







主要思想:
在输入或者网络参数存在微小扰动的情况下,鼓励教师和学生网络预测结果的一致性,具体来说:
1、 通常给同一个无标签的样本构建两种不同的数据增强,需要通过约束使得学生和教师模型尽量产生相似的预测结果
2、 学生网络首先使用有标签样本进行梯度下降训练,而在无监督训练的过程中使用的是每次迭代时学生网络权重和教师网络权重的加权和来更新教师网络权重
3、 总的训练损失一般是由对有标签样本进行监督训练的交叉熵和无标签样本进行无监督训练的教师和学生预测结果的MSE损失共同组成
相关理论概述:之前的temporal ensembling方法通过预测标签的EMA(指数移动平均)。temporal ensembling构建出一个标准的输出向量 ,用来作为一致性正则化的比较标准。在mean-teachers中,将 称之为teacher,而每次网络输出的 称之为student,老师包含更多的特征信息,比学生 更加健壮,可以指导学生的学习。

Mean-teachers将原来计算输出向量 的过程变为计算整个网络的参数 ,即原来的网络视为student model,新增加的一个teacher model,teacher的参数由student计算指数移动平均值得到。

此时,计算损失的公式可以表述为:
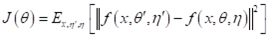
也就是比较teacher和student产生的输出向量,仍然使用L2距离。注意teacher和student上分别使用了不同的扰动 。此处对于整个网络的训练来说,有标签的数据根据student model计算分类损失,然后所有数据和teacher model计算一致性损失,训练的每一步,更新student的梯度之后,计算得到新的 更新teacher model

根据上图可以发现,整个模型分为两个部分,第一个是student model,第二个是teacher model。student model的网络参数通过学习梯度下降获得,teacher model的参数是通过student model的网络参数经过指数移动平均获得的。
损失函数包括两部分,有监督损失函数,保证有标签训练数据拟合;第二部分是无监督损失函数,主要是保证student model的预测结果和teacher model的预测结果尽量的相似,因为teacher model的参数是根据student model的移动平均得到,所以对于任何新来的数据,预测结果都不应该有太大的抖动,如果模型是正确的,那么前后两个模型的预测标签应该是接近的,并且变化比较小,那么使模型向两个模型预测结果接近的方向移动,就是向着groudtruth model的方向移动














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









