







24年的TDSC,又是一篇CCF A,好好学习一下
关键词:用户聚类;梯度稀疏;隐私保护聚合;联邦学习
预览
摘要
随着机器学习的广泛采用和对数据隐私的日益关注,联邦学习(FL)受到了极大的关注。 FL 方案通常使一组参与者(即数据所有者)能够使用其本地数据单独训练机器学习模型,然后在中央服务器的协调下进行聚合以构建全局 FL 模型。标准 FL 的改进包括
(i) 通过利用梯度稀疏化来减少梯度传输的通信开销,以及
(ii) 通过采用隐私保护聚合 (PPAgg) 协议来增强聚合的安全性。
然而,由于用户稀疏梯度向量的异质性,最先进的 PPAgg 协议不容易与梯度稀疏互操作。为了解决这个问题,我们提出了一种动态用户聚类(DUC)方法,该方法具有一组支持协议,根据 PPAgg 协议的性质和梯度稀疏技术将用户划分为集群,从而提供安全保证和通信效率。实验结果表明,与基线相比,DUC-FL 显着降低了通信开销并实现了相似的模型精度。所提出的协议的简单性使其对于实施和进一步改进都具有吸引力。
- 核心问题:已有的两种FL改进方案 隐私保护聚合 与 梯度稀疏方法 不易兼容
- 核心目的:解决提到的不兼容问题
- 本人关心的问题:
- 首先了解这两个方法,以及各自优缺点,为何不兼容
- 本文的用户聚类的作用是什么?聚类依据是什么?不同的簇有什么不同的地方?聚类完如何做?
- 本文把两种方法兼容后是否确实带来了好处?
2. 动机
2.1 已有方法
- 梯度稀疏:
- 用户仅传输其梯度的一个子集,同时保持全局联邦学习模型的性能。原理是可以从一组梯度中选择最重要的梯度在每次训练轮次中进行传输(这就是所谓稀疏化),以降低通信成本。
- 选择梯度的依据是什么?我目前了解到的方法有:确定一个阈值,梯度本身超过阈值的进行保留,or选择前N个绝对值最大的梯度分量保留(top-k方法)。
- 作用:感觉主要是提升通信效率的,有些论文中也会写这样同样能提供一定的隐私性,因为参与交互的参数更少了,恶意方能够获取到的信息也相应更少。
- 隐私保护聚合(PPAgg):
- 问题:可以访问用户本地训练模型的对手(例如服务器)可能会发起所谓的梯度深度泄漏(DLG)攻击,导致用户数据的严重信息泄露。
