile文件中有指定,echo $PATH
-

- 解决方法:指定完整路径名,不应该使用su命令从用户会话中取得root用户特权,应该使用自己的标识登录到机器:/usr/bin/su -root
文件系统安全
-
文件名并不是数据的一部分
-
大部分的Linux文件系统由目录项inode和数据块组成
-
目录项:包括文件名和inode号码
-
inode:又称文件索引节点,包含文件的基础信息以及数据快的指针
- 文件的字节数、文件的拥有者的User ID,文件的组ID、文件的读写执行权限、文件的时间戳、链接数、文件数据block的位置
-
数据块:包含文件的具体内容
stat app.apk -
文件占据的数据块
ls -l ls -s -
Linux文件存储中,文件名不是文件内容的一部分
-
windows并列树状结构,linux单个树状结构



-
-
Linux中目录也是一种文件
-
链接是对文件的引用
-
链接就是他所对应的原始文件
-
软连接和硬链接
-
硬链接:用不同的文件名访问相同的内容、对文件进行修改会影响到所有的文件名,删除一个文件名不影响另一个文件名的访问
ln source_file target_file两个文件的inode号码相同,链接数+1,当链接数为0则系统会回收
-
软连接:(符号链接)类似于windows的快捷方式,删除根文件其余文件访问时会报错
ln -s source_file target_file
-
-
权限
-
自主访问控制:(DAC)
- 文件的所有权:系统中的每个文件都有所有者,文件的所有者就是创建这个文件的用户,那么此文件的自主访问控制权限由它的所有者来决定如何设置和分配
- 时操作系统中使用的标准模型
-
ACE访问控制条目与ACL访问控制列表:
- ACL时ACE的集合
- ACE:允许/拒绝用户/组队文件/文件夹的某种类型的访问
-
作用于文件、目录等
-

