







1.1 回顾V1和V2
V1:05_YouOnlyLookOnce(YOLOV1)目标检测领域的革命性突破-CSDN博客
V2:07_YouOnlyLookOnce(YOLOv2)Better,Faster,Stronger-CSDN博客
1.2 简介
YOLOv3(You Only Look Once version 3)是YOLO系列目标检测算法的第三代版本,由Joseph Redmon等人在2018年推出。YOLO系列因其快速且准确的目标检测能力而广受欢迎,尤其适合需要实时处理的应用场景。YOLOv3在继承前代优势的基础上,通过一系列关键改进,进一步提升了检测精度和运行速度,实现了对各类尺度目标的有效检测。
-
Darknet-53作为骨干网络:YOLOv3采用了一个新的特征提取网络——Darknet-53,这个网络包含53个卷积层,每个卷积层后通常跟随批量归一化层(Batch Normalization)和Leaky ReLU激活函数,以加速训练并提高模型的非线性表达能力。Darknet-53没有池化层,而是利用步长为2的卷积层来下采样特征图,这有助于保持更多的空间信息。
-
特征金字塔网络(Feature Pyramid Networks, FPN):YOLOv3引入了FPN机制,能够在不同尺度上进行特征检测。它在Darknet-53的输出上添加了几个额外的卷积层,形成了三个不同尺度的特征图(13x13, 26x26, 52x52),每个尺度对应不同的对象尺寸,从而提高了对小目标的检测能力。这种设计允许模型在不同层级捕获多种尺度的信息,增强了模型的泛化能力和准确性。
-
多尺度预测:与YOLOv2相比,YOLOv3在每个特征图的每个网格上预测3个边界框,每个边界框包含位置信息、对象类别概率以及一个置信度分数,表明该框内存在对象的概率。这种多尺度和多框的策略有助于模型更灵活地适应不同大小和形状的对象。
-
优化的损失函数:YOLOv3采用了更加精细化的损失函数,既考虑了分类损失,也考虑了定位损失,同时对小对象的检测给予了更高的权重,以解决小对象检测难题。
-
实时性:尽管YOLOv3在精度上有了显著提升,但它仍然保持了较快的推理速度,使得它在诸如自动驾驶、视频监控和无人机导航等需要即时响应的场景中非常实用。
1.3 V3的性能
-
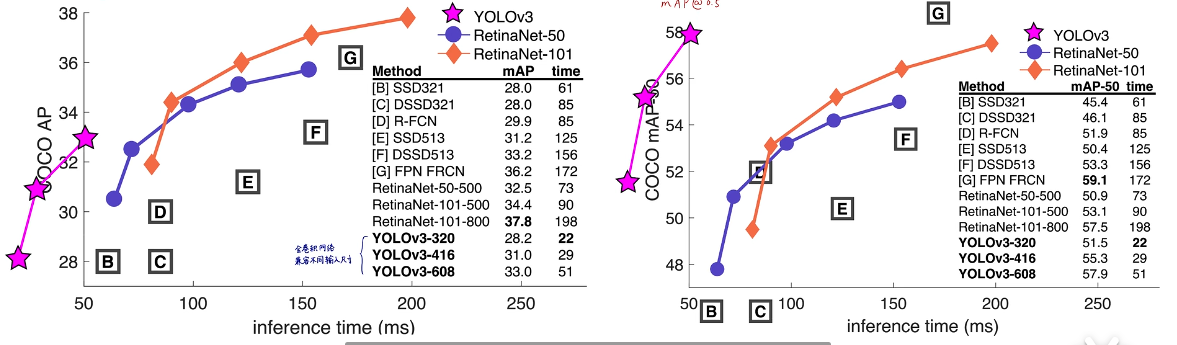
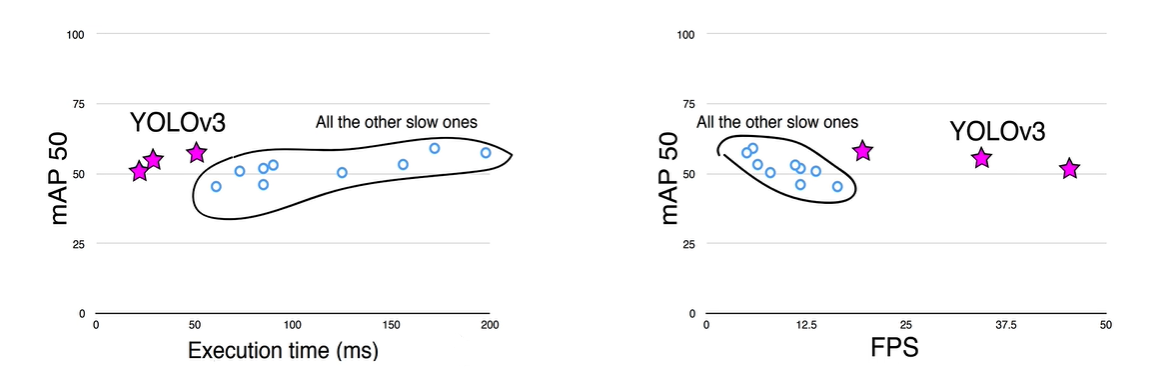
高精度与实时性平衡:YOLOv3在精确度和速度之间实现了良好的平衡。它在保持快速检测速度的同时,显著提高了检测精度。例如,在Titan X GPU上,YOLOv3能在大约51毫秒(ms)内完成一张图像的检测,达到57.9%的平均精度均值(AP50),这意味着它的检测速度非常快,同时具有较高的检测准确性。
-
多尺度检测能力:通过在不同尺度的特征图上进行预测,YOLOv3能有效检测从小到大的各种尺寸的目标。它的设计使得模型能够在多个分辨率级别上捕捉对象特征,这对于检测复杂场景中的多样化目标尤为重要。
-
改进的损失函数与正负样本匹配:YOLOv3采用了优化的损失函数,能够更好地处理分类和定位任务,同时,它采用基于聚类的方法来生成先验框,这有助于模型更好地适应不同目标的尺度和宽高比,提高了模型的稳定性和精度。
