







预览
from豆包
1. 摘要
许多人工智能技术已被应用于从海量工业大数据中提取有用信息。然而,许多现有方法通常忽视隐私问题。在本文中,我们提出了一种用于工业大数据挖掘的匿名且保护隐私的联邦学习方案。我们通过实验探讨了共享参数的比例对精度的影响,发现共享部分参数几乎可以达到共享所有参数的精度。在此基础上,我们提出的联邦学习方案通过在服务器和每个参与者之间共享更少的参数来减少隐私泄露。具体来说,我们利用高斯机制在共享参数上的差分隐私来提供严格的隐私保护;测试不同ε和δ对精度的影响;我们跟踪δ——当它达到某个阈值时,训练就会停止。此外,我们采用代理服务器作为服务器和所有参与者之间的中间层,以实现参与者的匿名性;值得注意的是,这还可以减轻联邦学习服务器的通信负担。最后,通过与其他方案的比较,我们提供了安全性分析和性能评估。
- 核心问题:在现有的联邦学习方法中,共享模型参数可能会导致隐私泄露,例如恶意参与者可能通过共享的参数恢复敏感数据。
- 核心思想:减少共享的参数规模,从而降低隐私泄露风险
2. 动机&贡献
2.1. 现有隐私保护机制
- 通过匿名来保护数据聚合过程中身份信息的隐私,如k-匿名算法用于数据隐私保护,帮助多源数据汇总其信息而不泄露个人隐私。
- 同态加密:可以实现加密状态下的数据共享;在[8]中,提出了一种隐私保护深度计算模型,在云服务器上用加密数据训练模型,而客户端仅基于同态加密对私有数据进行加密和解密。然而,同态加密需要机器学习算法中非线性函数的多项式逼近,从而在准确性和隐私性之间做出权衡。
- 扰动机制:对原始数据进行干扰以实现隐私保护,例如差分隐私(DP)。通过在梯度中添加高斯噪声,提出了一种差分隐私随机梯度下降算法[9],参与者不断计算隐私泄露的概率,一旦达到阈值就停止训练。