- PPAgg协议使中央服务器能够以保护隐私的方式聚合用户本地训练的模型或梯度,引起了学术界和工业界的极大关注[2],[3],[8],[27] ,[29]。最先进的 PPAgg 协议 [2]、[3] 利用成对屏蔽技术。
成对屏蔽技术说明
具体来说,对于一组有序用户 U,其中每个用户
持有一个梯度矩阵
。目标是计算
,同时保留每个
将成对掩码添加到
。
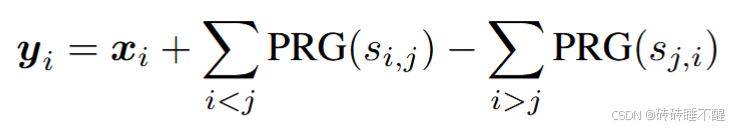
PRG 表示能够使用共享种子
生成数字序列的伪随机数生成器;该种子由用户对
通过 Diffie-Hellman (DH) 密钥交换协议达成一致。
解析:对于用户
。这样,当所有用户的掩码矩阵
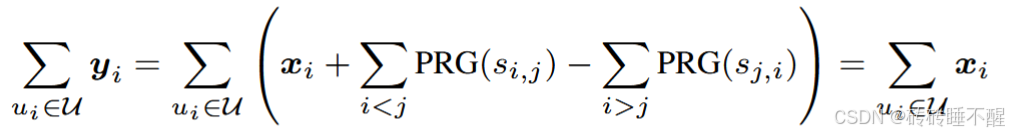
这个公式表明,尽管每个用户的梯度都被掩码了,但是当我们将所有用户的掩码矩阵相加时,所有的掩码项都会相互抵消,最终得到的是所有用户梯度的简单总和
- 困难:稀疏化技术仅选择矩阵的一小部分,而 SecAgg 协议需要对整个矩阵进行操作。成对掩码的未对准会导致不正确的掩码取消。
2.2 动机
为了解决这个问题,一个直观的想法是将所有用户划分为多个集群,并将同一集群中的用户矩阵对齐。这样每个集群的用户就可以独立进行SecAgg进行聚合,即基于集群的SecAgg。然而,聚类结果会影响(i)通信效率,因为不同用户的稀疏梯度矩阵的索引分布不同,这决定了梯度对齐的填充和裁剪操作的数量,从而决定了梯度矩阵的大小。此外,聚类结果影响(ii)所采用的SecAgg协议的安全保证,因为系统中可能存在掉线用户和恶意用户。因此,要获得一种既高效又安全的聚类算法并不是一件容易的事。
2.3 贡献
- DUC 算法:该算法动态地将用户划分为多个集群,以实现基于集群的 SecAgg,与标准 SecAgg 协议相比,它针对半诚实合谋对手提供了相似的安全保证。
- 梯度过滤算法:以使同一集群中用户的矩阵对齐,从而实现最佳通信效率。此外,提出了经过调整的稀疏化算法,以在机器学习任务中保持相似的模型性能。
- 隐私与性能的权衡分析
3. 方法
3.1 攻击设置:
在恶意环境下,对手可以在DUC方案中执行三种类型的攻击:(i)向不同用户分发不同的全局模型,而不是单一的全局模型,使得即使用户的梯度相关信息在安全聚合后仍可识别并直接与其来源相关联;(ii)模拟足够数量的恶意用户,例如通过Sybil攻击。在这种情况下,恶意用户的数量超过了SecAgg方案中定义的保证安全的阈值,从而破坏了安全保证;(iii)选择专门设计的梯度进行操纵,以便可以从聚合结果中区分出诚实用户的梯度,类似于密码学中选择明文攻击(CPA)的思想。
为应对第一种漏洞,可以采用一致性检查和验证技术[2]、[3]、[27]。在这种方法中,每个用户在其接收到的全局模型上生成一个签名,然后将其转发给其他用户,以便根据接收到的全局模型验证其一致性。
然而,处理与第二种漏洞相关的Sybil攻击存在挑战,因此,先前的工作仅在恶意用户数量不超过预定义阈值的设置中考虑它[2]、[3]、[27]。在这种设置下,如SecAgg + [2]中所提出的通过用户联合执行的分布式通信图生成方法,可用于在DUC方案中由所有参与用户而不是服务器生成集群。这确保了足够数量的恶意用户不会与诚实用户分配到同一集群中,防止攻击者利用奇异索引进行信息泄露。
此外,如后文所述,第三种漏洞可以通过确保足够数量的诚实用户聚集在同一集群中来解决。
3.2 具体方法
3.2.1 框架总览
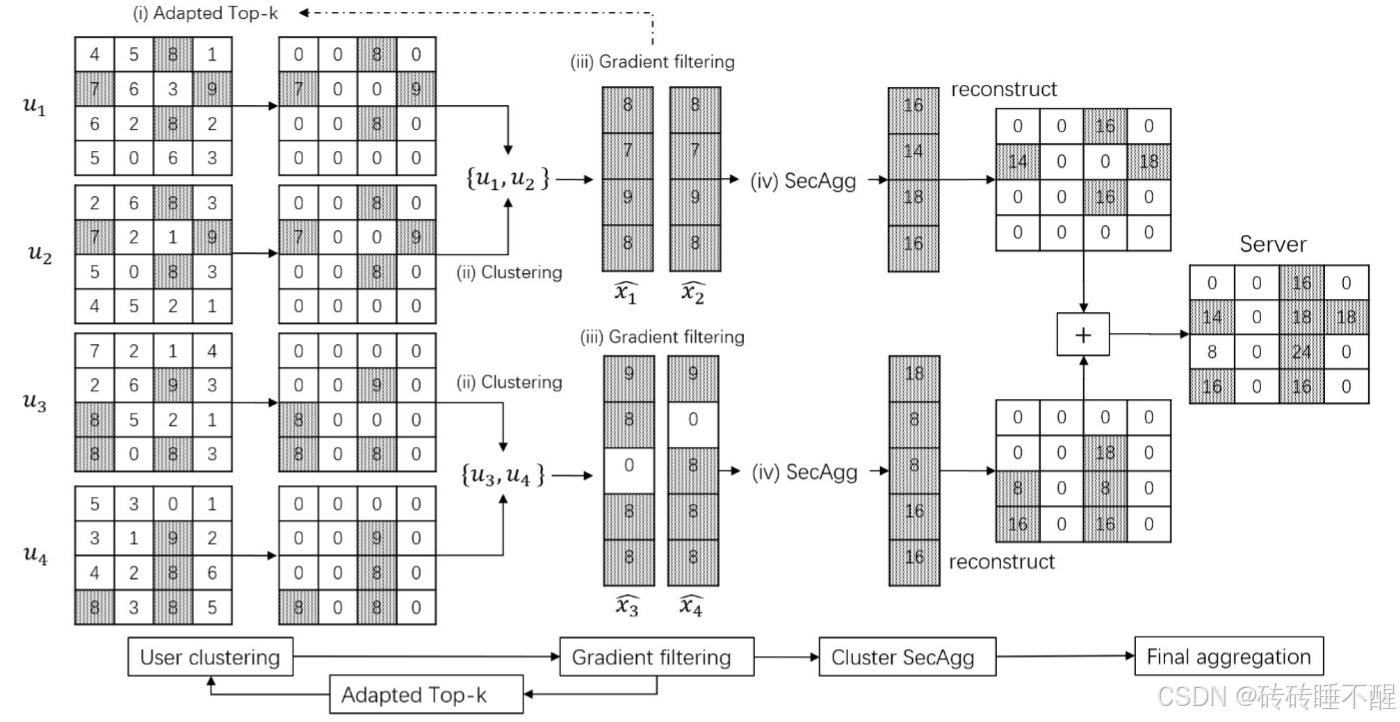
主要由四个连续步骤组成,即
(i)适应Top-k稀疏化:在top-k似乎做了一些调整
(ii)用户聚类:将用户划分为簇,其中用户的稀疏 Top-k 矩阵具有相似的索引分布。如上图,用户1,2被划分到一个簇,3,4被划分到一个簇。
(iii)梯度过滤:1和2的梯度是对齐的,因此未作调整;而对于34,使用它们的索引的并集并将零填充到填充位置。之后,每个集群按照SecAgg协议计算用户稀疏矩阵的总和,然后将其重构为矩阵并由服务器聚合以获得最终结果。
(iv)SecAgg:参考论文Practical secure aggregation for privacy-preserving machine learning,本文未对SecAgg方面做优化。
