






文章等级:CCF-A
关键词:联邦学习;边缘计算;差分隐私;通信回合
预览
1. 摘要
联邦学习(FL)作为一种协作机器学习框架,能够保留来自移动终端(MT,可以理解为客户端)的私有数据,同时将数据训练成有用的模型。尽管如此,从信息论的角度来看,好奇的服务器仍然有可能从 MT 上传的共享模型中推断出私人信息。
为了解决这个问题,我们首先利用本地差分隐私(LDP)的概念,并提出一种用户级差分隐私(UDP)算法,在将共享模型上传到服务器之前向共享模型添加人工噪声。根据我们的分析,UDP框架可以通过改变人工噪声过程的方差来实现第i个客户的-LDP,并具有可调节的隐私保护级别。然后我们得出 UDP 算法的理论收敛上限。它揭示了存在最佳的通信轮数来实现最佳的学习性能。更重要的是,我们提出了一种通信回合折扣(CRD)方法。与启发式搜索方法相比,所提出的CRD方法可以在搜索计算复杂度和收敛性能之间实现更好的权衡。大量实验表明,我们的 UDP 算法使用所提出的 CRD 方法可以有效提高给定隐私保护级别的训练效率和模型质量。
- 核心问题:
- 场景:IoT
- 问题描述:FL中不可信的服务器可能从全局模型中推断移动终端(客户端)的隐私信息
- 核心目标:
- 过程中改变噪声方差,从而实现用户级LDP,隐私级别可调节。
- 计算复杂度与收敛的权衡分析,并提出优化方法
阅读本文时我思考的关键问题是:
- 如何计算每个客户端的噪声方差?
- 如何衡量隐私泄露程度?{文章提到自己计算了隐私泄露privacy loss moment的程度,关于moment的预备知识补充在第五节中}
2. 动机&贡献
2.1 现有方法
文章主要对DP做综述,感觉说introduction部分的很笼统,没有进行分门别类叙述,总的来说现存问题跟其他论文中写的差不多,通信成本问题,防御范围有限(如无法防御好奇的服务器)。因此,写作时条理清晰很重要
(人家是CCF A我搁这蛤蟆评价人类了sorry,退一步也许是我水平有限读不明白)
DP-深度学习:
1. DP-SGD:在每次训练迭代时仔细分配隐私预算来改进基于 DP 的随机梯度下降 (SGD) 算法,每次迭代的隐私预算和步长是在运行时根据当前训练迭代获得的噪声统计数据(例如梯度)的质量动态确定的。
2. FL的DP:
- [23]中的工作提出了一种基于每次聚合的随机子采样调度的FL算法。当有足够多的参与客户端时,该算法可以在给定的隐私级别上取得良好的训练性能。然而,它无法保护 MT 的私人信息不被暴露给好奇的服务器。
- [24] 中的工作提出了一种替代方法,该方法利用 DP 和安全多方计算 (SMC) 来防范推理威胁并生成高精度模型。这项工作的一个关键组成部分是能够通过利用 SMC 框架来减少噪音,同时考虑可定制的信任参数,这也会消耗更多的通信和计算资源。
- [25]中的工作涉及sketch算法,使用哈希函数以有限误差压缩输入数据,以考虑分布式学习中的通信效率和隐私保护。然而,其中一些方法无法保护 MT 的私人信息不被暴露给好奇的服务器。
- 此外,其他方法(例如 SMC 和sketch算法)可能会消耗大量通信和计算机资源。
2.2 核心贡献
- 方法:提出了一种新颖的隐私保护 FL 框架,用户级差分隐私 (UDP) 算法:利用本地差分隐私 (LDP) 的概念,并验证该 UDP 框架在具有好奇服务器进行迭代学习模型交换的时候可以实现
-LDP(对客户 i )。
- 理论:增强了标准差分隐私(DP)机制(矩会计方法),并分析了LDP定义下每个客户端的敏感性。然后,通过调整添加到模型更新中的高斯噪声方差,证明第 i 个客户端 的训练过程满足不同隐私级别的