-

-
十字符显示法
-

-

-



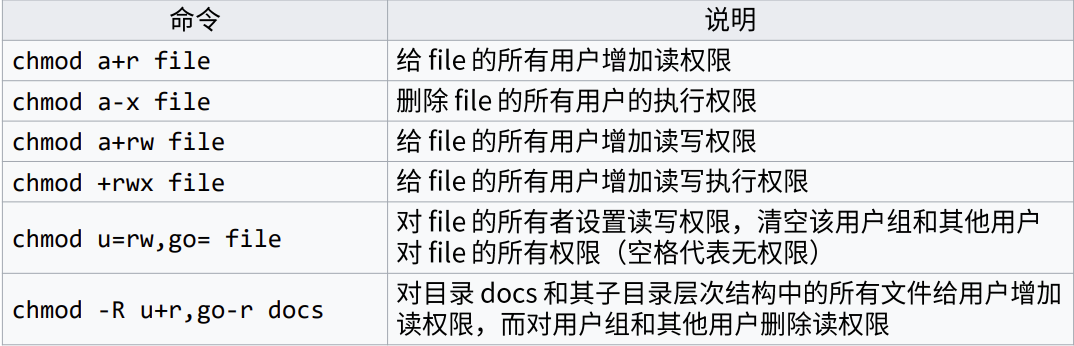
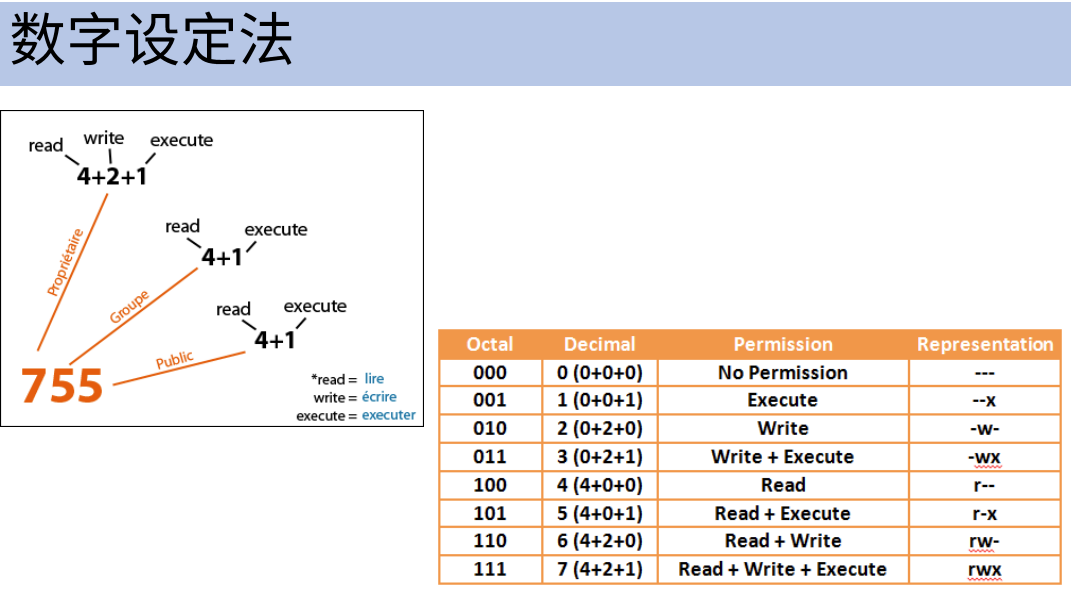
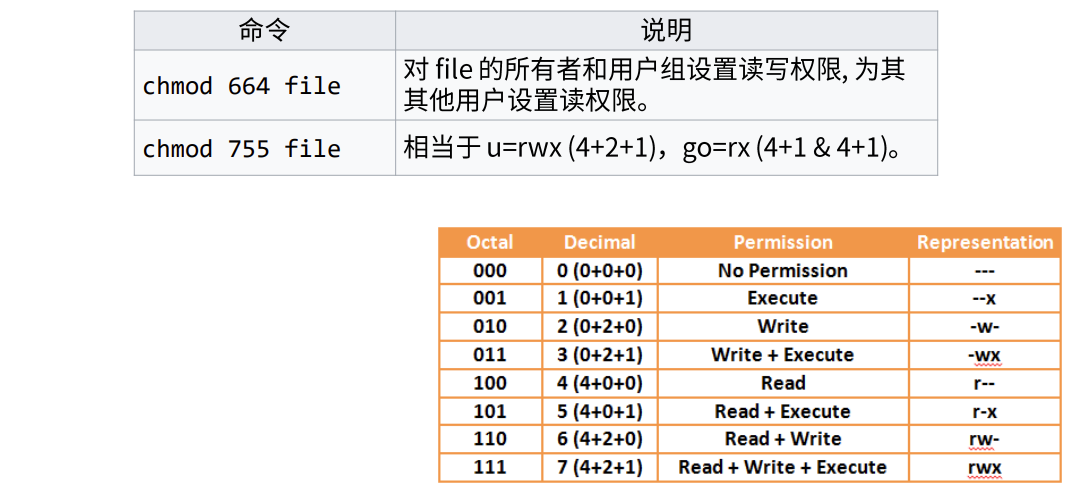
-
安卓的资源隔离:会为每个应用分配单独的用户ID
-
基于Linux的用户组的概念
-
//注意设定顺序 sudo chown root vulp sudo chmod 4755 vulp
缓冲区溢出
-
计算机编译:
- 程序必须要经过编译才转换成CPU可以接受的指令
- 一句程序可能转换为多句指令
- 程序在执行过程中是在内存中完成的
- 程序在执行过程中,在内存中的不同区域,存放代码和相关的数据
-
电脑内部使用的是虚拟内存
- 方便管理
- 可以做到内存隔离
- 上课使用的是32位,64位可以做到向下兼容
- 64位仅使用2^48虚拟地址内存
-
虚拟地址
- 虚拟地址通过CPU的转换才能对应到物理地址,而且每次程序运行时,操作系统都会重新安排虚拟地址和物理地址的对应关系,那一段物理内存空闲就用那一段
- 程序无需介入操作系统的内存管理
- 优点:地址空间相互隔离,程序A和B虽然都可以访问同一个地址,但他们呢对应的物理地址是不同的,无论如何操作都不会修改对方的内存
- 可以提高内存使用效率,操作系统会更多的介入到内存管理工作中,这使得控制内存权限成为可能
- 虚拟空间的大小收到物理地址的映射关系(操作系统)以及编译模式的影响
-
C与指针
- 指针用来表示一个地址,引用了存储器(内存)的地址
- 取出值的过程叫做解引用
- typename *p; 此时 *p=var=值的大小;p=&var=存储的地址
-
内存布局:(从上到下为由高地址到低地址)
- 进程启动时才被设定(对编译条件进行设定)
- Stack(栈:存储局部变量、函数参数、返回地址等;栈是由编译器自动分配并释放的)
- 栈由高地址向低地址增长:向下
- 栈顶由栈指针**%esp**来标记,是一个32为寄存器,里面存放着最后一个压入栈顶的项的内存地址
- 函数中return返回变量:清除已经push进来的数据,返回值
- Heap(堆:动态分配的内存;由程序员手动分配和释放)
- 堆由低地址向高地址增长:向上
- 代码段 |
- 静态(初始化数据) | 这三个段是在编译时已知的
- BSS(未初始化的静态变量) |
-
栈与函数调用:
-
基本的栈布局:低——>高地址
//压栈顺序:loc2,loc1,...,...,arg1,arg2,arg3,caller's data void func(char *arg1, int arg2, int arg3){ char loc1[4]; int loc2; .... loc2++; //此时如何找到loc2的地址? .... //程序在编译时无法找到绝对地址,但我们始终知道相对地址,loc2始终在....的8bytes之前,因为是32位地址 } -
%ebp:ebp寄存器记录了一个帧指针,用于记录loc1的地址;&ebp+8即为loc2的值
-
%ebp …(%eip) arg1 arg2 arg3 caller’s data %ebp(压栈后) %ebp(压栈前) -
代码段中有指令指针%eip从低向高告诉我们执行到哪一行代码
- 执行到func后需要知道原来的代码到哪一行了,%eip也需要压栈
-
总结:
-
调用函数:
- 将参数压栈(反向)
- 压入返回地址,即返回后你想要运行的指定的地址
- 跳到要执行的函数的地址
-
被调用函数:
- 将旧帧指针压入栈(%ebp)
- 将帧指针%ebp设置为当前栈末尾的位置(%esp)
- 将局部变量压入栈
-
函数返回:
- 充值之前的栈帧:%ebp = (%ebp)
- 回到返回的地址:(%eip)=4+(%eip)
-
三者作用:
1.EIP寄存器里存储的是CPU下次要执行的指令的地址:也就是调用完fun函数后,让CPU知道应该执行main函数中的printf(“函数调用结束”)语句了。
2.EBP寄存器里存储的是是栈的栈底指针,通常叫栈基址,这个是一开始进行fun()函数调用之前,由ESP传递给EBP的。(在函数调用前你可以这么理解:ESP存储的是栈顶地址,也是栈底地址。)
3.ESP寄存器里存储的是在调用函数fun()之后,栈的栈顶。并且始终指向栈顶。
-
-
-
缓冲区溢出:
-
#include <stdio.h> int main() { int i,t; char s[]="abcdefg"; char *p; p=s; printf("字符串占用 %d 个字节\n\n",t=sizeof(s)); for(i=0;i<t;i++) printf("%c %x \n",*(p+i),*(p+i)); } //输出: 字符串占用 8 个字节 a 61 b 62 c 63 d 64 e 65 f 66 g 67 0 -
void func(char *arg1){ //int auth = 0; //非常关键,可以用来判断缓冲区溢出是否覆盖掉了他来执行其他操作 char buffer[4]; strcpy(buffer, arg1); if(auth == 0){ //没有发生溢出时,可以做的操作 ....... } } -
对于溢出的内容可以是代码让程序执行
-
如何注入代码
-
如何将自己的代码加载到内存中
-
如何让%eip指向它(相当于变成主程序执行)
可以将返回地址改为自己代码的地址
劫持%eip(由于再%ebp与%eip之间还有可能有其他指令,因此我们不能精确计算把自己的%eip填在想要的地方)
可以使用nop指令(no operation有效的不操作指令):再%eip(保存填充地址的位置)与代码指令段之间填充nop指令,增加攻击成功的概率
-
运行什么代码:通用的shell代码;命令行,为攻击者提供对系统的一般访问;启动shell的代码成为shellcode;可以通过提权拿到rootshell
name[0] = "/bin/sh"; name[1] = "NULL"; execuve(name[0], name, NULL);
- 注意:
- 必须是机器代码指令
- 小心构建:不能包含任何全零字节,否则sprintf/gets/scanf…将停止复制,
- 不能使用额外的组件来解析程序地址
-
-
-
其他攻击:
-
stack smashing(栈缓冲区溢出)
-
(堆缓冲区溢出)
int main(int argc, char *argv[]){ char *input = malloc(20); char *output = malloc(20); strycpy(output, "normal output"); strcop(input, argv[1]); //argv[1]的长度>=20bytes是不一定溢出,因为操作系统分配内存时可能会有一个内存对齐策略,32位系统按每8字节对齐 } -
整数溢出(千年虫)
-
计算机整数是以二进制的方式存储的
-
一个整数有一个固定的长度,他能存储的最大值时固定的,当场是存储一个大于这个固定的最大值时,将导致一个整数溢出;当4-bit存储时,存16(10000)会变成(0000)
#include<stdio.h> int main() int InputTest; unsigned short OutputTest; printf("InputTest"); scanf("%d",&InputTest); OutputTest=InputTest; printf("OutputTest:%d\n")
-
-
以上攻击会影响代码,返回值和函数指针
-
可以溢出数据:
- 修改状态变量以绕过授权检查(前面的auth位)
- 修改命令部分的解释字串,例如SQL注入
-
缓冲区过读
-
不同于写入缓冲区,这种bug可以用来泄露秘密信息
int main() char buf[100],*p; int i,len; while(1){ p=fgets(buf,sizeof(buf),stdin) //指定buf放sizeof大小的数据 if(p==NULL) return 0; len = atoi(p); p=fgets(buf,sizeof(buf),stdin) if(p==NULL) return 0; for(i=0;i<len;i++){ //len的长度可能超过真实的消息长度,且他不会因为是’\0‘停止 if(!iscntr1(buf[i])) } } -
心脏出血漏洞HTTP
- SSL服务器定时接受心跳消息,确保其他服务器存活
- 心跳消息指定器回显部分的长度,但有缺陷的代码没有确定回显长度
-
过期内存
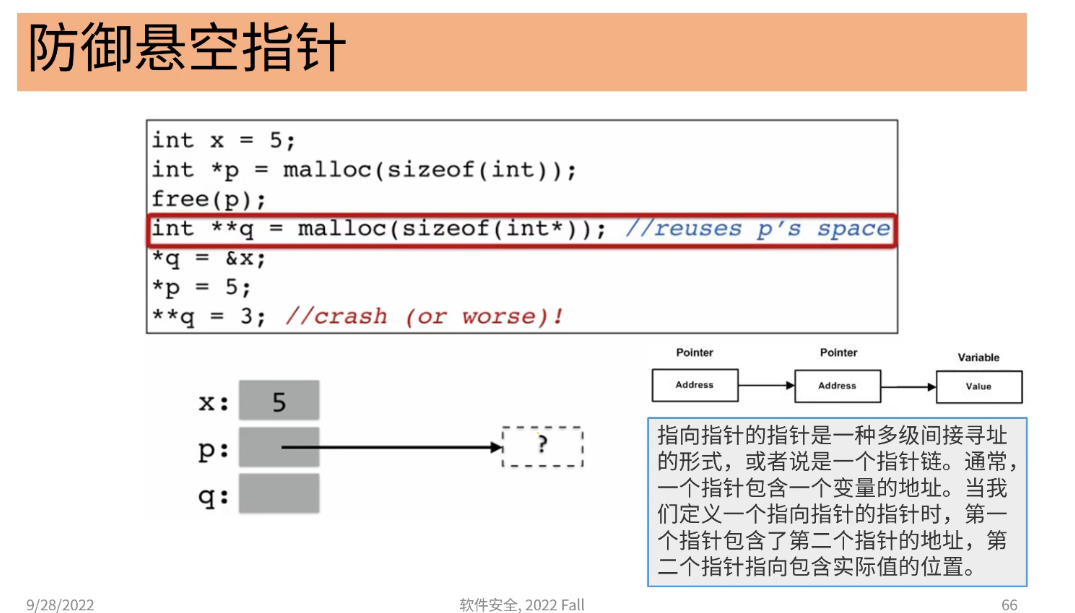
void func(){ char *dp=(char *)malloc(A_CONST); ... free(dp); //dp变为悬空指针 }//free只是把指针所指向的内存时放掉,但并没有把指针本身释放掉,可以通过访问dp指针访问以后可能会用到的该片区域 -
格式化输入输出
void print_record(int age, char *name){ printf_("Name: %s\tAge: %d\n",name,age); }void safe(){ char buf[80]; if(fgets,sizeof(buf),stdin)==NULL; return; printf("%s",buf); } void vulnerable(){ char buf[80]; if(fgets,sizeof(buf),stdin)==NULL; return; printf(buf); //没有格式化为字符串输出,攻击者可以控制格式化, } //读取字符大小过大到了别的栈帧 -
printf的实现
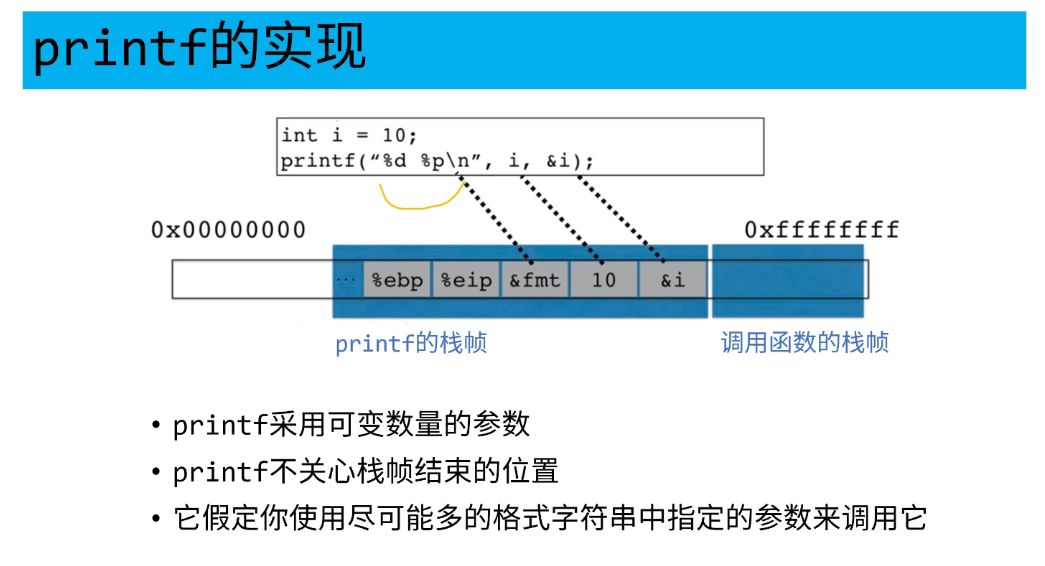
-
-
如何防御
-
有什么共同之处?
- 控制程序使用的某些数据
- 利用数据访问程序中的某些存储区
- 缓冲区
- 到栈上的任意位置
-
防御技术
-
内存安全特性
内存安全程序:执行时对任何输入都是内存安全的
内存安全(编程)语言:使用的语言对内存安全(不操作内存)
-
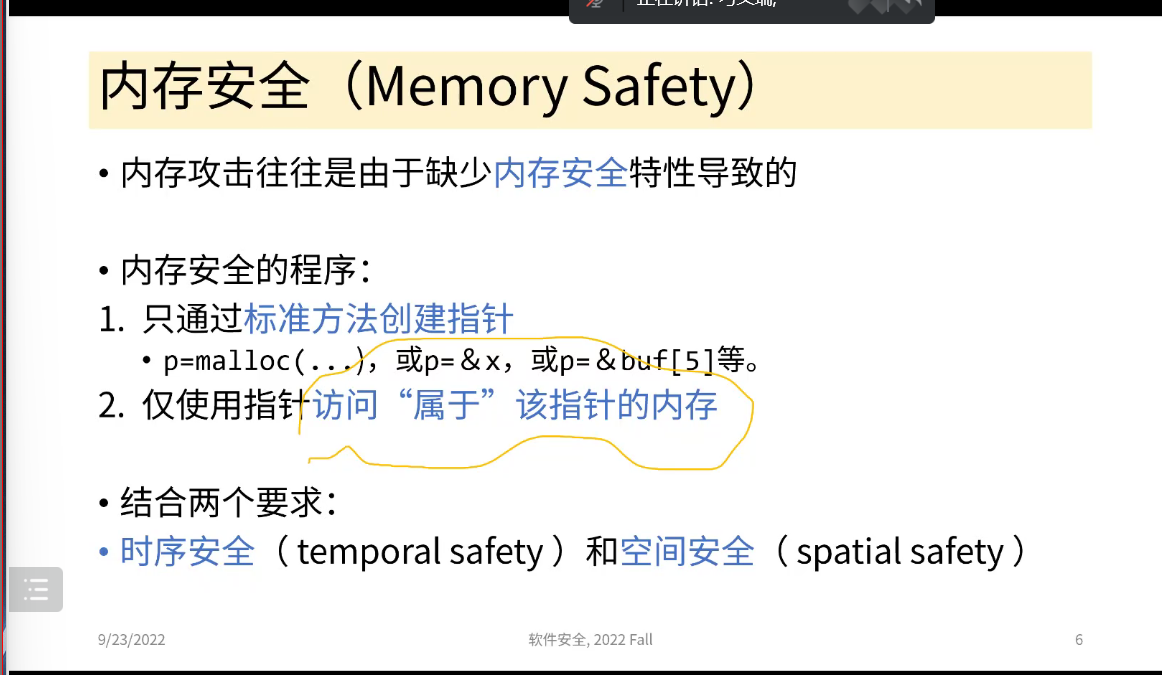
空间安全:

