






Abstract
针对摘要,首先下学习了几个名词
1.Temporal Ensembling

训练过程的每一个epoch中,同一个无标签样本前向传播(forward)两次,通过 data augmentation和 dropout注入扰动(或者说随机性、噪声),同一样本的两次forward会得到不同的 predictions。然后计算这两个predictions的平方误差,n-Model希望这两个predictions 尽可能一致,即模型对扰动鲁棒。对于有标签的样本,向前传播(forward)一次,通过 data augmentation和 dropout 注入扰动,得到预测值后与自己的真实标签计算交叉熵,最后将平方误差与交叉熵加权求和即为损失值。
 相较于Π模型,Temporal Ensembling 对无标签数据减少了一次计算,因此速度快了一倍。Temporal Ensembling对П-Mode的改进在于,训练过程的每一个 epoch 中,同一个无标签样本前向传播(forward)一次。那么另一次怎么得到呢?Temporal Ensembling 使用之前 epoch 得到的 predictions 来充当,具体做法是用指数滑动平均(Exponentially Moving Average,EMA)的方式计算之前 epochs的 predictions,使得 forward 的次数减少一半,速度提升近两倍。
相较于Π模型,Temporal Ensembling 对无标签数据减少了一次计算,因此速度快了一倍。Temporal Ensembling对П-Mode的改进在于,训练过程的每一个 epoch 中,同一个无标签样本前向传播(forward)一次。那么另一次怎么得到呢?Temporal Ensembling 使用之前 epoch 得到的 predictions 来充当,具体做法是用指数滑动平均(Exponentially Moving Average,EMA)的方式计算之前 epochs的 predictions,使得 forward 的次数减少一半,速度提升近两倍。
以上文字来源于半监督方法-前记:Π模型,Temporal Ensembling,Mean-Teacher-CSDN博客
2、EMA

EMA可以近似看成过去 1/(1−β) 个时刻 V 值的平均。那么就是 β 越大,表示考虑前 N-1 的影响越大,而考虑当前第N次的影响越小。
2 Mean Teacher
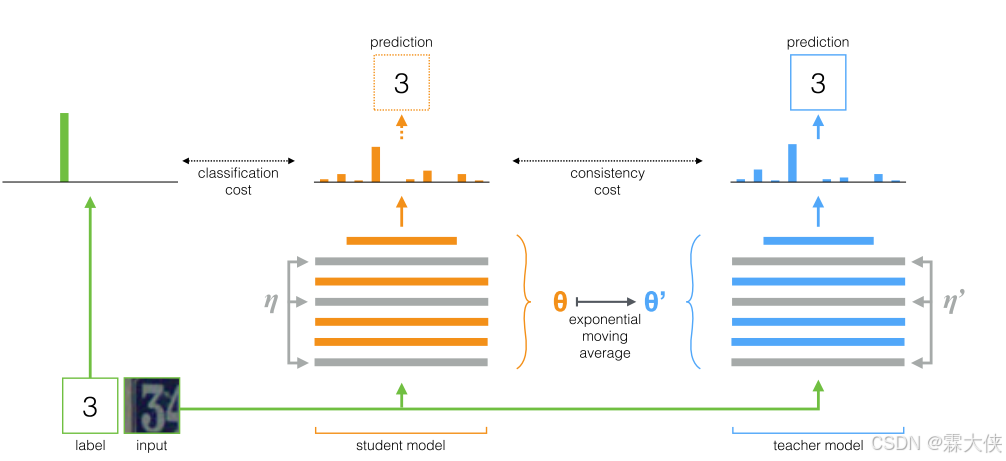
图2:Mean Teacher方法。 该图描述了具有单个标记示例的训练批。 学生模型和教师模型都在计算中使用噪声(η, η ')来评估输入。 将学生模型的softmax输出与使用分类成本的one-hot标签和使用一致性成本的教师输出进行比较。 在用梯度下降法更新学生模型的权重之后,教师模型的权重被更新为学生权重的指数移动平均值。 两种模型的输出都可以用于预测,但在培训结束时,教师的预测更有可能是正确的。 与未标记示例的训练步骤相似,除了不应用分类成本。
对方法图中的要点解释:
- 在训练步骤中对模型权重进行平均,往往会产生比直接使用最终权重更准确的模型
- 教师模型不与学生模型共享权重,而是使用学生模型的EMA(指数移动平均)权重
- 目标模型具有更好的中间表示
- 与One-Hot编码的标签比较(有监督学习):
