







1.人工智能、机器学习与深度学习的关系
人工智能的目的是制造像人一样的智能机器或智能系统,其中的一种方式是机器学习,机器学习是一种利用已有的经验自我改进的方法,而深度学习是特指一类使用深度神经网络进行机器学习的方法。
2.机器学习的三个步骤
- 根据问题选择模型
- 寻找合适的损失函数(目标函数)评估模型
- 选择优化算法使用数据训练模型
3.解释过拟合与欠拟合
过拟合:模型对于训练数据拟合呈过当,评估指标上表现为模型在训练集上的表现非常好,但在测试集和新数据上的表现较差。可能的原因是模型过于复杂或者迭代次数过多,把噪声数据的特征也学习到模型中,导致模型泛化能力下降。
欠拟合指的是模型没有很好地捕捉到数据的特征,不能够很好地拟合数据,评估指标上表现为在训练和预测时表现都不好的情况。可能的原因包括训练集数据不足,训练次数不足,选择的特征不恰当。
4. 解释方差和偏差的概念
偏差指的是由所有采样得到的大小为m的训练数据集训练出的所有模型的输出的平均值和真实模型 输出之间的偏差。偏差通常是由于我们对学习算法做了错误的假设所导致的,比如真实模型是某个二次 函数,但我们假设模型是一次函数。由偏差带来的误差通常在训练误差上就能体现出来。表现为欠拟合
方差指的是由所有采样得到的大小为m的训练数据集训练出的所有模型的输出的方差。方差通常是 由于模型的复杂度相对于训练样本数m过高导致的,比如一共有100个训练样本,而我们假设模型是阶 数不大于200的多项式函数。由方差带来的误差通常体现在测试误差相对于训练误差的增量上。表现为过拟合
bias:偏差;variance:方差 -> 实际上对应着物理实验中系统误差和随机误差的概念
5. 正则化的概念和目的
概念:向损失函数中加入描述模型复杂程度的正则项,正则项通常包括对光滑度及向量空间内范数上界 的限制。
目的:1. 获得比较平滑的function,由于输出对输入是不敏感的,测试的时候,一些噪声对平滑的 function的影响就会比较小,因而给我们一个比较好的结果。 2.控制曲线的参数和形状,使之不会出现过拟合的现象。 平滑:输入有变化的时候,输出对输入的变化是比较不敏感的。
6.简述几种降低过拟合和欠拟合风险的方法
- 降低过拟合风险的方法
- 增加训练数据,直接增加原始数据或者进行数据扩展,如图像分类中对图像进行平移、旋转、缩放等,更进一步可以使用生成对抗网络。
- 降低模型复杂度,避免拟合过多的采样噪声。
- 正则化,为模型参数加上一定的正则约束
- 集成学习,将多模型集成在以及降低单一模型过拟合风险
- 降低欠拟合风险的方法
- 添加新特征。当特征不足或者现有特征与样本标签的相关性不强时,模型容易出现欠拟合。通过挖掘“上下文特征”“ID类特征”“组合特征”等新的特征,往 往能够取得更好的效果。在深度学习潮流中,有很多模型可以帮助完成特征工 程,如因子分解机、梯度提升决策树、Deep-crossing等都可以成为丰富特征的方 法。
- 增加模型复杂度,简单模型的学习能力较差,复杂模型具有更好的拟合能力
- 减小正则化系数。正则化是用来防止过拟合的,但当模型出现欠拟合现 象时,则需要有针对性地减小正则化系数。
7.简述梯度下降的过程
初始化梯度集合,根据优化算法迭代更新梯度,寻找使得损失函数最小的梯度集合。
18.冲量(momentum)方法做了什么以及解决了什么问题
冲量法为参数更新中添加惯性,使得梯度下降的方向不仅依赖于当前的梯度值,还取决于之前的梯度,并通过指数加权平均的方法逐渐遗忘历史数据。
解决训练卡在局部最小值/鞍点/plateau(critical point)的问题,使得收敛速度更快,收敛曲线也更稳定。
橙色为原始梯度,绿色为修正后的梯度,横向变得很快,纵向振幅减少。
类比于下山越来越快,左右冲量逐渐抵消。