//指针变量的加减运算与类型的大小有关,指向字节起始位置 int x; //假设sizeof(int)=4 int *y = &x; //p = &x,b = &x,e = &x+4 int *z = y+1; //p = &c+4,b = &x,e = &x+4 *y = 3; //OK: *z = 3; //BAD:struct foo{ char buf[4]; int x; }; struct foo f={"cat",5}; char *y=&f.buf; //p=b=&f.buf+3<=(&f.buf+4)-1 y[3]='s'; //OK y[4]='f'; //BADstruct foo{ int x; int y; char *pc; }; struct foo *pf = malloc(...); pf->x=5; pf->y=256; pf->pc="before"; pf->pc+=3; int *px = &pf->x;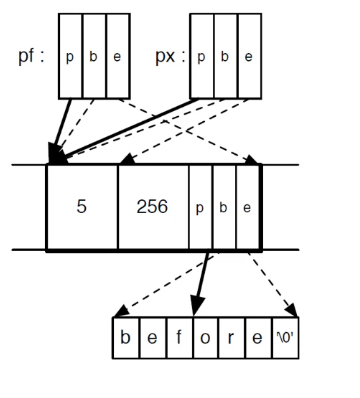
void copy(char *src,char *dst, int len){ int i; for(i=0;i<len;i++){ dst=*src; src++; dst++; } } -
格式化字符攻击