3.2.2 详细说明:
- 用户聚类模块{这一块不对聚类方法做过多的工作,聚类方法采用优化的kmeans聚类}:
- 首先直观地想,解决掩码无法互相抵消的问题有一个方案是:将具有相同索引的用户划分到若干个集群中,并在每个集群中执行安全聚合协议,然后将所有集群的结果总和进行聚合。
- 问题:稀疏化的随机性,导致匹配存在挑战性。举个例子,例如,一个基于 3 层神经网络的简单 MNIST 分类任务 [24],以及采用 90% 丢弃率的梯度稀疏化(假设具有1000个客户端,每个梯度具有50,000分量,稀疏化选取10%进行保留),计算得出的概率是很小的,这样做不划算。
- 解决思路:
- part1. 不采取严格的“梯度索引完全相同”策略,放宽松弛,一个聚类中的用户梯度距离满足“汉明距离之和最小”原则,具体来说,I 是用户 i 的梯度在稀疏后的索引矩阵,D表示汉明距离,μ表示簇 ci 中索引的均值,优化目标是找到聚类C满足表达式最小化。
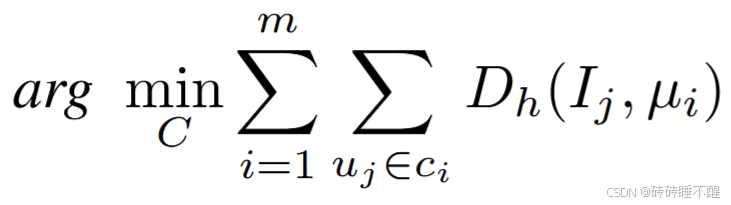
- part2. 解决隐私泄露的问题,例如下图,梯度x1和x2都可能被推断出来,对应索引8和10,称为奇异索引(singular index),
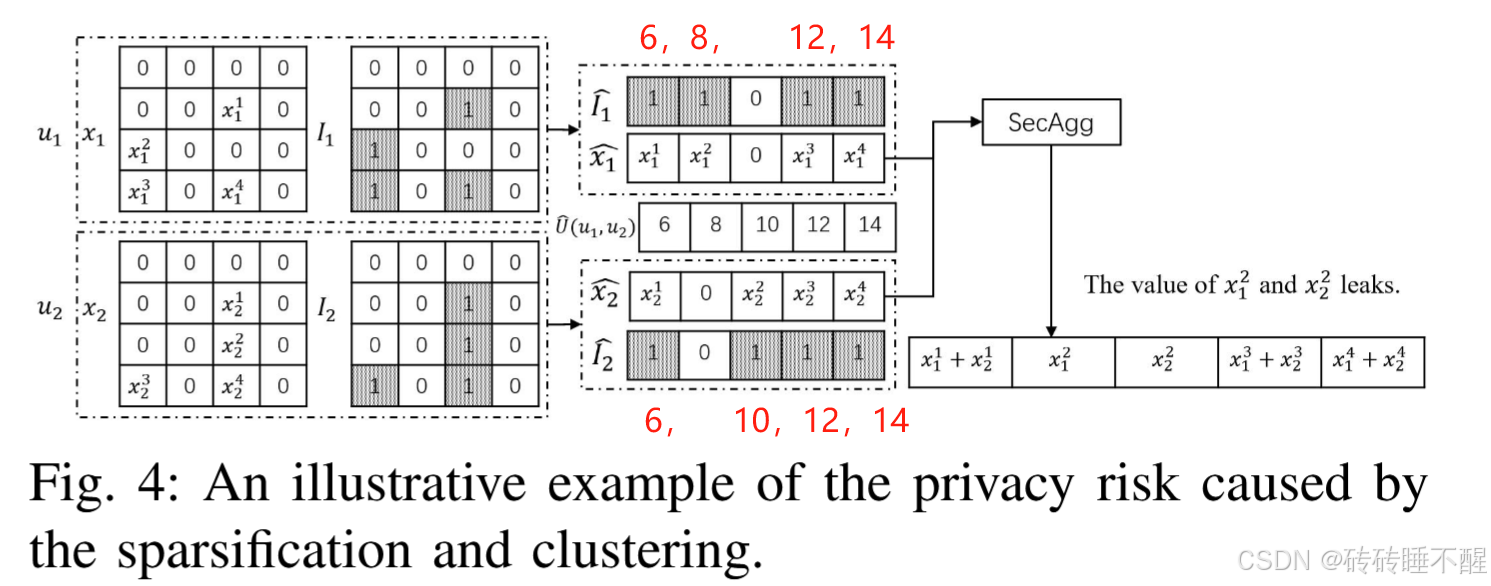
因此,可以新增目标:最小化奇异索引的数量,其中是索引并集
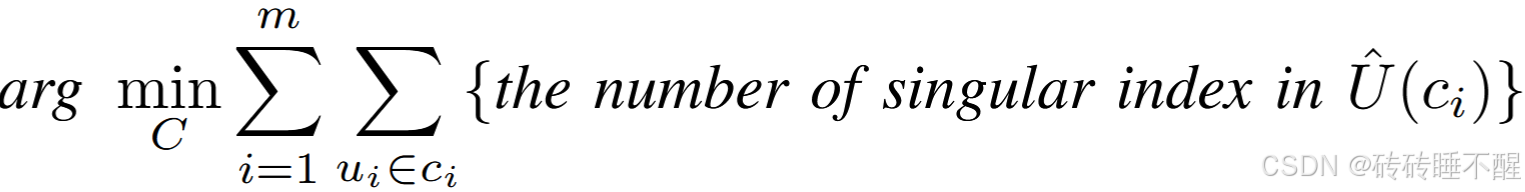
- 除此之外,考虑到shamir安全性,又提出了几个限制,通过这些限制能够确定一个最优的聚类数量。这里就不仔细描述了。
- part1. 不采取严格的“梯度索引完全相同”策略,放宽松弛,一个聚类中的用户梯度距离满足“汉明距离之和最小”原则,具体来说,I 是用户 i 的梯度在稀疏后的索引矩阵,D表示汉明距离,μ表示簇 ci 中索引的均值,优化目标是找到聚类C满足表达式最小化。
- 至此,可以获得DUC伪代码如下

- 梯度过滤模块:
- 目标:确保过滤后,一个簇至少有2个诚实的客户的梯度,基于下面限制,得到要提出辅助矩阵aux以及推出Algo3中的不等式(5)。