-
增强的特征提取网络:Darknet-53作为YOLOv3的骨干网络,提供了强大的特征提取能力。该网络结构的高效性使得模型可以在保持较高检测速度的同时,提升对目标特征的学习能力。
-
计算效率:相比其他先进的目标检测模型如SSD和RetinaNet,YOLOv3在某些配置下能够提供更快的检测速度。例如,它被报道在某些基准测试中,其运行速度可以达到SSD和RetinaNet的大约3.8倍,这对于资源受限或对延迟有严格要求的应用场景尤为重要。
-
适应多标签任务:YOLOv3通过改进的Softmax层设计,能够更好地处理一个网格内存在多个对象的情况,提高了模型在复杂场景下的表现。
1.4 DarkNet53
Darknet53特性概览
-
残差结构:Darknet53的一个关键特点是大量采用了残差学习(Residual Learning)的思想,即残差块(Residual Block)。每个残差块通常包含两个卷积层:一个3x3卷积层紧跟着一个1x1卷积层,中间穿插Batch Normalization(BN)和激活函数(通常是Leaky ReLU)。这些残差块通过快捷连接(skip connection)将输入直接加到经过若干卷积操作后的特征上,帮助解决深度网络中的梯度消失问题,使得模型能够更轻松地训练更深的网络。
-
下采样策略:与传统的池化层用于下采样不同,Darknet53主要使用步长为2的3x3卷积来进行特征图的下采样,这有助于减少信息损失,同时增加网络的深度。
-
网络深度:Darknet53相较于其前身Darknet19,深度大大增加至53层,这样的设计旨在进一步提升模型的特征表达能力。
-
卷积模块:网络中广泛使用了一种称为
DarknetConv2D的定制化卷积模块,该模块在每次卷积操作后都会进行L2正则化、批量归一化(BatchNorm)以及Leaky ReLU激活,这样的设计有利于训练稳定性和加速收敛。
网络结构
- 基础块:网络由一系列的卷积层堆叠而成,其中包含多个残差块。每个残差块通常由两组卷积层组成,先是一个较小的3x3卷积层(步长可能为2以进行下采样),接着是一个1x1卷积层用于调整通道数,所有这些之后都伴随有BN和激活函数。
- 层级特征:随着网络的深入,特征图的尺寸减小,但通道数增加,这种设计允许模型在不同尺度上捕获特征,这对于检测不同大小的目标至关重要。
- 输出层:最终,Darknet53产生多个不同尺度的特征图,这些特征图随后被用于构建特征金字塔,并在此基础上进行分类和边界框回归。
性能影响
Darknet53的设计使得YOLOv3不仅能够快速提取图像特征,还显著提高了检测精度,尤其是在处理小目标和多尺度目标时。它的深度和残差结构有助于学习更复杂的特征表示,而不会遭受严重的梯度消失或爆炸问题,从而提升了整个YOLOv3系统的性能。


1.5 V3的网络架构
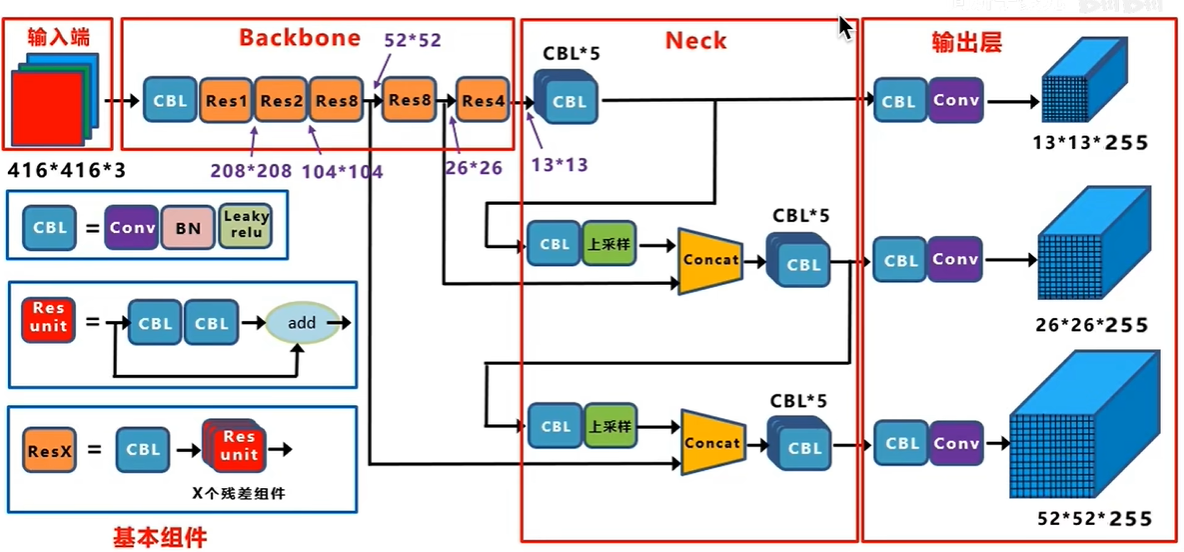
YOLOv3(You Only Look Once version 3)的网络架构设计精巧,旨在实现高速与高精度目标检测的平衡。以下是YOLOv3网络架构的关键组成部分和工作流程:
1. 输入层
- 输入图像:YOLOv3通常接受固定尺寸的输入图像,如416x416像素,这是为了方便网络结构中的下采样操作。