8. Adagrad方法解决了什么问题,如何做的?
解决了学习率自适应变化的问题,对任一维度的梯度,随着该维度上梯度变化的积累,学习率逐渐降低。
W
t
=
W
t
−
1
−
λ
S
t
+
σ
∗
Δ
W
t
W_t = W_{t-1} - \frac{\lambda }{\sqrt{S_t}+\sigma}*\Delta W_t
Wt=Wt−1−St+σλ∗ΔWt
S
t
=
S
t
−
1
+
Δ
W
t
2
S_t=S_{t-1}+\Delta W_t^2
St=St−1+ΔWt2
对学习率进行修正,历史修改越多S越大,则学习率越低。adagrad在稀疏数据上效果很好,稀疏数据指数据点之间不同维度的差异大于相同维度上的差异,特征越多的数据集越容易出现稀疏数据。
9.随机梯度下降解决了什么问题,如何做的?
解决梯度下降问题中计算次数太多的问题(需要对数据集的结果取均值),每次选取一个数据点对模型参数进行更新。
V
t
=
β
∗
V
t
−
1
+
(
1
−
β
)
∗
Δ
W
t
V_t=\beta*V_{t-1} +(1-\beta)*\Delta W_{t}
Vt=β∗Vt−1+(1−β)∗ΔWt
W
t
=
W
t
−
1
−
λ
V
t
W_t = W_{t-1}-\lambda V_t
Wt=Wt−1−λVt
实际应用中随机梯度下降实际是批量随机梯度下降,SGD是批大小为1的特例,batch取值太大时容易陷入局部极值
随机梯度下降法对于凸问题的误差是根号K分之一,对于强凸问题的误差为K分之一
补充:adam
ada=adagrad+冲量法
梯度变化的积累计算时采用指数加权平均,遗忘历史数据。
10. 简述机器学习任务中,回归和分类任务的区别
- 输出不同 回归输出类型是连续数据,回归问题输出的是物体的值,输出的值是定量的。 分类输出类型是离散数据,输出的是物体所属的类别,输出的值是定性的。
- 目的不同 分类的目的是为了寻找决策边界,即分类算法得到是一个决策面,用于对数据集中的数据进行分类。 回归的目的是为了寻找最优拟合,通过回归算法得到是一个最优拟合线,这个线条可以最好的接近数据 集中的各个点。
- 评价方式不同,分类使用精度、混淆矩阵等,回归问题使用均方误差等。
在一定条件下,两者可以进行转换。
11.分类和回归任务的模型输出区别
分类任务给出的是定性输出,是一个离散值。
回归任务给出的是定量输出,是一个连续值。
12.简述判别模型和生成模型各自的做法以及两种方法的区别
判别模型直接对后验概率P(c|x)进行建模,生成模型先对联合分布建模再获取模型之上生成的后验概率P(c|x)
判别模型根据数据集使用梯度下降和交叉熵函数训练出模型参数
生成模型首先对样本分布进行假设,利用最大似然估计法计算最有的高维分布参数,进而求出模型参数
判别模型当训练数据量充足时,判别模型的准确率更高。
生成模型需要更少的数据,对噪音的抵抗能力更强;
判别模型:决策树 BP神经网络 SVM
生成模型:贝叶斯分类器
13.逻辑斯蒂回归中,若使用平方误差(square error)作为损失函数的表示,可行吗?