- Algo3中,
表示有多少用户保留了梯度的分量 i ,而bound计算用于决定哪些梯度索引应该被剪辑或填充,具体地,计算是通过最小化一个特定的损失函数来确定的,考虑了集群大小 l 、腐败or掉线的用户比例 γ 以及梯度的稀疏性δ。猜测该损失函数是根据梯度过滤模块中的约束4得到的。
aux值为1则该梯度分量归类到残差矩阵部分,并将梯度中这些分量置换为0;这一步是为了在后续训练中补偿被剪辑掉的梯度信息;aux为-1则将res残差矩阵的值取出给当前的稀疏梯度,并将残差矩阵对应分量置换为0,这一步是为了在当前训练中使用这些填充的梯度信息。

- 目标:确保过滤后,一个簇至少有2个诚实的客户的梯度,基于下面限制,得到要提出辅助矩阵aux以及推出Algo3中的不等式(5)。
- 调整的top-k稀疏:对于稀疏后的梯度矩阵
,增加辅助矩阵 aux(计算参考Algo.3)可以理解为1是要记录,-1是要使用之前的记录?

总结
对本文的工作进行总结,主要贡献是实现了SecAgg和梯度稀疏法难以结合使用的问题。
存在问题:SecAgg部分其实就是2.1中的2(PPAgg),稀疏梯度导致掩码在求和时可能无法抵消,导致数据泄露。
总体来说,感觉本文的做法还是有一点点绕,对聚合算法未作改动,稍微梳理一下:
1.流程:用户训练——>普通的top-k稀疏(保留梯度分量中k个绝对值最大的,提升通信效率)——>用户聚类(尽可能让能够相互抵消的(即,达成最小程度的隐私泄露)稀疏梯度对应用户被分到一个簇中)——>梯度过滤(计算aux)——>调整后的Top-k(基于aux更新梯度矩阵、分量索引矩阵以及残差矩阵)——>发送服务器,对簇内利用SecAgg算法执行第一次聚合(隐私保护:服务器只能知道不同簇的梯度,无法知道具体客户端的梯度)——>各簇的结果求和,抵消掩码,得到真正的梯度更新,更新模型。

2. 思考:方向上确实是我想了解的客户聚类,就是不知道SecAgg具体是什么方法,还需要了解一下前置知识。


















 2625
2625

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