-
时序安全
悬空指针访问到了过期内存
//访问已释放的内存,内容随机 int *p=malloc(sizeof(int)); *p=5; free(p); printf("%d\n",*p); //访问未初始化指针,所指向的地址随机 int *p; *p=5;//违反时序安全
-
-
自动防御
-
栈警惕标志
使用canary检测溢出:在buffer和栈帧之间插入canary,溢出时会把canary覆盖掉,检测到被覆盖后报错

放难以利用和猜测的值
-
终止符



问题:没有对局部变量进行保护、堆上无法防御
-
使栈数据不可执行

-
-

-
没把恶意代码放到栈上,通过返回到库函数执行启动一个shell
-

-

-

-

-
-

-

-

-
-
Web安全
-
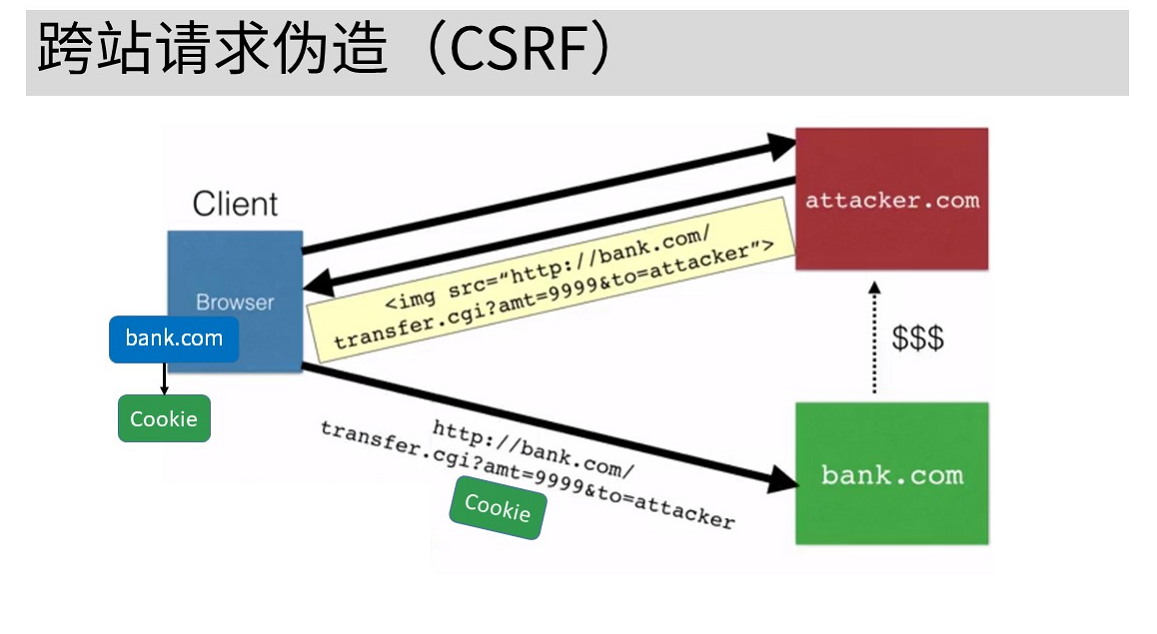
跨站请求伪造
-
同站请求伪造:请求被发送到了不同网站,网页的来源和请求的去处不是同一个网站




echo "$sql<br>";