不可行。 如果是cross entropy的话,距离目标越远,梯度就越大,参数更新的时候变化量就越大,迈出去的步伐也就越大。 平方误差计算得到的梯度即使距离目标远的时候,也是非常小的,参数更新的速度非常慢的。实际操作的时候,当梯度接近于0的时候,其实就很有可能 会停下来,因此使用square error很有可能在一开始的时候就卡住不动了,而且这里也不能随意地增大 learning rate,因为在做gradient descent的时候,gradient接近于0,有可能离target很近也有可能很远,因此不知道learning rate应该设大还是设小。 综上,尽管square error可以使用,但是会出现update十分缓慢的现象,而使用cross entropy可以让训练更快。
交叉熵更新梯度
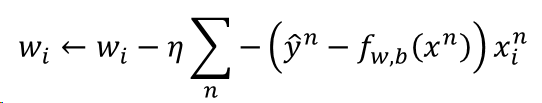
平方差更新梯度
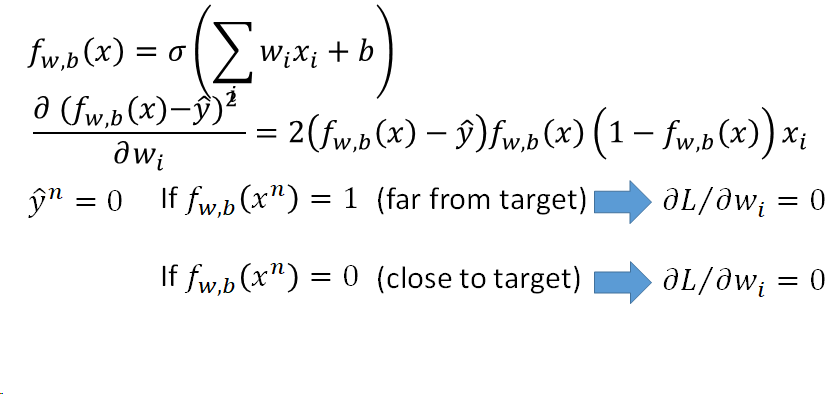
14.简述深度学习训练时,反向传播都做了什么
反向传播根据链式法则快速计算出各个参数的偏导数进行梯度更新。
15.简述CNN的卷积层和池化层,各自的实现了什么特性,以及做了什么
卷积层实现了参数共享、稀疏连接的特性。利用卷积核与上层运算建立连接。
池化层实现下采样,降低特征的维度。对一定的区域进行求均值或保留极值等操作。
16.CNN中,卷积操作的本质特性包括稀疏交互和参数共享,具体解释这两种特性及其作用
参数共享是指在同一个模型的不同模块中使用相同的参数,它是卷积运算的固有属性。全连接网络 中,计算每层的输出时,权值参数矩阵中的每个元素只作用于某个输入元素一次;而在卷积神经网络 中,卷积核中的每一个元素将作用于每一次局部输入的特定位置上。根据参数共享的思想,我们只需要学习一组参数集合,而不需要针对每个位置的每个参数都进行优化,从而大大降低了模型的存储需求。参数共享的物理意义是使得卷积层具有平移等变性。
系数交互:在卷积神经网络中,卷积核尺度远小于输入的维度,这样每个输出神经元仅与前一层特定局部区 域内的神经元存在连接权重(即产生交互),我们称这种特性为稀疏交互
稀疏交互的物理意义是,通常图像、文本、语音等现实世界中的数据都具有局部的特征结构,我们 可以先学习局部的特征,再将局部的特征组合起来形成更复杂和抽象的特征。
17.梯度消失产生的原因以及如何解决
原因:对于靠近input层的参数 , 在通过Sigmoid函数时会被压缩到一个更小的范围。 Δ W \Delta W ΔW 的影响随 着层数加深而衰减,导致 Δ W \Delta W ΔW对Loss的影响减小。因此,靠近input的对Loss的梯度 远小于靠近 output的 的梯度。因此,靠近input层的参数更新较慢,靠近output层的参数更新较快。当靠近input 层的参数还是随机的时候,靠近output层的参数已经收敛了。这样,靠近input层的参数没有得到有效的 训练。
解决方法:前馈神经网络中使用ReLU激活函数,取得更快的收敛速度和更好的收敛结果。
长短时记忆模型及其变种门控循环单元(Gated recurrent unit,GRU)等模型通过加入门控机制,很大程度上弥补了梯度消失所带来的损失
深度残差网络是对前馈神经网络的改进,通过残差学习的方式缓解了梯度 消失的现象,从而使得我们能够学习到更深层的网络表示;
ReLU就是线性整流单元,是神经网络中常用的激活函数。如max(0,wx+b)
当采用ReLU作为循环神经网络中隐含层的激活函数时,只有当W 的取值在单位矩阵附近时才能取得比较好的效果,因此需要将W初始化为单位矩 阵。实验证明,初始化W为单位矩阵并使用ReLU激活函数在一些应用中取得了与 长短期记忆模型相似的结果,并且学习速度比长短期记忆模型更快,是一个值得 尝试的小技巧[25]
19.dropout方法做了什么以及解决了什么问题
训练阶段中对于神经元的激活值由p的概率丢弃不使用;测试阶段中不对数据丢弃,每个神经元的权重乘以(1-p)
解决了减弱全体神经元之间的联合适应性, 减少过拟合的风险,增强泛化能力的问题。
本质上将N神经元的网络拓展成了,2^N个模型的集合,这些集合共享部分权值和相同的网络层数,而模型的参数数目不变,大大简化运算,每次训练都挑选不同的神经元共同优化。
20.L1&L2 正则化