- 其他密码学方法。例如,在[10]中,提出了一种基于云的相互认证协议,旨在确保车联网(IoV)系统中有效的隐私保护。{个人觉得可以跟2合并}
- 联邦学习(FL),然而仍然存在隐私保护的问题。
2.2 贡献
- 本文主要场景:恶意参与者或好奇的服务器可能通过共享参数泄露他人隐私的问题。
- 首先,参与者可以在训练时通过公开更新参数来间接揭示有关其训练数据集的一些信息。
- 另一个是好奇的服务器可以链接每个参与者的更新。
- 因此,本文设计系统是为了实现两个目标:防止模型参数泄露隐私和设计一个不知道上传者身份的参数服务器(即无法确定每个local梯度具体来源)。
- 贡献:
- 减少共享参数规模:过共享更少的参数来减少隐私泄露。在每一次迭代中,选择部分参与者的部分参数进行更新。实验结果证明,当共享参数减少一个数量级时(即,即使不共享所有参数),模型精度几乎没有下降。什么样的参数筛选机制能够不对模型精度造成显著影响?
- 代理服务器:我们引入代理服务器用于 FL 服务器和参与者之间的通信,有助于减轻 FL 服务器的通信负担并防止其获取参与者身份。
- 噪声机制:我们在梯度中添加高斯噪声以提供严格的隐私保护,并设置自停止机制。实验分析了噪声对模型精度的影响。
方法&创新
方法
模型架构:
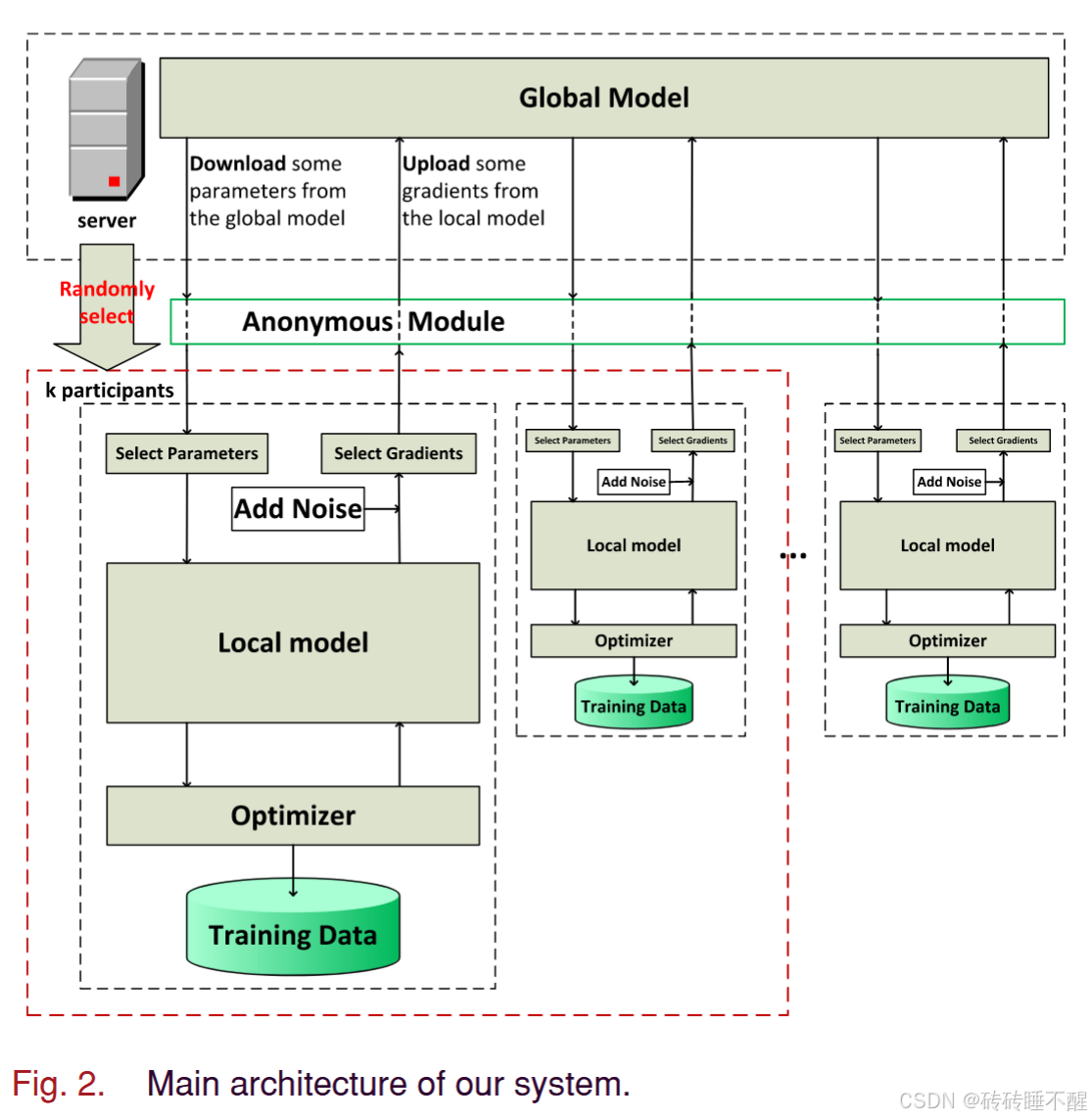
可以看出来,相比普通FL,要多的几个步骤跟贡献中是对应的:选择参数;添加噪声;匿名模块(代理服务器)

流程:
- 下发全局模型:开始前,随机选择k个参与训练的客户端,进行全局模型下发
- 初始化本地模型:从全局模型中随机选择一定比例参数(例如,
),替换到本地模型中,作为初始化的本地模型
- 本地模型训练:可以选择自己的训练方法,本文采用了小批量梯度下降(MBGD)
- 梯度噪声扰动:训练完,得到梯度
,并添加噪声。然后选择
个绝对值最大的梯度分量,这些分量保持不变,其余梯度分量置为0.