目的:计算分类损失(交叉熵损失),这是有监督学习的核心部分。这一步的目的是让模型学习如何根据输入数据正确分类。
过程:将学生模型的softmax输出(预测概率分布)与真实的标签(one-hot编码形式)进行比较,计算它们之间的差异。这个差异(损失)告诉我们模型的预测与实际标签之间的误差有多大
优化:通过最小化这个损失,模型学习调整其参数以提高预测的准确性。
-
与教师模型的输出比较(半监督学习/一致性正则化):
目的:计算一致性损失,这是半监督学习中的一个重要组成部分,特别是在Mean Teacher方法中。这一步的目的是提高模型的泛化能力,确保模型对输入数据的小扰动保持鲁棒。
过程:将学生模型的输出与教师模型的输出进行比较,计算两者之间的差异。由于教师模型是学生模型权重的指数移动平均,它提供了一个平滑且稳定的预测目标。
优化:通过最小化这个一致性损失,模型被鼓励产生稳定的预测,即使输入数据有轻微的变化或扰动。
一致性损失:均方误差
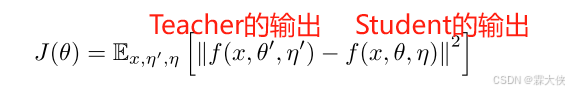
损失定义为二者之间期望的距离。
总成本:这些成本的加权和,其中分类成本的权重是每个小批量标记示例的预期数量,受下面描述的增加。
Π模型、Temporal Ensembling和mean teacher之间的区别在于如何生成教师预测:
①Π模型:使用θ' = θ
②Temporal Ensembling:近似f(x, θ', η')为连续预测的加权平均值
③Mean teacher:定义在训练步骤t时的θ'_t为连续θ权重的EMA(指数移动平均)
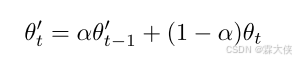
对于这个权重更新参数的介绍参考上面的解释。
Mean Teacher方法相对于Temporal Ensembling的主要优势在于,它可以在每个训练步骤后更新教师模型的权重,而Temporal Ensembling只能在每个训练周期结束后更新。这使得Mean Teacher方法更适合大型数据集和在线学习场景,因为它可以更快地利用未标记数据中的信息
这里的“训练步骤”通常指的是一次前向传播和随后的一次反向传播的整个过程,这个过程会更新一次模型的权重。具体来说:
-
前向传播(Forward Pass):输入数据被送入模型,模型根据当前的参数(权重和偏差)计算输出。
-
损失计算(Loss Calculation):模型的输出与真实标签(对于有监督学习)或与之前的输出(对于某些无监督学习或半监督学习算法,如Mean Teacher)进行比较,计算损失函数,以衡量模型性能。
-
反向传播(Backward Pass):根据损失函数计算梯度,即损失相对于模型参数的导数,这个过程称为反向传播。
-
参数更新(Parameter Update):使用计算出的梯度和选择的优化器(如SGD、Adam等)来更新模型的参数。
-
实时更新:在在线学习或某些连续学习场景中,模型参数可能会在处理每个新数据点后更新,这是一种极端的“在每个训练步骤上更新”的情况。
在传统的训练过程中,这个更新步骤会在每个mini-batch或每个epoch后进行。以下是一些相关的细节:
-
Mini-batch梯度下降:在每次处理一个mini-batch数据后,模型参数就会更新一次。这种方法平衡了计算效率和参数更新的频率。
3 Experiments