正则化是指为损失函数添加正则项进行修正,正则项包含了光滑度及向量空间内范数上界的限制,以得到一个更光滑的模型。
L1正则化
∣ ∣ θ ∣ ∣ 1 = ∣ w 1 ∣ + ∣ w 2 ∣ + . . . L ′ ( θ ) = L ( θ ) + λ ∣ ∣ θ ∣ ∣ 1 w t + 1 = w t − η ϕ L ′ ϕ w = w t − η ϕ L ϕ w − η λ Σ w t ||\theta||_1 = |w_1|+|w_2|+...\\L'(\theta) = L(\theta)+\lambda||\theta||_1\\w^{t+1}=w^t-\eta\frac{\phi L'}{\phi w}=w^t-\eta\frac{\phi L}{\phi w}-\eta\lambda \Sigma w^t ∣∣θ∣∣1=∣w1∣+∣w2∣+...L′(θ)=L(θ)+λ∣∣θ∣∣1wt+1=wt−ηϕwϕL′=wt−ηϕwϕL−ηλΣwt
L2正则化
∣ ∣ θ ∣ ∣ 2 = ( w 1 ) 2 + ( w 2 ) 2 + . . . L ′ ( θ ) = L ( θ ) + 1 2 λ ∣ ∣ θ ∣ ∣ 2 w t + 1 = w t − η ϕ L ′ ϕ w = ( 1 − η ) w t − η ϕ L ϕ w ||\theta||_2 = (w_1)^2+(w_2)^2+...\\L'(\theta) = L(\theta)+\frac{1}{2}\lambda||\theta||_2\\w^{t+1}=w^t-\eta\frac{\phi L'}{\phi w}=(1-\eta)w^t-\eta\frac{\phi L}{\phi w} ∣∣θ∣∣2=(w1)2+(w2)2+...L′(θ)=L(θ)+21λ∣∣θ∣∣2wt+1=wt−ηϕwϕL′=(1−η)wt−ηϕwϕL
作用 :
- L1正则常被用来进行特征选择,主要原因在于L1正则化会使得较多的参数为0,从而产生稀疏矩阵,我们可以将0对应的特征遗弃,进而用来选择特征。一定程度上L1正则也可以防止模型过拟合。
- L2正则主要用来防止模型过拟合,直观上理解就是L2正则化是对于大数值的权重向量进行严厉惩罚。 鼓励参数是较小值,如果 小于1,那么 会更小。
21.相比CNN与传统DNN,RNN是为了解决什么问题?如何解决的?(P240)
RNN是用来建模序列化数据的一种主流深度学习模型,解决了传统前馈神经网络无法处理变长的序列信息的问题(即使通过一些方法把序列处理成定长的向量,模型也很难捕捉序列中的长距离依赖关系)。
RNN则通过将神经元串行起来处理序列化的数据。每个神经元能用它的内部变量保存之前输入的序列信息,得到序列的抽象表示,并可以据此进行分类或生成新的序列。
RNN牺牲了参数数目,使模型变得更复杂。
效果:循环神经网络却能很好地处理文本数据变长并且有序的输入序列。它模拟了人阅读一篇文章的顺序,从前到后阅读文章中的每一个单词,将前面阅读到的有用信息编码到状态变量中去,从而拥有了一 定的记忆能力,可以更好地理解之后的文本。
23.RNN训练中为什么会出现梯度爆炸现象(P242)
直观理解:参数在不同的时间点被反复使用,参数的变化有时候可能对RNN的 输出没有影响,而一旦产生影响,经过长时间的不断累积,该影响就会被放得无限大
数学解释:由于预测的误差是沿着神经网络的每一层反向传播的,因此当雅克比矩阵 ϕ n e t t ϕ n e t t − 1 \frac{\phi net_t}{\phi net_{t-1}} ϕnett−1ϕnett的最大特征值大于1时,随着离输出越来越远,每层的梯度大小会呈指数增长,导致梯度爆炸;
解决方法:通过梯度裁剪来缓解,即当梯度的范式大于某个给定值时,对梯度进行等比收缩。
22.长短时记忆网络LSTM四个主要的模块及其各自作用
- C t C_t Ct当前时刻的内部记忆单元,保存着经过处理后当前时刻及此前时刻有多少信息被保存着。
- f t f_t ft遗忘门,控制前一时刻记忆单元中的信息有多少比例会被过滤掉。
- i t i_t it输入门,控制着当前时刻的新状态有多少比例更新到内部记忆单元中。
- o t o_t ot输出门,控制着当前时刻的输出有多少比例来源于当前的内部记忆单元


24.半监督学习中的生成模型方法和监督学习中的有何异同?