-
跨站请求伪造
- 保护:在请求地址中添加token
-
攻击页面的Javascript不可以读取被攻击的页面
竞争条件
-

-
TOCTOU:文件竞争规律:在使用文件之前检查文件的属性
-
实际上有可能无效,被称为TOCTOU,会有一个时间差导致竞争条件
-
要求运行setuid对一个属于程序运行者的文件执行写操作
-
程序使用access判断执行

恶意文件使用符号链接到另外一个执行文件


-
-
做法:
- 将检查可使用的操作变成原子化操作,使其之间不留时间;
- 多次检查
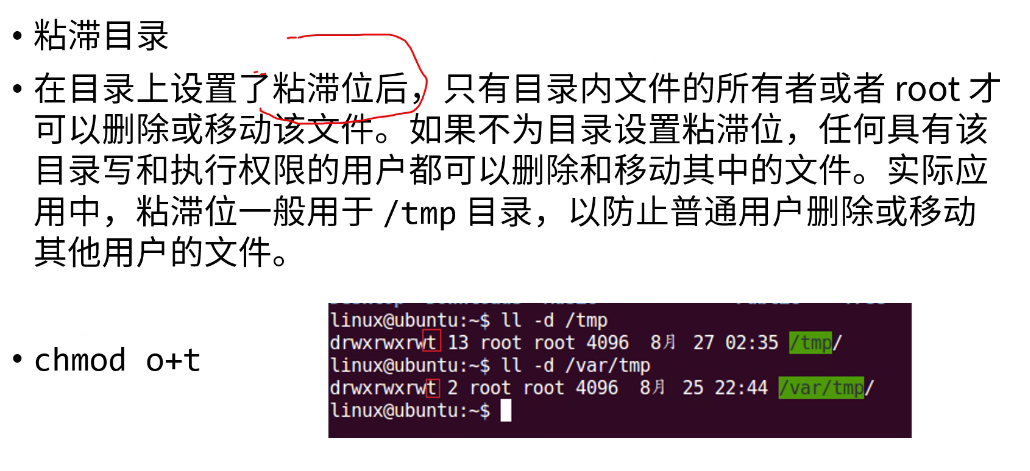
- 粘滞目录保护位
- 最小权限原则
-
其他竞争条件
- 数据库的数据同步(先花钱,再集体全同步)

- 建议:尽量使用单线程不要多线程,多线程时将某些问题原子化操作
-
APP全局API(辅助操作):
-
安装劫持:(第三方应用市场)在后台静默安装时会需要INSTALL_PACKAGES系统权限;自动安装:第三方应用市场通过access_ability_API绕过了系统权限。

“检查机制相当于帮助使用者自己点击了install按钮
-
恶意软件和正常软件哪一个会显示在前台并被点击?
-
安全设计原则
- 比起修补,从一开始就建立安全性
安全工程
- 需求分析
- 设计
- 代码实现
- 测试
- 开发阶段
威胁模型
- 明确了对手的假定能力
- 模型中做出的假设都是对手可以利用的潜在漏洞
安全需求
-
隐私与机密性:防止未授权的用户访问数据
-
匿名:例如非账户持有人可访问bank网站的信息而不被跟踪
-
完整性:防止未授权的修改数据
-
可用性:经授权用户及时准确不间断访问数据(Dos)
系统提供的机制:身份认证、授权、审计
身份认证:确认操作者身份,将行动与身份联系起来
授权:被授权者可以执行某项操作
审计:保留足够信息以确定违规或者不当行为
误用例
用例描述系统该做什么,误用例描述系统不该做什么
- 用例实例:系统允许银行经理修改账户的利率
- 误用例实例:用户可以欺骗经历,从而更改账户的利率
软件安全指导原则
软件缺陷包括flaw(设计中的问题)和bug(实现中的问题),设计阶段很重要
安全设计原则分类
预防:完全消除软件缺陷
缓解:减少未知缺陷造成的伤害
检测:识别并理解攻击,还原伤害
尽可能简单
越复杂安全性就越难
-
使用默认失效安全
- 配置和使用选择会影响安全性,默认选择应该是安全的
-
不要指望专家级用户
- 考虑用户思维模式和能力
- 默认提供安全性而不是繁琐操作后获得安全性
-
口令:难猜到=难记住
-
口令管理器:记住一个主口令
-
对口令强度进行反馈
谨慎信任
XcodeGhost
- 最小权限原则:只授予为执行某操作而必须的最小访问权限,只分配访问所需的最小时间。最大可能减 少程序滥用
- 信任是会传递的,信任A即信任A所信任的一切
- 输入验证是一种最小权限验证
- 尽可能限制敏感信息的流量(例如pdf只能看不能下载)
- 隔离:断开数据库与internet连接,linux一种沙盒——seccomp沙盒(只允许四种系统调用命令)
- 分割:隔离的同时,系统分割为小单元降低损害
深度防御
- 使用多种防御策略管理风险
监控与可追溯性
- 记录相关操作
防御措施
- 使字符串安全(char、strcpy…)、是STD Calls安全(获得异常参数时出发错误处理机制)、最小权限 (不受信任输入由非root处理,尽可能以非特权用户运行减少权限,chroot操作可指定根目录,隐藏指 定根目录之外的的所有目录,不能操作)
漏洞分级报告
CVE
- 通用漏洞披露,一个与消息安全有关的数据库,为每个漏洞赋予专属编号:CVE-YYYY-NNNN(YYYY公 元纪年,NNNN流水编号)
- 供应商一般对安全漏洞保密直至相关修复已完成再发布
- 满足一定条件才能分配CVE ID
负责人的披露
不能黑白通吃,responsibility disclosure
漏洞评级
CVSS标准,三个度量组:基础、时间、环境
基础度量组:反应漏洞固有特征,不随时间和用户环境改变
- 可利用指标:可被利用的简单程度与技术手段
- 影响指标:成功利用该漏洞导致的直接结果及后续结果
程序分析
软件测试引导
软件测试:需求分析、设计规格说明和编码的最终复审,随着软件规模和复杂性增加日趋重要
bug:计算机错误
Debug:寻找错误
只有通过软件测试才能发现软件缺陷,只有发现缺陷才能将其从软件产品中清除
软件测试的正面性:为了验证软件产品能否正常工作
软件测试的反面性:测试是为了证明程序有错
软件测试过程
单元测试:针对程序最小单元——模块/组件进行白盒测试,从内部结构出发设计测试用例,检查 每个单元已实现功能与定义功能是否一致
**集成测试:**将模块组装起来进行测试,主要为了发现与接口有关的模块之间的问题。
- 非增式集成测试法:将各模块连接起来作为整体进行测试
- 增式集成测试法:不断将待测模块连接到已测模块上进行测试
**确认测试:**从用户角度进行功能验证,基于产品说明书 系统测试:将软件放在实际运行环境下进行安全、强度、性能等测试,开发人员和组织不能参与
**验收测试:**进一步确保软件准备就绪执行既定功能

