







预览
老规矩,请出豆包看一下大纲
1. 摘要
随着 5G 和移动计算的快速发展,社交计算和社交物联网 (IoT) 中的深度学习服务在过去几年丰富了我们的生活。具有计算能力的移动设备和物联网设备可以随时随地加入社交计算。联邦学习可以充分利用去中心化的训练设备,无需原始数据,为进一步打破数据孤岛、提供更精准的服务提供了便利。
然而,各种攻击表明,当前联邦学习的训练过程仍然受到数据和内容层面披露的威胁。在本文中,我们提出了一种新的联邦学习混合隐私保护方法来应对上述挑战。首先,我们采用先进的函数加密算法,不仅保护每个客户端上传数据的特征,还保护加权求和过程中每个参与者的权重。通过设计局部贝叶斯差分隐私,噪声机制可以有效提高不同分布式数据集的适应性。此外,我们还利用稀疏差分梯度来提高联邦学习训练中的传输和存储效率。实验表明,当我们使用稀疏差分梯度来提高传输效率时,模型的准确率最多只下降3%。
- 核心问题:
- 场景:社交物联网(Social IoT)中多方数据共享的联邦学习场景
- 具体:1)攻击者从传输梯度中获取敏感信息;2)攻击者利用背景知识和训练模型,通过模型反转攻击和成员推理攻击等手段,从训练数据中反推隐私信息
- 核心思想:提出一种新的混合隐私保护方法,用于联邦学习,以应对上述挑战。具体包括:
- 加密算法:保护每个客户端上传的数据特征和加权求和过程中的权重。
- 局部贝叶斯差分隐私:通过噪声机制提高不同分布式数据集的适应性。
- 稀疏差分梯度:提高联邦学习训练中的传输和存储效率。
2. 动机&贡献
2.1. 已有方法
已有的FL中隐私保护方法根据保护对象可划分两类,包括:
- 数据级:
- 说明:保护数据本身or特征的,可以理解为数据加密。
- 相关方法:同态加密/安全多方计算。
- 内容级:
- 说明:对原始数据进行修改,使其与真实数据有一定程度的偏差。这可以防止攻击者通过发布的信息或提供的服务接口获取用户的隐私信息。防止攻击者通过模型推理出隐私信息。
- 相关方法:差分隐私。
2.2 现存问题/动机
对应上面的分类进行叙述。这部分具体可以看下论文。
- 可用性问题&场景通用性问题:同态加密、安全多方计算、DP-SGD
- 服务器可信问题:贝叶斯-DP
- 开销问题:在现实世界的社交物联网和移动社交计算系统中,客户在参与联邦学习时经常面临许多限制。由于移动设备或物联网中计算能力、存储、能源等资源的限制,在实施联邦学习的同时,很难分离出海量资源来实施同态密码、乱码电路等高功率隐私保护方法。模型计算[18]。