2. Darknet-53作为骨干网络
- 基础特征提取:首先,图像通过Darknet-53网络进行处理。Darknet-53包含53层,主要由卷积层构成,使用大量的残差块(Residual Blocks)来加深网络,每个残差块包括两个3x3卷积层(其中一个可进行下采样),并使用批量归一化(Batch Normalization)和Leaky ReLU激活函数。
3. 特征金字塔网络(Feature Pyramid Network, FPN)
- 多层次特征提取:Darknet-53的输出通过一系列上采样和特征融合操作形成特征金字塔。具体来说,网络在最后几个卷积层后,通过上采样操作(如最近邻插值或双线性插值)将低分辨率特征图与之前较高分辨率的特征图融合,形成了三个不同尺度的特征图(一般为52x52、26x26、13x13),分别对应于检测不同大小的目标。
4. 检测层(YOLO Layers)
-
多尺度预测:在每个尺度的特征图上,YOLOv3应用一个卷积层来预测该尺度上的目标信息。每个网格预测3个边界框(anchor boxes),每个边界框含有5个坐标参数(x, y, w, h, confidence score)以及C个条件类别概率(每个类别一个概率)。其中,(x, y)是边界框中心相对于网格单元的偏移,(w, h)是边界框的宽度和高度的预归一化值,confidence score表示边界框内存在物体的概率,以及框的精确度。
5. 输出层
- 输出格式:最终,YOLOv3输出是三个尺度的特征图,每个特征图上的每个网格预测出B个边界框,每个边界框关联C个类别概率,因此输出维度为(S1S1B*(5+C), S2S2B*(5+C), S3S3B*(5+C)),其中Si是每个特征图的大小。
6. 损失函数
- 优化目标:YOLOv3使用多部分损失函数,包括边界框的位置误差、对象存在的置信度误差、以及分类误差,通过优化这个复合损失来同时训练位置、置信度和类别预测。
255是怎么来的?85x3,就是每个grid cell生成3个anchor box,每一个anchor对应一个预测框,每一个预测框有5+80,5是XYWHC(中心点坐标,预测框长宽,置信度),80是coco数据集80个类别的条件类别概率。
13x13(416下采样32倍,每个 gridcell对应原图的感受野是32x32,负责预测大物体),26x26(下采样16倍,负责预测中等大小物体),52x52(下采样8倍,预测小物体)都是gridcell个数,每个girdcell对应3个anchor。

1.6 损失函数



后记
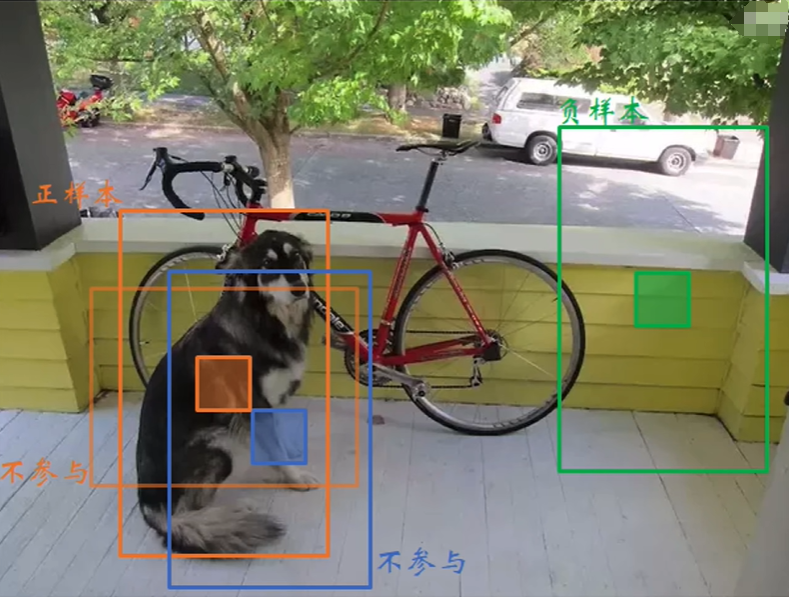
对于正负样本,V1V2中置信度标签为IOU,V3变成2分类(1或者0)
正样本:与GT IOU最大的那个Anchor
负样本:Iou<0.5的anchor
忽略:IoU>0.5 但不是最大的anchor
V3中每个GT仅分配一个anchor负责预测,对不负责预测GT的anchor不计算其定位和分类损失函数,仅计算置信度损失函数(标签为0).只有正样本时分类和定位学习产生贡献,负样本只对置信度学习产生贡献。


2.pytorch复现