首先在TensorFlow[1]中复制Π模型作为基线。 然后修改了基线模型,使用加权平均一致性目标。 模型架构是一个13层卷积神经网络(ConvNet),具有三种类型的噪声:输入图像的随机平移和水平翻转,输入层上的高斯噪声,以及网络内应用的dropout。 我们使用均方误差作为一致性成本,并在前80次迭代中将其权重从0增加到最终值。 该模型和训练程序的细节见附录B.1。

-
EMA加权模型的优势:
使用指数移动平均(EMA)加权的模型(图中蓝色和深灰色曲线)在初始阶段之后,比原始的学生模型(橙色和浅灰色曲线)提供了更准确的预测。这表明EMA加权模型在训练过程中能够更快地学习并提高其性能。 -
正反馈循环:
其中教师模型(蓝色曲线)通过一致性成本改善学生模型(橙色曲线),而学生模型通过指数移动平均(EMA)改善教师模型。这种相互作用促进了模型性能的提升。 - 当只有500个标签时(中间列),Mean Teacher模型学习得更快,并在Π模型停止改进后继续训练。这表明在标签稀缺的情况下,Mean Teacher模型能够更有效地利用有限的标签数据,并继续从大量的未标记数据中学习。
- 在所有数据都有标签的情况下(左列),Mean Teacher模型和Π模型的表现几乎相同。这说明当有足够标签数据时,Mean Teacher模型的额外好处可能不那么明显,因为模型已经能够从丰富的标签数据中学习。
3.4 Ablation experiments
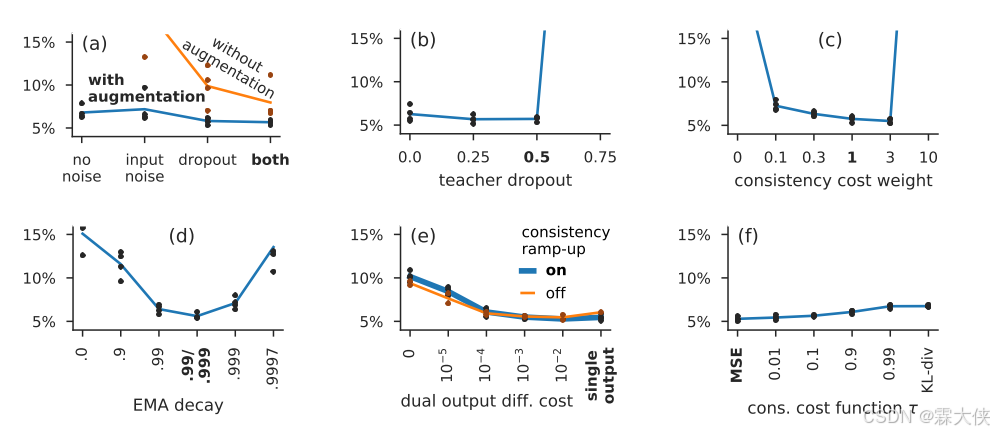
图a和图b:
- 尽管引入了Mean Teacher模型,噪声(在这里指数据增强和dropout)仍然是提高模型性能所必需的。这表明,即使有了Mean Teacher提供的一致性正则化,额外的噪声源也能为模型带来好处。
- 当使用数据增强时,输入噪声(input noise)并没有提供额外的帮助。这可能意味着数据增强已经为模型提供了足够的多样性,使得额外的输入噪声变得不那么必要。
- 在教师模型中使用dropout相比于只在学生模型中使用,只能提供边际上的好处。虽然dropout是一种有效的正则化技术,但在Mean Teacher框架中,其在教师模型中的效果可能不如在学生模型中显著
图c和图d:
- α值较低意味着教师模型将更快地反映学生模型的变化,而α值较高则意味着教师模型的变化将更加平滑。
- 当EMA衰减率α=0时,教师模型的权重将与学生模型的权重完全相同,这使得模型成为Π模型的一个变体
- 在评估运行中,使用了EMA衰减率α=0.99作为初始阶段(ramp-up phase)的值,以及α=0.999作为其余训练阶段的值。这种策略的选择是因为学生模型在训练初期改进迅速,因此教师模型应该快速忘记旧的、不准确的学生权重。后期学生模型的改进速度减慢,教师模型从更长的记忆期中受益。
图f:
- MSE比其他成本函数表现得更好
模型压缩与蒸馏的关系:
- 模型压缩技术旨在减小深度学习模型的大小和复杂度,以便在资源受限的设备上高效部署和运行。蒸馏是模型压缩的一种方法,通过训练一个小型的“学生”模型来模仿一个大型的“教师”模型的行为,学生模型学习教师模型的输出,以较小的架构实现类似的性能
蒸馏与一致性正则化的区别:
- 蒸馏是在模型训练完成后进行的,目的是将一个训练好的复杂模型的知识转移到一个更简单的模型上。一致性正则化则是在模型训练过程中使用的,它要求模型对输入数据的微小扰动保持一致的预测,以此来提高模型的泛化能力.