**软件测试环境:**硬件(什么设备什么配置)+软件(OS)+网络(局域网or互联网,传输带宽等)+数据准备(尽可 能大量真实的正确与错误数据,没有就模逆)+测试工具(已有、购买或自行开发,根据需求)
尽量去模拟真实环境,不要安装与测试无关软件,环境与开发环境独立
静态分析与动态分析
**程序测试:**确保程序在输入集上正确运行,出席那故障有助于恢复,但昂贵,难以覆盖所有代码路径
**代码审计:**源代码分析,说服他人源代码是正确的。人类一次乐意看出多次错误,所以后优于单次运行,但人力昂贵
**自动化程序分析技术:**静态&动态(是否需要运行代码)
-
**静态分析:**检查代码或运行自动化方法来查找错误,覆盖率更高,智能分析优先属性,可能漏报误报,运行非常耗时
-
**动态分析:**测试条件下运行代码查看可能的问题(比如GDB)
数据流分析(污点分析)
- 显示:明显赋值关系等
- 静态污点传播分析(简称静态污点分析)是指在不运行且不修改代码的前提下,通过分析程序变量间的数据依赖关系来检测数据能否从污点源传播到污点汇聚点.
- 静态污点分析的对象一般是程序的源码或中间表示.可以将对污点传播中显式流的静态分析问题转化为对程序中静态数据依赖的分析:
- 动态传播分析:对污点分支控制范围内的所有赋值语句中的变量都进行标记
- 隐式:通过循环侧面影响
获取相关数据沿着程序执行路径流动的信息分析技术
**污点分析:**跟踪并分析污点信息在程序中的流动,许多攻击就是因为信任了未经验证的输入(格式化字符串攻击)
对用户输入做污点标记(代表可能被敌手控制),其他数据假设不被标记
strcpy、printf、SQL查询表单字段等往往不希望污点标记的数据

无污点标记数据流:对所有可能输入证明在预期无污点数据的地方永远不会使用污点标记数据(需要推 断数据流)
- tained标记的数据可以接收tained或者untained的data
- u n t a i n e d ≤ t a i n e d untained \leq tained untained≤tained
- 这里的大小可以认为是风险值
- untained的data仅可以接受untained的data,这里untained表示不希望对手控制,一旦控制说明fail
- u n t a i n e d ≰ t a i n e d untained \nleq tained untained≰tained
- 即受过污染的都可以,不受污染的只能接受干净流
- 在一条指令中,如果至少一个读位置是污染的,就将所有的写位置污染
- 在一条指令中,如果所有的读位置都是非污染的,就将所有的写位置去污染
污点流污染
- 流敏感:正常使用
- 路径敏感:为了解决流敏感的同一个变量调用两次(如常量)
- 上下文敏感:为了解决路径敏感的两次同时调用一个函数的问题,输入标记为-1,返回值标记为+1
**分析途径:**创建名称(α,β)-生成约束-求解约束-无解可能有非法流


没有α,β的解
当存在条件时能够检测出非法的流

去除条件时,会出现误报

原因是分析过程流不敏感(没有考虑程序语句执行的顺序)
增加流敏感:允许一个变量的每个指定使用不同限定符多条件时,再次产生误报
原因是分析过程路径不敏感(没有考虑路径可行性)
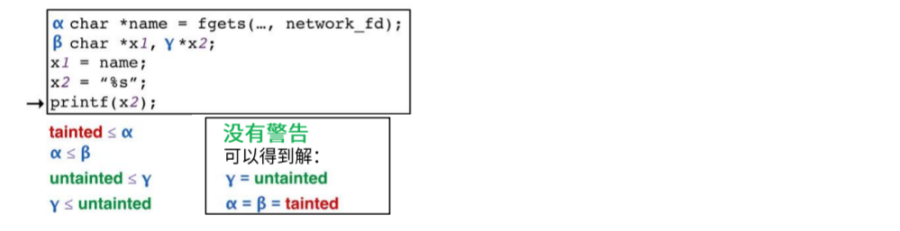
增加路径敏感,分析检查可行性
流敏感和路径敏感都会增加精度,但二者使求解变困难。精度的提高降低了可扩展性

函数调用也创造了流:
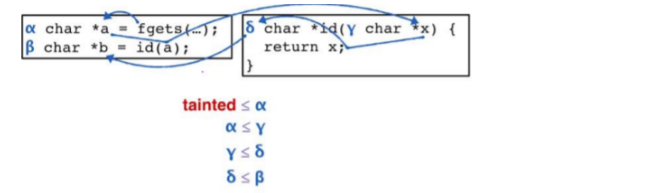
两次调用同一函数时再次产生误报(检测出的污点流实际是不可能的路径)

原因:上下文不敏感 增加上下文敏感:可以区分调用点,将调用与返回相匹配(±i)