# Author:SiZhen
# Create: 2024/6/15
# Description:外接摄像头捕捉实时目标检测
# 参考视频https://www.bilibili.com/video/BV1Vg411V7bJ/?spm_id_from=333.999.0.0
import cv2
import numpy as np
import matplotlib.pyplot as plt
#定义可视化图像函数
def look_img(img):
#opencv读入图像格式为BGR,matplotlib可视化格式为RGB,需要转化
img_RGB = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
plt.imshow(img_RGB)
plt.show()
#导入与训练YOLOV3模型
net = cv2.dnn.readNet('yolov3.weights','yolov3.cfg')
#获取三个尺度输出层的名称
layersNames = net.getLayerNames()
output_layers_names = [layersNames[i[0]-1]for i in net.getUnconnectedOutLayers()]
with open('coco.names','r')as f:
classes = f.read().splitlines()
CONF_THRES = 0.2 #指定置信度阈值,阈值越大,置信度过滤越强
NMS_THRES = 0.4 #指定NMS阈值,阈值越小,NMS越强
#处理帧函数
def process_frame(img):
#获取图像宽高
height,width,_ =img.shape
blob = cv2.dnn.blobFromImage(img,1/255,(416,416),(0,0,0),swapRB=True,crop=False)
net.setInput(blob)
#前向推断
prediction = net.forward(output_layers_names)
#从三个尺度输出结果中解析所有预测框信息
boxes = []#存放预测框坐标
objectness = []#存放置信度
class_probs = [] #存放类别概率
class_ids = [] #存放预测框类别索引号
class_names = [] #存放预测框类别名称
for scale in prediction : #遍历三种尺度
for bbox in scale: #遍历每个预测框
obj = bbox[4] #获取该预测框的confidence(objecness)
class_scores = bbox[5:] #获取该预测框在coco数据集80哥类别的概率
class_id = np.argmax(class_scores) # 获取概率最高类别的索引号
class_name = classes[class_id] # 获取概率最高类别的名称
class_prob = class_scores[class_id] # 获取概率最高类别的概率
# 获取预测框中心点坐标,预测框宽高
center_x = int(bbox[0] * width)
center_y = int(bbox[1] * height)
w = int(bbox[2] * width)
h = int(bbox[3] * height)