代码复现
环境配置
创建一个新的虚拟环境:conda create -n meanTpy37 python=3.7
conda activate meanTpy37因为代码年份比较早,所以用3.7比较好
pip install torch==1.6.0 torchvision==0.7.0 numpy==1.18.5 scipt==1.5.4 pandas==1.1.5 matplotlib==3.3.0 tqdm==4.51.0大概就安装了这几个包
代码修改
1、main文件中:
①224行:替换
原:target_var = torch.autograd.Variable(target.cuda(async=True))
换:target_var = torch.autograd.Variable(target.cuda(non_blocking=True))
②326行:替换
原:target_var = torch.autograd.Variable(target.cuda(async=True), volatile=True)
换:target_var = torch.autograd.Variable(target.cuda(non_blocking=True), volatile=True)
③原:class_loss 是一个0维张量(标量),直接使用索引访问其元素会导致 IndexError。你应该使用 .item() 方法来获取这个标量的值。
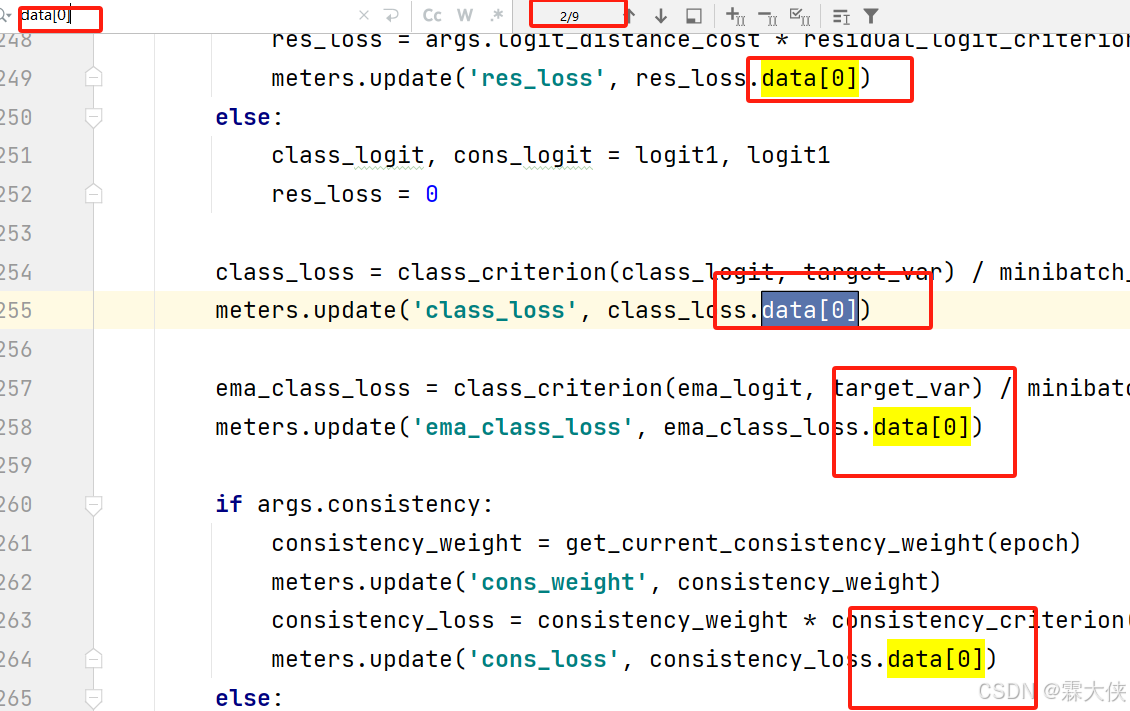
将其都换成.item()
2、pytorch/mean_teacher/utils.py第88行
原:self.avg = self.sum / self.count
改:self.avg = self.sum / float(self.count)
原因:这样可以确保在进行除法时使用的是 Python 的浮点数,而不是张量
3、pytorch/mean_teacher/run_context.py第38行
原:df.to_msgpack(self.log_file_path, compress='zlib')
改:df.to_pickle(self.log_file_path)
原因:因为在较新版本的 pandas 中,to_msgpack 方法已经被移除


















 3295
3295

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