- 方法优化:对于给定的隐私级别,在收敛性能方面存在最佳的通信轮数。这个属性表明需要重新考虑通信轮次。因此,设计了一种在线优化方法,称为通信轮数折扣(CRD),与原始UDP算法和离线启发式搜索方法相比,它可以在复杂性和收敛性能之间获得更好的权衡。
- 实验:对真实数据集进行了广泛的实验,实验结果验证了文中的UDP 中的CRD 方法在损失函数值方面可以达到与离线搜索相当的性能,并具有更低的复杂度。
3. 方法
3.1 流程部分
3.1.1 基础方法UDP

流程
服务器下发模型——>客户端训练本地模型后得到梯度——>裁剪梯度——>利用梯度更新模型参数——>计算噪声等级(3.2节中噪声计算的第一个公式截图)——>对模型参数添加噪声——>上传服务器聚合——>服务器下发新模型,客户端进行性能测试,直到回合T
3.1.2 方法优化CRD
理论论证了对于UDP的隐私级别,存在最优通信回合T,然而无法直接推导该值,而穷举法的时间复杂度又比较大,因此考虑提出CRD算法进行优化,通过在训练过程中用discount方法调整通信轮数T,以达到更好的收敛性能。优化后的伪代码:

流程:
1. 初始化:服务器向所有MT广播初始参数(模型参数&T)
2. 步骤1:本地训练:所有参与训练的客户端本地计算训练参数。
{为了DP保证,每个数据样本对局部梯度的影响应该受到一个裁剪阈值C的限制。每个梯度向量基于2范数进行裁剪,即 t 时刻的第 i 个局部梯度向量第 t 轮通信被替换为
。文中指出,这种做法常见但不一定对隐私有贡献,“我们可以说,出于非隐私原因,这种形式的参数裁剪是 ML 的一个流行成分”}
3. 步骤2:噪声计算:每个客户端使用所提出的噪声计算方法获得人工高斯噪声的方差(计算方法:3.2中噪声公式的第二个截图);
4. 步骤3:噪声添加:每个客户端向本地训练的模型参数添加高斯噪声
5. 步骤4:参数上传:所有参与聚合的客户端将噪声扰动的模型参数上传到服务器进行聚合。
6. 步骤5:模型聚合:服务器对上传的参数进行聚合。
7. 步骤6:模型广播:服务器将聚合后的参数和通信轮数T广播给所有客户端。
8. 步骤7:模型更新:所有客户端更新各自的模型,然后测试性能并将性能上传到服务器。
9. 步骤8:通信轮次折扣:当收敛性能通过停止改善时(判断依据:,其中
为阈值,
为模型
的测试损失),服务器将触发折扣方法。具体地:服务器将通过线性折扣因子 β 和整数值
获得一个更小的 T,从而控制 T 的衰减速度。当聚合时间达到预设的 T,训练完成。
总的来说,基于CRD的UDP跟本文最开始提出的UDP差别在于:
1. 每次完成客户端训练完——>服务器聚合完模型——>本地更新local model后测试性能后,基于测试结果动态调整全局轮次 T
2. 迭代计算噪声方差:考虑当前轮次、全局轮次,是迭代计算的
3.2 方法分析部分
这个部分分析一下我最关心的问题。结论先行哈,
- 隐私泄露的衡量:参考论文Deep learning with differential privacy定义的基于矩的隐私损失,其中,由于难以保证Deep learning with differential privacy中对客户端选择概率 q 的限制,本文分析了矩生成函数的上界,从而将隐私损失进行bound。
- 噪声的设定依据:基于矩的上界以及计算得到的敏感性,推导出客户端 i 的噪声方差。
1. 隐私泄露分析:
本文参考了论文“Deep learning with differential privacy”中的隐私损失定义如下。矩生成函数α可以理解为两个分布和
最大距离的对数。
对应
高斯概率密度函数PDF,