# 计算预测左上角坐标
x = int(center_x - w / 2)
y = int(center_y - h / 2)
# 将每个预测框的结果存放至上面的列表中
boxes.append([x, y, w, h])
objectness.append(float(obj))
class_ids.append(class_id)
class_names.append(class_name)
class_probs.append(class_prob)
#将预测框置信度objectness与各类别置信度class_pred相乘,获得最终该预测框的置信度confidence
confidences = np.array(class_probs) *np.array(objectness)
#置信度过滤,非极大值抑制NMS
indexes = cv2.dnn.NMSBoxes(boxes, confidences, CONF_THRES, NMS_THRES)
indexes = np.array(indexes)
colors = np.random.uniform(0, 255, size=(len(boxes), 3))
for i in indexes.flatten():
#获取坐标
x, y, w, h = boxes[i]
# 获取置信度
confidence = str(round(confidences[i], 2))
# 获取颜色,画框
color = colors[i % len(colors)]
cv2.rectangle(img, (x, y), (x + w, y + h), color, 8)
# 写类别名称和置信度
# 图片,添加的文字,左上角坐标,字体,字体大小,颜色,字体粗细
string = '{} {}'.format(class_names[i], confidence)
cv2.putText(img, string, (x, y + 20), cv2.FONT_HERSHEY_COMPLEX, 1, (255, 255, 255), 2)
return img
import time
#获取摄像头,0表示获取系统默认摄像头,1为外接摄像头
cap = cv2.VideoCapture(1)
cap.open(1) #打开摄像头
#无限循环直到break被触发
while cap.isOpened():
#获取画面
success,frame = cap.read()
if not success:
print("Error")
break
strat_time = time.time()
#处理帧函数
frame = process_frame(frame)
#展示处理后的三通道图像
cv2.imshow('my_window',frame)
if cv2.waitKey(1) in [ord('q'),27]: #按键盘上的q或esc退出
break
#关闭摄像头
cap.release()
#关闭图像窗口
cv2.destroyAllWindows()















 974
974











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