- 恶意用户问题:IoT参与者数量众多,很容易被恶意用户渗透。恶意用户可以对服务器发布的模型进行成员推理攻击,从而间接获取其他参与者的训练数据[19]。针对这种场景下的数据泄露,不少研究人员提出了针对性的防范方案。徐等人 [20]提出了一种高效的混合隐私保护方法,该方法使用函数加密协议来降低联邦学习中数据训练的成本。服务器只能通过解密获得梯度的平均值,而无法获得每个本地训练的模型的具体梯度权重。尽管具有上述优点,但该解决方案仍存在一些挑战,阻碍了其在实际应用中的推广。 (1)更好的隐私保护。现有联邦学习中的函数式加密算法虽然可以减少一定的计算量,保护每个参与者上传的数据特征的隐私,但它忽略了每个参与者权重暴露的信息。攻击者可以通过分配给每个参与者的权重在一定程度上推断出数据集分布信息。 (2) 最大化可用性。通过使用差分隐私技术来保护训练模型免受成员推理攻击,任何不合理的设置都可能导致更大的隐私泄露或服务质量的损失。挑战在于合理分配隐私预算,确保在保护隐私的前提下提高服务质量。 (3)性能优化。即使使用设计良好的多方安全计算协议(例如函数加密),隐私保护方法的资源开销仍然是物联网设备的一大负担。
2.3 贡献
提出混合的隐私保护方法,主要包括3个部分:贝叶斯DP+函数加密+稀疏梯度
- 函数加密(Functional Encryption)
- 目的:保护客户端上传的数据特征和权重,防止服务器或其他客户端直接获取这些信息。
- 实现:使用多输入函数加密(Multi-Input Function Encryption, MIFE),允许多个客户端独立加密它们的数据并发送给服务器。服务器使用从可信第三方(TTP)获取的解密密钥,对所有客户端参数的聚合结果进行解密,而不是单独解密每个客户端的参数。
- 优势:服务器无法获取单个客户端的参数,也无法重建任何客户端的模型,从而保护了客户端参数的隐私。
- 贝叶斯DP
- 目的:根据数据分布调整噪声强度,提供更平衡的隐私保护,同时提高模型服务质量。
- 实现:在客户端本地计算隐私损失,并根据数据分布调整噪声的添加。这种方法允许客户端根据其数据集的特性调整隐私预算,以实现更好的隐私保护。
- 优势:与经典差分隐私相比,贝叶斯差分隐私可以提供更精细的隐私保护,并且可以根据数据分布动态调整噪声,以保持服务质量。
- 稀疏差分梯度
- 目的:提高联邦学习训练的传输和存储效率,减少通信量和计算负担。
- 实现:在迭代过程中,只有当梯度的变化量超过某个阈值时,客户端才将这些梯度的变化量上传给服务器。服务器将这些变化量与之前缓存的梯度累加,以恢复完整的梯度,然后分发给客户端进行下一轮训练。
- 优势:减少了每次迭代中上传的梯度量,降低了服务器和客户端之间的通信成本,同时减少了加密参数的数量,减轻了加密所需的计算负担。
方法
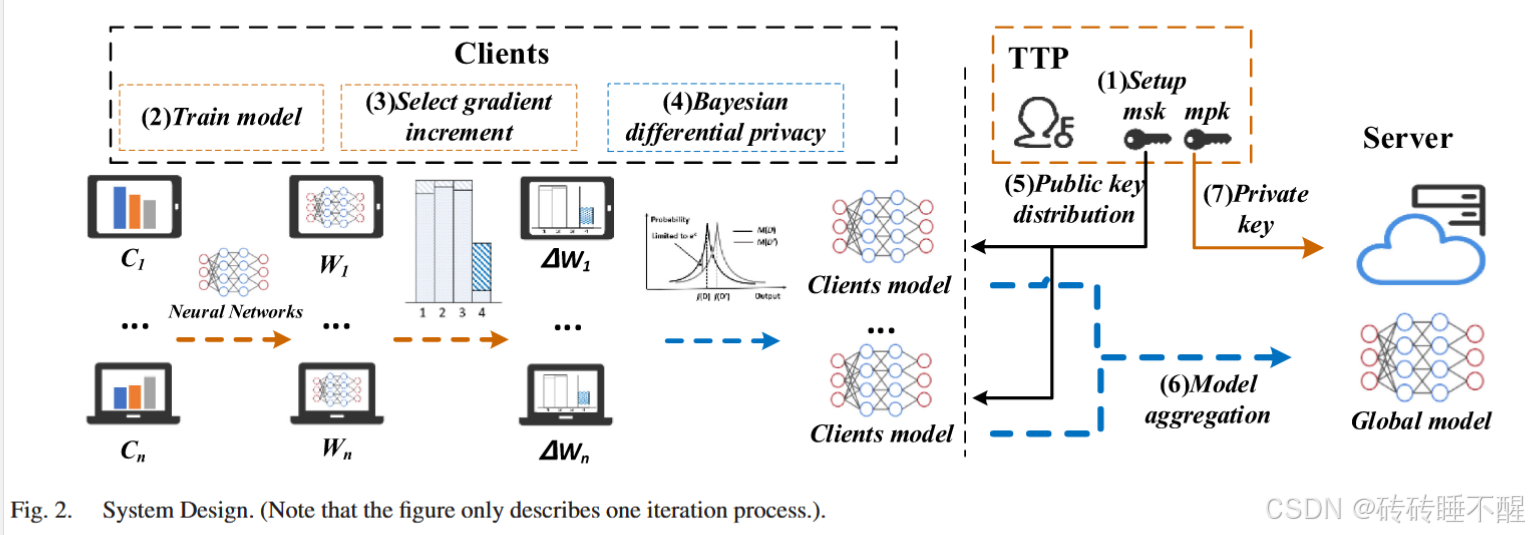
流程总览:
代表N个客户端,每个客户端都有自己对应的数据集
。服务器代表云服务器聚合参数,使用TTP代表受信任的第三方来管理和生成密钥。每个客户端