为什么不适用路径/流敏感分析
- 流敏感增加了精度,并且路径敏感增加了增加了更多精度
- 但这两点都会使得求解更加困难
- 流敏感还会增加约束图中的节点数
- 路径敏感需要更通用的求解程序来处理路径条件,还可能出现路径爆炸的问题
- 简而言之:精确度(通常)会降低可扩展性,限制了可以分析的程序规模
符号执行技术
用测试和代码审查找软件bug还是有遗漏
测试每次使用的是具体值值讨论一种可能执行,完整但不彻底
符号执行会分析得到让特定代码区域执行的输入,过程中使用符号值而非具体值作为输入,在目标代码处用约束求解器得到出发目标代码的具体值
断言不为真程序会终止并允许报错
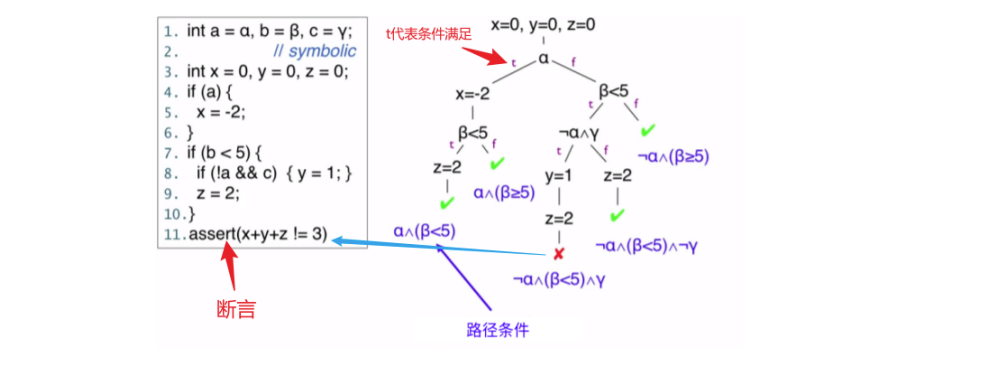
每个符号执行路径代表具体满足路径的运行集,可以覆盖更多的程序执行空间
符号执行时计算密集型,每一个分支语句都可能使指数级的路径增长
基本的符号执行
断言:真继续,假终止
**符号执行:**是一种程序分析技术,可以通过分析程序来得到让特点给代码区域执行的输入,使用符号执行分析一个程序时,该程序会使用符号值作为输入,而非一般执行程序时使用的具体值在达到目标代码时,分析器可以得到相应的路径约束,通过约束求解器来得到可以出发目标代码的具体值
**符号变量:**读取输入时引入α、β,出现bug可以恢复程序重现bug输入
符号表达式:制作修改语言解释器以能够进行符号运算
覆盖了更大的范围
线性执行:

路径条件:

路径与断言:

防止了越界访问
符号执行通用化了测试,通过静态分析生成涵盖不同程序路径的测试
Fuzzing
一种随机测试,将自动或半自动生成的随机数据输入程序中并监视程序异常,确保崩溃、异常、未终止等(安全漏洞的基础)不会发生
模糊测试分类:
-
黑盒:对程序一无所知,只能探索浅层状态
-
基于语法:可以更深入状态空间
-
白盒:至少部分根据被测试程序代码生成新输入
**模糊测试输入:**对合法输入进行转变,从头开始,组合(这块翻译不出来摆了)
渗透测试 模拟黑客的手法对网络或主机进行攻击测试,积极尝试查找可利用的漏洞来评估安全性
通常由单独小组执行,与开发人员分开,利用自己的工具搜索利用漏洞
通常会给予成员从无法访问到完全访问的各种权限
-
优点:产生真实漏洞的证据才更利于修复
-
缺点:未渗透成功不是安全的证据,系统更改就需要重新测试代价昂贵
身份认证
- 确认操作者身份,确定对某种资源的访问和使用权限
- 根据你所知道的、所拥有的、独一无二的身体特征证明
认证技术
基于主机:通常快速但粗陋
-
常用ip认证网络连接,还有mac地址、机器唯一识别码
-
客户端第一次链接时分配标识,后续连接中附上(cookies)
-
本质上消息是不可靠的客户端提供的,ip相对可靠一些(需要一定程度专业技术)
物理令牌
-
如钥匙、智能卡
-
问题在于必须为每个用户提供某种输入设备,物理令牌可能会遗失或被盗,有些易复制
生物认证:便携,但需要通过物理输入设备
生物行为是可变的,虽然唯一但不保密(砍你一根指头?)
better:活体检测-体温、血流 生物信息侵犯了隐私某种程度上
口令认证
用户名/口令始终是最流行的认证方式,用户和认证代理共享一个口令
看作物理令牌的数字模拟
深度防御:多因素认证,口令+验证码
口令存储
对口令加密,将口令存储问题转换成了口令密钥存储问题
better:保存使用口令的hash
可能攻击:彩虹表攻击,彩虹表是用于加密散列函数逆运算的预计算表,在破解时直接查文件
改进:加盐,对于每个用户的每个口令盐值不同;是指通过在口令任意固定位置插入特定的字符串,让散列后的结果和使用原始口令的散列结果不相符
加盐不是为了防止针对某个哈希值被暴力破解,而是防止彩虹表批量破解哈希值(增加了离线字典攻击 难度,几乎不可能发现一个用户在多个系统中使用相同口令)
登录失败:限制次数,失败多次锁定账户。解锁或找回密码过程会复杂一些
一次性口令
用户和服务器共享一些秘密,这些秘密用于计算一系列一次性口令
- 基于认证服务器和客户端的时间同步(通常是一个安全令牌内有精确时钟与服务器同步)
- 使用算法根据之前的密码生成新秘密
- 新密码基于挑战或计数器(服务器选择随机数)
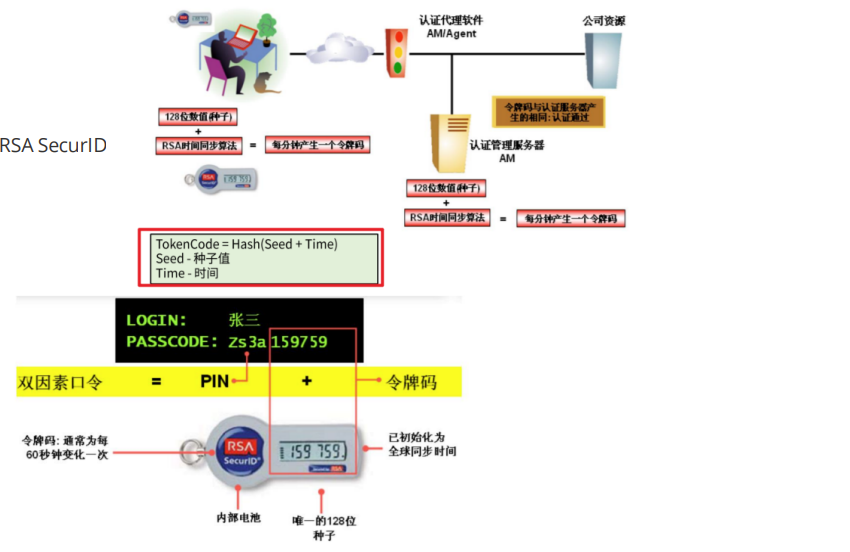
哈希链:循环的进行哈希用于认证

实用安全
-
**人机交互:**系统和用户之间的关系
-
**可用性评估:**有专家评估、用户实验、问卷访谈等
-
安全技术人员往往不关心用户需要什么,我们应当考虑用户如何与系统进行交互
-
可用安全是以人为中心设计和搭建的安全系统