对应混合高斯的PDF
![]() ,q是每个客户端被选中参与当轮训练的概率。
,q是每个客户端被选中参与当轮训练的概率。
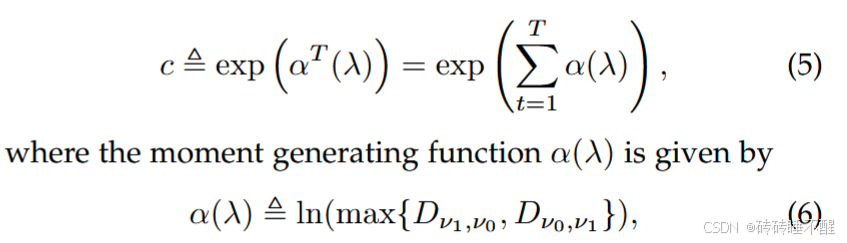
其中矩生成函数经过理论推导可简化成,从而放宽参考论文“Deep learning with differential privacy”的一些限制,得到论文中矩的上界。
文章的敏感性中的 l 是本地训练过程。基于下面公式计算,这部分我没太看懂,有空再推导一下看看。

2. 噪声选择部分
有了敏感性和矩的上界,根据
-LDP的要求,计算得出客户端 i 的噪声方差。论证部分在论文中写的也比较清晰。在不采用CRD时,噪声方差的计算是非迭代的,用下面的公式。
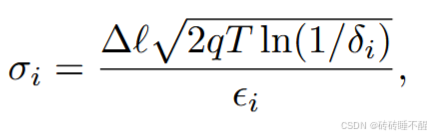
而在采用CRD时,噪声方差是迭代计算的,具体地,在 t (0<=t<=T)回合:
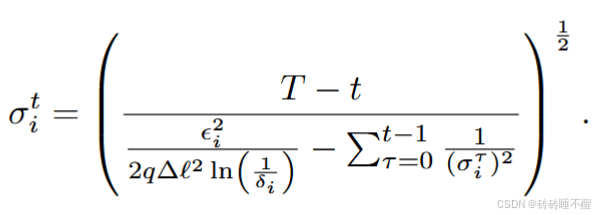
4. 总结
理论推导部分没有吃透,只能对理论分析看了个大概。目前读到两篇在DP噪声机制上做文章的,一篇是设置方差时考虑敏感性,这篇则是动态调整噪声方差。粗想感觉噪声机制没有那么多研究发挥的空间,还需要坚实的理论基础,难啊难。或许考虑特定场景+特定数据敏感性会比较好切入。
本文动态调整T的想法我觉得也挺好的,但是本文提出的discount方法也偏启发式,推导不易。
5. 补充知识——差分隐私中的moment(矩)
1. 定义
在差分隐私中,“moment”(矩)是一种用于衡量隐私损失的概念。具体来说,它与隐私机制输出的分布有关。对于一个随机隐私机制(例如,在差分隐私保护下的数据发布机制),其 k - moment( k 阶矩)用于量化隐私损失在 k 阶统计量上的表现。
设是隐私机制
在输入数据为 x 时的输出随机变量。对于整数
,
的 k - moment 定义为
,其中
和
是相邻数据集(即它们之间只有一个元素的差异)。
2. 作用
- 隐私分析:矩在差分隐私分析中起到了关键作用。通过计算不同阶数的矩,可以评估隐私机制在不同程度上的隐私损失。例如,较低阶的矩(如 k=1 或 k = 2 )可以提供关于隐私机制输出的均值和方差的信息,这些信息对于理解隐私机制的基本特性很重要。较高阶的矩则可以捕捉更复杂的分布特征,如偏度和峰度,从而更全面地评估隐私机制的隐私风险
- 隐私机制比较:同阶情况下,越小的moment表示越好的隐私保护性能。假设有两个隐私机制
和
,通过计算它们的各阶矩,可以直观地比较它们在隐私保护性能上的差异。如果对于所有的 k ,
3. 与差分隐私定义的联系:
差分隐私的标准定义是基于概率的。一个隐私机制是
-差分隐私的,若对所有相邻数据集
和
以及所有可观察输出集合S,有
矩与这个定义密切相关,因为矩可以从统计分布的角度来理解隐私机制对相邻数据集输出的差异。例如,当计算一阶矩( k=1 )时,实际上是在考察隐私机制输出的期望差异,这与差分隐私定义中关于输出概率的比较有内在的联系。
4. 与隐私损失随机变量的关系:
在差分隐私中,通常会定义一个隐私损失随机变量。例如,对于隐私机制和相邻数据集
和
,隐私损失随机变量可以定义为
,其中z是机制
的一个可能输出。矩的计算可以基于这个隐私损失随机变量进行。
例如, k - moment 可以看作是隐私损失随机变量 L 的 k 阶矩,通过研究这些矩,可以深入了解隐私损失的分布特性。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