使用其数据集在本地训练机器学习模型,模型的参数用
表示。
- 可信第三方TTP生成公钥密钥。(函数加密)
- 客户端训练本地模型
- 客户端计算梯度增量,选择增量超过阈值的梯度。(稀疏差分梯度部分)
- 对梯度添加贝叶斯DP噪声。
- 客户端使用可信第三方(TPP)提供的公钥
对其参数进行加密,然后将加密后的参数发送到服务器。(函数加密)
- 猜测是TTP对加密参数执行了聚合,接下来服务器会向TTP请求聚合函数的解密密钥,并使用解密密钥解密所有客户端参数的聚合结果(而不是解密每个客户端参数)。(函数加密)
模块拆解说明:
- 函数加密部分:使用函数隐藏多输入函数加密(Function Hiding MIFE),它总共包含五种算法:Setup;KeyGen; KeyDistribute; Enc; Dec;并将这五种算法分配给联邦学习场景中的客户端、服务器、可信第三方(TTP)三种角色。
其中,Setup; KeyGen; KeyDistribute由TPP执行来生成主公钥和主私钥,并将它们的密钥分发给服务器和客户端。
Enc算法由客户端执行,对各个参数进行加密。
服务器执行Dec算法来解密参数聚合的结果。
KeyDistribute 算法是本文设计的,用于管理和分发所有密钥。 - 贝叶斯DP部分:由于计算隐私预算需要预估数据服从的分布,这很难做到,因此通过估计的方法计算。基于分布,通过预估得到隐私预算,进而确定每个客户端的噪声量。
- 稀疏差分梯度:
- 仅在第一次迭代时将完整的参数上传到服务器。
- 经过第一轮迭代更新后,我们不再上传完整的参数到服务器,而是根据选择策略只上传梯度变化较大的参数。
- 具体来说,我们会计算这次每个参与者产生的梯度增量,并设置一个选择阈值。对于每个客户端,只有那些梯度增量大于阈值的梯度才会被选择,并将梯度增量
上传到服务器。服务器需要从第一轮迭代开始,缓存每次聚合后的梯度,从第二轮迭代开始,服务器的梯度表示ΣΔW。收到客户端上传的参数后,将上一轮的参数添加到上传的梯度增量中以恢复其完整性。然后将梯度发送给每个客户端以进行下一轮训练。
- 好处:稀疏差分梯度减少了每次迭代时的梯度上传量,减少了服务器和客户端之间的通信量,同时减少了加密参数的数量,降低了加密所需的计算开销。令人惊讶的是,稀疏差分梯度对参数也具有隐私保护作用,因为一些变化最小的参数被随机丢弃。
个人总结
1. 贝叶斯噪声部分可以了解一下,maybe创新点在基于分布对隐私预算的估计?{本人对这块还不是很了解}
2. 稀疏梯度部分:很常见的思想,阈值的选择比较重要
3. 选择TTP,同样要考虑实际场景中TTP是否真的可信?



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