回顾
- 尽可能简单
- 默认失效安全
- 某些配置或使用选择会影响系统安全性
- 加密密钥的长度
- 口令的选择
- 哪些输入被视为有效
- 默认选择安全
- 密钥长度
- 没有默认口令
- 白名单
- 某些配置或使用选择会影响系统安全性
- 不指望专家级用户
- 简单的用户界面
- 无安全决策
例子
- SSl警告:通常一方发现异常时向另一方发送警告
- 安卓权限:最小化权限、动态权限授权
- CAPTCHA:验证码,防止自动化攻击,存在基于机器学习的自动化破解
- 身份认证(从实用安全的角度)
软件保护技术
代码安全保护需要
折中可用性,防止盗版也会给用户带来麻烦(密钥、绑定机器)
折中性能,额外代码占用内存空间
软件保护方案都是趋向于打扰用户的,因此需要权衡优劣
版权保护方案
许可证密钥:(激活码、序列号)创建一个许可证密钥集合,保证随机选择的字符串是无效的存在缺陷,但会给人心理威慑
如果了解了授权机制就会失效——注册机
- 许可证密钥:激活码序列号,创建一个许可证密钥集合,保证随机选择的字符串是无效的,存在缺陷
- 注册机
- 许可证文件:根据用户的特定信息产生与用户相关的许可证
- 通常传送给用户经过数字签名处理的文件,应用程序中内嵌签名公钥进行验证
- 可以在第一次运行时创建包含安装时间的许可证以限制许可时间
- 将机器信息纳入许可证范围,可以提高破解难度
- 对于大型机构如大学往往会建立许可证服务器分发许可证以允许一定数量并发用户使用软件,通常有较 短的失效期
- 其他方案:查询手册输入指令(过时)、加密狗(一种硬件,程序运行时会检查加密狗是否存在,昂贵的 解决方案、麻烦)、远程执行(向服务器申请验证,运行在服务器上,需要一直在线)
防篡改
绝大多数的方案,依赖于使软件分析和修改困难,我们将这些防御性的方法称为防篡改
任何能够增加攻击者修改软件的难度,并且不会让软件崩溃的方法都可以归类为防篡改方法
- 例如将许可证管理程序散布在应用中
- 我们可以重复多次检查,而不是依赖于一个集中的许可证管理库
- 这些努力会增加代码的支持和维护难度
代码混淆:
数据校验
-
文件校验:安卓检查签名,开发人员签名,x.509证书
- 文件校验是指在程序启动时计算文件的校验值,然后于实现计算好的校验值进行比较,判断文件是否被篡改
- 文件校验PE
-
内存校验
- 计算可能遭受篡改的代码区块的校验和,可以通过对内存区域预先计算其校验和,然后动态的根这个值做比较
-
当检测到有人在无权限使用或者篡改软件时让程序出错或者停止?
- 不可以,这样会让攻击者知道你处理攻击代码的位置,需要把检测攻击和处理代码放的越远越好
- 不能让攻击者通过查看崩溃附近的内存,以及查看最近使用的变量追踪检测代码
-
防止滥用:
- 保留程序中的错误代码,当且仅当没有篡改异常的时候,在防篡改代码中修复或者处理这些原有的程序错误
-
防止程序被调试/动态分析
- 在调试器中逐行跟踪代码比程序正常运行耗费的时间要长很多
- 可以是使用父进程检测
- 系统痕迹检测的方法
-
软甲加壳
- 加壳就是使用专门的工具或者方法,在应用程序中加入一段如同保护层的代码,使原程序代码失去本来的面目,从而防止程序被非法修改和编译
- 用户在执行被加壳的程序时,实际先执行"外壳"程序,然后外壳把源程序在内存中解开
-
软件脱壳:
- 硬脱壳:执行解密算法
- 动态脱壳:执行过程中从内存中导出
代码混淆
- 是将计算机程序的代码转换成功能等价但难于阅读和理解的形式的行为
- 难以维护
- 独特的数据编码
- 程序控制流
- 效能:破解困难
- 抗逆:对于自动化去混淆工具的抵抗
- cost:内存、时间、空间
随机数生成
- 怎样有效的使用伪随机数
- 熵
- 现实世界使用的伪随机数系统
什么是随机数
- 数字序列在统计上是随机的
- 不能通过已知序列推算后面的序列
伪随机数发生器
-
计算机不能产生真正的随机数
-
伪随机数下一个的值完全取决于它前一个值
-
种子
熵
-
对一个数据随机性的度量
-
用一个随机熵做伪随机数的种子
-
深度防御
加密型PRNG
- 给予足够的熵
- 不能通过给定的随机序列的一部分在大于0.5的概率推算出该序列的其他部分
统计型PRNG
- 对任意统计测试产生一个看似随机的数据序列
- 并不是结果不可预测
实例:
- 线性同余生成器,但在高,在高性能pc机下能够实现暴力破解。
- 种子位数越多越难破解,但本质上每个输出都会泄露状态
- PRNG种子通常参照系统时钟生产,意味着算出生成器发生时间就能预测所有
- 即使种子是完全真正的随机数也不是安全的,attacker同样能够通过观察做出预测
- 防御密码分析攻击&防御内部状态的攻击
PRNG统计测试
- 高质量PRNG的输出和真随机数应该是不可区分的
对于PRNG,真随机数作为种子是否安全
- 并不是,因为攻击者不知道生成器采用哪个数字作为种子,他仍然可以观察你的程序和做一些猜测来预测处PRNG生成的数字
- PRNG输出和真随机数是不可区分的
熵的收集与处理
- 硬件设备
现实
- /dev/random适于质量要求改,熵池不足会阻塞
- /dev/urandom非阻塞,会重复利用熵池,输出熵会小于前者
密码技术应用
一般性建议
- 绝不创建自己的密码技术
- 安全要基于算法和密钥的安全强度上,不靠隐蔽内部细节
- 避免设计自己的协议(比设计可靠密码算法更难)
- 绝不重复使用相同密钥(尤其是流密码)
- 加密技术无法保证数据完整性(数据变垃圾),要用MAC检查消息完整性
常见密码技术误用
- PRNG弱随机数种子
- 一些算法已证明不安全(DES等)
- 短密钥易被暴力穷举(RSA建议2048bit)
- ECB模式的缺陷(可识别明文问题)
- CBC模式的弱IV值(不够随机),同时CBC一比特密文的确实会导致重新分组无法解密
- 硬编码的密钥(密钥直接嵌入程序中)
- PEB算法:基于口令的加密,根据口令生成密钥再用密钥进行加密。
- 用盐(抵御彩虹表)和口令组成再 哈希的密钥加密加密消息的密钥
- 可以进行多次哈希提高安全性
一次一密
完美的加密算法,随机生成和消息一样长的密钥,与明文加密。但实际上很少用:安全分发密钥的困难,与消息等长密钥的开销
一次一密几乎没有实用性,但衍生出了流密码使用伪随机数生成器



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