- 聚合:直接fedavg聚合
匿名模块部分说明:
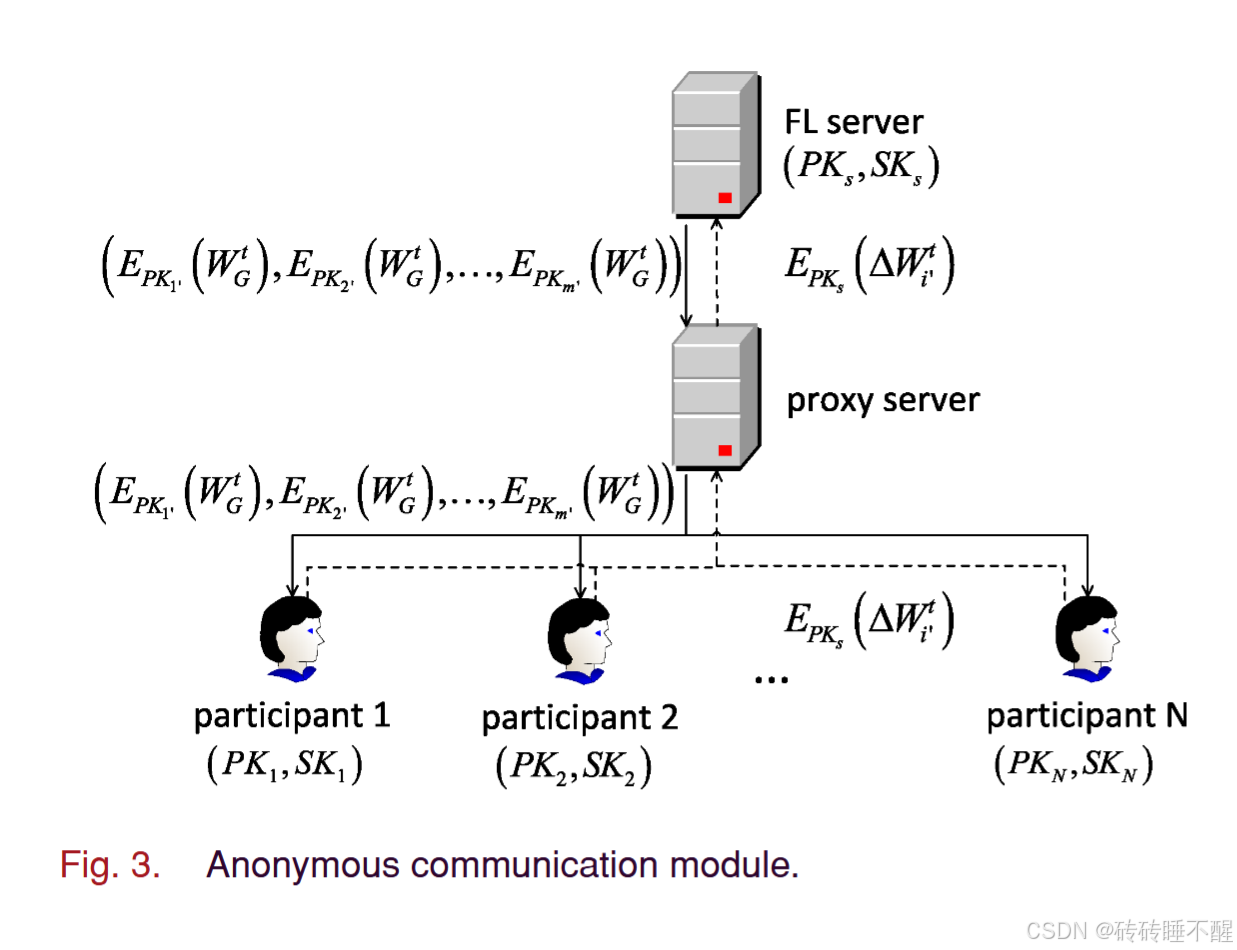
采用代理服务器作为服务器和所有参与者之间的中间层,以实现参与者的匿名性,并减轻FL服务器的通信负担。如图 3 所示,FL 服务器和所有参与者都有自己的一对公钥和私钥,分别为 和
,其中
捐赠参与者 i 的密钥。FL服务器和参与者提前协商并分发密钥(也可以使用证书颁发机构(CA)来帮助FL服务器和参与者获取他人的公钥)
- 代理服务器存储FL服务器和所有参与者的地址。首先,FL服务器随机选择m个参与者,分别用各自的公钥对全局模型进行加密,得到
。
- FL服务器将加密后的数据发送给代理服务器,然后转发给所有N个参与者。所有参与者都尝试用自己的私钥解密数据,只有选定的 m 个参与者才能解密以获得全局模型。对于每个参与者 i′,训练本地模型并计算梯度,用 FL 服务器的公钥对梯度进行加密,然后得到
。
- 加密的梯度被发送到代理服务器并转发到FL服务器。这样,FL服务器就不知道自己正在和谁通信;此外,代理服务器和未选中的参与者由于没有相应的私钥,因此无法获取参数或梯度。更重要的是,当FL服务器的通信负担转移到代理服务器时,减轻了FL服务器的通信负担。
总结:每个客户端都生成自己的公钥私钥对,将公钥发送到服务器——>服务器随机选m个客户端的公钥用来加密,得到m个加密的模型参数,这些模型只有那m个客户端才能成功解密——>其余时候执行前面说到的噪声扰动&选择梯度分量
总结
- 方法上来说不难想到,相当于结合DP+梯度压缩,中间加了个匿名模块,类似的也可以换成shuffler模块
- 梯度选择的方法是否比较草率or还有更好的方法?文章直接选择了具有最大绝对值的分量


















 2284
2284

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