异:
-
半监督学习中,除了已知的数据,还用概率预估未标签数据的标签(软标签)。
-
监督学习中生成的模型是一次计算出的,但是半监督学习的模型是在循环迭代中不断调整的。
同:都是假设数据满足某一分布,并试图还原分布。
25.Hard label / Soft label 区别
Hard label强行把未标签数据归为某一类,是非黑即白的,要么是要么不是。
Soft label是一个带有分数(概率)的标签,代表某元素归于某一类的可能性。这意味着一个元素可以是 多个类的成员。
在神经网络训练中,要采用Hard label,Soft label是不起作用的。
26.简述聚类中的k-means方法
k-means是一种将数据划分到K个聚类的无监督学习方法,过程如下:
- 首先随机抽取K个样本点 x n x^n xn初始化为聚类中心 c i c_i ci
- 重复一下操作,直到达到最大迭代次数:
- 遍历所有样本点,计算其到所有聚类中心的距离,该样本的归类为最近的聚类
- 更新聚类中心为每个聚类所有样本的平均值
- 确定最优的聚类中心
27.简述PCA方法以及其实现的最主要目标
目标:PAC即主程序分析,是一种降维方法,用较少的互不相关的新变量来反映原变量所表示的大部分信息,有效解决维度灾难问题。
方法:假设有n条d维数据需要降低到k维
- 将原始数据按照列排布成n*d的矩阵,进行零均值化
- 计算协方差矩阵 C = 1 m X ∗ X T C=\frac{1}{m}X*X^T C=m1X∗XT
- 求出协方差矩阵的特征值和对于的特征向量
- 将特征向量按照特征值大小从上到下排列成矩阵去前k行组成矩阵P
- 计算Y=PX
28.异常检测主要做了什么
给定训练数据 { x 1 , x 2 , . . . . } \{x_1,x_2,....\} {x1,x2,....},判断输入x是否与训练数据相近,如果相近判断为正常否则为异常数据,可以对异常数据进行删除或修正。
29.什么是灾难性遗忘?为了解决灾难性遗忘问题,我们可以怎样做?
灾难性遗忘是指在一个顺序无标注的、可能随机切换的、同种任务可能长时间不复现的任务序列中,AI对当前任务B进行学习时,对先前任务A的知识会突然地丢失的现象。
减灾方法:选择突出可塑性,只改变对于先前学习任务不重要的参数。假设 θ ′ \theta' θ′为之前学习到的参数,令新的损失函数 L ( θ ′ ) = L ( θ ) + λ Σ b i ( θ i − θ i ′ ) 2 L(\theta')=L(\theta)+\lambda \Sigma b_i(\theta^i - \theta_i')^2 L(θ′)=L(θ)+λΣbi(θi−θi′)2,其中 b i b_i bi为参数的重要性。
30.简述元学习和机器学习的异同
相同:元学习和机器学习都是通过给出的数据进行学习得到一个模型
不同:元学习学习的是一个学习算法,即如何学习机器学习,而机器学习学习到是具体问题的答案
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









